线性判别分析(LDA)
1、简介线性判别式分析(Linear Discriminant Analysis, LDA),也叫做Fisher线性判别(Fisher Linear Discriminant ,FLD),是模式识别的经典算法,它是在1996年由Belhumeur引入模式识别和人工智能领域的。性鉴别分析的基本思想是将高维的模式样本投影到最佳鉴别矢量空间,以达到抽取分类信息和压缩特征空间维数的效果,投影后保证模式样本
1、简介
线性判别式分析(Linear Discriminant Analysis, LDA),也叫做Fisher线性判别(Fisher Linear Discriminant ,FLD),是模式识别的经典算法,它是在1996年由Belhumeur引入模式识别和人工智能领域的。性鉴别分析的基本思想是将高维的模式样本投影到最佳鉴别矢量空间,以达到抽取分类信息和压缩特征空间维数的效果,投影后保证模式样本在新的子空间有最大的类间距离和最小的类内距离,即模式在该空间中有最佳的可分离性。因此,它是一种有效的特征抽取方法。LDA是一种有监督的算法。
2、LDA算法(二类情况)
给定特征为d维的N个样例 x ( i ) { x 1 ( i ) , x 2 ( i ) , ⋯ , x d ( i ) } x^{(i)}\left\{x_{1}^{(i)}, x_{2}^{(i)}, \cdots, x_{d}^{(i)}\right\} x(i){x1(i),x2(i),⋯,xd(i)},其中有 N 1 N_{1} N1个样例属于类别 ω 1 \omega_{1} ω1, N 2 N_{2} N2个样例属于类别 ω 2 \omega_{2} ω2。
现在我们想将 d d d维特征降到只有一维,而又要保证类别能够“清晰”地反映在低维数据上,也就是这一维就能决定每个样例的类别。这里的降维可以通过将样本点投影到一个低维平面上来实现。在这里为了简单起见,我们设样例为二维的,也就是 d = 2 d=2 d=2,并将其投影到一条方向为 w w w的直线上去,这样就将2维的特征降到了1维。
样例 x x x到从原点出发方向为 w w w的直线上的投影可以用下式来计算: y = w T x y=w^{T} x y=wTx。注意,这里的 y y y不是标签值,而是 x x x投影到直线上的点到原点的距离。
我们的目的是寻找一条从原点出发方向为
w
w
w的直线,可以将投影后的样例点很好的分离,大概如下图所示:

从直观上来讲,第二条直线看起来还不错,可以很好地将两类样例分离,那这条直线是不是我们所要找的最佳的直线呢?要回答这个问题,我们就要从定量的角度来确定最佳的投影直线,即直线的方向向量
w
w
w。
首先求每类样例的均值(中心点):
μ
i
=
1
N
i
∑
x
∈
w
i
x
\mu_{i}=\frac{1}{N_{i}} \sum_{x \in w_{i}} x
μi=Ni1∑x∈wix
那么投影后的每类样例的均值(中心点)为:
μ
~
i
=
1
N
i
∑
y
∈
w
i
y
=
1
N
i
∑
x
∈
w
i
w
T
x
=
w
T
μ
i
\tilde{\mu}_{i}=\frac{1}{N_{i}} \sum_{y \in w_{i}} y=\frac{1}{N_{i}} \sum_{x \in w_{i}} w^{T} x=w^{T} \mu_{i}
μ~i=Ni1∑y∈wiy=Ni1∑x∈wiwTx=wTμi
从上面两条公式可以看出,投影后的中心点就是中心点的投影。
从上面两张图可以看出,能够使投影后的两类样本中心点尽量分离的直线是好的直线,定量表示就是:
max
w
J
(
w
)
=
∣
μ
~
1
−
μ
~
2
∣
=
∣
w
T
μ
1
−
w
T
μ
2
∣
\max _{w} J(w)=\left|\tilde{\mu}_{1}-\tilde{\mu}_{2}\right|=\left|w^{T} \mu_{1}-w^{T} \mu_{2}\right|
maxwJ(w)=∣μ~1−μ~2∣=∣∣wTμ1−wTμ2∣∣。但是仅仅考虑
J
(
w
)
J(w)
J(w)是不行的,如下图所示:
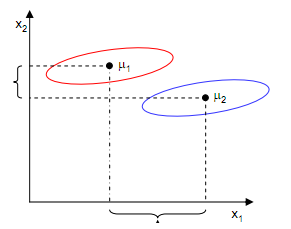
尽管在
X
1
X_{1}
X1轴上取得了中心点投影的最大间距,但是由于重叠严重,反而不能很好的分离两类样本点。中心点投影在
X
2
X_{2}
X2轴上的间距虽然很小,但是却能够取得比
X
1
X_{1}
X1轴更好的分离效果。这是为什么呢?
LDA是基于Fisher准则的算法,其必须同时遵从类内密集,类间分离这两个条件。中心点投影间距最大化只是满足类间分离而没有考虑类内密集,所以为了获得最佳的投影方向
w
w
w,我们还要将同一类样例的类内密集度做为一个约束,在这里,我们采用散列值 scatter作为密集度的一个度量。
每个类别的散列值定义如下:
s
~
i
2
=
∑
y
∈
w
i
(
y
−
μ
~
i
)
2
\tilde{s}_{i}^{2}=\sum_{y \in w_{i}}\left(y-\tilde{\mu}_{i}\right)^{2}
s~i2=∑y∈wi(y−μ~i)2,可以看出,散列值与方差较为接近,类内越密集,散列值越小;类内越分散,散列值越大。
有了散列值,我们得以满足Fisher准则的类内密集的要求,结合最大化中心点的投影间距,我们可以提出最终的度量公式:
max
w
J
(
w
)
=
∣
μ
1
~
−
μ
2
~
∣
2
s
1
~
2
+
s
2
~
2
\max _{w} J(w)=\frac{\left|\tilde{\mu_{1}}-\tilde{\mu_{2}}\right|^{2}}{\tilde{s_{1}}^{2}+\tilde{s_{2}}^{2}}
maxwJ(w)=s1~2+s2~2∣μ1~−μ2~∣2
将散列值的公式展开可得:
s
i
~
2
=
∑
y
∈
w
i
(
y
−
μ
~
i
)
2
=
∑
x
∈
w
i
(
w
T
x
−
w
T
μ
i
)
2
=
∑
x
∈
w
i
w
T
(
x
−
μ
i
)
(
x
−
μ
i
)
T
w
\tilde{s_{i}}^{2}=\sum_{y \in w_{i}}\left(y-\tilde{\mu}_{i}\right)^{2}=\sum_{x \in w_{i}}\left(w^{T} x-w^{T} \mu_{i}\right)^{2}=\sum_{x \in w_{i}} w^{T}\left(x-\mu_{i}\right)\left(x-\mu_{i}\right)^{T} w
si~2=∑y∈wi(y−μ~i)2=∑x∈wi(wTx−wTμi)2=∑x∈wiwT(x−μi)(x−μi)Tw
令
S
i
=
∑
x
∈
w
i
(
x
−
μ
i
)
(
x
−
μ
i
)
T
,
S
w
=
S
1
+
S
2
S_{i}=\sum_{x \in w_{i}}\left(x-\mu_{i}\right)\left(x-\mu_{i}\right)^{T}, S_{w}=S_{1}+S_{2}
Si=∑x∈wi(x−μi)(x−μi)T,Sw=S1+S2
则
s
i
~
2
=
w
T
S
i
w
,
s
1
~
2
+
s
2
~
2
=
w
T
S
w
w
\tilde{s_{i}}^{2}=w^{T} S_{i} w, \tilde{s_{1}}^{2}+\tilde{s_{2}}^{2}=w^{T} S_{w} w
si~2=wTSiw,s1~2+s2~2=wTSww,分母部分完毕,接下来处理分子部分。
展开分子,
(
μ
~
1
−
μ
~
2
)
2
=
(
w
T
μ
1
−
w
T
μ
2
)
2
=
w
T
(
μ
1
−
μ
2
)
(
μ
1
−
μ
2
)
T
w
\left(\tilde{\mu}_{1}-\tilde{\mu}_{2}\right)^{2}=\left(w^{T} \mu_{1}-w^{T} \mu_{2}\right)^{2}=w^{T}\left(\mu_{1}-\mu_{2}\right)\left(\mu_{1}-\mu_{2}\right)^{T} w
(μ~1−μ~2)2=(wTμ1−wTμ2)2=wT(μ1−μ2)(μ1−μ2)Tw
令
S
B
=
(
μ
1
−
μ
2
)
(
μ
1
−
μ
2
)
T
S_{B}=\left(\mu_{1}-\mu_{2}\right)\left(\mu_{1}-\mu_{2}\right)^{T}
SB=(μ1−μ2)(μ1−μ2)T ,则
(
μ
1
~
−
μ
2
~
)
2
=
w
T
S
B
w
\left(\tilde{\mu_{1}}-\tilde{\mu_{2}}\right)^{2}=w^{T} S_{B} w
(μ1~−μ2~)2=wTSBw,分子部分完毕。
度量公式可表示为:
max
w
J
(
w
)
=
w
T
S
B
w
w
T
S
w
w
\max _{w} J(w)=\frac{w^{T} S_{B} w}{w^{T} S_{w} w}
maxwJ(w)=wTSwwwTSBw
在我们求导之前,需要对分母进行归一化,因为不做归一的话,
w
w
w扩大任何倍,都成立,我们就无法确定
w
w
w。因此我们打算令
∥
w
T
S
w
w
∥
=
1
\left\|w^{T} S_{w} w\right\|=1
∥∥wTSww∥∥=1,那么加入拉格朗日乘子后,求导:
c
(
w
)
=
w
T
S
B
w
−
λ
(
w
T
S
w
w
−
1
)
c(w)=w^{T} S_{B} w-\lambda\left(w^{T} S_{w} w-1\right)
c(w)=wTSBw−λ(wTSww−1)
d
c
d
w
=
2
S
B
w
−
2
λ
S
w
w
=
0
\frac{d c}{d w}=2 S_{B} w-2 \lambda S_{w} w=0
dwdc=2SBw−2λSww=0
S
B
w
=
λ
S
w
w
S_{B} w=\lambda S_{w} w
SBw=λSww
若Sw可逆,则
S
w
−
1
S
B
w
=
λ
w
S_{w}^{-1} S_{B} w=\lambda w
Sw−1SBw=λw ,即
w
w
w 是矩阵
S
w
−
1
S
B
S_{w}^{-1} S_{B}
Sw−1SB 的特征向量。由此可以求出
w
w
w。
上面这个式子还可以进一步化简:
S
B
w
=
(
μ
1
−
μ
2
)
(
μ
1
−
μ
2
)
T
w
=
(
μ
1
−
μ
2
)
∗
λ
w
S_{B} w=\left(\mu_{1}-\mu_{2}\right)\left(\mu_{1}-\mu_{2}\right)^{T} w=\left(\mu_{1}-\mu_{2}\right) * \lambda_{w}
SBw=(μ1−μ2)(μ1−μ2)Tw=(μ1−μ2)∗λw ,这里的
λ
w
\lambda_{w}
λw 是一个常数。
代入原式可得:
S
w
−
1
S
B
w
=
S
w
−
1
(
μ
1
−
μ
2
)
∗
λ
w
=
λ
w
S_{w}^{-1} S_{B} w=S_{w}^{-1}\left(\mu_{1}-\mu_{2}\right) * \lambda_{w}=\lambda w
Sw−1SBw=Sw−1(μ1−μ2)∗λw=λw,由于对
w
w
w 扩大缩小任何倍不影响结果,因此可以约去两边的末知常数
λ
w
,
λ
\lambda_{w}, \lambda
λw,λ ,
得到
w
=
S
w
−
1
(
μ
1
−
μ
2
)
w=S_{w}^{-1}\left(\mu_{1}-\mu_{2}\right)
w=Sw−1(μ1−μ2) 。
上面那张图的投影结果如下图所示:

3、LDA算法(多类情况)
在二类情况下, J ( w ) J(w) J(w)的分子是两类中心距,分母是每个类自己的散列度。现在投影方向是多维了(好几条直线),分子需要做一些改变,我们不是求两两样本中心距之和(这个对描述类别间的分散程度没有用),而是求每类中心相对于全样本中心的散列度之和。除却这个变化,其他推导与二类情况相似,这里不做展开说明。
4、实例
三维投影到二维平面:(
W
1
W1
W1相比
W
2
W2
W2能够获得更好的分离效果。)

PCA与LDA的降维对比:
LDA用于降维,和PCA有很多相同,也有很多不同的地方,因此值得好好的比较一下两者的降维异同点。
首先我们看看相同点:
1)两者均可以对数据进行降维。
2)两者在降维时均使用了矩阵特征分解的思想。
3)两者都假设数据符合高斯分布。
我们接着看看不同点:
1)LDA是有监督的降维方法,而PCA是无监督的降维方法
2)LDA降维最多降到类别数k-1的维数,而PCA没有这个限制。
3)LDA除了可以用于降维,还可以用于分类。
4)LDA选择分类性能最好的投影方向,而PCA选择样本点投影具有最大方差的方向。
这点可以从下图形象的看出,在某些数据分布下LDA比PCA降维较优。

PCA选择样本点投影具有最大方差的方向,LDA选择分类性能最好的方向。
LDA既然叫做线性判别分析,应该具有一定的预测功能,比如新来一个样例x,如何确定其类别?
拿二值分来来说,我们可以将其投影到直线上,得到
y
y
y,然后看看
y
y
y是否在超过某个阈值
y
0
y_{0}
y0,超过是某一类,否则是另一类。而怎么寻找这个
y
0
y_{0}
y0呢?
看
y
=
w
T
x
\mathrm{y}=w^{T} x
y=wTx
根据中心极限定理,独立同分布的随机变量和符合高斯分布,然后利用极大似然估计求
P
(
y
∣
C
i
)
\mathrm{P}\left(\mathrm{y} \mid \mathrm{C}_{i}\right)
P(y∣Ci)
然后用决策理论里的公式来寻找最佳的y0,详情请参阅PRML。
这是一种可行但比较繁琐的选取方法,可以看第7节(一些问题)来得到简单的答案。
5. 使用LDA的一些限制
1、 LDA至多可生成C-1维子空间
LDA降维后的维度区间在[1,C-1],与原始特征数n无关,对于二值分类,最多投影到1维。
2、 LDA不适合对非高斯分布样本进行降维。
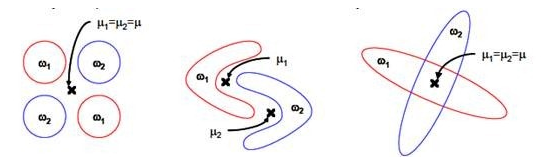
上图中红色区域表示一类样本,蓝色区域表示另一类,由于是2类,所以最多投影到1维上。不管在直线上怎么投影,都难使红色点和蓝色点内部凝聚,类间分离。

上图中,样本点依靠方差信息进行分类,而不是均值信息。LDA不能够进行有效分类,因为LDA过度依靠均值信息。
4、 LDA可能过度拟合数据。
6. LDA的一些变种
1、非参数LDA
非参数
L
D
A
L D A
LDA 使用本地信息和K临近样本点来计算
S
B
S_{B}
SB,使得
S
B
S_{B}
SB 是全秩的,这样我们可以抽取多余C-1个特征向
量。而且投影后分离效果更好。
2、正交LDA
先找到最佳的特征向量,然后找与这个特征向量正交且最大化 fisher条件的向量。这种方法也能摆脱
C
−
1
C-1
C−1 的限 制。
3、一般化LDA
引入了贝叶斯风险等理论
4、核函数
L
D
A
L D A
LDA
将特征
x
→
Φ
(
x
)
\mathrm{x} \rightarrow \Phi(\mathrm{x})
x→Φ(x) ,使用核函数来计算。
7. 一些问题
上面在多值分关中使用的
S
B
=
∑
i
=
1
c
N
i
(
μ
i
−
μ
)
(
μ
i
−
μ
)
T
\mathrm{S}_{B}=\sum_{i=1}^{c} N_{i}\left(\mu_{i}-\mu\right)\left(\mu_{i}-\mu\right)^{T}
SB=i=1∑cNi(μi−μ)(μi−μ)T
是带权重的各关样本中心到全样本中心的散列矩阵。如果
C
=
2
C=2
C=2 (也就是二值分类时) 套用这个公式,不能够 得出在二值分尖中使用的
S
B
\mathrm{S}_{B}
SB 。
S
B
=
∑
i
=
1
c
(
μ
1
−
μ
2
)
(
μ
1
−
μ
2
)
T
\mathrm{S}_{B}=\sum_{i=1}^{c}\left(\mu_{1}-\mu_{2}\right)\left(\mu_{1}-\mu_{2}\right)^{T}
SB=i=1∑c(μ1−μ2)(μ1−μ2)T
因此二值分类和多值分关时求得的
S
B
\mathrm{S}_{B}
SB 会不同,而
S
W
\mathrm{S}_{W}
SW 意义是一政的。
对于二值分类问题,令人惊奇的是最小二乘法和Fisher线性判别分析是一致的。
下面我们证明这个结论,并且给出第 4 节提出的
y
\mathrm{y}
y 值得选取问题。
回顾之前的线性回归,给定
N
\mathrm{N}
N 个
d
\mathrm{d}
d 维特征的训练样例
x
(
i
)
{
x
1
(
i
)
,
x
2
(
i
)
,
…
,
x
d
(
i
)
}
x^{(i)}\left\{x_{1}^{(i)}, x_{2}^{(i)}, \ldots, x_{d}^{(i)}\right\}
x(i){x1(i),x2(i),…,xd(i)} (i从1到
N
\mathrm{N}
N ),每个
x
(
i
)
x^{(i)}
x(i) 对应一个粂 标签
y
(
i
)
y^{(i)}
y(i) 。我们之前令
y
=
0
y=0
y=0 表示一类,
y
=
1
y=1
y=1 表示另一关,现在我们为了证明最小二乘法和LDA的关系,我们需要 做一些改栾
{
y
=
N
N
1
,
样例属于有
N
1
个元素的类
C
1
y
=
−
N
N
2
,
样例属于有
N
2
个元素的类
C
2
\left\{\begin{array}{l} \mathrm{y}=\frac{N}{N_{1}}, \text { 样例属于有 } N_{1} \text { 个元素的类 } C_{1} \\ \mathrm{y}=-\frac{N}{N_{2}}, \text { 样例属于有 } N_{2} \text { 个元素的类 } C_{2} \end{array}\right.
{y=N1N, 样例属于有 N1 个元素的类 C1y=−N2N, 样例属于有 N2 个元素的类 C2
就是将0/1做了值蔓换。
我们列出最小二乘法公式
E
=
1
2
∑
i
=
1
N
(
w
T
x
(
i
)
+
w
0
−
y
(
i
)
)
2
\mathrm{E}=\frac{1}{2} \sum_{i=1}^{N}\left(w^{T} x^{(i)}+w_{0}-y^{(i)}\right)^{2}
E=21∑i=1N(wTx(i)+w0−y(i))2
w
w
w 和
w
0
w_{0}
w0 是拟合权重参数。
分别对
w
0
w_{0}
w0 和
w
w
w 求导得
∑
i
=
1
N
(
w
T
x
(
i
)
+
w
0
−
y
(
i
)
)
=
0
\sum_{i=1}^{N}\left(w^{T} x^{(i)}+w_{0}-y^{(i)}\right)=0
∑i=1N(wTx(i)+w0−y(i))=0
∑
i
=
1
N
(
w
T
x
(
i
)
+
w
0
−
y
(
i
)
)
x
(
i
)
=
0
\sum_{i=1}^{N}\left(w^{T} x^{(i)}+w_{0}-y^{(i)}\right) x^{(i)}=0
i=1∑N(wTx(i)+w0−y(i))x(i)=0
从第一个式子展开可以得到
w
T
N
μ
+
N
w
0
−
∑
i
=
1
N
y
(
i
)
=
w
T
N
μ
+
N
w
0
−
(
N
1
N
N
1
−
N
2
N
N
2
)
=
0
w^{T} N \mu+N w_{0}-\sum_{i=1}^{N} y^{(i)}=w^{T} N \mu+N w_{0}-\left(N_{1} \frac{N}{N_{1}}-N_{2} \frac{N}{N_{2}}\right)=0
wTNμ+Nw0−i=1∑Ny(i)=wTNμ+Nw0−(N1N1N−N2N2N)=0
消元后,得
可以证明第二个式子展开后和下面的公式等价
其中
S
w
S_{w}
Sw 和
S
B
S_{B}
SB 与二值分关中的公式一样。
由于
S
B
w
=
(
μ
1
−
μ
2
)
∗
λ
w
S_{B} \mathrm{w}=\left(\mu_{1}-\mu_{2}\right) * \lambda_{w}
SBw=(μ1−μ2)∗λw
因此,最后结果仍然是
这个过程从几何意义上去理解也就是变形后的线性回归(将类标笈重新定义),线性回归后的直线方向就是 二值分关干LDA求得的直线方向
w
w
w 。
好了,我们从改变后的
y
y
y 的定义可以㺺出
y
>
0
y>0
y>0 属于关
C
1
,
y
<
0
C_{1} , y<0
C1,y<0 属于关籿
C
2
C_{2}
C2 。因此我们可以选取
y
0
=
0
y 0=0
y0=0 ,即如果
y
(
x
)
=
w
T
x
+
w
0
>
0
\mathrm{y}(\mathrm{x})=w^{T} x+w_{0}>0
y(x)=wTx+w0>0 ,就是栚
C
1
C_{1}
C1 ,否则是猋
C
2
C_{2}
C2 。
写了好多,挺杂的,还有个topic模型也叫做LDA,不过名字叫做Latent Dirichlet Allocation,第二作者就 是Andrew Ng大牛,最后一个他导师Jordan泰斗了,什么时候拜读后再写篇总结发上来吧。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)