
Pytorch实现U-net视网膜血管分割
网络结构U-net是MICCAI2015的专门针对医学影像分割设计的网络结构,直到今天还是很好用,效果任然很好。网络的左半部分是Encode部分,此部分将输入图像逐步下采样得到高层的语义信息。右半部分是Decoder部分,将Encode提取的语义特征逐步恢复为原始图像的尺寸,中间是跳跃连接,将下采样过程中提取到的不同level的特征加入到Decoder中,得到更好的分割结果。完整训练代码和数据可以
一键AI生成摘要,助你高效阅读
问答
·
网络结构

U-net是MICCAI2015的专门针对医学影像分割设计的网络结构,直到今天还是很好用,效果任然很好。网络的左半部分是Encode
部分,此部分将输入图像逐步下采样得到高层的语义信息。右半部分是Decoder部分,将Encode提取的语义特征逐步恢复为原始图像的尺寸,中间是跳跃连接,将下采样过程中提取到的不同level的特征加入到Decoder中,得到更好的分割结果。
完整训练代码和数据可以去我的github上面下载:https://github.com/SPECTRELWF/Semantic-Segmentation
个人主页:liuweifeng.top:8090
数据集介绍
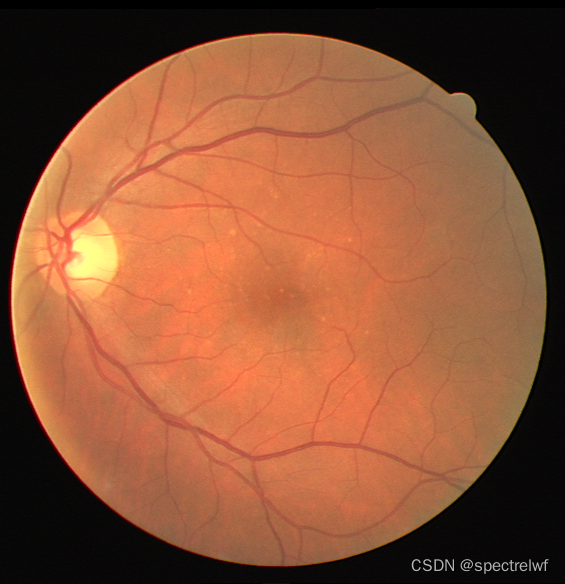

数据集是来自网上的视网膜血管分割数据集,训练集只有二十张图像,少得可怜。测试集也是二十张图像。原始数据集中image和label使用.tif和.gif格式存储的,需要先进行一下预处理,将数据组织成想要的样子,再来进行训练。
train
# !/usr/bin/python3
# -*- coding:utf-8 -*-
# Author:WeiFeng Liu
# @Time: 2021/12/9 下午1:54
from unet_model.unet import UNET
from dataset import SWXG_Dataset
import torch.optim as optim
import torch.nn as nn
import torch
def train_net(net,device,data_path,epochs=40,batch_size=1,lr=1e-5):
isbi_dataset = SWXG_Dataset(data_path)
train_loader = torch.utils.data.DataLoader(isbi_dataset,
batch_size,
shuffle = True)
#使用RMSprop优化
optimizer = optim.RMSprop(net.parameters(),lr,weight_decay=1e-8,momentum=0.9)
criterion = nn.BCEWithLogitsLoss()
best_loss = float("inf")
for epoch in range(epochs):
net.train()
for images, labels in train_loader:
optimizer.zero_grad()
images = images.to(device,dtype = torch.float32)
labels = labels.to(device,dtype=torch.float32)
pred = net(images)
loss = criterion(pred,labels)
print('epoch:%d train loss:%f' % (epoch+1,loss.item()))
if loss <best_loss:
best_loss = loss
torch.save(net.state_dict(), 'best_model.pth')
loss.backward()
optimizer.step()
if __name__ == "__main__":
device = torch.device('cuda:0')
net = UNET(n_channels=1,n_classes=1)
net.to(device)
data_path = r'Dataset/train/'
train_net(net,device,data_path)
结果:
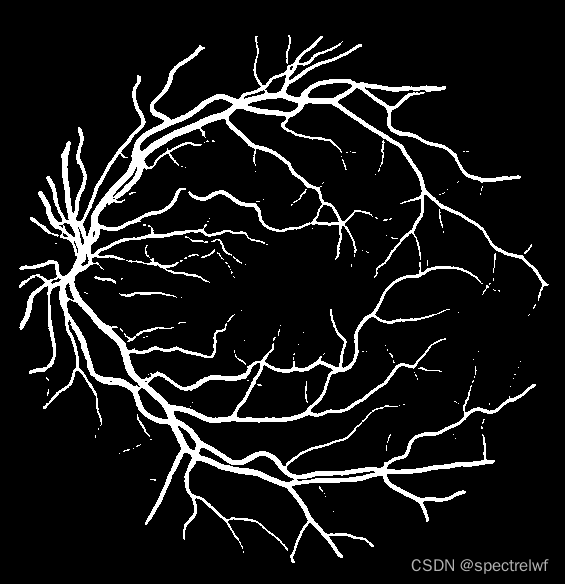
训练30个epoch之后的结果看起来还是很好的。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)