云原生向量数据库Milvus(二)-数据与索引的处理流程、索引类型及Schema
本文将介绍 Milvus 系统中数据写入、索引构建、数据查询的具体处理流程,同时,还会介绍Milvus支持的索引类型;另外,还将讲述如何定义字段和集合Schema。数据与索引的处理流程数据写入用户可以为每个 collection 指定 shard 数量,每个 shard 对应一个虚拟通道 (vchannel)。如下图所示,在日志代理( log broker)内,每个 vchannel 被分配了一个
本文将介绍 Milvus 系统中数据写入、索引构建、数据查询的具体处理流程,同时,还会介绍Milvus支持的索引类型;另外,还将讲述如何定义字段和集合Schema。
数据与索引的处理流程
数据写入
用户可以为每个 collection 指定 shard 数量,每个 shard 对应一个虚拟通道 (vchannel)。如下图所示,在日志代理( log broker)内,每个 vchannel 被分配了一个对应的物理通道(pchannel)。Proxy 基于主键哈希决定输入的增删请求进入哪个 shard。
由于没有复杂事务,DML 的检查与确认工作被提前至 Proxy。对于所有的增删请求,Proxy 会先通过请求位于 root coord 的 TSO 中心授时模块获取时间戳。这个时间戳决定了数据最终可见和相互覆盖的顺序。除了分配时间戳,Proxy 也为每行数据分配全局唯一的 Primary key。
Primary key 以及 entity 所处的 segmentID 均从 data coord 批量获取,批量有助于提升系统的吞吐,降低 data coord 的负载。
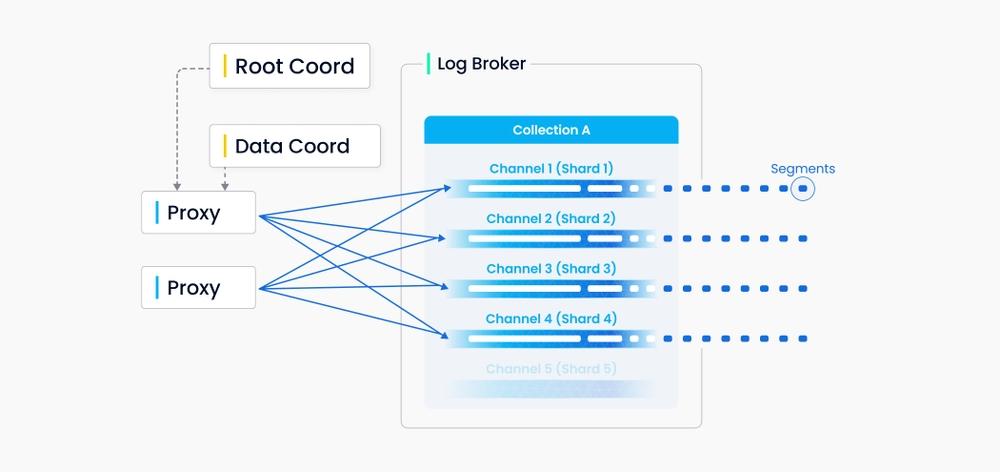
除增删类操作之外,数据定义类操作也会写⼊⽇志序列(Log sequence)。由于数据定义类操作出现的频率很低,系统只为其分配一路 channel。
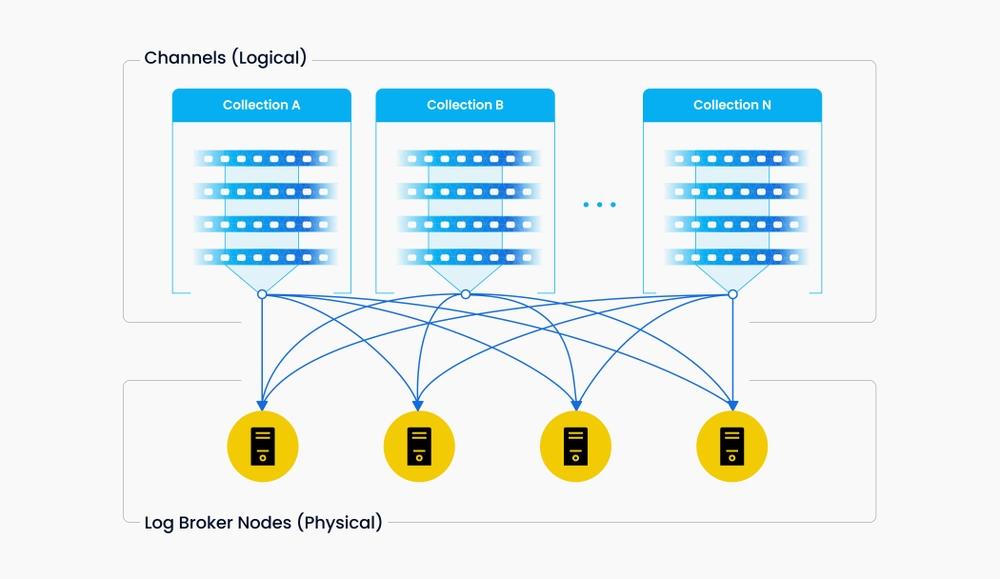
虚拟通道 (vchannel)在底层日志代理节点中维护。不同虚拟通道 (vchannel)可以被调度到不同的物理节点,但每个 channel 在物理上不再进一步拆分,因此单个 vchannel 不会跨多个物理节点。
当 collection 写入出现瓶颈时,通常需要关注两个问题:一是 log broker 节点负载是否过高,是否需要扩容;二是 shard 是否足够多,保证每个 log broker 的负载足够均衡。
 ]
]
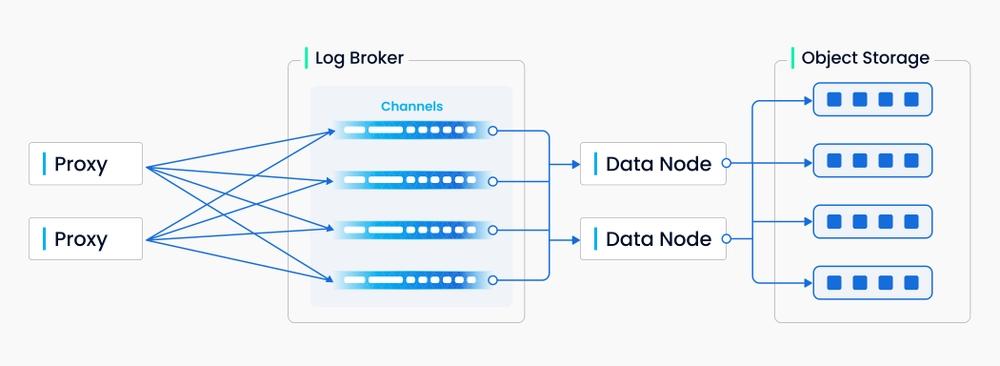
上图总结了日志序列的写⼊过程中涉及的四个组件:Proxy、log broker、data node 和对象存储。 整体共四部分工作:DML 请求的检查与确认、日志序列的发布订阅、流式日志到日志快照的转换、日志快照的持久化存储。
在 Milvus 2.0 中,对这四部分工作进行了解耦,做到同类型节点之间的对等。面向不同的⼊库负载,特别是大规模⾼波动的流式负载,各环节的系统组件可以做到独立的弹性伸缩。
索引构建
构建索引的任务由 index node 执⾏。为了避免数据更新导致的索引频繁重复构建,Milvus 将 collection 分成了更⼩的粒度,即 segment,每个 segment 对应自己的独立的索引。
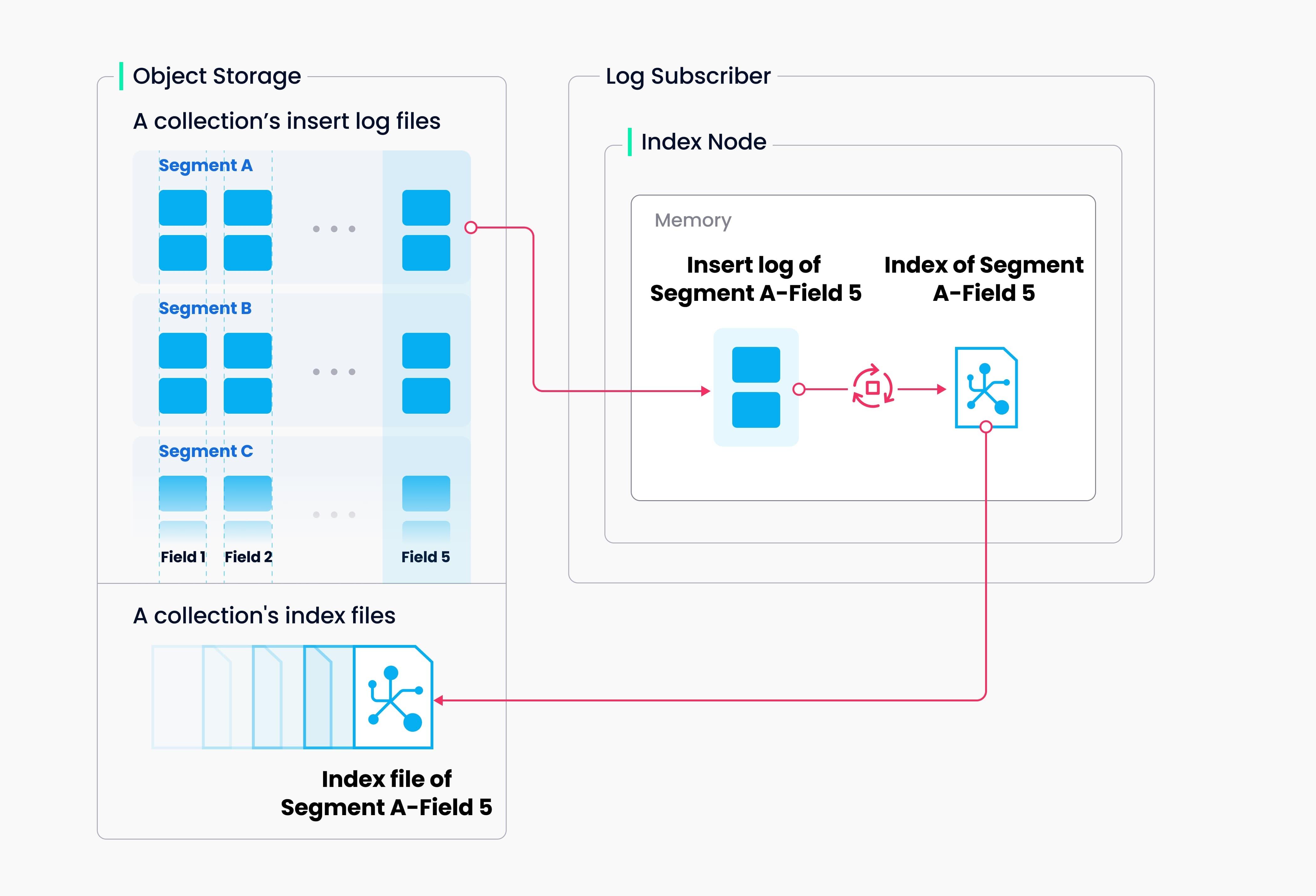
Milvus 可以对每个向量列、标量列和主键列构建索引。索引构建任务的输⼊与输出都是对象存储。Index node 拉取 segment 中需要构建索引的日志快照,在内存中进⾏数据与元信息的反序列化,构建索引。索引构建完成后,将索引结构序列化并写回对象存储。
对向量构建索引的过程属于计算密集、访存密集的负载类型,主要操作是向量运算与矩阵运算。由于被索引的数据维度过高,难以通过传统的树形结构进行高效索引。目前较为成熟的技术是基于聚类或图来表示高维稠密向量的近邻关系。无论哪种索引类型,都涉及到大规模向量数据的多次迭代计算,如寻找聚类、图遍历的收敛状态。
与传统的索引操作相比,向量计算需要充分利⽤ SIMD 加速。目前,Milvus 内置的引擎支持 SSE、AVX2、AVX512 等 SIMD 指令。向量索引任务具备突发性、高资源消耗等特点,其弹性能力对于成本格外重要。未来 Milvus 会继续探索异构计算和 serverless 架构,持续优化索引构建的成本。
同时,Milvus 支持标量过滤和主键查询功能。为了实现高效率的标量查询,Milvus 构建了 Bloom filter index、hash index、tree index 和倒排索引( inverted index)。未来 Milvus 会逐渐完善索引类型,提供 bitmap index、rough index 等更多外部索引能力。
数据查询
数据查询指在一个指定 collection 中查找与目标向量最近邻的 k 个向量或满足距离范围的全部向量的过程。结果返回满足条件的向量及其对应的 primary key 和 field。
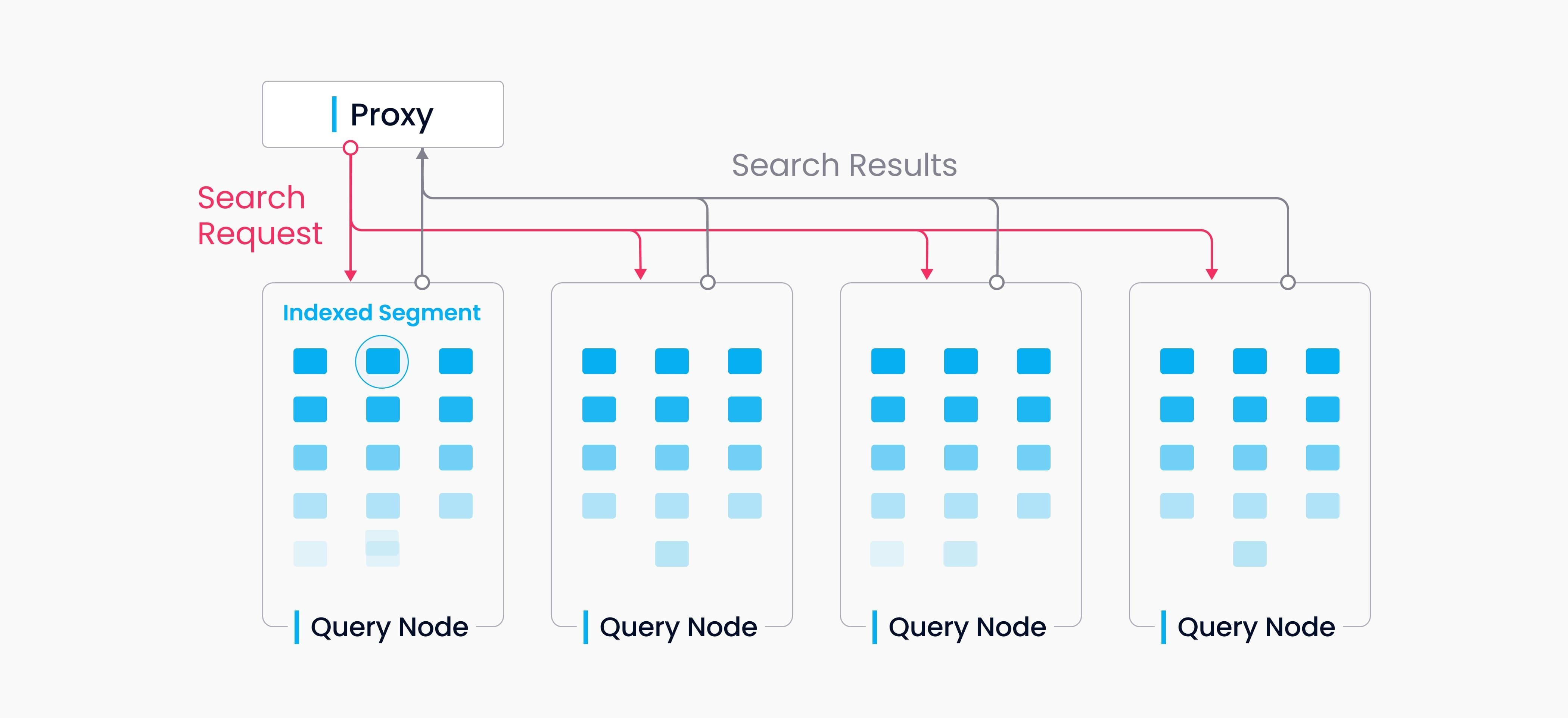
一个 collection 中的数据被分为多个 segment,query node 以 segment 为粒度加载索引。查询请求会广播到全部的 query node,所有 query node 并发执行查询。每个 query node 各自对本地的 segment 进行剪枝并搜索符合条件的数据,同时将各 segment 结果进行聚合返回。
上述过程中 query node 并不感知其他 query node 的存在,每个 query node 只需要完成两件任务:首先是响应 query coord 的调度,加载/卸载 segment;其次是根据本地的 segment 响应查询请求。Proxy 负责将每个 query node 返回的数据进行全局聚合返回给客户端。
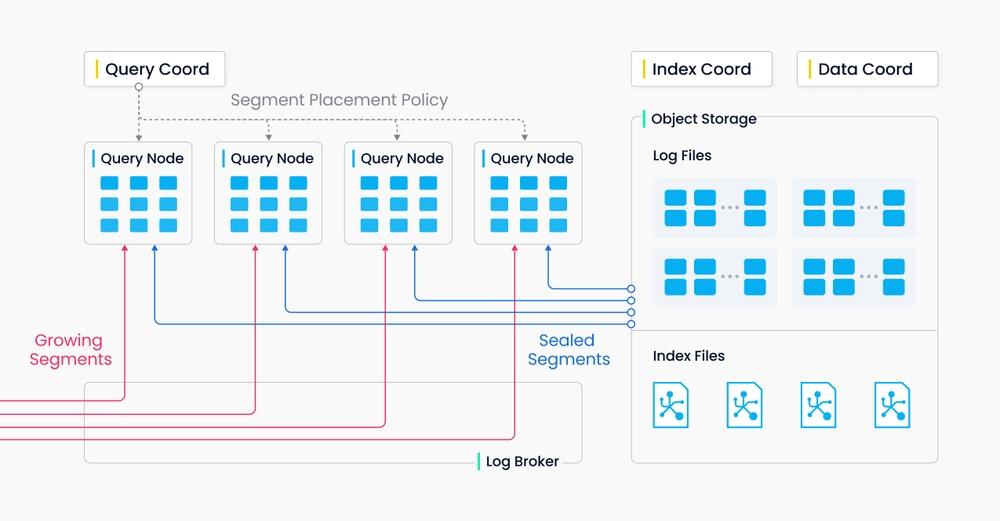
Query node 中的 segment 只存在两种状态,分别对应增量数据(growing)和历史数据(sealed)。对于 growing segment,query node 通过订阅 vchannel 获取数据的近期更新。
当 data coord 已经 flush 完该 segment 的所有数据,会通知 query coord 进行 handoff 操作,将增量数据转换为历史数据。
Sealed segment 的索引由 index node 构建完成后会被 query node 自动加载。对于 sealed segment,query coord 会综合考虑内存使用、CPU 开销、segment 数目等因素,尽可能均匀分配给所有的 query node。
Milvus 支持哪些索引类型及距离计算公式?
创建索引是一个组织数据的过程,是向量数据库实现快速查询百万、十亿、甚至万亿级数据集所依赖的一个巨大组成部分。在查询或检索数据前,必须先指定索引类型及距离计算公式。如未指定索引类型,Milvus 将默认执行暴力搜索。
相似性搜索引擎的工作原理是将输入的对象与数据库中的对象进行比较,找出与输入最相似的对象。索引是有效组织数据的过程,极大地加速了对大型数据集的查询,在相似性搜索的实现中起着重要作用。对一个大规模向量数据集创建索引后,查询可以被路由到最有可能包含与输入查询相似的向量的集群或数据子集。在实践中,这意味着要牺牲一定程度的准确性来加快对真正的大规模向量数据集的查询。
为提高查询性能,你可以为每个向量字段指定一种索引类型。目前,一个向量字段仅支持一种索引类型。切换索引类型时,Milvus 自动删除之前的索引。
注意:
默认设定下,Milvus 不会对插入的数据少于 1024 行的 segment 创建索引。如修改此项参数,需修改
milvus.yaml中的rootCoord.minSegmentSizeToEnableIndex配置项。
索引创建机制
当 create_index 方法被调用时,Milvus 会同步为这个字段的现有数据创建索引。Segment 是 Milvus 中储存数据的最小单位。在建立索引时,Milvus 为每个 Segment 单独创建索引文件。
索引类型
Milvus 目前支持的向量索引类型大都属于 ANNS(Approximate Nearest Neighbors Search,近似最近邻搜索)。
ANNS 的核心思想是不再局限于只返回最精确的结果项,而是仅搜索可能是近邻的数据项,即以牺牲可接受范围内的精度的方式提高检索效率。
根据实现方式,ANNS 向量索引可分为五大类:
- 基于树的索引
- 基于图的索引
- 基于哈希的索引
- 基于量化的索引
- 基于量化和图的索引
Milvus 支持的索引类型如下,我们可以根据应用场景选择具体的索引:
-
FLAT:适用于需要 100% 召回率且数据规模相对较小(百万级)的向量相似性搜索应用。
-
IVF_FLAT:基于量化的索引,适用于追求查询准确性和查询速度之间理想平衡的场景(高速查询、要求高召回率)
-
IVF_SQ8:基于量化的索引,适用于磁盘或内存、显存资源有限的场景(高速查询、磁盘和内存资源有限、接受召回率的小幅妥协)
-
IVF_PQ:基于量化的索引,适用于追求高查询速度、低准确性的场景(超高速查询、磁盘和内存资源有限、接受召回率的实质性妥协)
-
HNSW:基于图的索引,适用于追求高查询效率的场景(高速查询、要求尽可能高的召回率、内存资源大的情景)
-
ANNOY:基于树的索引,适用于追求高召回率的场景(低维向量空间)
-
IVF_HNSW:基于量化和图的索引,高速查询、需要尽可能高的召回率、内存资源大的情景
-
RHNSW_FLAT:基于量化和图的索引,高速查询、需要尽可能高的召回率、内存资源大的情景
-
RHNSW_SQ:基于量化和图的索引,高速查询、磁盘和内存资源有限、接受召回率的小幅妥协
-
RHNSW_PQ:基于量化和图的索引,超高速查询、磁盘和内存资源有限、接受召回率的实质性妥协
距离计算公式
Milvus 基于不同的距离计算方式比较向量间的距离。根据插入数据的形式,选择合适的距离计算方式能极大地提高数据分类和聚类性能。
浮点型向量主要使用以下距离计算公式:
- 欧氏距离 (L2): 主要运用于计算机视觉领域。
- 内积 (IP): 主要运用于自然语言处理(NLP)领域。
二值型向量主要使用以下距离计算公式:
- 汉明距离 (Hamming): 主要运用于自然语言处理(NLP)领域。
- 杰卡德距离 (Jaccard): 主要运用于化学分子式检索领域。
- 谷本距离 (Tanimoto): 主要运用于化学分子式检索领域。
- 超结构 (Superstructure): 主要运用于检索化学分子式的相似超结构。
- 子结构 (Substructure): 主要运用于检索化学分子式的相似子结构。
Milvus 目前支持的距离计算方式与数据格式、索引类型之间的兼容关系以下表格所示。
| 数据格式 | 距离计算方式 | 索引类型 |
|---|---|---|
| 浮点型向量 | 欧氏距离 (L2) 内积 (IP) | FLAT IVF_FLAT IVF_SQ8 IVF_PQ HNSW IVF_HNSW RHNSW_FLAT RHNSW_SQ RHNSW_PQ ANNOY |
| 二值型向量 | 杰卡德距离 (Jaccard) 谷本距离 (Tanimoto) 汉明距离 (Hamming) | BIN_FLAT BIN_IVF_FLA |
| 二值型向量 | 超结构 (superstructure) 子结构 (substructure) | BIN_FLAT |
Schema
字段Schema
字段Schema是字段的逻辑定义。 这是在定义集合Schema和创建集合之前需要去定义的。
注:Milvus 2.0 只支持一个集合中的一个主键字段。
字段 schema 属性
| 属性 | 描述 | 注释 |
|---|---|---|
| name | 集合中字段的名称 | 数据类型:String。必须的 |
| dtype | 字段的数据类型 | 必须的 |
| description | 字段的描述 | 数据类型: String。可选的 |
| is_primary | 是否将该字段设置为主键字段 | 数据类型: Boolean (true or false)。 主键字段为必填项 |
| dim | 向量的维数 | 数据类型: Integer ∈[1, 32768]。对于向量字段是必需的 |
创建一个字段 schema
from pymilvus import FieldSchema
# 主键
id_field = FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, description="primary id")
age_field = FieldSchema(name="age", dtype=DataType.INT64, description="age")
embedding_field = FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=128, description="vector")
字段支持的数据类型
DataType 定义字段包含的数据类型。 不同的字段支持不同的数据类型。
- 主键字段支持的数据类型:
- INT8: numpy.int8
- INT16: numpy.int16
- INT32: numpy.int32
- INT64: numpy.int64
- 标量字段支持的数据类型:
- BOOL: Boolean (
trueorfalse) - INT8: numpy.int8
- INT16: numpy.int16
- INT32: numpy.int32
- INT64: numpy.int64
- FLOAT: numpy.float32
- DOUBLE: numpy.double
- BOOL: Boolean (
- 向量字段支持的数据类型:
- BINARY_VECTOR: Binary vector
- FLOAT_VECTOR: Float vector
集合 Schema
集合 schema 是 集合 的逻辑定义。通常你需要在定义 集合 schema 和创建集合之前定义字段 schema。
集合 schema 的属性
| 属性 | 描述 | 备注 |
|---|---|---|
| field | 要创建的 collection 中的 field | 强制 |
| description | collection 描述 | 数据类型:String。 可选 |
| auto_id | 是否启用自动分配 ID (即 primary key) | 数据类型:Boolean (true 或 false)。 可选 |
创建一个集合 schema
先定义字段 schema,再定义集合 schema。
from pymilvus import FieldSchema, CollectionSchema
id_field = FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, description="primary id")
age_field = FieldSchema(name="age", dtype=DataType.INT64, description="age")
embedding_field = FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=128, description="vector")
schema = CollectionSchema(fields=[id_field, age_field, embedding_field], auto_id=False, description="desc of a collection")
使用指定的 schema 创建集合:
from pymilvus import Collection
collection_name1 = "tutorial_1"
collection1 = Collection(name=collection_name1, schema=schema, using='default', shards_num=2)
注意: 你可以使用 shards_num 参数定义分片编号,并通过在 using 中指定别名来定义您希望在哪个 Milvus 服务器中创建集合。
你也可以使用 Collection.construct_from_dataframe 自动从 DataFrame 生成一个 collection schema 并创建一个 collection。
import pandas as pd
df = pd.DataFrame({
"id": [i for i in range(nb)],
"age": [random.randint(20, 40) for i in range(nb)],
"embedding": [[random.random() for _ in range(dim)] for _ in range(nb)]
})
collection, ins_res = Collection.construct_from_dataframe(
'my_collection',
df,
primary_field='id',
auto_id=False
)

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)