【深度学习】动手学深度学习——编码器-解码器
参考资料:https://zh.d2l.ai/chapter_recurrent-modern/encoder-decoder.html自然语言处理10.9 编码器—解码器(seq2seq)在自然语言处理中,输入输入都可以是不定长序列,此时可以用编码器—解码器(encoder-decoder)[1] 或者seq2seq模型 [2]。根据“编码器-解码器”架构的设计, 我们可以使用两个循环神经网络(
参考资料:
https://zh.d2l.ai/chapter_recurrent-modern/encoder-decoder.html
1 深度学习简介
核心思想:用数据编程
机器学习:寻找适用不同问题的函数形式,以及如何使用数据来获取函数的参数。
深度学习:机器学习中的一类函数,形式为多层神经网络。
赫布理论:神经通过正向强化来学习(感知机算法原型)
随机梯度下降:强化合理的,惩罚不合理的,获得好的网络参数
神经网络核心原则:
- 交替使用线性单元和非线性单元,统称为层
- 使用链式法则(反向传播)更新网络参数
核方法、决策树、概率图模型在数据和计算力少的时候好用
算力增长可以用于优化参数,使用非线性处理单元可以提高存储利用效率。
深度学习发展原因:
- 丢弃法,解决过拟合(在网络中加入噪声)
- 注意力机制,在不增加参数的情况下扩大记忆容量和复杂度(指针记忆中间状态)
- 记忆网络和编码器-解释器,允许重复修改深度网络的内部状态(修改内存)
- GAN网络,传统上关注找正确的概率分布和采样算法。GAN将采样替换成任意含有可微分参数的算法,这些参数被训练到使辨别器不能分别真实和生成的样本。可用任意算法来生成输出。
- 分布式并行训练:随机梯度下降需要更小的批量
- 深度学习框架,TensorFlow(Keras对TensorFlow进行了封装),pytorch

案例: - 搜索,个性化推荐,网页排序
- 智能助手
- 物体识别
- 博弈
- 自动驾驶
- 深度学习在CV领域应用
特点
表征学习:关注自动找出表示数据的合适方式,使输入变为正确的输出
深度学习:具有多级表示的表征学习方法。从原始数据开始,通过简单的函数将该级的表示变换为更高级的表示。深度学习可看作由许多简单函数复合而成的函数。
- 深度学习自动找出每一级表示数据的合适方式。
- 端到端训练:没有特征提取阶段,用自动优化的逐级过滤器替代。
- NLP中,词袋模型(将一个句子映射到一个词频向量,忽视单词排列顺序和标点符号)不适用,可用词嵌入模型。
- 从含参数统计模型转向无参数模型:数据稀缺时,简化对现实的假设得到实用模型。数据充足时,用更好拟合现实的无参数模型替代。
- 对非最优解的包容、对非凸非线性优化的使用
2 预备知识
用conda安装
创建虚拟环境:conda env create -f environment.yml
激活虚拟环境:conda deactivate
5 卷积神经网络
要求卷积核和偏差的参数
二维互相关运算

核数组又叫卷积核或过滤器
二维卷积层:将输入和卷积核做互相关后,加上一个标量偏差得到输出
通过数据学习核数组:输入数据X和输出数据Y,来学习核数组K
训练时通常先对卷积核随机初始化,使⽤平⽅误差来⽐较Y和卷积层的输出,计算梯度来更新权重(卷积核的参数)。
卷积运算:将核数组左右翻转再上下反转(旋转180度),再做互相关运算。
由于学习的是核数组的参数,不管使用互相关还是卷积,均能够得到想要的输出结果。后续卷积运算均指互相关运算。
特征图:二维卷积层输出的二维数组
感受野:特征图上单个元素(1个)在输入上的反向相关元素(9个)。更深的网络可增加单个元素的感受野
自然语言处理
10.9 编码器—解码器(seq2seq)
在自然语言处理中,输入输出都可以是不定长序列,此时可以用编码器—解码器(encoder-decoder)[1] 或者seq2seq模型 [2]。根据“编码器-解码器”架构的设计, 我们可以使用两个循环神经网络(分别叫做编码器和解码器)来设计一个序列到序列学习的模型。
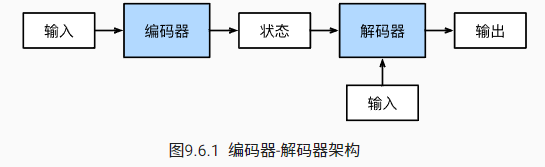
编码器接受一个长度可变的序列作为输入, 并将其转换为具有固定形状的编码状态。
解码器将固定形状的编码状态映射到长度可变的序列。
“编码器-解码器”架构是形成后续章节中不同序列转换模型的基础。

使⽤编码器—解码器将上述英语句⼦翻译成法语句⼦
<eos>(end of sequence)表⽰序列的终⽌。
<bos>(beginning of sequence)表⽰序列的开始。
编码器的作⽤是把⼀个不定⻓的输⼊序列变换成⼀个定⻓的背景变量c,并在该背景变量中编码输⼊序列信息。编码器可以使⽤循环神经⽹络。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)