
社区发现算法——LPA与SLPA算法
LPA(Label Propagation Algorithm)LPA算法是2002年由zhu等提出的,在2007年被Usha、Nandini、Raghavan应用到了社区发现领域,提出了RAK算法。但是大部分研究者称RAK算法为LPA算法。LPA是一种基于标签传播的局部社区划分。对于网络中的每一个节点,在初始阶段,Label Propagation算法对于每一个节点都会初始化一个唯一的一个标签。
LPA(Label Propagation Algorithm)
LPA算法是2002年由zhu等提出的,在2007年被Usha、Nandini、Raghavan应用到了社区发现领域,提出了RAK算法。但是大部分研究者称RAK算法为LPA算法。
LPA是一种基于标签传播的局部社区划分。对于网络中的每一个节点,在初始阶段,Label Propagation算法对于每一个节点都会初始化一个唯一的一个标签。每一次迭代都会根据与自己相连的节点所属的标签改变自己的标签,更改的原则是选择与其相连的节点中所属标签最多的社区标签为自己的社区标签,这就是标签传播的含义了。随着社区标签不断传播。最终,连接紧密的节点将有共同的标签。
LPA认为每个结点的标签应该和其大多数邻居的标签相同,将一个节点的邻居节点的标签中数量最多的标签作为该节点自身的标签(bagging思想)。给每个节点添加标签(label)以代表它所属的社区,并通过标签的“传播”形成同一个“社区”内部拥有同一个“标签”。
标签传播算法(LPA)的做法比较简单:
第一步: 为所有节点指定一个唯一的标签;
第二步: 逐轮刷新所有节点的标签,直到达到收敛要求为止。对于每一轮刷新,节点标签刷新的规则如下:
对于某一个节点,考察其所有邻居节点的标签,并进行统计,将出现个数最多的那个标签赋给当前节点。当个数最多的标签不唯一 时,随机选一个。
LPA的一个简单例子
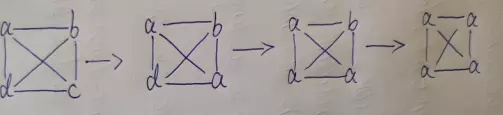
**算法初始化:**a、b、c、d各自为独立的社区;
第一轮标签传播:
一开始c选择了a,因为大家的社区标签都是一样的,所以随机选择了一个;
d也根据自己周围的邻居节点来确定标签数,最多的是a,所以就是d为a了;
**继续标签传播:**以此类推,最后就全部都是a了;
时间复杂度接近线性:对顶点分配标签的复杂度为O(n),每次迭代时间为O( m),找出所有社区的复杂度为O (n +m),但迭代次数难以估计
LPA标签传播分为两种传播方式,同步更新,异步更新。
1. 同步更新
所谓同步更新,即节点z在第t次迭代的label依据于它的邻居节点在第t-1次迭代时所得的label。
对于节点x,在第 t 轮迭代时,根据其所在节点在第t-1代的标签进行更新。也就是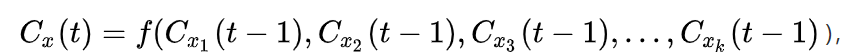
,其中 C x ( t ) C_x(t) Cx(t)表示的就是节点x在第 t 次迭代时的社区标签。函数f表示的就是取参数节点中社区标签最多的。
需要注意的是,这种同步更新的方法会存在一个问题,当遇到二分图的时候,会出现标签震荡,解决的方法就是设置最大迭代次数,提前停止迭代。
2. 异步更新
即节点z在第t次迭代的label依据于第t次迭代已经更新过label的节点和第t次迭代未更新过label的节点在第t-1次迭代时的label。
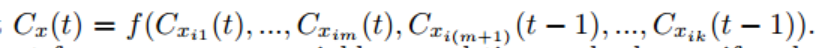
LPA算法优缺点
LPA算法的最大的优点就是算法的逻辑非常简单,相对于优化模块度算法的过程是非常快的。
LPA算法利用自身的网络的结构指导标签传播,这个过程是无需任何的任何的优化函数,而且算法初始化之前是不需要知道社区的个数的,随着算法迭代最后可以自己知道最终有多少个社区。
划分结果不稳定,随机性强是这个算法致命的缺点。具体体现在:
- 每个顶点在初始的时候赋予唯一的标签,即“重要性”相同,而迭代过程又采用随机序列,节点标签更新顺序随机,会导致同一初始状态不同结果甚至巨型社区的出现;
- 随机选择:如果一个节点的出现次数最大的邻居标签不止一个时,随机选择一个标签作为自己标签。这种随机性可能会带来一个雪崩效应,即刚开始一个小小的聚类错误会不断被放大。不过话也说话来,如果相似邻居节点出现多个,可能是weight计算的逻辑有问题,需要回过头去优化weight抽象和计算逻辑。
代码如下:
class LPA:
def __init__(self, G, max_iter=20):
self._G = G
self._n = len(G.nodes(False)) # 节点数目
self._max_iter = max_iter
# 判断是否收敛
def can_stop(self):
# 每个节点的标签和邻近节点最多的标签一样
for i in range(self._n):
node = self._G.nodes[i]
label = node["label"]
max_labels = self.get_max_neighbor_label(i)
if label not in max_labels:
return False
return True
# 获得邻近节点最多的标签
def get_max_neighbor_label(self, node_index):
m = collections.defaultdict(int)
for neighbor_index in self._G.neighbors(node_index):
neighbor_label = self._G.nodes[neighbor_index]["label"]
m[neighbor_label] += 1
max_v = max(m.values())
# 可能多个标签数目相同,这里都要返回
return [item[0] for item in m.items() if item[1] == max_v]
# 异步更新
def populate_label(self):
# 随机访问
visitSequence = random.sample(self._G.nodes(), len(self._G.nodes()))
for i in visitSequence:
node = self._G.nodes[i]
label = node["label"]
max_labels = self.get_max_neighbor_label(i)
# 如果标签不在最大标签集中才更新,否则相同随机选取没有意义
if label not in max_labels:
newLabel = random.choice(max_labels)
node["label"] = newLabel
# 根据标签得到社区结构
def get_communities(self):
communities = collections.defaultdict(lambda: list())
for node in self._G.nodes(True):
label = node[1]["label"]
communities[label].append(node[0])
return communities.values()
def execute(self):
# 初始化标签
for i in range(self._n):
self._G.nodes[i]["label"] = i
iter_time = 0
# 更新标签
while (not self.can_stop() and iter_time < self._max_iter):
self.populate_label()
iter_time += 1
return self.get_communities()
LPA算法改进思路
1:标签随机选择改进
给节点或边添加权重(势函数、模块密度优化、LeaderRank值、局部拓扑信息的相似度、标签从属系数等),信息熵等描述节点的传播优先度,进而初步确定社区中心点以提高社区划分的精度;
这样,在进行邻居节点的最大标签统计的时候,可以将邻居节点的weight权值和节点邻接点的度数等作为参考因素。
2:标签初始化改进
可以提取一些较为紧密的子结构来作为标签传播的初始标签(例如非重叠最小极大团提取算法),或通过初始社区划分算法先确定社区的雏形再进行传播。
3:其它可能改进
- 在社区中寻找不重叠三角形作为起始簇的雏形,以提高算法结果的稳定性和运行效率;
- 添加标签熵属性,在迭代过程中不采用随机序列,而是根据每个节点的标签熵来排序序列;
- 在2的基础上,为了不完全消除标签传播算法的随机性,将排序好的队列平均分成三个部分,在每个部分内,节点进行随机排列。
- 对于同一节点的邻居节点的标签可能存在多种社区最大数目相同的情况,不使用随机方法,而是分析该节点的邻节点的邻节点集标签分布情况来决定该节点的标签
- 在社区中寻找以度最大的若干节点为中心的“雪花型”结构作为起始簇的雏形
在实现的过程中,将上述方案进行组合衍生出更多的可行方案,初步试验结果表明算法的随机性与稳定性很难同时保证,设定起始簇的结构收敛速度快但有可能生成巨型社区;在节点较少的情况下,标签熵的方法准确率和稳定性最好;至于组合方案初步的试验验证发现效果反而下降了。
SLPA(Speaker-listener Label Propagation Algorithm)
SLPA是一种重叠型社区发现算法,其中涉及一个重要阈值参数r,通过r的适当选取,可将其退化为非重叠型.
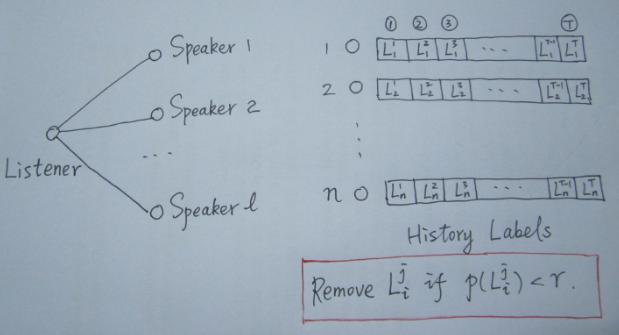
SLPA 中引入了 Listener 和 Speaker 两个比较形象的概念,你可以这么来理解:在刷新节点标签的过程中,任意选取一个节点作为 listener,则其所有邻居节点就是它的 speaker 了,speaker 通常不止一个,一大群 speaker 在七嘴八舌时,listener 到底该听谁的呢?这时我们就需要制定一个规则。
在 LPA 中,我们以出现次数最多的标签来做决断,其实这就是一种规则。只不过在 SLPA 框架里,规则的选取比较多罢了(可以由用户指定)。
当然,与 LPA 相比,SLPA 最大的特点在于:它会记录每一个节点在刷新迭代过程中的历史标签序列(例如迭代 T 次,则每个节点将保存一个长度为 T 的序列,如上图所示),当迭代停止后,对每一个节点历史标签序列中各(互异)标签出现的频率做统计,按照某一给定的阀值过滤掉那些出现频率小的标签,剩下的即为该节点的标签(通常有多个)。
算法步骤
(1) 初始化所有节点的标签信息,使得每个节点拥有唯一的标签。
(2) 最为主要的是标签传播过程。
- 当前节点作为一个listener。
- 当前节点的每一个邻居节点根据一定的speaking策略传递标签信息。
- 当前节点从邻居节点传播的标签信息集中根据一定的listener策略选择一个标签作为本次迭代中的新标签。
- 算法收敛或遍历达到指定的次数,算法结束。否则,标签在不断的遍历过程中传播。
(3) 标签分类过程。后处理阶段根据节点的标签信息进行社区发现。
SLPA的工作过程:
- 将所有成员打上不同标签
- 遍历成员,扫描每个成员关联的成员的标签。
- 将出现次数最多的标签记录,成为此成员的一个候选标签
- 候选标签出现最多的标签为此成员当前的社区名(例如:用户1记录标签:1出现三次,2出现五次,3出现四次,用户1所属社区就是2社区)
- 经过多次遍历成员使社区的划分更加明确
算法优点
算法SLPA 不会像其它算法一样忘记上一次迭代中节点所更新的标签信息,它给每个节点设置了一个标签存储列表来存储每次迭代所更新的标签。最终的节点社区从属关系将由标签存储列表中所观察到的标签的概率决定,当一个节点观察到有非常多一样的标签时,那么,很有可能这个节点属于这个社区,而且在传播过程中也很有可能将这个标签传播给别的节点。更有益处的是,这种标签存储列表的设计可以使得算法可以支持划分重叠社区。
Dolphin 数据集是 D.Lusseau 等人使用长达 7 年的时间观察新西兰 Doubtful Sound海峡 62 只海豚群体的交流情况而得到的海豚社会关系网络。这个网络具有 62 个节点,159 条边。节点表示海豚,而边表示海豚间的频繁接触
代码如下:
class SLPA:
def __init__(self, G, T, r):
"""
:param G:图本身
:param T: 迭代次数T
:param r:满足社区次数要求的阈值r
"""
self._G = G
self._n = len(G.nodes(False)) # 节点数目
self._T = T
self._r = r
def execute(self):
# 节点存储器初始化
node_memory = []
for i in range(self._n):
node_memory.append({i: 1})
# 算法迭代过程
for t in range(self._T):
# 任意选择一个监听器
# np.random.permutation():随机排列序列
order = [x for x in np.random.permutation(self._n)]
for i in order:
label_list = {}
# 从speaker中选择一个标签传播到listener
for j in self._G.neighbors(i):
sum_label = sum(node_memory[j].values())
label = list(node_memory[j].keys())[np.random.multinomial(
1, [float(c) / sum_label for c in node_memory[j].values()]).argmax()]
label_list[label] = label_list.setdefault(label, 0) + 1
# listener选择一个最流行的标签添加到内存中
max_v = max(label_list.values())
# selected_label = max(label_list, key=label_list.get)
selected_label = random.choice([item[0] for item in label_list.items() if item[1] == max_v])
# setdefault如果键不存在于字典中,将会添加键并将值设为默认值。
node_memory[i][selected_label] = node_memory[i].setdefault(selected_label, 0) + 1
# 根据阈值threshold删除不符合条件的标签
for memory in node_memory:
sum_label = sum(memory.values())
threshold_num = sum_label * self._r
for k, v in list(memory.items()):
if v < threshold_num:
del memory[k]
communities = collections.defaultdict(lambda: list())
# 扫描memory中的记录标签,相同标签的节点加入同一个社区中
for primary, change in enumerate(node_memory):
for label in change.keys():
communities[label].append(primary)
# 返回值是个数据字典,value以集合的形式存在
return communities.values()
结果如下
0 [1, 5, 6, 7, 9, 13, 17, 19, 22, 25, 26, 27, 31, 32, 39, 41, 48, 54, 56, 57]
1 [4, 8, 11, 15, 18, 21, 23, 24, 29, 35, 45, 51, 59]
2 [10, 28, 42, 47]
3 [12, 14, 16, 20, 33, 34, 37, 38, 40, 43, 44, 50, 52]
4 [60]
0.4337
代码与数据下载github

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐
 8
8 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)