oracle中行列转换总结
oracle中行列转换1.行列转换包括以下六种情况:2. 列转行2.1 UNION ALL2.2 MODEL2.3 COLLECTION2.4 UNPIVOT3. 行转列3.1 AGGREGATE FUNCTION3.2 PIVOT4 字符串的行列转换4.1 多行转字符串4.2 字符串转多列4.3字符串转多行4.4 wm_concat函数整理了部分来自论坛及博客关于行列转换的案例,待以备查1.行列
oracle中行列转换
整理了部分来自论坛及博客关于行列转换的案例,待以学习与备查
1.行列转换包括以下六种情况:
- 列转行
- 行转列
- 多列转换成字符串
- 多行转换成字符串
- 字符串转换成多列
- 字符串转换成多行
下面分别进行举例介绍。
首先声明一点,有些例子需要如下 10g 及以后才有的知识:
A. 掌握 model 子句
B. 正则表达式
C. 加强的层次查询
讨论的适用范围只包括 8i,9i,10g 及以后版本。
2. 列转行
CREATE TABLE t_col_row( ID INT,
c1 VARCHAR2(10), c2 VARCHAR2(10), c3 VARCHAR2(10));
INSERT INTO t_col_row VALUES (1, 'v11', 'v21', 'v31'); INSERT INTO t_col_row VALUES (2, 'v12', 'v22', NULL); INSERT INTO t_col_row VALUES (3, 'v13', NULL, 'v33'); INSERT INTO t_col_row VALUES (4, NULL, 'v24', 'v34'); INSERT INTO t_col_row VALUES (5, 'v15', NULL, NULL);
INSERT INTO t_col_row VALUES (6, NULL, NULL, 'v35'); INSERT INTO t_col_row VALUES (7, NULL, NULL, NULL); COMMIT;
SELECT * FROM t_col_row;
2.1 UNION ALL
适用范围:8i,9i,10g 及以后版本
SELECT id, 'c1' cn, c1 cv
FROM t_col_row
UNION ALL
SELECT id, 'c2' cn, c2 cv
FROM t_col_row
UNION ALL
SELECT id, 'c3' cn, c3 cv FROM t_col_row;
若空行不需要转换,只需加一个 where 条件,
WHERE COLUMN IS NOT NULL 即可。
2.2 MODEL
适用范围:10g 及以后
SELECT id, cn, cv FROM t_col_row
MODEL
RETURN UPDATED ROWS PARTITION BY (ID) DIMENSION BY (0 AS n)
MEASURES ('xx' AS cn,'yyy' AS cv,c1,c2,c3) RULES UPSERT ALL
(
cn[1] = 'c1', cn[2] = 'c2', cn[3] = 'c3', cv[1] = c1[0], cv[2] = c2[0], cv[3] = c3[0]
)
ORDER BY ID,cn;
2.3 COLLECTION
适用范围:8i,9i,10g 及以后版本
要创建一个对象和一个集合:
CREATE TYPE cv_pair AS OBJECT(cn VARCHAR2(10),cv VARCHAR2(10)); CREATE TYPE cv_varr AS VARRAY(8) OF cv_pair;
SELECT id, t.cn AS cn, t.cv AS cv
FROM t_col_row,
TABLE(cv_varr(cv_pair('c1', t_col_row.c1), cv_pair('c2', t_col_row.c2), cv_pair('c3', t_col_row.c3))) t
ORDER BY 1, 2;
2.4 UNPIVOT
适用范围:11g 及以后版本
假设有表student
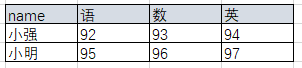
SELECT *
FROM student1
UNPIVOT (
score FOR subject IN ("语","数","英")
)
得到结果
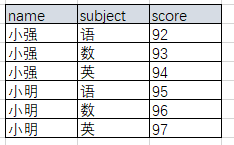
同样使用一下方法也可以得到上面结果
SELECT
NAME,
'语' AS subject ,
MAX("语") AS score
FROM student1 GROUP BY NAME
UNION
SELECT
NAME,
'数' AS subject ,
MAX("数") AS score
FROM student1 GROUP BY NAME
UNION
SELECT
NAME,
'英' AS subject ,
MAX("英") AS score
FROM student1 GROUP BY NAME
3. 行转列
CREATE TABLE t_row_col AS SELECT id, 'c1' cn, c1 cv
FROM t_col_row
UNION ALL
SELECT id, 'c2' cn, c2 cv
FROM t_col_row
UNION ALL
SELECT id, 'c3' cn, c3 cv FROM t_col_row; SELECT * FROM t_row_col ORDER BY 1,2;
3.1 AGGREGATE FUNCTION
适用范围:8i,9i,10g 及以后版本
SELECT id,
MAX(decode(cn, 'c1', cv, NULL)) AS c1, MAX(decode(cn, 'c2', cv, NULL)) AS c2, MAX(decode(cn, 'c3', cv, NULL)) AS c3
FROM t_row_col GROUP BY id ORDER BY 1;
MAX 聚集函数也可以用 sum、min、avg 等其他聚集函数替代。 被指定的转置列只能有一列,但固定的列可以有多列,请看下面的例子:
SELECT mgr, deptno, empno, ename FROM emp ORDER BY 1, 2;
3.2 PIVOT
适用范围:11g 及以后版本
有表
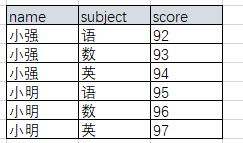
SELECT *
FROM student
PIVOT (
SUM(score) FOR subject IN (语, 数, 英)
)
得到结果

PIVOT 后跟一个聚合函数来拿到结果,FOR 后面跟的科目是我们要转换的列,这样的话科目中的语文、数学、英语就就被转换为列。IN 后面跟的就是具体的科目值。
也可以用 CASE WHEN 得到同样的结果,但没有 PIVOT 简单直观,具体如下
SELECT name,
MAX(
CASE
WHEN subject='语'
THEN score
ELSE 0
END) AS "语",
MAX(
CASE
WHEN subject='数'
THEN score
ELSE 0
END) AS "数",
MAX(
CASE
WHEN subject='英'
THEN score
ELSE 0
END) AS "英"
FROM student
GROUP BY name
以上提到的Pivot 为 SQL 语言增添了一个非常重要且实用的功能。您可以使用 pivot 函数针对任何关系表创建一个交叉表报表,而不必编写包含大量 decode 函数的令人费解的、不直观的代码。同样,您可以使用 unpivot 操作转换任何交叉表报表,以常规关系表的形式对其进行存储。Pivot 可以生成常规文本或 XML 格式的输出。如果是 XML 格式的输出,您不必指定 pivot 操作需要搜索的值域
4 字符串的行列转换
4.1 多行转字符串
这个比较简单,用||或concat函数可以实现
select concat(id,username) str from app_user
select id||username str from app_user
4.2 字符串转多列
实际上就是拆分字符串的问题,可以使用 substr、instr、regexp_substr函数方式
4.3字符串转多行
使用union all函数等方式
4.4 wm_concat函数
10G提供该函数wm_concat(列名),该函数可以把列值以","号分隔起来,并显示成一行
例子如下:准备测试数据
create table test(id number,name varchar2(20));
insert into test values(1,'a');
insert into test values(1,'b');
insert into test values(1,'c');
insert into test values(2,'d');
insert into test values(2,'e');
效果1 : 行转列 ,默认逗号隔开
select wm_concat(name) name from test;

效果2: 把结果里的逗号替换成"|"
select replace(wm_concat(name),',','|') from test;
效果3: 按ID分组合并name
select id,wm_concat(name) name from test group by id;

4.4 LISTAGG
Oracle11.2新增了LISTAGG函数,可以用于字符串聚集,实现对列值的拼接

官方文档的解释如下:
For a specified measure, LISTAGG orders data within each group specified in the ORDER BY clause and then concatenates the values of the measure column.
即在每个分组内,LISTAGG根据order by子句对列植进行排序,将排序后的结果拼接起来。
measure_expr:可以是任何基于列的表达式。
delimiter:分隔符,默认为NUL
order_by_clause:order by子句决定了列值被拼接的顺序。
通过该用法,可以看出LISTAGG函数不仅可作为一个普通函数使用,也可作为分析函数。
order_by_clause和query_partition_clause的用法如下:


4.4.1普通函数
对工资进行排序,用逗号进行拼接。
SQL> select listagg(ename,',')within group(order by sal)name from emp;
NAME
---------------------------------------------------------------------------------------------------
SMITH,JAMES,ADAMS,MARTIN,WARD,MILLER,TURNER,ALLEN,CLARK,BLAKE,JONES,FORD,SCOTT,KING
4.4.2 分组函数
SQL> select deptno,listagg(ename,',')within group(order by sal)name from emp group by deptno;
DEPTNO NAME
---------- ----------------------------------------------------------------------------------------------------
10 MILLER,CLARK,KING
20 SMITH,ADAMS,JONES,FORD,SCOTT
30 JAMES,MARTIN,WARD,TURNER,ALLEN,BLAKE
4.4.3 分析函数
SQL> select deptno,ename,sal,listagg(ename,',')within group(order by sal)over(partition by deptno)name from emp;
DEPTNO ENAME SAL NAME
---------- ---------- ---------- ----------------------------------------
10 MILLER 1300 MILLER,CLARK,KING
10 CLARK 2450 MILLER,CLARK,KING
10 KING 5000 MILLER,CLARK,KING
20 SMITH 800 SMITH,ADAMS,JONES,SCOTT,FORD
20 ADAMS 1100 SMITH,ADAMS,JONES,SCOTT,FORD
20 JONES 2975 SMITH,ADAMS,JONES,SCOTT,FORD
20 SCOTT 3000 SMITH,ADAMS,JONES,SCOTT,FORD
20 FORD 3000 SMITH,ADAMS,JONES,SCOTT,FORD
30 JAMES 950 JAMES,MARTIN,WARD,TURNER,ALLEN,BLAKE
30 MARTIN 1250 JAMES,MARTIN,WARD,TURNER,ALLEN,BLAKE
30 WARD 1250 JAMES,MARTIN,WARD,TURNER,ALLEN,BLAKE
30 TURNER 1500 JAMES,MARTIN,WARD,TURNER,ALLEN,BLAKE
30 ALLEN 1600 JAMES,MARTIN,WARD,TURNER,ALLEN,BLAKE
30 BLAKE 2850 JAMES,MARTIN,WARD,TURNER,ALLEN,BLAKE
14 rows selected.
4.5 XMLAGG
xmlagg函数需要将输入的值转换为xml,处理返回结果也是xml,最后再用getclobval()获取colb类型的结果。当查询结果过长,拼接的字符串长度过长大于4000字节,我们可以使用这个函数,函数返回结果为CLOB类型,大对象数据类型。最大可以存储4GB的数据长度。
语法:
- xmlagg(xmlelement(e, 合并字段, ‘,’).extract(‘//text()’)).getclobval()
- xmlagg(xmlparse(content 合并字段 ||’,’ wellformed) order by 排序字段).getclobval()
select t.nation,rtrim(xmlagg(xmlelement(e,t.city,',').extract('//text()')).getclobval(),',') as citys
from a_test t
group by t.nation;
---结果中的聚合字段是CLOB类型,是文本字符。
---处理400多万条数据,运行时间是20分钟
特别要注意非聚合字段是null的情况,这是导致聚合字段过长的主要原因。
select t.nation,xmlagg(xmlparse(content t.city || ',' wellformed) order by t.nation).getclobval()
from a_test t
group by t.nation;
---结果汇总的聚合字段也是clob类型,不过是hex字节;
---处理400多万条数据,运行时间是56秒
select xmlagg(xmlparse(content t.a||',' wellformed) order by t.at.a).getclobval()
from table t;--基础写法

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)