Python--随机森林模型
机器学习概念Bagging算法Boosting算法随机森林模型的基本原理随机森林模型的代码实现大数据分析与机器学习概念 集成学习模型:将多个模型组合在一起,从而产生更强大的模型 随机森林模型:非常典型的集成学习模型 集成模型简介: 集成学习模型使用一系列弱学习器(也称为基础模型或基模型)进行学习,并将各个弱学习器的结果进行整合,从而获得比单个学习器更好的学习效果。 集成学习模型的常见算法有Bagg
大数据分析与机器学习
概念
集成学习模型:将多个模型组合在一起,从而产生更强大的模型
随机森林模型:非常典型的集成学习模型
集成模型简介:
集成学习模型使用一系列弱学习器(也称为基础模型或基模型)进行学习,并将各个弱学习器的结果进行整合,从而获得比单个学习器更好的学习效果。
集成学习模型的常见算法有Bagging算法和 Boosting算法两种。
Bagging算法的典型机器学习模型为随机森林模型,而Boosting算法的典型机器学习模型则为AdaBoost、GBDT、XGBoost 和 LightGBM模型。
Bagging算法
Bagging的想法是采用类似于“民主投票”的方式,即每一个基础模型都有一票,最终结果通过所有基础模型投票,少数服从多数的原则产生预测结果。
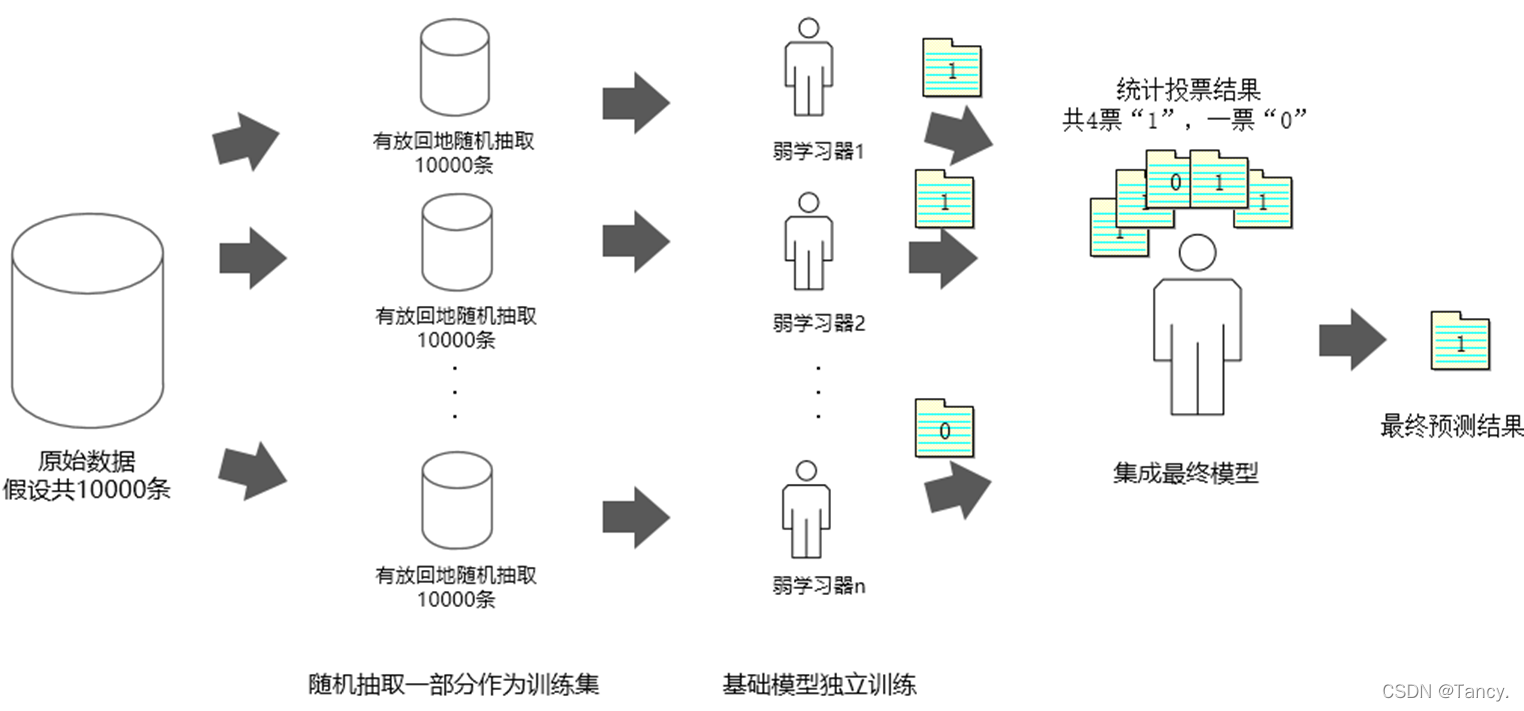
原理:从原始训练数据中(假设共有10000条数据),随机有放回地抽取10000次数据构成一个新的数据集(因为是随机有放回抽样,所以可能出现某一条数据多次被抽中,也有可能某一条数据一次也没有被抽中),每次使用一个训练样本训练一个基础模型。这样进行有放回的随机抽取n次后,训练结束时我们就能获得n个由不同的数据集训练的基础模型,也称之为n个弱学习器,根据这n个弱学习器的结果,我们可以获得一个更加准确合理的结果。
Boosting算法
Boosting算法的本质是将弱学习器提升为强学习器,
它和Bagging的区别在于,Bagging对待所有的基础模型一视同仁。而Boosting则做到了对于基础模型的“区别对待”
通俗来讲,Boosting算法注重“培养精英”和“重视错误”
-
“培养精英”,
即每一轮对于预测结果较为准确的基础模型,会给予它一个较大的权重,表现不好的基础模型则会降低它的权重。
这样在最终预测时,“优秀模型”的权重是大的,相当于它可以投出多票,而**“一般模型”只能在投票时投出一票或不能投票**。 -
“重视错误”
即在每一轮训练后改变训练数据的权值或概率分布,通过提高那些在前一轮被基础模型预测错误样例的权值,减小前一轮预测正确样例的权值,来使得分类器对误分的数据有较高的重视程度,从而提升模型的整体效果。原理如图:

随机森林模型的基本原理
随机森林(Random Forest)是一种经典的Bagging模型,其弱学习器为决策树模型。
如下图所示,随机森林模型会在原始数据集中随机抽样,构成n个不同的样本数据集,然后根据这些数据集搭建n个不同的决策树模型,最后根据这些决策树模型的平均值(针对回归模型)或者投票(针对分类模型)情况来获取最终结果。
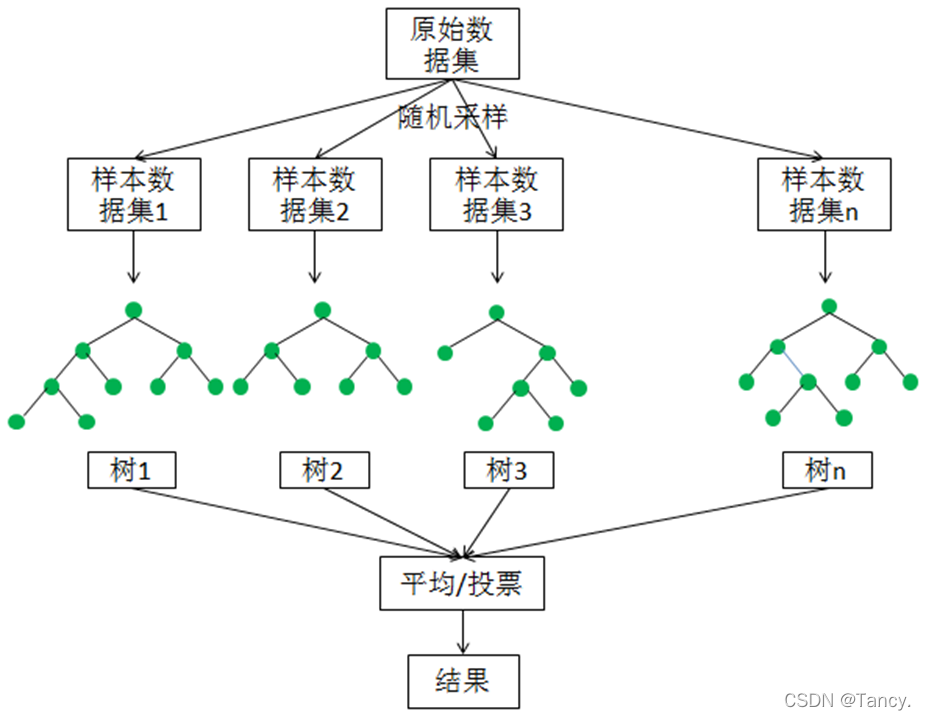
为了保证模型的泛化能力(或者说通用能力),随机森林在建立每棵树的时候,往往会遵循两个基本原则:
- 数据随机:随机地从所有数据当中有放回地抽取数据作为其中一棵决策树的数据进行训练。
举例来说,有1000个原始数据,有放回的抽取1000次,构成一组新的数据(因为是有放回抽取,有些数据可能被选中多次,有些数据可能不被选上),作为某一个决策树的数据来进行模型的训练。 - 特征随机:如果每个样本的特征维度为M,指定一个常数k<M,随机地从M个特征中选取k个特征,在使用Python构造随机森林模型时,默认取特征的个数k是M的平方根:√𝑀。
与单独的决策树模型对比,随机森林模型由于集成了多个决策树,其预测结果会更准确,且不容易造成拟合现象,泛化能力更强
随机森林模型的代码实现
随机森林和决策树模型一样,可以做分类分析,也可以做回归分析:
- 随机森林分类模型(RandomForestClassifier),随机森林分类模型的基模型是分类决策树模型
# 引入分类模型相关库
from sklearn.ensemble import RandomForestClassifier
# X 是特征变量,有五个训练数据,每个训练数据两个特征,所以特征值为2
X = [[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]]
# y 是目标变量,有两个分类
y = [0, 0, 0, 1, 1]
# 弱学习机器设置为 10 random_state=123 保证采用相同的节点划分方式,即运行的结果相同
model = RandomForestClassifier(n_estimators=10, random_state=123)
# 训练模型
model.fit(X, y)
# predict 函数进行预测
print(model.predict([[5, 5]]))
# 结果是0
- 随机森林回归模型(RandomForestRegressor),随机森林回归模型的基模型则是回归决策树模型
# 引入分类模型相关库
from sklearn.ensemble import RandomForestRegressor
# X 是特征变量,有五个训练数据,每个训练数据两个特征,所以特征值为2
X = [[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]]
# y 是目标变量,是一个连续值
y = [1, 2, 3, 4, 5]
# 弱学习机器设置为 10 random_state=123 保证采用相同的节点划分方式,即运行的结果相同
model = RandomForestRegressor(n_estimators=10, random_state=123)
# 训练模型
model.fit(X, y)
# predict 函数进行预测
print(model.predict([[5, 5]]))
# 结果是[2,8]

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)