
day01 --- hadoop
学习链接hadoop数据量呈指数增长(硬盘容量不断提升),但是硬盘的访问速度并未与时俱进有非常大的提升什么是hadoopHadoop是Apache旗下一个开源框架,用来开发与运行分布式应用程序来处理海量数据(大型数据集),hadoop不是指一个具体的软件或者应用,它是一个编程模型(思想)来处理实际的问题,它提供了一些基础模块或软件为此框架做支撑2 集群环境准备2.1 准备虚拟机克隆或复制 三个虚拟
hadoop
数据量呈指数增长(硬盘容量不断提升),但是硬盘的访问速度并未与时俱进有非常大的提升
什么是hadoop
Hadoop是Apache旗下一个开源框架,用来开发与运行分布式应用程序来处理海量数据(大型数据集),
hadoop不是指一个具体的软件或者应用,它是一个编程模型(思想)来处理实际的问题,它提供了一些基础模块或软件为此框架做支撑
hadoop的核心组件是什么?
- HDFS:分布式存储组件
- MapReduce:分布式计算组件
- Yarn:资源调度管理器
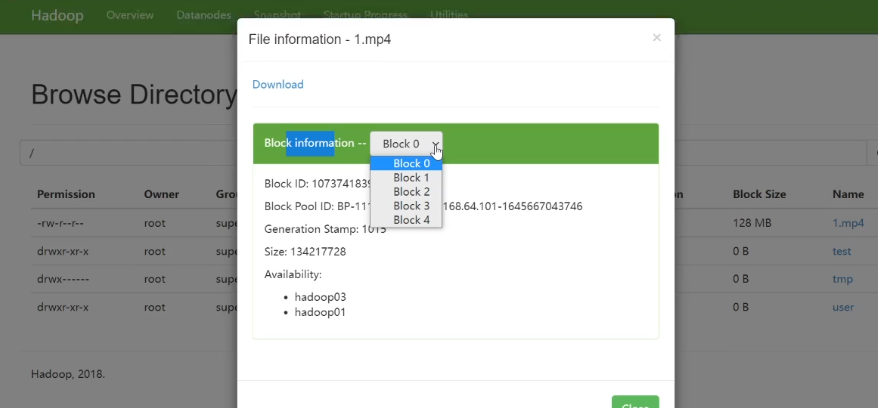
如何理解HDFS 分布式存储?
Block Size =128MB:默认划分的块大小
Size : 实际大小
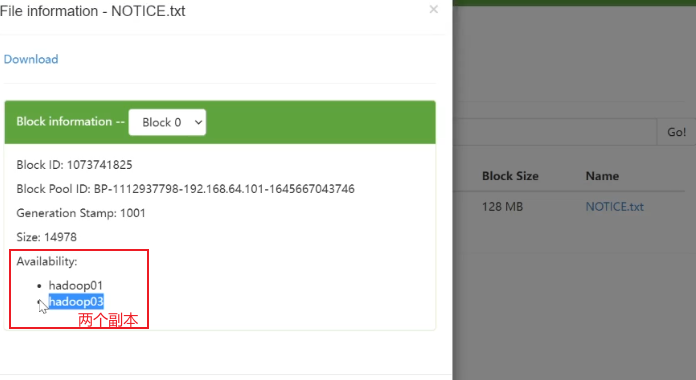
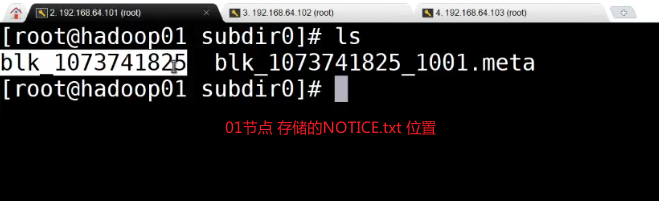
595.48MB存储在5个块中,每个块所在的节点位置分配不同

2 集群环境准备
2.1 准备虚拟机
克隆或复制 三个虚拟机hadoop01、hadoop02、hadoop03均为NAT模式,
其中hadoop01内存设置为1G(16G内存以上建议设置为2G),hadoop02和hadoop03为512M。
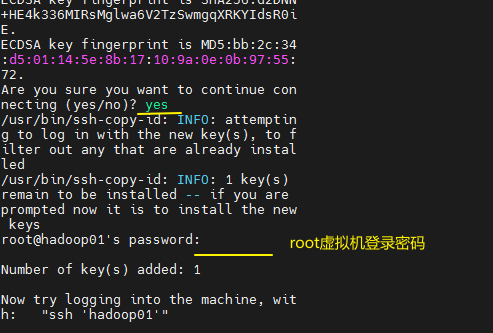
注:虚拟机登录的用户名和密码都是root
hadoop1,hadoop2 2个处理器
hadoop3 4个处理器

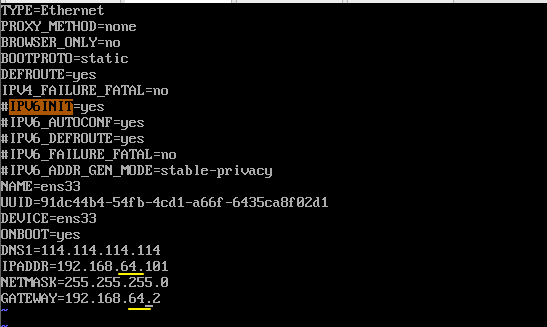
2.2 修改为静态IP
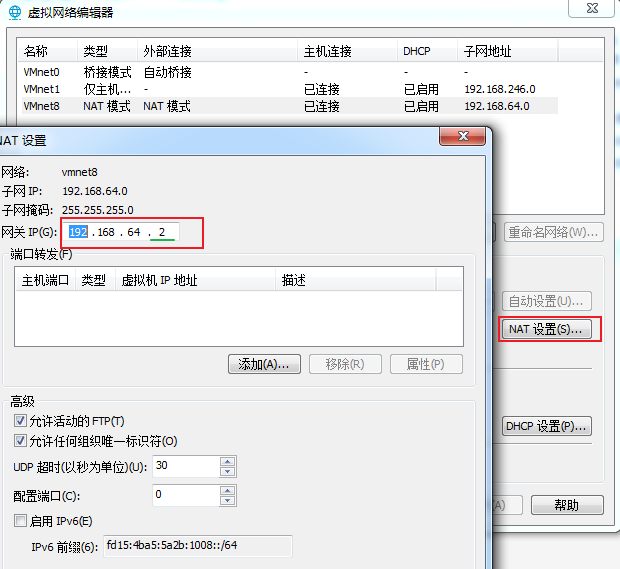
修改IP地址,将:
第一台hadoop01的虚拟机ip地址改为:192.168.64.101
第二台hadoop02的虚拟机ip地址改为:192.168.64.102
第三台hadoop03的虚拟机ip地址改为:192.168.64.103
重启虚拟网卡
二选一
service network restart #重启网络
systemctl restart network.service #重启网络centos7
测试网络
ping www.baidu.com

如上修改hadoop02,hadoop03
2.3 修改系统邮件提示
echo "unset MAILCHECK">> /etc/profile
2.4 关闭NetworkManager,防止网络出错
systemctl stop NetworkManager
systemctl disable NetworkManager
2.5 关闭防火墙,禁止开机自启
systemctl stop firewalld
systemctl disale firewalld
查看防火墙状态
firewall-cmd --state

2.6 修改主机名
分别修改三台主机名 hadoop01,hadoop02,hadoop03
vim /etc/hostname


2.7 修改hosts文件
vim /etc/hosts
2.8 重启 ,测试
reboot
测试
互相 ping

2.9 设置免密登录
三台机器生成公钥与私钥
ssh-keygen
执行该命令之后,按下三个回车即可
拷贝公钥到同一台机器
三台机器执行命令:
ssh-copy-id hadoop01
复制第一台机器的认证到其他机器
将第一台机器的公钥拷贝到其他机器上
在第一台机器上面执行以下命令
## 将keys 发送到hadoop02 的/root节点
scp /root/.ssh/authorized_keys hadoop02:/root/.ssh
scp /root/.ssh/authorized_keys hadoop03:/root/.ssh
scp 远程复制

测试


不需要输入密码直接进入说明成功,exit退出
2.10 三台机器时钟同步
分布式存储 三个节点记录时间一样
通过网络进行时钟同步
通过网络连接外网进行时钟同步,必须保证虚拟机连上外网
基于互联网
基于内部
ntpdate us.pool.ntp.org
阿里云时钟同步服务器
ntpdate ntp4.aliyun.com

三台机器定时任务
crontab -e
*/1 * * * * /usr/sbin/ntpdate us.pool.ntp.org;
或者直接与阿里云服务器进行时钟同步
crontab -e
## 1 每个小时的1分执行,*/1 每隔一分钟
*/1 * * * * /usr/sbin/ntpdate ntp4.aliyun.com;

2.11 三台机器安装jdk
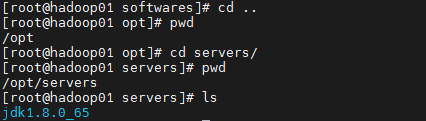
三台机器创建目录 安装,存放路径
所有软件的安装路径
mkdir -p /opt/servers
所有软件压缩包的存放路径
mkdir -p /opt/softwares
上传,解压
解压

配置环境变量
配置环境变量
## /etc/profile 全局配置文件
vim /etc/profile
在最后添加
export JAVA_HOME=/opt/servers/jdk1.8.0_65
export PATH=:$JAVA_HOME/bin:$PATH

修改完成之后记得 source /etc/profile生效
source /etc/profile
发送文件到hadoop02和hadoop03
全路径分发
## 全路径发送
scp -r /opt/servers/jdk1.8.0_65/ hadoop02:/opt/servers/
scp -r /opt/servers/jdk1.8.0_65/ hadoop03:/opt/servers/
相对路径分发
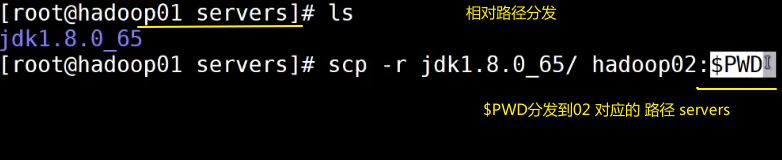
注意:发送完成后要配置环境变量并生效。
scp /etc/profile hadoop02:/etc/
scp /etc/profile hadoop03:/etc/
source /etc/profile
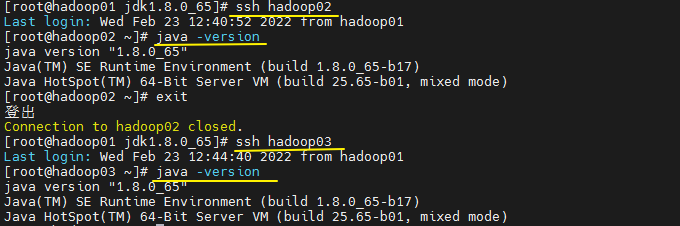
测试
java -version
javac
ssh hadoop02
java -version
ssh hadoop03
java -version
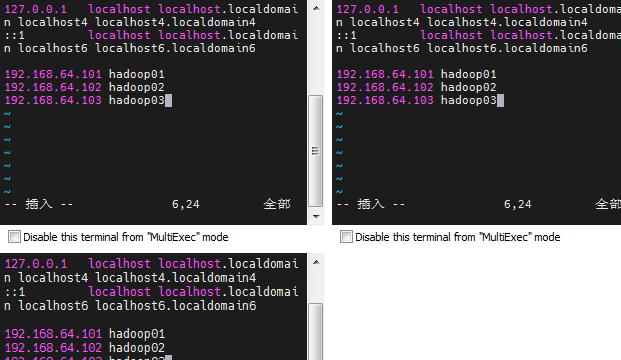
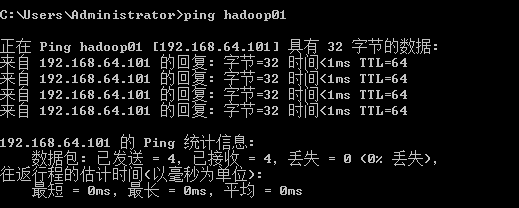
2.12 修改windows中的hosts文件

在windows中的hosts文件里添加如下映射
192.168.64.101 hadoop01
192.168.64.102 hadoop02
192.168.64.103 hadoop03
在cmd 测试能否 ping 通 hadoop01,02,03
3 Hadoop 介绍
https://hadoop.apache.org/
hadoop的定义:hadoop是一个 分布式存储 和 分布式计算 的框架。
分布式存储:是一个数据存储技术,将数据存储在多个服务上的(存储单元)磁盘空间中。目前解决的是大量数据存储的问题。
分布式计算:是一个计算科学技术,将一个大量的计算过程拆分成弱干个小的任务,由多个节点执行,最后做数据汇总。
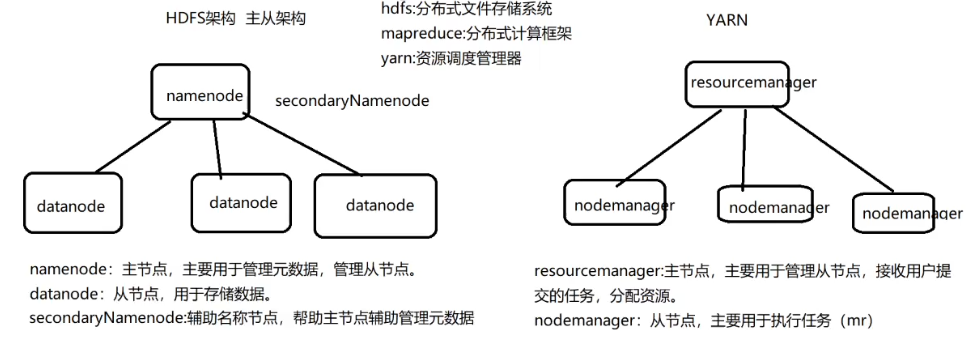
3.1 hadoop的核心组件
HDFS(Hadoop Distributed File System):分布式存储组件
MapReduce:分布式计算组件
Yarn:资源调度管理器

3.2 hadoop2.x架构模型
3.3 Hadoop 的安装有三种方式
-
单机模式:直接解压,只支持MapReduce的测试,不支持HDFS,一般不用。
-
伪分布式模式:单机通过多进程模拟集群方式安装,支持Hadoop所有功能。
优点:功能完整。
缺点:性能低下。学习测试用。 -
完全分布式模式:集群方式安装,生产级别。
HA:高可用。
3.3.1 伪分布式部署
需要环境:
JDK,JAVA_HOME,配置hosts,关闭防火墙,配置免密登录等。
注意:我们只将其安装在hadoop01节点上。
进入目录
cd /opt/softwares
上传安装包并解压
tar -xvzf hadoop-2.7.7.tar.gz -C ../servers/

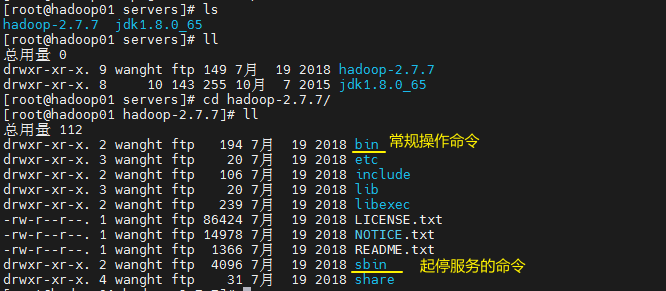
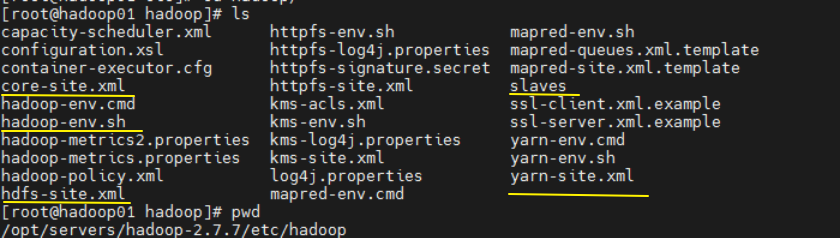
修改配置文件
位置:/opt/servers/hadoop-2.7.7/etc/hadoop
- 修改hadoop-env.sh
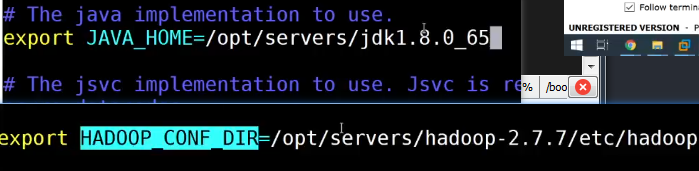
修改vim /opt/servers/hadoop-2.7.7/etc/hadoop/hadoop-env.shexport JAVA_HOME=/opt/servers/jdk1.8.0_65 export HADOOP_CONF_DIR=/opt/servers/hadoop-2.7.7/etc/hadoop

-
修改 core-site.xml
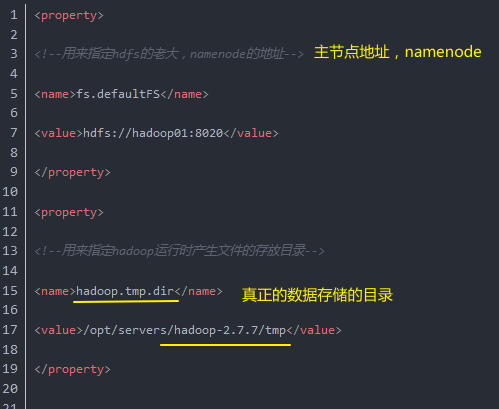
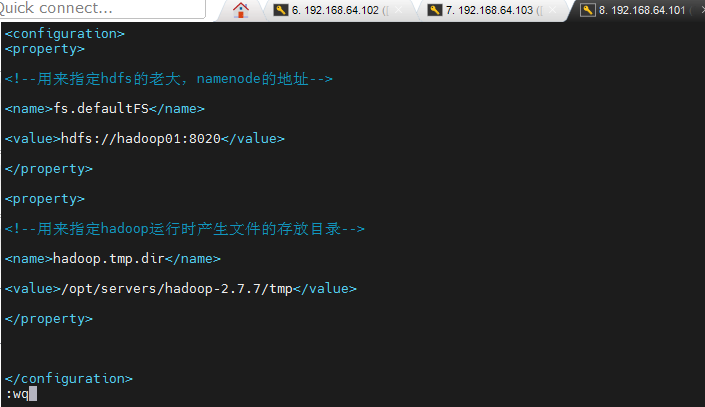
vim /opt/servers/hadoop-2.7.7/etc/hadoop/core-site.xml
增加namenode配置、文件存储位置配置:粘贴代码部分到标签内
- 修改 hdfs-site.xml
vim /opt/servers/hadoop-2.7.7/etc/hadoop/hdfs-site.xml
配置包括自身在内的备份副本数量到标签内
- 修改 mapred-site.xml
说明:在/opt/servers/hadoop-2.7.7/etc/hadoop的目录下,只有一个mapred-site.xml.template文件,复制一个。
cp mapred-site.xml.template mapred-site.xml
vim /opt/servers/hadoop-2.7.7/etc/hadoop/mapred-site.xml

配置mapreduce运行在yarn上:粘贴高亮部分到标签内
<property>
<!--指定mapreduce运行在yarn上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
- 修改 yarn-site.xml
vim /opt/servers/hadoop-2.7.7/etc/hadoop/yarn-site.xml
配置:粘贴高亮部分到标签内
<property>
<!--指定yarn的老大resourcemanager的地址-->
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<!--NodeManager获取数据的方式-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
- 修改slaves
vim /opt/servers/hadoop-2.7.7/etc/hadoop/slaves
修改为
hadoop01
- 配置hadoop的环境变量
vim /etc/profile
放在最后
export HADOOP_HOME=/opt/servers/hadoop-2.7.7
export PATH=:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
配置完成之后生效
source /etc/profile

环境变量配置完成,测试环境变量是否生效
echo $HADOOP_HOME
启动
初始化
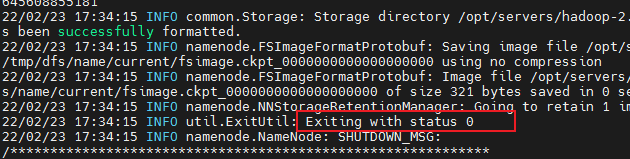
hdfs namenode -format
启动
start-all.sh
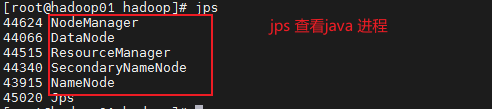
3.3.2 完全分布式部署
以下是在伪分布式部署基础下修改的
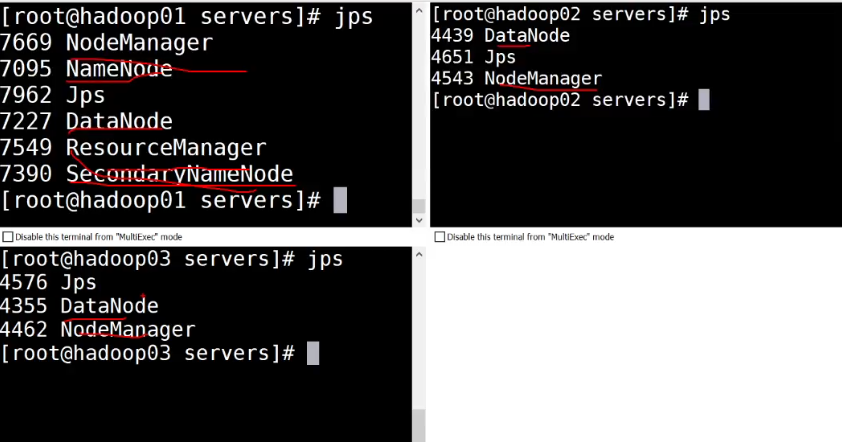
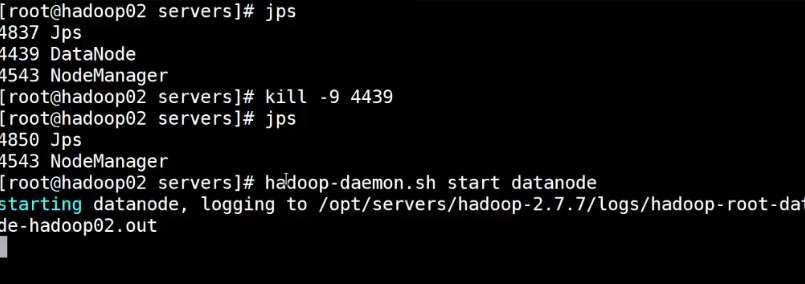
jps 有服务先停止全部服务 stop-all.sh
修改配置文件 hdfs-site.xml (副本数改为2),slaves(添加02,03节点)
分发,配置环境变量
初始化,启动
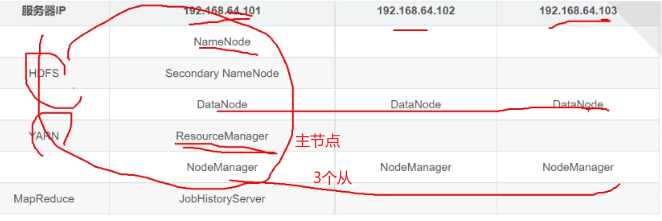
检查服务

修改配置文件 hdfs-site.xml ,slaves
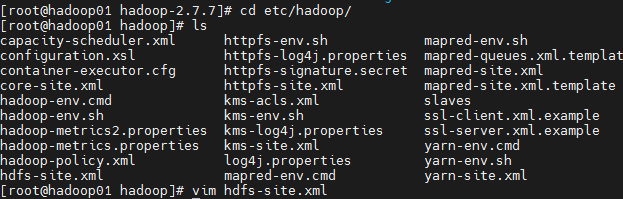
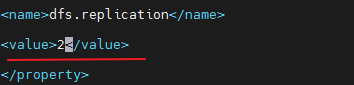

分发到02,03节点

cd /opt/servers/
scp -r hadoop-2.7.7/ hadoop02:$PWD
scp -r hadoop-2.7.7/ hadoop03:$PWD
hadoop02、hadoop03服务器配置hadoop的环境变量

02,03文件生效
source

启动
初始化
hdfs namenode -format
启动服务
start-all.sh
访问:
http://hadoop01:50070/
http://hadoop01:8088/
3.4 hadoop集群初体验
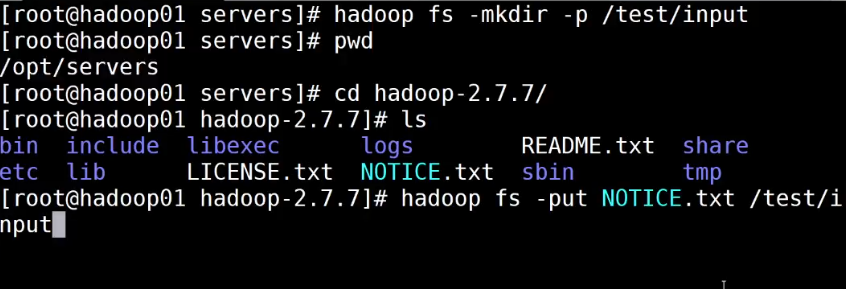
- hdfs:put
- mapreduce:圆周率计算
3.4.1 伪分布式部署
分布式存储
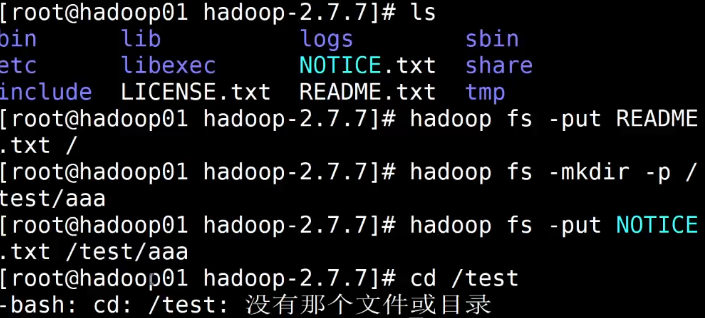
hadoop fs -put README.txt /
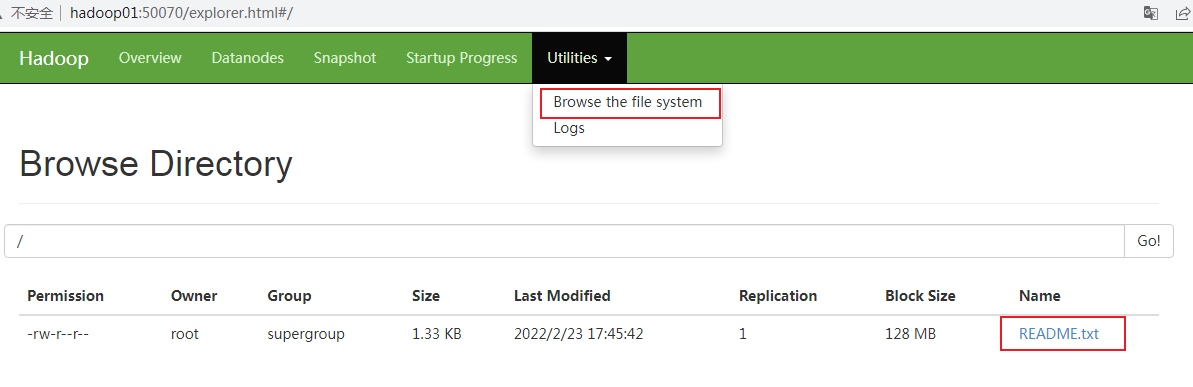
存储路径是虚拟路径
分布式计算
mapreduce
计算圆周率
##
hadoop jar /opt/servers/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar pi 2 5

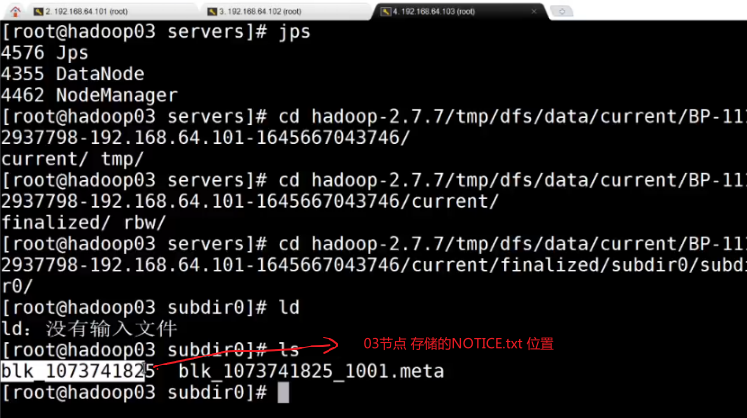
3.4.2 完全分布式部署测试体验


瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)