
【深度学习】步态识别-论文阅读(无参考意义):Cross-View Gait Recognition Based on Feature Fusion
这里写目录标题摘要介绍相关工作改进提出多尺度特征融合全局和局部特征融合特征映射结论基于特征融合的跨视图步态识别摘要与人脸识别相比,步态识别是最有前途的视频生物特征识别技术之一,步态图像易于远距离捕获,步态特征对外观伪装具有鲁棒性。现有的许多步态识别方法都是针对单一场景的,如固定摄像机,但当视点发生变化时,识别精度会急剧下降。本文对现有的步态识别方法进行了改进,提出了一种基于特征融合的跨视角步态识别
基于特征融合的跨视图步态识别
摘要
与人脸识别相比,步态识别是最有前途的视频生物特征识别技术之一,步态图像易于远距离捕获,步态特征对外观伪装具有鲁棒性。
现有的许多步态识别方法都是针对单一场景的,如固定摄像机,但当视点发生变化时,识别精度会急剧下降。
本文对现有的步态识别方法进行了改进,提出了一种基于特征融合的跨视角步态识别方法。
首先,提出一种多尺度特征融合模块,提取不同粒度的步态序列特征;
然后,引入双路径结构,分别学习全局外观特征和细粒度局部特征。随着网络的深化,两条路径的特征逐渐融合,获得互补信息。在最后的特征映射阶段,使用GeneralizedMean池来支持区别表示。在公共数据集CASIA-B上的大量实验表明,我们的方法可以获得最先进的识别性能
步态识别,特征融合,交叉视图
介绍
应用:步态识别是指通过人的行走姿势或足迹来识别人,是身份识别中最有潜力的方法之一。它具有远距离识别的优势,而且由于步态是一种潜意识行为,因此对伪装或化妆也具有很强的抵抗力。因此,步态识别在视频监控、公共安全和认证等领域具有广阔的应用前景。
挑战:
1个体在行走过程中会受到外部环境和自身姿态的影响,
2尤其是视角的变化也是限制识别性能的重要因素。当行人从一个摄像头的监控区域以不同视角移动到另一个监控区域时,会出现不同视角的步态序列,行人的轮廓会随着视角的不同而变化。因此,提高跨视角步态识别的性能仍是十分必要的。
近年来,卷积神经网络(convolutional neural network, CNN)被广泛应用于步态识别领域,在公共数据集上取得了良好的效果。GeiNet[1]以步态能量图像为输入,尝试通过卷积神经网络获得判别表示。GaitSet[2]使用2D CNN在帧级提取全局特征,将步态序列视为可以呈现时间信息的集合。然后利用集合池方法将帧级特征聚合成独立的序列级特征,比基于步态模板的方法更全面。GaitNet[3]提出了一种自动编码器框架,该框架从原始RGB图像中提取步态特征,然后利用LSTM (long-short-term memory, LSTM)网络建立步态序列时间变化模型。这些方法只利用全局特征来描述步态信息,而没有对步态序列的局部细节给予足够的关注。为了获得不同个体更细微和可区分的步态特征,Zhang et al.[4]提出了局部特征提取器和时间注意模型来提取具有判别性的空间和时间特征,同时建立了有效的损失函数来区分步态特征。GaitPart[5]引入了一种新型的卷积,focalconvolution Layer,在该层中,它水平地划分特征图,以获得几个部分的步态序列。每个局部序列对应人体的不同部位,从而探索更细粒度的局部信息。然而,局部信息表示丢失了步态帧的全局上下文信息,忽略了局部区域之间的关系。因此,我们提出了一种基于全局和局部特征融合的跨视角步态识别框架。特别地,我们首先构建了一个多尺度特征融合模块来提取不同粒度的步态特征。然后,一方面利用正常卷积层获取步态序列的全局特征,以步态轮廓的整体特征为重点;另一方面,引入focalconvolution Layer[5]来提取步态序列的局部特征,该方法更注重不同序列的细节。随着网络的深化,这两种特征被聚合和扩展,可以实现信息互补。
相关工作
随着计算机视觉的发展,步态分析在生物特征识别领域逐渐受到重视。
现有的步态识别方法大致可分为基于三维模型的步态识别方法和基于二维视频序列的步态识别方法。
三维建模主要采用多摄像机从不同角度进行标定,建立三维人体步态模型。
它可以准确地表示人体各部位的空间特征,从而减少遮挡等因素的负面影响。Tang等人[6]利用先进的三维成像设备进行三维重建和目标跟踪,但仅利用距离数据很难准确分割人体轮廓。为了解决这个问题,唐家璇et al。[7]提出了拉普拉斯变形能量函数通过2 d身体轮廓和姿势使模型变形对应的角度和姿势,然后将本地信息到一个二维空间建立步态能量用于识别图像。Deng等[8,9]提出了一种基于多视图集成和确定性学习的方法,利用不同视角的图像合成轮廓图像进行识别。但在进行三维分析时,需要多台摄像机同时配合,才能捕捉到足够的步态信息。由于相机平衡原理复杂,建模计算量过大,这些方法一般只适用于完全可控的多相机协作环境,难以应用于真实场景。
二维图像序列的步态识别研究是通过构建步态能量模板进行的。个体的周期性、连续的时空运动序列会按照一定的规则和形式叠加成一个或几个模板。他们可以从不同的角度学习步态序列之间的映射和投影关系,通过步态相似性度量达到识别的目的。透视变换模型可以将不同视角下的步态特征转化为同一视角下的步态特征,从而缓解了跨视角步态识别问题。Zheng等人[10]将步态矩阵分解为低秩对应矩阵,然后通过奇异值分解(SVD)实现鲁棒的VTM (view transformation model)模型。Hu等人[11]利用高阶奇异值分解将VTM模型扩展为四阶张量空间的多线性投影模型,然后提取与视图无关和与姿势无关的向量来识别步态周期不完整的交叉视图步态序列。Muramatsu表示等。
基于VTM的方法可以将一个步态特征视角转换为另一个视角来处理不同视角之间的相似性度量问题,但不能有效地利用多个视角之间的互补信息。此外,它们在建模和透视变换过程中容易受到噪声的传播,导致识别性能下降。近年来,由于CNN可以直接处理输入的原始图像,避免了复杂的预处理操作,在交叉视图步态识别中表现出了良好的性能。Wu等人[14]提出了一种针对一组图像集的特征提取方法,有效地抑制过拟合问题。将步态轮廓输入CNN获得全局表示,该网络能够处理步态序列中的视点变换。Zhang et al.[15]提出了一种将步态能量图像(GEIs)放入具有两个对称结构子网络的双深度卷积神经网络中的方法。Tan et al.[16]提出将GEIs馈送到具有共享权值的双通道CNN中训练匹配模型,在交叉视图步态识别中显示出了良好的鲁棒性。Wu等人[17]将网络分为三部分,分别提取不同层次的特征。Wolf等人[18]提出了一个用于步态识别的3D CNN框架,其中网络的输入由灰度步态图像和光流组成。Li等人[19]将步态序列周期性检测后直接送入CNN网络进行特征提取,然后结合贝叶斯分类进行步态识别。
改进
现有方法:大多采用生成的GEIs作为CNN的输入,但在剪影序列叠加后GEIs会丢失时间信息。
相反,我们直接将步态图像输入到网络中,保留序列的时间信息,并进一步融合全局特征和局部特征以获得更好的识别结果。
提出
首先介绍所提出方法的网络框架,
然后介绍了该模型的关键组成部分,包括多尺度特征融合模块、全局和局部特征融合模块以及特征映射模块。
最后给出了培训和测试的细节。所提步态识别方法的总体框架如图1所示。
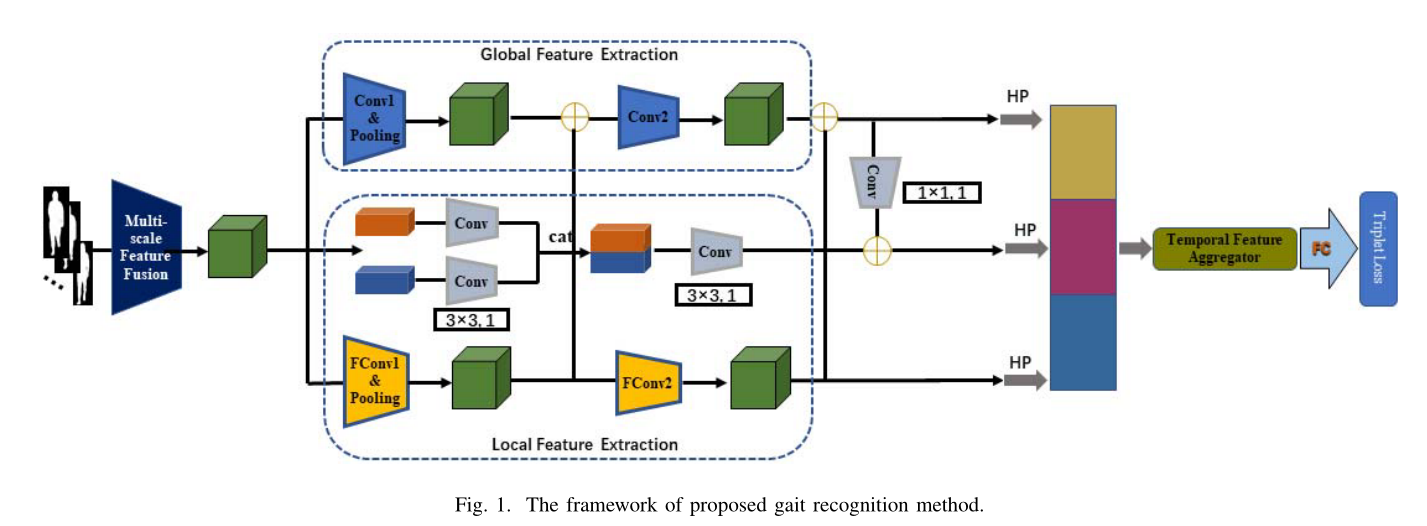
多尺度特征融合
多尺度特征融合的常见形式有两种,一种是并行多分支网络,另一种是串行跳级连接结构。
作用:提取不同接受域下的特征。
本文的多尺度特征融合模块属于前者。
组成:它由三个简单的分支组成,分别代表1×1 convolution, 3×3 convolution和5×5 convolution层。
过程:将输入的步态序列通过不同的分支转换成不同粒度的特征映射,然后在通道维上将这些特征映射连接起来。最后,通过另一个卷积层将完整的特征调整到适当的信道数。将同一层上具有不同接收域的特性传输到下一层,可以更灵活地平衡模型的功能。
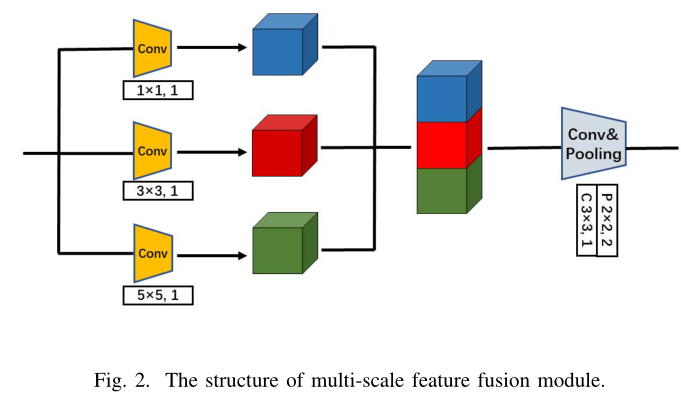
多尺度特征融合模块结构如图2所示。
输入:X(c1xhxw)
c1:频道的数量;h,w:分别表示每帧的高度和宽度
融合特征可以表示为:
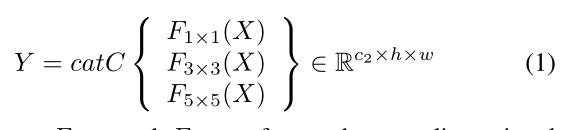
cat C:表示通道维度上的连接操作。
F1X1 F3X3.F5X5:对于卷积核分别为1、3和5的二维卷积运算
全局和局部特征融合
全局特征是指图像的整体属性,一般包括颜色特征、纹理特征和形状特征。
由于该模型的输入是步态轮廓,因此本文的全局特征主要集中在目标的形状上。
缺点:虽然全局特征具有良好的不变性,但局部特征在存在混叠和缺陷的图像下会表现出更好的稳定性(当原始彩色图像转换为黑白剪影图像时,有时提取的轮廓不清晰,与周围环境中其他物体的轮廓有缺陷的或有别名的)。
Fan等人[5]提出了利用Focal Convolution Layer提取局部特征,**将feature map水平地分成几个块。每个块都用相同的卷积核进行处理,然后将得到的几个特征图像串接在一起,形成一个完整的feature map。**它可以促进局部层次空间特征的细粒度学习,提取出更多的细粒度局部信息。考虑到全局特征和局部特征各自的优势,我们将它们进行整合,以获得更好的结果。
给定inputX∈Rc×h×w,其中c表示频道数,h,w表示每个视频帧的高度和宽度,则全局特征可表示为
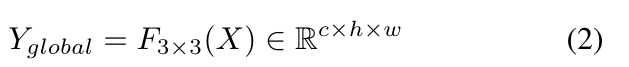
为了获得局部特征,首先对输入特征进行分割,在水平方向上得到局部特征,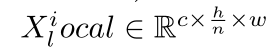
依次表示第i个水平局部特征,完整的局部特征可以表示为
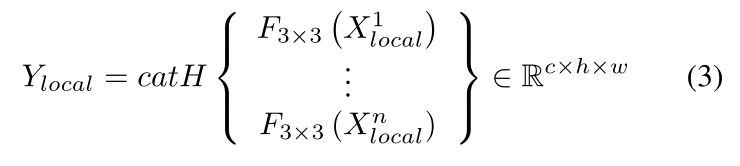
F3X3:表示卷积核为3的二维卷积,
Cat H:指水平维度上的连接。
最后融合的特征可以表示为
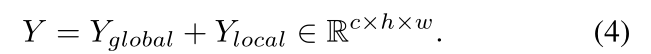
特征映射
为了增强时间特征,提出了一种基于注意力的时间特征聚合器来表示局部微运动特征和整个步态序列[5]的全局描述。实际上,通过一维Global Average Pooling和一维Global Max Pooling得到微运动特征向量序列。
给定输入featureX,输出featureyouout可以表示为
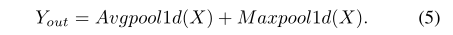
考虑到这种池化策略的不灵活性,引入了一种特殊的池化操作——广义均值池化(GeM)[20]。它是均值池和最大值池的中间形式,由参数p控制。GeM通过调整参数sp,可以保持局部信息的不变性,关注不同的细度。GeM的公式如下:
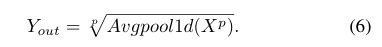
其中为可学习参数。当p= 1时,操作等价于max pooling,当p→∞时,操作等价于pooling
带指数参数p的广义平均池化 (generalized mean pooling ,GeM)将空间响应map转化成固定大小。p用于调节辨别性和不变性
也就是整张图的每个像素的p次方求和再开p次方。
p>1时会增大输入特征图的对比度,专注于输入特征图突出、跳跃的部分。这个在后面实验会详细说。
为什么叫generalized,因为p=1时是平均池化,p=无穷是max pooling。
结论
本文对现有的步态识别模型进行了改进,以获得更好的交叉视图性能。
首先提出一种多尺度特征融合模块来提取不同粒度的步态特征,
然后通过全局和局部特征融合模块获得更详细的步态特征信息。
最后,我们引入GeM来增强连续视频帧的时间特性,从而促进学习特征的识别。在公共交叉视角步态数据集上的大量实验结果验证了该模型的优越性。

鸿蒙生态一站式服务平台。
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)