GooLeNet-V4代码实现
GooLeNet-V4开发环境准备工作项目代码结构开发环境python–3.7torch–1.8+cu101torchsummarytorchvision–0.6.1+cu101PILnumpyopencv-pythonpillow准备工作Inception-ResNet-v2预训练模型权重下载地址:https://data.lip6.fr/cadene/pretrainedmodels/ince
·
GooLeNet-V4
开发环境
- python–3.7
- torch–1.8+cu101
- torchsummary
- torchvision–0.6.1+cu101
- PIL
- numpy
- opencv-python
- pillow
准备工作
Inception-ResNet-v2预训练模型权重下载地址:
https://data.lip6.fr/cadene/pretrainedmodels/inceptionresnetv2-520b38e4.pth
Inception-V4预训练模型权重下载地址:
https://data.lip6.fr/cadene/pretrainedmodels/inceptionv4-8e4777a0.pth
项目代码结构
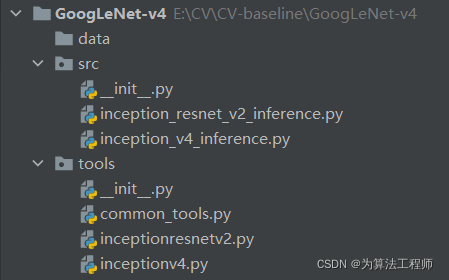
- data文件夹存储了Inception-ResNet-v2预训练模型权重文件、Inception-V4预训练模型权重文件和推理demo相关文件
- src存储了Inception-ResNet-v2推理程序文件和Inception-V4推理程序文件
- tools存储了Inception-ResNet-v2和Inception-V4的模型构建文件。
Inception-V4网络结构定义程序
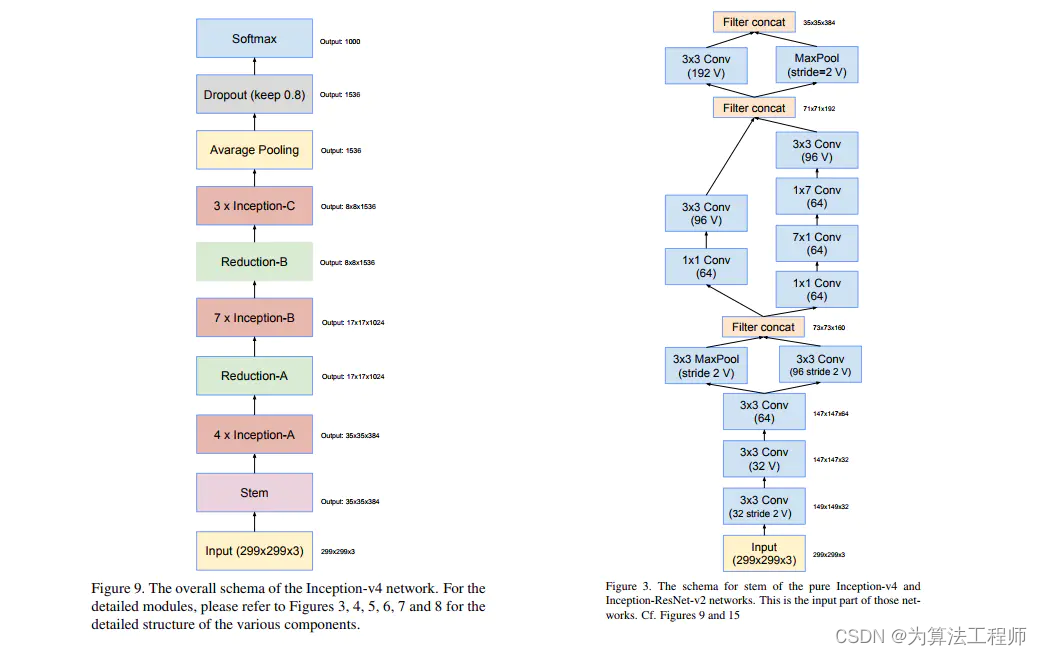
整体结构图及stem部分
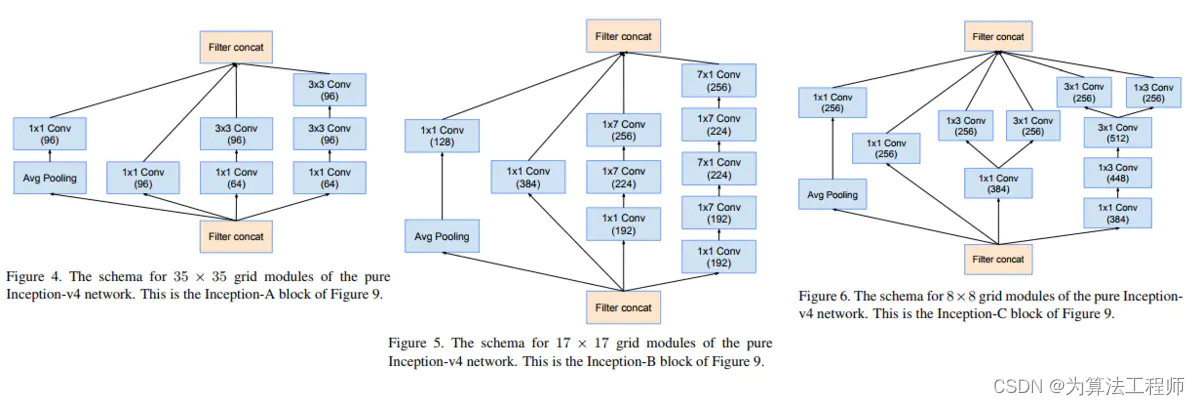
从左到右分别为Inception-v4中的 Inception A、 Inception B、 Inception C模块
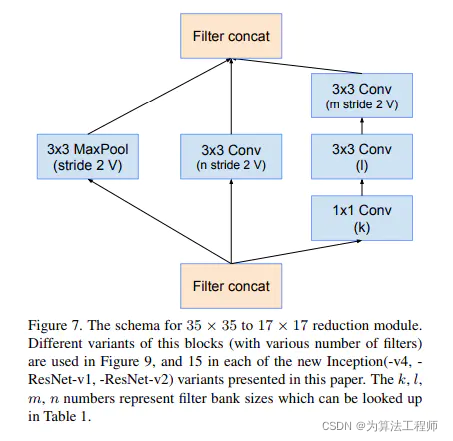
Inception-v4中的 Reduction模块
from __future__ import print_function, division, absolute_import
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.model_zoo as model_zoo
class InceptionV4(nn.Module):
def __init__(self, num_classes=1001):
super(InceptionV4, self).__init__()
# Special attributs
self.input_space = None
self.input_size = (299, 299, 3)
self.mean = None
self.std = None
# Modules
self.features = nn.Sequential(
# 1/6: Stem
BasicConv2d(3, 32, kernel_size=3, stride=2), # marked with V
BasicConv2d(32, 32, kernel_size=3, stride=1), # marked with V
BasicConv2d(32, 64, kernel_size=3, stride=1, padding=1), # not marked with V
Mixed_3a(),
Mixed_4a(),
Mixed_5a(),
# 2/6 Inception-A
Inception_A(),
Inception_A(),
Inception_A(),
Inception_A(),
# 3/6 Reduction-A
Reduction_A(), # Mixed_6a
# 4/6 Inception-B
Inception_B(),
Inception_B(),
Inception_B(),
Inception_B(),
Inception_B(),
Inception_B(),
Inception_B(),
# 5/6 Reduction-B
Reduction_B(), # Mixed_7a
# 6/6 Inception-C
Inception_C(),
Inception_C(),
Inception_C()
)
self.last_linear = nn.Linear(1536, num_classes)
def logits(self, features):
# Allows image of any size to be processed
adaptiveAvgPoolWidth = features.shape[2] # 这两行代码实现特征图池化到1*1大小
x = F.avg_pool2d(features, kernel_size=adaptiveAvgPoolWidth) # 这两行代码实现特征图池化到1*1大小
x = x.view(x.size(0), -1)
x = self.last_linear(x)
return x
def forward(self, input):
x = self.features(input)
x = self.logits(x)
return x
class BasicConv2d(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride, padding=0):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_planes,
out_planes,
kernel_size=kernel_size,
stride=stride,
padding=(padding, ),
bias=False) # verify bias false
self.bn = nn.BatchNorm2d(out_planes,
eps=0.001, # value found in tensorflow
momentum=0.1, # default pytorch value
affine=True)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
# Stem
class Mixed_3a(nn.Module):
def __init__(self):
super(Mixed_3a, self).__init__()
self.maxpool = nn.MaxPool2d(3, stride=2)
self.conv = BasicConv2d(64, 96, kernel_size=3, stride=2)
def forward(self, x):
x0 = self.maxpool(x)
x1 = self.conv(x)
out = torch.cat((x0, x1), 1)
return out
# Stem
class Mixed_4a(nn.Module):
def __init__(self):
super(Mixed_4a, self).__init__()
self.branch0 = nn.Sequential(
BasicConv2d(160, 64, kernel_size=1, stride=1),
BasicConv2d(64, 96, kernel_size=3, stride=1)
)
self.branch1 = nn.Sequential(
BasicConv2d(160, 64, kernel_size=1, stride=1),
BasicConv2d(64, 64, kernel_size=(1, 7), stride=1, padding=(0, 3)),
BasicConv2d(64, 64, kernel_size=(7, 1), stride=1, padding=(3, 0)),
BasicConv2d(64, 96, kernel_size=(3, 3), stride=1)
)
def forward(self, x):
x0 = self.branch0(x)
x1 = self.branch1(x)
out = torch.cat((x0, x1), 1)
return out
# Stem
class Mixed_5a(nn.Module):
def __init__(self):
super(Mixed_5a, self).__init__()
self.conv = BasicConv2d(192, 192, kernel_size=3, stride=2)
self.maxpool = nn.MaxPool2d(3, stride=2)
def forward(self, x):
x0 = self.conv(x)
x1 = self.maxpool(x)
out = torch.cat((x0, x1), 1)
return out
class Inception_A(nn.Module):
def __init__(self):
super(Inception_A, self).__init__()
self.branch0 = BasicConv2d(384, 96, kernel_size=1, stride=1)
self.branch1 = nn.Sequential(
BasicConv2d(384, 64, kernel_size=1, stride=1),
BasicConv2d(64, 96, kernel_size=3, stride=1, padding=1)
)
self.branch2 = nn.Sequential(
BasicConv2d(384, 64, kernel_size=1, stride=1),
BasicConv2d(64, 96, kernel_size=3, stride=1, padding=1),
BasicConv2d(96, 96, kernel_size=3, stride=1, padding=1)
)
self.branch3 = nn.Sequential(
nn.AvgPool2d(3, stride=1, padding=1, count_include_pad=False),
BasicConv2d(384, 96, kernel_size=1, stride=1)
)
def forward(self, x):
x0 = self.branch0(x)
x1 = self.branch1(x)
x2 = self.branch2(x)
x3 = self.branch3(x)
out = torch.cat((x0, x1, x2, x3), 1)
return out
class Reduction_A(nn.Module):
def __init__(self):
super(Reduction_A, self).__init__()
self.branch0 = BasicConv2d(384, 384, kernel_size=3, stride=2)
self.branch1 = nn.Sequential(
BasicConv2d(384, 192, kernel_size=1, stride=1),
BasicConv2d(192, 224, kernel_size=3, stride=1, padding=1),
BasicConv2d(224, 256, kernel_size=3, stride=2)
)
self.branch2 = nn.MaxPool2d(3, stride=2)
def forward(self, x):
x0 = self.branch0(x)
x1 = self.branch1(x)
x2 = self.branch2(x)
out = torch.cat((x0, x1, x2), 1)
return out
class Inception_B(nn.Module):
def __init__(self):
super(Inception_B, self).__init__()
self.branch0 = BasicConv2d(1024, 384, kernel_size=1, stride=1)
self.branch1 = nn.Sequential(
BasicConv2d(1024, 192, kernel_size=1, stride=1),
BasicConv2d(192, 224, kernel_size=(1, 7), stride=1, padding=(0, 3)),
BasicConv2d(224, 256, kernel_size=(7, 1), stride=1, padding=(3, 0))
)
self.branch2 = nn.Sequential(
BasicConv2d(1024, 192, kernel_size=1, stride=1),
BasicConv2d(192, 192, kernel_size=(7, 1), stride=1, padding=(3, 0)),
BasicConv2d(192, 224, kernel_size=(1, 7), stride=1, padding=(0, 3)),
BasicConv2d(224, 224, kernel_size=(7, 1), stride=1, padding=(3, 0)),
BasicConv2d(224, 256, kernel_size=(1, 7), stride=1, padding=(0, 3))
)
self.branch3 = nn.Sequential(
nn.AvgPool2d(3, stride=1, padding=1, count_include_pad=False),
BasicConv2d(1024, 128, kernel_size=1, stride=1)
)
def forward(self, x):
x0 = self.branch0(x)
x1 = self.branch1(x)
x2 = self.branch2(x)
x3 = self.branch3(x)
out = torch.cat((x0, x1, x2, x3), 1)
return out
class Reduction_B(nn.Module):
def __init__(self):
super(Reduction_B, self).__init__()
self.branch0 = nn.Sequential(
BasicConv2d(1024, 192, kernel_size=1, stride=1),
BasicConv2d(192, 192, kernel_size=3, stride=2)
)
self.branch1 = nn.Sequential(
BasicConv2d(1024, 256, kernel_size=1, stride=1),
BasicConv2d(256, 256, kernel_size=(1, 7), stride=1, padding=(0, 3)),
BasicConv2d(256, 320, kernel_size=(7, 1), stride=1, padding=(3, 0)),
BasicConv2d(320, 320, kernel_size=3, stride=2)
)
self.branch2 = nn.MaxPool2d(3, stride=2)
def forward(self, x):
x0 = self.branch0(x)
x1 = self.branch1(x)
x2 = self.branch2(x)
out = torch.cat((x0, x1, x2), 1)
return out
class Inception_C(nn.Module):
def __init__(self):
super(Inception_C, self).__init__()
self.branch0 = BasicConv2d(1536, 256, kernel_size=1, stride=1)
self.branch1_0 = BasicConv2d(1536, 384, kernel_size=1, stride=1)
self.branch1_1a = BasicConv2d(384, 256, kernel_size=(1, 3), stride=1, padding=(0, 1))
self.branch1_1b = BasicConv2d(384, 256, kernel_size=(3, 1), stride=1, padding=(1, 0))
self.branch2_0 = BasicConv2d(1536, 384, kernel_size=1, stride=1)
self.branch2_1 = BasicConv2d(384, 448, kernel_size=(3, 1), stride=1, padding=(1, 0))
self.branch2_2 = BasicConv2d(448, 512, kernel_size=(1, 3), stride=1, padding=(0, 1))
self.branch2_3a = BasicConv2d(512, 256, kernel_size=(1, 3), stride=1, padding=(0, 1))
self.branch2_3b = BasicConv2d(512, 256, kernel_size=(3, 1), stride=1, padding=(1, 0))
self.branch3 = nn.Sequential(
nn.AvgPool2d(3, stride=1, padding=1, count_include_pad=False),
BasicConv2d(1536, 256, kernel_size=1, stride=1)
)
def forward(self, x):
x0 = self.branch0(x)
x1_0 = self.branch1_0(x)
x1_1a = self.branch1_1a(x1_0)
x1_1b = self.branch1_1b(x1_0)
x1 = torch.cat((x1_1a, x1_1b), 1)
x2_0 = self.branch2_0(x)
x2_1 = self.branch2_1(x2_0)
x2_2 = self.branch2_2(x2_1)
x2_3a = self.branch2_3a(x2_2)
x2_3b = self.branch2_3b(x2_2)
x2 = torch.cat((x2_3a, x2_3b), 1)
x3 = self.branch3(x)
out = torch.cat((x0, x1, x2, x3), 1)
return out
InceptionResNetV2网络结构程序
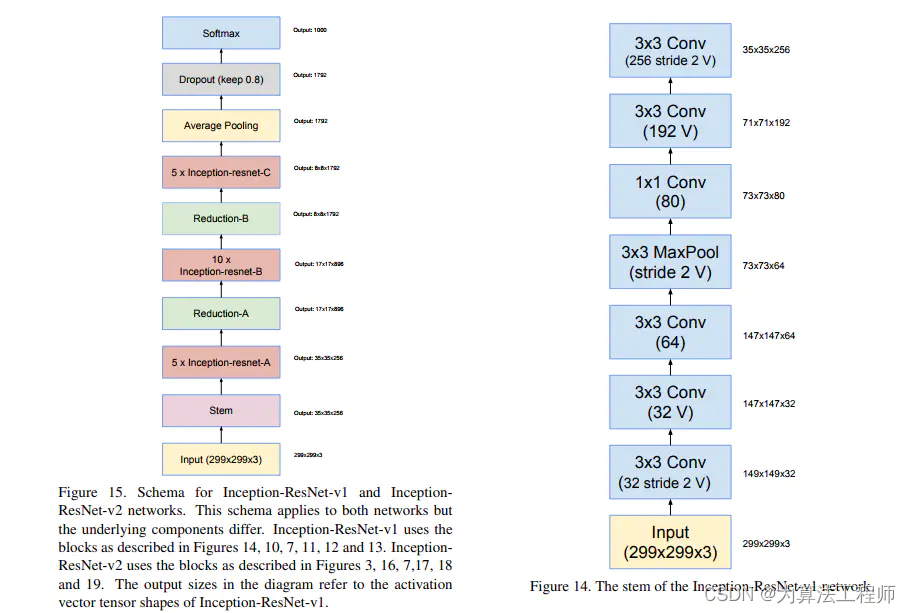

from __future__ import print_function, division, absolute_import
import torch
import torch.nn as nn
import torch.utils.model_zoo as model_zoo
class InceptionResNetV2(nn.Module):
def __init__(self, num_classes=1001):
super(InceptionResNetV2, self).__init__()
# Special attributs
self.input_space = None
self.input_size = (299, 299, 3)
self.mean = None
self.std = None
# Modules
# 1/6 Stem
self.conv2d_1a = BasicConv2d(3, 32, kernel_size=3, stride=2) # marked with V
self.conv2d_2a = BasicConv2d(32, 32, kernel_size=3, stride=1) # marked with V
self.conv2d_2b = BasicConv2d(32, 64, kernel_size=3, stride=1, padding=1) # not marked with V
self.maxpool_3a = nn.MaxPool2d(3, stride=2)
self.conv2d_3b = BasicConv2d(64, 80, kernel_size=1, stride=1)
self.conv2d_4a = BasicConv2d(80, 192, kernel_size=3, stride=1)
self.maxpool_5a = nn.MaxPool2d(3, stride=2)
# 2/6
self.mixed_5b = Mixed_5b() # 额外增加的
self.repeat = nn.Sequential( # Inception-resnet-A * 10, 论文是*5
Block35(scale=0.17),
Block35(scale=0.17),
Block35(scale=0.17),
Block35(scale=0.17),
Block35(scale=0.17),
Block35(scale=0.17),
Block35(scale=0.17),
Block35(scale=0.17),
Block35(scale=0.17),
Block35(scale=0.17)
)
# 3/6 Reduction-A figure7.
self.mixed_6a = Mixed_6a()
# 4/6 Inception-resnet-B * 20, figure17.
self.repeat_1 = nn.Sequential(
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10),
Block17(scale=0.10)
)
# 5/6 Reduction-B figure 18. 8*8*1792
self.mixed_7a = Mixed_7a()
# 6/6 Inception-C *9 figure 19.
self.repeat_2 = nn.Sequential(
Block8(scale=0.20),
Block8(scale=0.20),
Block8(scale=0.20),
Block8(scale=0.20),
Block8(scale=0.20),
Block8(scale=0.20),
Block8(scale=0.20),
Block8(scale=0.20),
Block8(scale=0.20)
)
self.block8 = Block8(noReLU=True)
self.conv2d_7b = BasicConv2d(2080, 1536, kernel_size=1, stride=1)
self.avgpool_1a = nn.AvgPool2d(8, count_include_pad=False)
self.last_linear = nn.Linear(1536, num_classes)
def features(self, input):
# 1/6 Stem: figure 14.
x = self.conv2d_1a(input) # 149*149*32
x = self.conv2d_2a(x) # 147*147*32
x = self.conv2d_2b(x) # 149*149*64
x = self.maxpool_3a(x) # 73*73*64
x = self.conv2d_3b(x) # 73*73*80
x = self.conv2d_4a(x) # 71*71*192
x = self.maxpool_5a(x) # 35*35*192
# 2/6 Inception-resnet-A: figure 16.
x = self.mixed_5b(x) # 35*35*320 标准Inception moudle, 额外增加的
x = self.repeat(x) # 35*35*320 论文是35*35*384
# 3/6 Reduction-A figure7.
x = self.mixed_6a(x) # 17*17*1088
# 4/6 Inception-resnet-B figure17.
x = self.repeat_1(x) # 17*17*1088
# 5/6 Reduction-B figure 18.
x = self.mixed_7a(x) # 8*8*2080
# 6/6 Inception-C figure 19.
x = self.repeat_2(x) # 8*8*2080
x = self.block8(x) # 该模块输出前未用Relu,原因未知
# 1*1卷积压缩特征图厚度:2080 --> 1536
x = self.conv2d_7b(x) # 8*8*1536
return x
def logits(self, features):
x = self.avgpool_1a(features) # 1*1*1536
x = x.view(x.size(0), -1) # 1536
x = self.last_linear(x) # 1000
return x
def forward(self, input):
x = self.features(input)
x = self.logits(x)
return x
class BasicConv2d(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride, padding=0):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_planes, out_planes,
kernel_size=kernel_size,
stride=stride,
padding=(padding,),
bias=False) # verify bias false
self.bn = nn.BatchNorm2d(out_planes,
eps=0.001, # value found in tensorflow
momentum=0.1, # default pytorch value
affine=True)
self.relu = nn.ReLU(inplace=False)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
# 标准Inception module
class Mixed_5b(nn.Module):
def __init__(self):
super(Mixed_5b, self).__init__()
# branch0: 1*1
self.branch0 = BasicConv2d(192, 96, kernel_size=1, stride=1)
# branch1: 1*1, 5*5
self.branch1 = nn.Sequential(
BasicConv2d(192, 48, kernel_size=1, stride=1),
BasicConv2d(48, 64, kernel_size=5, stride=1, padding=2)
)
# branch2: 1*1, 3*3, 3*3
self.branch2 = nn.Sequential(
BasicConv2d(192, 64, kernel_size=1, stride=1),
BasicConv2d(64, 96, kernel_size=3, stride=1, padding=1),
BasicConv2d(96, 96, kernel_size=3, stride=1, padding=1)
)
# branch3: avgPool, 1*1
self.branch3 = nn.Sequential(
nn.AvgPool2d(3, stride=1, padding=1, count_include_pad=False),
BasicConv2d(192, 64, kernel_size=1, stride=1)
)
def forward(self, x):
x0 = self.branch0(x)
x1 = self.branch1(x)
x2 = self.branch2(x)
x3 = self.branch3(x)
out = torch.cat((x0, x1, x2, x3), 1) # 96+64+96+64 = 320
return out
# figure 16.
class Block35(nn.Module):
def __init__(self, scale=1.0):
super(Block35, self).__init__()
self.scale = scale
self.branch0 = BasicConv2d(320, 32, kernel_size=1, stride=1)
self.branch1 = nn.Sequential(
BasicConv2d(320, 32, kernel_size=1, stride=1),
BasicConv2d(32, 32, kernel_size=3, stride=1, padding=1)
)
self.branch2 = nn.Sequential(
BasicConv2d(320, 32, kernel_size=1, stride=1),
BasicConv2d(32, 48, kernel_size=3, stride=1, padding=1),
BasicConv2d(48, 64, kernel_size=3, stride=1, padding=1)
)
self.conv2d = nn.Conv2d(128, 320, kernel_size=(1,), stride=(1,))
self.relu = nn.ReLU(inplace=False)
def forward(self, x):
x0 = self.branch0(x)
x1 = self.branch1(x)
x2 = self.branch2(x)
out = torch.cat((x0, x1, x2), 1)
out = self.conv2d(out)
out = out * self.scale + x
out = self.relu(out)
return out
# Reduction-A figure7.
class Mixed_6a(nn.Module):
def __init__(self):
super(Mixed_6a, self).__init__()
self.branch0 = BasicConv2d(320, 384, kernel_size=3, stride=2)
self.branch1 = nn.Sequential(
BasicConv2d(320, 256, kernel_size=1, stride=1),
BasicConv2d(256, 256, kernel_size=3, stride=1, padding=1),
BasicConv2d(256, 384, kernel_size=3, stride=2)
)
self.branch2 = nn.MaxPool2d(3, stride=2)
def forward(self, x):
x0 = self.branch0(x)
x1 = self.branch1(x)
x2 = self.branch2(x)
out = torch.cat((x0, x1, x2), 1)
return out
# Inception-resnet-B figure17.
class Block17(nn.Module):
def __init__(self, scale=1.0):
super(Block17, self).__init__()
self.scale = scale
self.branch0 = BasicConv2d(1088, 192, kernel_size=1, stride=1)
self.branch1 = nn.Sequential(
BasicConv2d(1088, 128, kernel_size=1, stride=1),
BasicConv2d(128, 160, kernel_size=(1, 7), stride=1, padding=(0, 3)),
BasicConv2d(160, 192, kernel_size=(7, 1), stride=1, padding=(3, 0))
)
self.conv2d = nn.Conv2d(384, 1088, kernel_size=1, stride=1) # 论文为1154,此处为1088,这个参数必须与输入的一样
self.relu = nn.ReLU(inplace=False)
def forward(self, x):
x0 = self.branch0(x)
x1 = self.branch1(x)
out = torch.cat((x0, x1), 1)
out = self.conv2d(out)
out = out * self.scale + x
out = self.relu(out)
return out
# Reduction-B figure 18.
class Mixed_7a(nn.Module):
def __init__(self):
super(Mixed_7a, self).__init__()
self.branch0 = nn.Sequential(
BasicConv2d(1088, 256, kernel_size=1, stride=1),
BasicConv2d(256, 384, kernel_size=3, stride=2)
)
self.branch1 = nn.Sequential(
BasicConv2d(1088, 256, kernel_size=1, stride=1),
BasicConv2d(256, 288, kernel_size=3, stride=2)
)
self.branch2 = nn.Sequential(
BasicConv2d(1088, 256, kernel_size=1, stride=1),
BasicConv2d(256, 288, kernel_size=3, stride=1, padding=1),
BasicConv2d(288, 320, kernel_size=3, stride=2)
)
self.branch3 = nn.MaxPool2d(3, stride=2)
def forward(self, x):
x0 = self.branch0(x)
x1 = self.branch1(x)
x2 = self.branch2(x)
x3 = self.branch3(x)
out = torch.cat((x0, x1, x2, x3), 1)
return out
# Inception-C figure 19.
class Block8(nn.Module):
def __init__(self, scale=1.0, noReLU=False):
super(Block8, self).__init__()
self.scale = scale
self.noReLU = noReLU
self.branch0 = BasicConv2d(2080, 192, kernel_size=1, stride=1)
self.branch1 = nn.Sequential(
BasicConv2d(2080, 192, kernel_size=1, stride=1),
BasicConv2d(192, 224, kernel_size=(1, 3), stride=1, padding=(0, 1)),
BasicConv2d(224, 256, kernel_size=(3, 1), stride=1, padding=(1, 0))
)
self.conv2d = nn.Conv2d(448, 2080, kernel_size=1, stride=1)
if not self.noReLU:
self.relu = nn.ReLU(inplace=False)
def forward(self, x):
x0 = self.branch0(x)
x1 = self.branch1(x)
out = torch.cat((x0, x1), 1)
out = self.conv2d(out)
out = out * self.scale + x
if not self.noReLU:
out = self.relu(out)
return out
inception_v4推理程序
import os
import time
import json
import torch
import torchvision.transforms as transforms
from PIL import Image
from matplotlib import pyplot as plt
from tools.common_tools import get_inception_v4
os.environ['NLS_LANG'] = 'SIMPLIFIED CHINESE_CHINA.UTF8'
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def img_transform(img_rgb, transform=None):
"""
将数据转换为模型读取的形式
:param img_rgb: PIL Image
:param transform: torchvision.transform
:return: tensor
"""
if transform is None:
raise ValueError("找不到transform!必须有transform对img进行处理")
img_t = transform(img_rgb)
return img_t
def process_img(path_img):
# hard code
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
inference_transform = transforms.Compose([
# transforms.Resize(256),
transforms.CenterCrop((299, 299)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# path --> img
img_rgb = Image.open(path_img).convert('RGB')
# img --> tensor
img_tensor = img_transform(img_rgb, inference_transform)
img_tensor.unsqueeze_(0) # chw --> bchw
img_tensor = img_tensor.to(device)
return img_tensor, img_rgb
def load_class_names(p_clsnames, p_clsnames_cn):
"""
加载标签名
:param p_clsnames:
:param p_clsnames_cn:
:return:
"""
with open(p_clsnames, "r") as f:
class_names = json.load(f)
with open(p_clsnames_cn, encoding='UTF-8') as f: # 设置文件对象
class_names_cn = f.readlines()
return class_names, class_names_cn
if __name__ == "__main__":
# config
path_state_dict_v4 = os.path.join(BASE_DIR, "..", "data", "inceptionv4-8e4777a0.pth")
# path_img = os.path.join(BASE_DIR, "..", "data","Golden Retriever from baidu.jpg")
path_img = os.path.join(BASE_DIR, "..", "data", "tiger cat.jpg")
path_classnames = os.path.join(BASE_DIR, "..", "data", "imagenet1000.json")
path_classnames_cn = os.path.join(BASE_DIR, "..", "data", "imagenet_classnames.txt")
# load class names
cls_n, cls_n_cn = load_class_names(path_classnames, path_classnames_cn)
# 1/5 load img
img_tensor, img_rgb = process_img(path_img)
# 2/5 load model
model = get_inception_v4(path_state_dict_v4, device, True)
# 3/5 inference tensor --> vector
with torch.no_grad():
time_tic = time.time()
outputs = model(img_tensor)
time_toc = time.time()
# 4/5 index to class names
_, pred_int = torch.max(outputs.data, 1)
_, top5_idx = torch.topk(outputs.data, 5, dim=1)
pred_idx = int(pred_int.cpu().numpy())
pred_str, pred_cn = cls_n[pred_idx], cls_n_cn[pred_idx]
print("img: {} is: {}\n{}".format(os.path.basename(path_img), pred_str, pred_cn))
print("time consuming:{:.2f}s".format(time_toc - time_tic))
# 5/5 visualization
plt.imshow(img_rgb)
plt.title("predict:{}".format(pred_str))
top5_num = top5_idx.cpu().numpy().squeeze()
text_str = [cls_n[t] for t in top5_num]
for idx in range(len(top5_num)):
plt.text(5, 15+idx*30, "top {}:{}".format(idx+1, text_str[idx]), bbox=dict(fc='yellow'))
plt.show()
inception_resnet_v2推理程序
import os
import time
import json
import torch
import torchvision.transforms as transforms
from PIL import Image
from matplotlib import pyplot as plt
from tools.common_tools import get_inception_resnet_v2
os.environ['NLS_LANG'] = 'SIMPLIFIED CHINESE_CHINA.UTF8'
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def img_transform(img_rgb, transform=None):
"""
将数据转换为模型读取的形式
:param img_rgb: PIL Image
:param transform: torchvision.transform
:return: tensor
"""
if transform is None:
raise ValueError("找不到transform!必须有transform对img进行处理")
img_t = transform(img_rgb)
return img_t
def process_img(path_img):
# hard code
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
inference_transform = transforms.Compose([
# transforms.Resize(256),
transforms.CenterCrop((299, 299)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# path --> img
img_rgb = Image.open(path_img).convert('RGB')
# img --> tensor
img_tensor = img_transform(img_rgb, inference_transform)
img_tensor.unsqueeze_(0) # chw --> bchw
img_tensor = img_tensor.to(device)
return img_tensor, img_rgb
def load_class_names(p_clsnames, p_clsnames_cn):
"""
加载标签名
:param p_clsnames:
:param p_clsnames_cn:
:return:
"""
with open(p_clsnames, "r") as f:
class_names = json.load(f)
with open(p_clsnames_cn, encoding='UTF-8') as f: # 设置文件对象
class_names_cn = f.readlines()
return class_names, class_names_cn
if __name__ == "__main__":
# config
path_state_dict_v2 = os.path.join(BASE_DIR, "..", "data", "inceptionresnetv2-520b38e4.pth")
path_img = os.path.join(BASE_DIR, "..", "data","Golden Retriever from baidu.jpg")
# path_img = os.path.join(BASE_DIR, "..", "data", "tiger cat.jpg")
path_classnames = os.path.join(BASE_DIR, "..", "data", "imagenet1000.json")
path_classnames_cn = os.path.join(BASE_DIR, "..", "data", "imagenet_classnames.txt")
# load class names
cls_n, cls_n_cn = load_class_names(path_classnames, path_classnames_cn)
# 1/5 load img
img_tensor, img_rgb = process_img(path_img)
# 2/5 load model
model = get_inception_resnet_v2(path_state_dict_v2, device, True)
# 3/5 inference tensor --> vector
with torch.no_grad():
time_tic = time.time()
outputs = model(img_tensor)
time_toc = time.time()
# 4/5 index to class names
_, pred_int = torch.max(outputs.data, 1)
_, top5_idx = torch.topk(outputs.data, 5, dim=1)
pred_idx = int(pred_int.cpu().numpy())
pred_str, pred_cn = cls_n[pred_idx], cls_n_cn[pred_idx]
print("img: {} is: {}\n{}".format(os.path.basename(path_img), pred_str, pred_cn))
print("time consuming:{:.2f}s".format(time_toc - time_tic))
# 5/5 visualization
plt.imshow(img_rgb)
plt.title("predict:{}".format(pred_str))
top5_num = top5_idx.cpu().numpy().squeeze()
text_str = [cls_n[t] for t in top5_num]
for idx in range(len(top5_num)):
plt.text(5, 15+idx*30, "top {}:{}".format(idx+1, text_str[idx]), bbox=dict(fc='yellow'))
print(text_str[idx])
plt.show()

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)