
linux安装kafka(单节点启动)
首先去官网上下载zookeeper和kafka(我这里下载的kafka3.0.0)解压完毕后 我放在/opt/module目录下复制zookeeper的conf目录下的zoo.example.cfg文件cp zoo.example.cfg zoo.cfg修改zoo.cfg退出vim进入bin启动zookeeper启动完毕后进入kafka文件夹修改config目录下的server.propertie
·
-
首先去官网上下载zookeeper和kafka(我这里下载的kafka3.0.0)
解压完毕后 我放在/opt/module目录下
-
复制zookeeper的conf目录下的zoo.example.cfg文件
cp zoo.example.cfg zoo.cfg
- 修改zoo.cfg
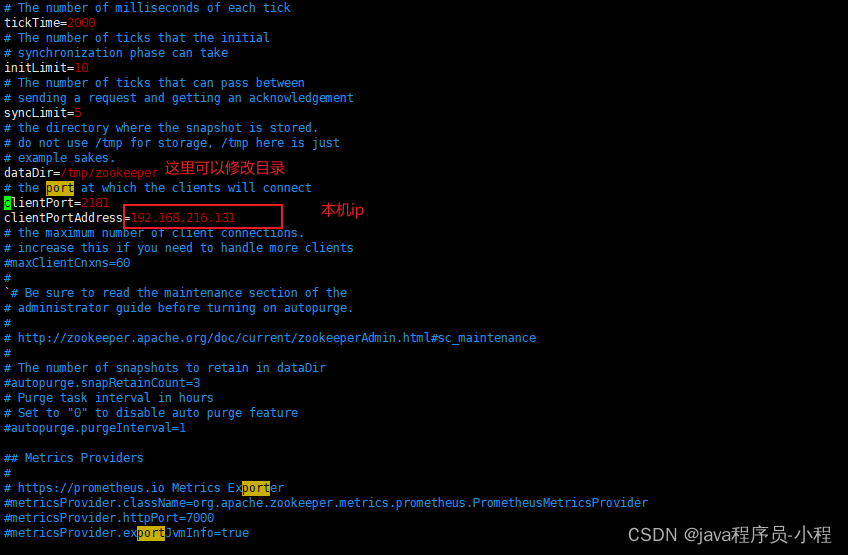
- 退出vim进入bin启动zookeeper

- 启动完毕后进入kafka文件夹
修改config目录下的server.properties的这些地方
注意:- 我这里添加的外部访问kafka的地址,到时候可以用java代码连接
- 关闭防火墙

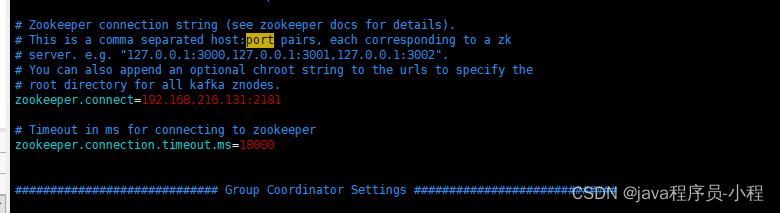

- 启动kafka
进入bin文件夹写脚本启动
#!/bin/bash
#启动zookeeper
sleep 3 #默默等3秒后执行
#启动kafka
/opt/module/kafka/bin/kafka-server-start.sh /opt/module/kafka/config/server.properties &

启动kafka
7.创建kafka topic的first
8.测试消费消息
./kafka-console-consumer.sh --bootstrap-server 192.168.216.131:9092 --topic first
这样就监控first的topic
9.java代码测试
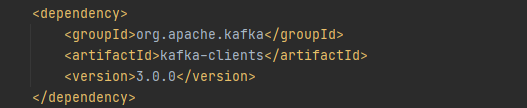
引入依赖
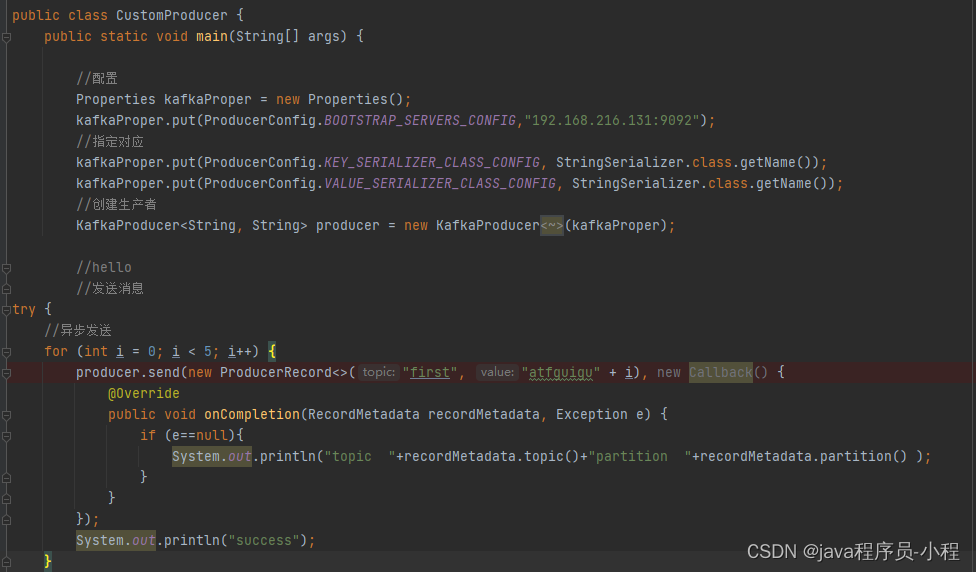
package com.atguigu.kafka.producer;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class CustomProducer {
public static void main(String[] args) {
//配置
Properties kafkaProper = new Properties();
kafkaProper.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.216.131:9092");
//指定对应
kafkaProper.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
kafkaProper.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//创建生产者
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(kafkaProper);
//hello
//发送消息
try {
//异步发送
for (int i = 0; i < 5; i++) {
producer.send(new ProducerRecord<>("first", "atfguigu" + i), new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e==null){
System.out.println("topic "+recordMetadata.topic()+"partition "+recordMetadata.partition() );
}
}
});
System.out.println("success");
}
}catch (Exception e){
e.printStackTrace();
}
//关闭流
producer.close();
}
}
10.测试数据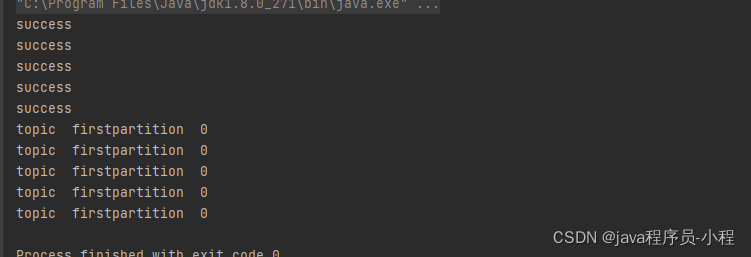

成功被消费,测试成功!!!!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)