
什么是AI?一位3年多前端自我学习的分享
AI 基础什么是AI人工智能(Artificial Intelligence),英文缩写为AI。它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。(百度百科)AI发展畅想图四要素1. 数据(信息)如今这个时代,无时无刻不在产生大数据。移动设备、廉价的照相机、无处不在的传感器等等积累的数据。这些数据形式多样化,大部分都是非结构化数据。如果需要为人工智能算法所用
AI 基础
什么是AI
人工智能(Artificial Intelligence),英文缩写为AI。它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。(百度百科)
AI发展畅想图

四要素
1. 数据(信息)
如今这个时代,无时无刻不在产生大数据。移动设备、廉价的照相机、无处不在的传感器等等积累的数据。这些数据形式多样化,大部分都是非结构化数据。如果需要为人工智能算法所用,就需要进行大量的预处理过程。数据是信息的载体
2. 算法(模型)
主流的算法主要分为传统的机器学习算法和神经网络算法。神经网络算法快速发展,近年来因为深度学习的发展到了高潮。模型是算法/规律的载体
总结:
- 人工智能是通过大量的数据,采集多维信息,自我训练出规律的算法模型。(创建模型)
- 再通过其模型,进行预测或者推演(误差)(使用模型)
3. 算力(训练)
人工智能的发展对算力提出了更高的要求。以下是各种芯片的计算能力对比。其中GPU领先其他芯片在人工智能领域中用的最广泛。GPU和CPU都擅长浮点计算,一般来说,GPU做浮点计算的能力是CPU的10倍左右。
另外深度学习加速框架通过在GPU之上进行优化,再次提升了GPU的计算性能,有利于加速神经网络的计算。如:cuDNN具有可定制的数据布局,支持四维张量的灵活维度排序,跨步和子区域,用作所有例程的输入和输出。在卷积神经网络的卷积运算中实现了矩阵运算,同时减少了内存,大大提升了神经网络的性能。
(算力发展迅速,GPU的算力是CPU的10倍左右,而深度学习框架优化,又再次提升了GPU的性能)
4. 场景(领域)
人有六感,视觉,听觉,嗅觉,味觉,触觉,还具有对机体未来的预感(直觉)。
和人一样,人工智能也有 “感觉”,目前比较常见的,有视觉,听觉(输入),还有直觉(训练猜测/预测)(输出)
图像识别 (视觉 + 直觉)(输入 + 输出)
语音识别(听觉 + 直觉)(输入 + 输出)
什么是机器学习
实现人工智能的方法或者这个过程,我们统称为“机器学习”。

机器学习是机器从历史数据中学习规律,来提升系统的某个性能度量。其实人类的行为也是通过学习和模仿得来的,所以我们就希望计算机和人类的学习行为一样,从历史数据和行为中学习和模仿,从而实现AI。
什么是神经网络
为什么使用神经网络
举个例子,房价。
| 面积(m2) | 价格(w) |
|---|---|
| 50 | 150 |
| 80 | 200 |
| 100 | 400 |
| … | … |

然后我们可以画一条线,并预测 更多的房子的房价。这种模型被称为线性回归,它是机器学习中最简单的模型之一。不过这个模型还不够好:
- 因为只有 8 个数据,所以不够可靠。
- 而且只有 2 个参数(面积,价格),但是还有更多可能会影响价格的因素:比如地区、装修情况等。
数据少,维度低(影响因素少),所以导致准确性也低
那么在实际生活中,我们遇到的,更多是高维的数据,对于4维甚至10000维以上的数据,大脑就没有办法在图表上对其进行可视化了,而神经网络就是为了解决这个问题而生的。
生物的神经网络
下图是生物神经网络及神经元的基本组成部分。

人工的神经网络
科学家们从生物神经网络的运作机制得到启发,构建了人工神经网络。其实人类很多的发明都是从自然界模仿得来的,比如飞机和潜艇等。下图是最经典的MP神经元模型,是1943年由科学家McCulloch和Pitts提出的,他们将神经元的整个工作过程抽象为下述的模型。

现在我们知道了最简单的神经元模型了,我们如何使用该模型从历史数据中进行学习,推导出相关模型了。我们使用上述MP模型学习一个最简单的二分类模型。

如上图,为了训练简单,我们训练集里面只有两条数据。
因为Input只有1个值x_1,所以初始设定参数ω_1,同时还需要一个Bias,我们将Bias设定为ω_0。上述两个参数,我们需要从历史数据中学习出来,但是最开始我们需要一个初始值,假设初始值为ω_1 = 2, ω_0 = -1.5 ;然后我们通过不断地更新迭代最终ω_1和 ω_0 将稳定在两个固定的值,这就是我们最终通过一个简单MP模型学习出来的参数。下图是整个更新迭代学习的过程:

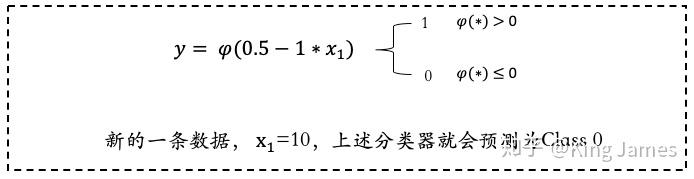
大家可以看到上图最后一次循环ω已经不再发生变化,说明[0.5,-1]就是最终我们学习出来的固定参数。那么上述整个过程就是一个通过神经网络MP模型学习的全过程。下图是最终学习出来的Classifier分类器,我们带入一个新的数据,就可以进行Class预测了。
什么是深度学习(进阶)
随着研究的不断深入,传统机器学习算法在很多“智能”问题上效果不佳,无法实现真正的“智能”。就像牛顿三大定律,无法解释一些天文现象。在1905年,爱因斯坦提出了“相对论”,解释了之前牛顿三大定律无法解释的天文现象。某种程度上,深度学习就是机器学习领域的相对论。
而人工智能,机器学习与深度学习的关系,如下图所示:

上文我们已经介绍了人工神经网络经典的MP模型,那么在深度学习里面我们使用的是什么样的神经网络了,这个”深度“到底指的是什么了?其实就是如下图所示的,输入层和输出层之间加更多的”Hidden Layer“隐藏层,加的越多越”深“。
最早的MP神经网络实际应用的时候因为训练速度慢、容易过拟合、经常出现梯度消失以及在网络层次比较少的情况下效果并不比其他算法更优等原因,实际应用的很少。中间很长一段时间神经网络算法的研究一直处于停滞状态。人们也尝试模拟人脑结构,中间加入更多的层”Hidden Layer“隐藏层,和人脑一样,输入到输出中间要经历很多层的突触才会产生最终的Output。加入更多层的网络可以实现更加复杂的运算和逻辑处理,效果也会更好。
但是传统的训练方式也就是我之前介绍的:随机设定参数的初始值,计算当前网络的输出,再根据当前输出和实际Label的差异去更新之前设定的参数,直到收敛。这种训练方式也叫做Back Propagation方式。Back Propagation方式在层数较多的神经网络训练上不适用,经常会收敛到局部最优上,而不是整体最优。同时Back Propagation对训练数据必须要有Label,但实际应用时很多数据都是不存在标签的,比如人脸。
当人们加入更多的”Hidden Layer“时,如果对所有层同时训练,计算量太大,根本无法训练;如果每次训练一层,偏差就会逐层传递,最终训练出来的结果会严重欠拟合(因为深度网络的神经元和参数太多了)。
所以一直到2006年,Geoffrey Hinton老爷子提出了一种新的解决方案:无监督预训练对权值进行初始化+有监督训练微调。
归纳一下Deep Learning与传统的神经网络算法最大的三点不同就是:
- 训练数据:传统的神经网络算法必须使用有Label的数据,但是Deep Learning下不需要;
- 训练方式不同:传统使用的是Back Propagation算法,但是Deep Learning使用自下上升非监督学习,再结合自顶向下的监督学习的方式。
- 层数不同:传统的神经网络算法只有2-3层,再多层训练效果可能就不会再有比较大的提升,甚至会衰减。同时训练时间更长,甚至无法完成训练。但是Deep Learning可以有非常多层的“Hidden Layer”,并且效果很好。
参考文档:人工智能是什么? - 知乎 (zhihu.com)
参考文档:通俗易懂讲解深度学习和神经网络 - 知乎 (zhihu.com)

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)