A State-of-the-Art Survey on Deep Learning Theory and Architectures论文翻译分析
A State-of-the-Art Survey on Deep Learning Theory and Architectures摘要近年来,深度学习在各种应用领域取得了巨大成功。机器学习这一新领域发展迅速,已应用于大多数传统应用领域,以及一些提供更多机会的新领域。基于不同类别的学习,人们提出了不同的方法,包括有监督、半监督和无监督学习。实验结果表明,在图像处理、计算机视觉、语音识别、机器翻译
A State-of-the-Art Survey on Deep Learning Theory and Architectures
摘要
近年来,深度学习在各种应用领域取得了巨大成功。机器学习这一新领域发展迅速,已应用于大多数传统应用领域,以及一些提供更多机会的新领域。基于不同类别的学习,人们提出了不同的方法,包括有监督、半监督和无监督学习。实验结果表明,在图像处理、计算机视觉、语音识别、机器翻译、艺术、医学成像、医学信息处理、机器人技术与控制、生物信息学、自然语言处理、网络安全和许多其他方面。本综述从深度神经网络(DNN)开始,简要介绍了深度学习(DL)领域的进展。调查还包括卷积神经网络(CNN)、递归神经网络(RNN),包括长短时记忆(LSTM)和门控循环归单元(GRU)、自动编码器(AE)、深度信念网络(DBN)、生成对抗网络(GAN)和深度强化学习(DRL)。此外,我们还讨论了最近的发展,例如基于这些DL方法的高级变体DL技术。这项工作考虑了自2012年深度学习历史开始以来发表的大部分论文。此外,本调查还包括在不同应用领域中探索和评估的DL方法。我们还包括最近开发的用于实施和评估深度学习方法的框架、SDK和基准数据集。在DL上发表了一些关于使用神经网络的调查和关于强化学习(RL)的调查。然而,这些论文没有讨论训练大规模深度学习模型的个别先进技术以及最近开发的生成模型方法。
keywords
深度学习;卷积神经网络;递归神经网络;自动编码器;受限玻尔兹曼机(RBM);深度信念网络;生成性对抗网络;深度强化学习;迁移学习
Introduction
自20世纪50年代以来,人工智能(AI)的一小部分,通常被称为机器学习(ML),在过去几十年中已经彻底改变了几个领域。神经网络(NN)是ML的一个子领域,正是这个子领域催生了深度学习(DL)。自DL诞生以来,它一直在制造越来越大的中断,几乎在每个应用领域都取得了卓越的成功。图1显示了AI的分类。DL使用深层学习体系结构或分层学习方法),是主要从2006年开始开发的一类ML。学习是一个过程,包括估计模型参数,以便学习的模型(算法)能够执行特定任务。例如,在人工神经网络(ANN)中,参数是权重矩阵。另一方面,DL由输入层和输出层之间的几层组成,这允许存在具有分层体系结构的多阶段非线性信息处理单元,用于特征学习和模式分类[1,2]。基于数据表示的学习方法也可以定义为表示学习[3]。最近的文献表明,基于DL的表征学习涉及一个特征或概念的层次结构,其中高层概念可以从底层概念中定义,而底层概念可以从高层概念中定义。在一些文章中,DL被描述为一种通用的学习方法,能够解决不同应用领域中的几乎所有问题。换句话说,DL不是特定于任务的[4]。
1.1.深度学习方法的类型
深度学习方法可分为以下几种:有监督、半监督或部分监督和无监督。此外,还有另一类称为强化学习(RL)或深度学习(DRL)的学习方法,通常在半监督或非监督学习方法的范围内讨论。图2显示了示意图。

1.1.1.深度监督学习 Deep Supervised Learning
监督学习是一种使用标记数据的学习技术。对于有监督的DL方法,环境有一组输入和相应的输出(xt,yt)-ρ. ,如果输入xt ,智能代理会预测y’t=f(xt), 代理将收到损失值l(yt,y’t). 然后,代理将迭代修改网络参数,以更好地逼近期望的输出。成功培训后,代理将能够从环境中获得问题的正确答案。有不同的深度学习监督学习方法,包括深度Neural网络(DNN)、卷积神经网络(CNN)、递归神经网络(RNN),包括长短时记忆(LSTM)和门控循环单元(GRU)。这些网络将在相应章节中详细描述。
1.1.2.深度半监督学习 Deep Semi-supervised Learning
半监督学习是基于部分标记数据集的学习。在某些情况下,DRL和生成性对抗网络(GAN)被用作半监督学习技术。GAN将在第7节中讨论。第8节概述了DRL方法。此外,RNN,包括LSTM和GRU,也用于半监督学习。
1.1.3.深度无监督学习 Deep Unsupervised Learning
无监督学习系统是一种可以在没有数据标签的情况下使用的系统。在这种情况下,代理学习内部表示或重要特征,以发现输入数据中的未知关系或结构。通常,聚类、降维和生成技术被认为是无监督的学习方法 。深度学习家族中有几个成员擅长聚类和非线性降维,包括自动编码器(AE)、受限玻尔兹曼机器(RBM)和最近开发的GAN。此外,RNN,如LSTM和RL,也用于许多应用领域的无监督学习。第6节和第7节详细讨论RNN和LSTM。
1.1.4.深度强化学习 Deep Reinforcement Learning (RL)
深度强化学习是一种用于未知环境的学习技术。DRL始于2013年,由Google Deep Mind[5,6]发起。从那时起,基于RL提出了几种先进的方法。以下是一个有关RL的示例:如果环境采样输入:xt-ρ, 代理预测:y’t=f(xt), 代理接收成本:ct-P(ct|xt,y’t) 其中P是未知概率分布,环境向代理询问一个问题,并给出一个噪声分数作为答案。有时这种方法也被称为半监督学习。有许多半监督和非监督技术都是基于这一概念实现的(见第8节)。在RL中,我们没有直接的损失函数,因此与传统的监督方法相比,学习更困难。RL和监督学习的根本区别在于:首先,您无法完全访问您试图优化的函数;您必须通过交互查询它们,其次,您正在与基于状态的环境交互:输入xt取决于以前的操作。
根据问题的范围或空间,可以决定需要应用哪种类型的RL来解决任务。如果问题有很多参数需要优化,DRL是最好的方法。如果问题具有较少的优化参数,则无导数RL方法是好的。退火、交叉熵方法和SPSA就是一个例子。

1.2.特征学习 Feature Learning
传统ML和DL之间的一个关键区别在于如何提取特征。传统的ML方法通过应用多种特征提取算法使用手工制作的工程特征,然后应用学习算法。此外,还提供了其他通常用于将多个学习算法应用于单个任务或数据集的特征,并根据不同算法的多个结果做出决策的情况的增强方法。
另一方面,在DL的情况下,特征会自动学习,并在多个级别上分层表示。这是DL相对于传统机器学习方法的优点。表1显示了具有不同学习步骤的不同基于特征的学习方法。

1.3. 为什么以及何时应用DL
DL用于机器智能有用的几种情况(见图3):
1.缺少人类专家(火星导航)
2.人类无法解释他们的专长(语音识别、视觉和语言理解)
3.问题的解决方案会随着时间的推移而变化(跟踪、天气预报、优先权、股票、价格预测)
4.解决方案需要适应特定情况(生物特征识别、个性化)。
5.对于我们有限的推理能力(计算网页排名、将广告与Facebook匹配、情绪分析),问题规模太大。
目前,DL在几乎所有领域都得到了应用。因此,这种方法通常被称为通用学习方法。
1.4. DL的艺术表现现状 The State-of-the-art Performance of DL
在计算机视觉和语音识别领域有一些杰出的成就,如下所述:
(a)基于ImageNet数据集的图像分类其中一个大规模问题被称为大规模视觉识别挑战(LSVRC)。CNN及其变体作为DL分支之一,在ImageNet任务中显示了最先进的准确性[7–12]。下图显示了DL Technologies在ImageNet-2012挑战赛上的成功案例。图3显示了ResNet-152已经实现了3.57%的错误率,超过了人类的准确性。


(b)自动语音识别。在流行的TIMIT数据集(通常用于评估的通用数据集)上的语音识别领域中,最初的成功在于小规模识别任务[24]。TIMIT声学语音连续语音语料库包含来自美国英语八种主要方言的630名说话人,每个说话人阅读10个句子。图4总结了错误率,包括这些早期结果,并以过去20年的电话错误率百分比(PER)来衡量。条形图清楚地显示了最近开发的DL与TIMIT数据集上以前的任何机器学习方法相比,这些方法(图的顶部)的性能更好。
图5和图6显示了一些示例应用程序。


为什么是DL?
1.5.1.通用学习方法
DL方法有时被称为通用学习,因为它几乎可以应用于任何应用领域。
1.5.2. Robust
深度学习方法不需要精确设计的功能。相反,对于手头的任务,会自动学习最佳特性。结果,实现了对输入数据的自然变化的鲁棒性。
1.5.3. Generalization
相同的DL方法可用于不同的应用程序或不同的数据类型。这种方法通常被称为迁移学习。此外,这种方法有助于解决没有足够的可用数据的问题。有许多文献讨论了这一概念(见第4节)。
1.5.4. Scalability
DL方法具有高度可扩展性。微软发明了一种称为ResNet的深层网络[11]。该网络包含1202层,通常以超级计算规模实现。劳伦斯·利弗莫尔国家实验室(LLNL)在开发类似网络的框架方面有一项重大举措,可以实现数千个节点[24]。
1.6.DL的挑战
DL面临几个挑战:
1.使用DL的大数据分析
2.DL方法的可伸缩性
3.生成数据的能力,这在数据不可用于学习系统的情况下非常重要(特别是对于计算机视觉任务,如反向图形)。
4.专用设备的节能技术,包括移动智能、FPGA等。
5.多任务和迁移学习或多模块学习。这意味着从不同领域或不同模型一起学习。
6.处理学习中的因果关系。
DL社区已经考虑了上述大部分挑战。首先,对于大数据分析挑战,2014年进行了一次很好的调查[30]。在本文中,作者详细解释了DL如何处理不同的标准,包括大数据问题的容量、速度、多样性和准确性。作者还展示了DL方法在处理大数据问题时的不同优势[31,32]。图7清楚地表明,传统的ML方法的性能在输入数据量较少的情况下显示出更好的性能。当数据量增加超过一定数量时,传统机器学习方法的性能变得稳定,而DL方法则随着数据量的增加而增加。

其次,在解决大规模问题的大多数情况下,解决方案都是在高性能计算(HPC)系统(超级计算、集群,有时被认为是云计算)上实施的,这为数据密集型业务计算提供了巨大的潜力。随着数据在速度、种类、准确性和容量上的爆炸式增长,使用企业级服务器和存储来扩展计算性能变得越来越困难。大多数文章都考虑了所有的需求,并建议使用异构计算系统实现高效的HPC。在一个例子中,劳伦斯·利弗莫尔国家实验室(LLNL)开发了一个称为利弗莫尔大型人工神经网络(LBANN)的框架,用于大规模应用DL的实现(超级计算规模),这显然取代了DL的可伸缩性问题[24]。
第三,生成模型是深度学习的另一个挑战。一个例子是GAN,它是任何任务的数据生成的杰出方法,可以生成具有相同分布的数据[33]。第四,我们在第7节讨论的多任务和迁移学习。第四,在网络体系结构和硬件方面,有很多关于节能深度学习方法的研究。第10节讨论了这个问题。
我们能否建立一个统一的模型来解决不同应用领域中的多个任务?就多模型系统而言,谷歌的一篇题为“一个模型学习所有模型”的文章[34]就是一个很好的例子。该方法可以从不同的应用领域学习,包括ImageNet、多翻译任务、图像字幕(MS-COCO数据集)、语音识别语料库和英语句法分析任务。我们将通过此次调查讨论大部分挑战和相应的解决方案。在过去几年中,还提出了一些其他多任务技术[35–37]。
最后,介绍了一个因果关系学习系统,它是一个图形模型,定义了如何从数据中推断因果模型。最近提出了一种基于DL的方法来解决此类问题[38]。然而,在过去几年中,还有许多具有挑战性的问题得到了解决,而这些问题在这场革命之前是不可能有效解决的。例如,图像或视频字幕[39],使用GAN将样式从一个域转移到另一个域[40],文本到图像合成[41],等等[42]。
最近在DL领域进行了一些调查[43–46]。这些论文综述了DL及其革命,但没有涉及最近发展起来的称为GAN的生成模型[33]。此外,他们讨论了很少的RL,没有涵盖DRL方法的最新趋势[1,44]。在大多数情况下,已进行的调查分别针对不同的DL方法。有一项基于强化学习方法的良好调查[46,47]。另一项关于迁移学习的调查[48]。对神经网络硬件进行了一次调查[49]。然而,这项工作的主要目标是提供关于深度学习及其相关领域的总体概念,包括深度监督(如DNN、CNN和RNN)、无监督(如AE、RBM、GAN)(有时GAN也用于半监督学习任务)和DRL。在某些情况下,DRL被视为半监督或非监督方法。此外,我们还考虑了该领域的最新发展趋势以及基于这些技术开发的应用。此外,我们还包括了经常用于评估深度学习技术的框架和基准数据集。此外,会议和期刊的名称也包括在内,该社区认为这些会议和期刊可用于发表其研究文章。
本文的其余部分按以下方式组织:第2节讨论了DNN的详细调查,第3节讨论了CNN。第4节描述了有效培训DL方法的不同高级技术。第5节讨论RNN。AEs和RBM在第6节中讨论。第7节讨论了具有应用程序的GAN。第8节介绍了RL。第9节解释了迁移学习。第10节介绍了DL的节能方法和硬接线。第11节讨论了深度学习框架和标准开发工具包(SDK)。第12节给出了具有web链接的不同应用程序域的基准。结论见第13节。
2.深度神经网络
2.1.DNN的历史
突出显示关键事件的神经网络的简要历史如图8所示。计算神经生物学在构建人工神经元的计算模型方面进行了重要的研究。试图模仿人脑行为的人工神经元是构建人工神经网络的基本组成部分。基本计算元素(神经元)称为节点(或单元),它接收来自外部源的输入,并具有一些产生输出的内部参数(包括训练期间学习的权重和偏差)。这个单位叫做感知器。参考文献[1,3]讨论了人工神经网络的基本原理。

ANN或一般NNs由多层感知器(MLP)组成,其中包含一个或多个隐藏层,其中包含多个隐藏单元(神经元)。有关MLP的详细信息,请参见参考文献[1,3,53]。
2.2.梯度下降
梯度下降法是一种一阶优化算法,用于寻找目标函数的局部极小值。在过去的几十年中,这已经成功地用于训练人工神经网络[1,53]。
2.3.随机梯度下降(SGD)
由于传统梯度下降法的主要缺点是训练时间长,因此SGD法用于训练深度神经网络(DNN)[1,58]。
2.4.反向传播(BP)
DNN使用流行的反向传播(BP)算法和SGD进行训练[47,53]。在MLP的情况下,我们可以很容易地使用计算图来表示NN模型,这些计算图是有向无环图。对于DL的表示,我们可以使用链式规则有效地使用BP计算从顶层到底层的梯度,如参考文献[53,59–63]所示。
2.5.推进力
动量法是一种有助于通过SGD方法加速训练过程的方法。其主要思想是使用梯度的移动平均值,而不是仅使用梯度的当前实际值。我们可以用以下方程式数学地表示:

这里是动量 γ 和动量 η 是第三轮培训的学习率。在过去几年中,还引入了其他流行的方法,这些方法在第九节“优化方法范围”中进行了解释。在训练期间使用动量的主要优点是防止网络陷入局部极小值。动量的值是γ∈ (0,1].值得注意的是,较高的动量值超过其最小值,可能使网络不稳定。通常,γ设置为0.5,直到初始学习稳定,然后增加到0.9或以上[60]。
2.6.学习率( η )
学习率是DNN训练的重要组成部分。学习率是训练过程中考虑的步长,它使训练过程更快。然而,选择学习率的值是敏感的。例如:如果选择的值较大㼿, 网络可能开始发散,而不是会聚。另一方面,如果您为㼿, 网络融合需要更多的时间。此外,它可能很容易陷入局部极小值。该问题的典型解决方案是降低培训期间的学习率[64]。
有三种常用的方法用于降低训练期间的学习率:常数衰减、因子衰减和指数衰减。首先,我们可以定义一个常数㼿 通过定义的步长函数手动降低学习率。第二,在培训期间,可以使用以下等式调整学习率:

其中ηt是tth轮学习率,η0是初始学习率, β 是衰减因子,其值介于(0,1)之间。
指数衰减的阶跃函数格式为:

通常的做法是使用衰减的学习率 β =0.1在每个阶段将学习率降低10倍。
2.7.重量衰减
作为L2正则化方法,权重衰减用于训练深度学习模型,这有助于防止过度拟合网络和模型泛化。L2正则化ℱ(θ,x) 可以定义为,
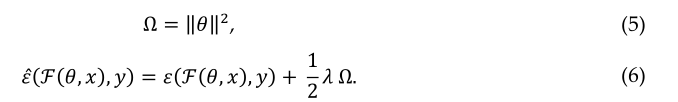
重量的梯度θ 是:

一般做法是使用值λ=0.00004。较小的 λ 将加速训练。
有效培训所需的其他组件,包括数据预处理和扩充、网络初始化方法、批量规范化、激活函数、带退出的正则化以及不同的优化方法(如第4节所述)。
在过去的几十年中,人们提出了许多有效的方法来更好地训练深层神经网络。在2006年之前,训练深层结构的尝试失败了:训练深层监督前馈神经网络的结果(无论是在训练还是在测试误差方面)往往比浅层(有1或2个隐藏层)更差。Hinton在DBNs方面的革命性工作在2006年率先改变了这一点[56,59]。
由于其组成,与浅层学习方法相比,多层DNN更能表示高度变化的非线性函数[62–65]。此外,由于特征提取和分类层的结合,DNN的学习效率更高。以下各节将详细讨论带有必要组件的不同DL方法。
3.卷积神经网络(CNN)
3.1.CNN概述
这种网络结构是福岛在1988年首次提出的[54]。然而,由于训练网络的计算硬件的限制,它没有得到广泛的应用。20世纪90年代,LeCun等人[55]将基于梯度的学习算法应用于CNN,并在手写数字分类问题上取得了成功的结果。之后,研究人员进一步改进了CNN,并在许多识别任务中报告了最新的结果。与DNN相比,CNN有几个优点,包括更像人类视觉处理系统,在处理2D和3D图像的结构上高度优化,以及在学习和提取2D特征的抽象方面有效。CNN的最大池层在吸收形状变化方面是有效的。此外,由稀疏连接和绑定权重组成的CNN的参数明显少于相同大小的完全连接网络。最重要的是,CNN采用基于梯度的学习算法进行训练,并且受梯度递减问题的影响较小。由于基于梯度的算法直接训练整个网络以最小化误差准则,CNN可以产生高度优化的权重。

较高级别的要素源自从较低级别图层传播的要素。当特征传播到最高层或级别时,特征的维数会根据卷积和最大池操作的内核大小而降低。然而,为了更好地表示输入图像的特征以确保分类精度,特征映射的数量通常会增加。CNN最后一层的输出用作完全连接网络的输入,该网络称为分类层。前馈神经网络被用作分类层,因为它们具有更好的性能[56,64]。在分类层,将提取的特征作为最终神经网络权值矩阵维数的输入。然而,完全连接的层在网络或学习参数方面是昂贵的。如今,有几种新技术,包括平均池和全局平均池,它们被用作全连接网络的替代方案。在顶部分类层中使用soft max层计算各个类别的分数。基于最高分数,分类器给出相应类的输出。下一节将讨论CNN不同层的数学细节。
3.1.1.卷积层
在该层中,来自前一层的特征映射与可学习的内核进行卷积。核的输出通过线性或非线性激活函数(如S形函数、双曲正切函数、Softmax函数、校正线性函数和单位函数)形成输出特征映射。每个输出特征映射可以与多个输入特征映射组合。一般来说,我们有
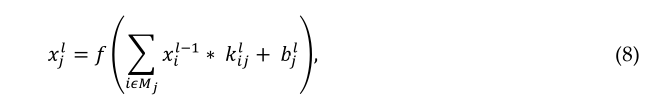
其中xil是当前层的输出,xil-1 是上一层的输出,kijl 是当前层的内核,并且bjl 是当前层的偏差。Mj 表示选择的输入映射。对于每个输出贴图,添加一个偏差 b 。但是,输入映射将使用不同的内核进行卷积,以生成相应的输出映射。输出贴图最终通过线性或非线性激活函数(例如,sigmoid、双曲正切、Softmax、校正线性或单位函数)。
3.1.2.次采样层
子采样层对输入贴图执行下采样操作。这通常称为池层。在该层中,输入和输出要素贴图的数量不变。例如,如果有 N 输入地图,然后就会有 N 输出地图。由于下采样操作,输出贴图的每个维度的大小将减小,具体取决于下采样掩码的大小。例如,如果使用2×2下采样内核,则每个输出维度将是所有图像对应输入维度的一半。此操作可表述为

其中down(.)表示子采样函数。此层中主要执行两种类型的操作:平均池或最大池。在采用平均池方法的情况下,该函数通常将前一层的特征地图的N×N个面片相加,并选择平均值。另一方面,在最大池的情况下,从特征地图的N×N面片中选择最大值。因此,输出映射维度减少了n倍。在某些特殊情况下,每个输出映射都与标量相乘。提出了一些可选的子采样层,如分数最大池层和卷积子采样层。第4.6节对此进行了解释。
3.1.3.分类层
这是一个完全连接的层,它根据前面步骤中从卷积层提取的特征计算每个类的分数。最后的图层特征图表示为带有标量值的矢量,这些标量值传递给完全连接的图层。将完全连接的前馈神经层用作软最大分类层。对于网络模型中包含的层数没有严格的规定。然而,在大多数情况下,在不同的体系结构中观察到两到四层,包括LeNet[55]、AlexNet[7]和VGG-Net[9]。由于完全连接的层在计算方面是昂贵的,在过去几年中提出了替代方法。其中包括全局平均池层和平均池层,这有助于显著减少网络中的参数数量。
在通过CNN的反向传播中,全连接层按照全连接神经网络(FCNN)的一般方法进行更新。通过对卷积层及其前一层之间的特征映射执行完全卷积运算,更新卷积层的滤波器。图10显示了输入图像的卷积和子采样中的基本操作。

3.1.4.CNN的网络参数和所需内存
计算参数的数量是衡量深度学习模型复杂性的一个重要指标。输出特征图的大小可按如下公式表示:

其中N表示输入特征图的尺寸,F表示滤波器或感受野的尺寸,M表示输出特征图的尺寸,S表示步幅长度。填充通常在卷积操作期间应用,以确保输入和输出特征映射具有相同的维度。填充量取决于内核的大小。等式17用于确定填充的行数和列数。
 这里P是填充量,F是内核的尺寸。比较模型时考虑了几个标准。然而,在大多数情况下,都会考虑网络参数的数量和内存总量。lth层的参数(Parml)个数根据以下公式计算:
这里P是填充量,F是内核的尺寸。比较模型时考虑了几个标准。然而,在大多数情况下,都会考虑网络参数的数量和内存总量。lth层的参数(Parml)个数根据以下公式计算:
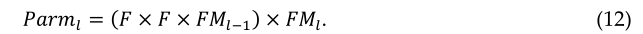
如果将偏差与权重相加,则上述方程可写成如下:
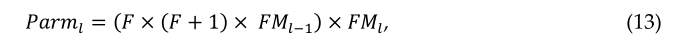
此处,lth的参数总数可用Pl表示,FMl表示输出特征图的总数,FMl-1表示输入特征图或通道的总数。例如,假设lth层有FMl-1=32个输入特征映射,FMl=64个输出特征映射,过滤器大小为F=5。在这种情况下,该层有偏差的参数总数为:Parml=(5×5×33)×64=528000。因此,lth层的操作所需的内存量(Meml)可以表示为:

3.2.流行的CNN架构
在本节中,将研究几种流行的最先进的CNN体系结构。通常,大多数深度卷积神经网络由一组关键的基本层组成,包括卷积层、子采样层、密集层和软最大层。该体系结构通常由几个卷积层和最大池层的堆栈组成,最后是一个完全连接的SoftMax层。此类模型的一些示例包括LeNet[55]、AlexNet[7]、VGG-Net[9]、NiN[66]和全卷积(全Conv)[67]。已经提出了其他替代方案和更高效的高级体系结构,包括DenseNet[68]、FractalNet[69]、具有初始单元的GoogLeNet[10,70,71]和剩余网络[11]。这些架构中的基本构建组件(卷积和池)几乎相同。然而,在现代深度学习体系结构中观察到一些拓扑差异。在许多DCNN体系结构中,AlexNet[7]、VGG[9]、GoogLeNet[10,70,71]、Dense CNN[68]和FractalNet[69]通常被认为是最流行的体系结构,因为它们在对象识别任务的不同基准上具有最先进的性能。在所有这些结构中,一些体系结构是专门为大规模数据分析而设计的(如GoogLeNet和ResNet),而VGG网络被认为是一种通用体系结构。有些体系结构在连通性方面非常密集,如DenseNet[68]。分形网络是ResNet模型的一种替代。
3.2.1. LeNet (1998)
尽管LeNet是在20世纪90年代提出的,但有限的计算能力和内存容量使得该算法直到2010年才得以实现[55]。然而,LeCun等人[55]提出了使用反向传播算法的CNN,并在手写数字数据集上进行了实验,以达到最先进的精度。提议的CNN架构被称为LeNet5[55]。LeNet-5的基本配置如下(见图11):两个卷积(conv)层、两个子采样层、两个完全连接的层和一个高斯连接的输出层。加权和乘法累加(MAC)的总数分别为431 k和2.3 M。
随着计算硬件的能力开始提高,CNN作为一种有效的学习方法在计算机视觉和机器学习领域变得越来越流行。

3.2.2. AlexNet (2012)
2012年,Alex Krizhevesky和其他人提出了一个比LeNet更深更广的CNN模型,并在2012年赢得了视觉对象识别方面最困难的ImageNet挑战,称为ImageNet大规模视觉识别挑战(ILSVRC)[7]。与所有传统的机器学习和计算机视觉方法相比,AlexNet实现了最先进的识别精度。这是机器学习和计算机视觉领域在视觉识别和分类任务方面的重大突破,也是对深度学习兴趣迅速增长的历史起点。
AlexNet的体系结构如图12所示。第一卷积层使用本地响应规范化(LRN)执行卷积和最大池,其中使用96个大小为11×11的不同接收滤波器。使用步长为2的3×3过滤器执行最大池操作。使用5×5滤波器在第二层执行相同的操作。3×3滤波器用于第三、第四和第五卷积层,分别具有384、384和296个特征映射。使用两个完全连接(FC)层,并在末尾使用一个Softmax层。对于该模型,两个具有相似结构和相同数量特征映射的网络被并行训练。在该网络中引入了两个新概念:局部响应规范化(LRN)和丢包。LRN可以以两种不同的方式应用:首先应用于单通道或特征贴图,其中从同一特征贴图中选择N×N面片,并基于邻域值进行归一化。其次,LRN可以跨通道或特征图应用(沿第三维的邻域,但只有一个像素或位置)。
AlexNet有三个卷积层和两个完全连接的层。在处理ImageNet数据集时,第一层AlexNet的参数总数可按如下方式计算:输入样本为224×224×3,滤波器(内核或掩码)或大小为11的感受野,步长为4,第一卷积层的输出为55×55×96。根据第3.1.4节中的方程式,我们可以计算出第一层有290400个(55×55×96)神经元和364个(11×11×3=363 1偏差)权重。第一卷积层的参数为290400×364=105705600。表2以百万为单位显示了每层的参数数量。整个网络的权重和MAC总数分别为61M和724M。
3.2.3. ZFNet / Clarifai (2013)
2013年,马修·泽勒(Matthew Zeiler)和罗伯·弗格(Rob Fergue)凭借作为AlexNet扩展的CNN架构赢得了2013年ILSVRC。该网络以作者的名字命名为ZFNet[8]。由于CNN的计算成本很高,因此从模型复杂性的角度来看,需要优化使用参数。ZFNet体系结构是AlexNet的改进,通过调整后者的网络参数来设计。ZFNet使用7x7内核而不是11x11内核来显著减少权重数量。这大大减少了网络参数的数量,提高了整体识别精度。
3.2.4. Network in Network (NiN)
该模型与之前引入了两个新概念的模型略有不同[66]。第一个概念是使用多层感知卷积,其中卷积使用1×1滤波器执行,这有助于在模型中添加更多非线性。这有助于增加网络的深度,然后可以通过退出来规范网络。这一概念通常用于深度学习模型的瓶颈层。
第二个概念是使用全局平均池(GAP)作为完全连接层的替代方案。这有助于显著减少网络参数的数量。GAP显著改变了网络结构。通过在大型特征地图上应用GAP,我们可以在不降低特征地图维数的情况下生成最终的低维特征向量。
3.2.5. VGGNET (2014)
视觉几何组(VGG)是2014年ILSVRC的亚军[9]。这项工作的主要贡献是,它表明网络的深度是CNN中实现更好的识别或分类精度的关键组成部分。VGG架构由两个卷积层组成,两个卷积层都使用ReLU激活功能。在激活功能之后是单个max pooling层,几个完全连接的层也使用ReLU激活功能。模型的最后一层是用于分类的Softmax层。在VGG-E[9]中,卷积滤波器的大小更改为3×3滤波器,跨步为2。三种VGG-E[9]型号,VGG-11、VGG-16和VGG-19;模型分为11层、16层和19层。VGG网络模型如图13所示。

VGG-E模型的所有版本都以三个完全连接的层结束。然而,不同卷积层数的VGG-11包含8个卷积层,VGG-16包含13个卷积层,VGG-19包含16个卷积层。VGG-19是计算成本最高的模型,其重量为138MW,重量为15.5 M MACS。
3.2.6. GoogLeNet (2014)
谷歌的Christian Szegedy提出了一种模型,其目的是与传统CNN相比,降低计算复杂度。提出的方法是合并具有可变感受野的起始层,这些感受野由不同的内核大小创建。这些感受野创建了捕获新特征映射堆栈中稀疏相关模式的操作
初始层的概念如图14所示。GoogLeNet使用一堆初始层提高了最先进的识别精度,如图15所示。初始初始层和最终初始层之间的区别在于增加了1x1卷积核。这些内核允许在计算昂贵的层之前进行降维。GoogLeNet总共由22层组成,远远超过之前的任何网络。[71]中提出了该网络的后续改进版本。然而,GoogLeNet使用的网络参数数量远低于其前身AlexNet或VGG。当AlexNet的网络参数为60M和VGG-19的网络参数为138M时,GoogLeNet的网络参数为7M。GoogLeNet的计算值也比AlexNet或VGG低1.53G MACs。
3.2.7. Residual Network (ResNet in 2015)
ILSVRC 2015的获胜者是剩余网络架构ResNet[11]。Resnet是由何开明开发的,其目的是设计超深网络,而不受前人所面临的消失梯度问题的影响。ResNet开发有许多不同的层;34,50,101,152,甚至1202。流行的ResNet50在网络末端包含49个卷积层和1个完全连接层。整个网络的权重和MAC总数为25.5M和3.9M。
ResNet体系结构的基本框图如图16所示。ResNet是一种传统的带有剩余连接的前馈网络。剩余层的输出可以基于(l-1)th的输出来定义,该输出来自定义为xl-1的前一层。ℱ(xl-1)是执行各种操作后的输出(例如,使用不同大小的过滤器进行卷积,批量标准化(BN),然后是激活函数,如xl-1上的ReLU)。剩余量的最终输出装置为xl,可通过以下等式定义:


残差网络由几个基本残差块组成。然而,残差块中的操作可以根据残差网络的不同架构而变化[11]。剩余网络的更广泛版本由Zagoruvko el提出。[72],另一种改进的残差网络方法称为聚合残差变换[73]。最近,基于剩余网络体系结构引入了剩余模型的一些其他变体[74–76]。此外,还有几种先进的体系结构与初始单元和剩余单元相结合。初始剩余单元的基本概念图如下图17所示。

从数学上讲,这个概念可以表示为
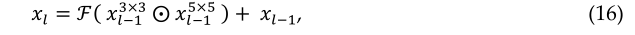 其中符号⨀指3×3和5×5过滤器两个输出之间的浓缩操作。然后,使用1×1滤波器执行卷积运算。最后,输出与该xl-1块的输入相加。在Inception-v4体系结构中引入了具有剩余连接的Inception块的概念[71]。还提出了初始残差网络的改进版本[76,77]。
其中符号⨀指3×3和5×5过滤器两个输出之间的浓缩操作。然后,使用1×1滤波器执行卷积运算。最后,输出与该xl-1块的输入相加。在Inception-v4体系结构中引入了具有剩余连接的Inception块的概念[71]。还提出了初始残差网络的改进版本[76,77]。
3.2.8. Densely Connected Network (DenseNet)
DenseNet由Gao等人于2017年开发[68],由密集连接的CNN层组成,每层的输出与密集块中的所有后续层连接[68]。因此,它是由各层之间的紧密连接形成的,因此得名为DenseNet。这个概念对于特征重用是有效的,这大大减少了网络参数。DenseNet由几个致密块体和过渡块体组成,它们位于两个相邻致密块体之间。密集区块的概念图如图18所示。

每个图层都将前面的所有要素地图作为输入。当解构图19时,lth 层接收到来自之前x0,x1,x2…xl-1层的所有特征图作为输入:

其中[x0,x1,x2…xl-1]是层 lth 的串联特征,H(∙)被视为单个张量。它执行三种不同的连续操作:Batch-Normalization(BN)[78],然后是ReLU[70]和3×3卷积操作。在事务块中,使用BN执行1×1卷积运算,后跟2×2平均池层。此新模型显示了最先进的准确性,并为对象识别任务提供了合理数量的网络参数。
3.2.9. FractalNet (2016)
该体系结构是ResNet模型的高级替代体系结构,可有效设计具有标称深度的大型模型,但训练期间梯度传播的路径较短[69]。这个概念是基于放置路径的,这是另一种制作大型网络的正则化方法。因此,这一概念有助于实现速度与精度的权衡。分形网的基本框图如Figure 19所示。

3.3. CapsuleNet
与最先进的手工特征检测器相比,CNN是检测对象特征和实现良好识别性能的有效方法。CNN有一些限制,即它没有考虑特征的特殊关系、透视、大小和方向。例如,如果您有一张人脸图像,CNN的神经元会错误地激活人脸的不同组件(鼻子、眼睛、嘴巴等)的位置并不重要,并且在不考虑特殊关系(方向、大小)的情况下识别为人脸。现在,想象一个神经元,它包含具有特征属性(透视、方向、大小等)的可能性。这种特殊类型的神经元,即胶囊,可以利用不同的信息有效地检测人脸。胶囊网络由几层胶囊节点组成。第一版胶囊网络(CapsNet)由编码单元中的三层胶囊节点组成。
对于MNIST(28×28)图像,256个9×9内核以步长1应用,因此输出为(28−9 +1=20),具有256个特征图。然后,输出被馈送到主胶囊层,主胶囊层是一个改进的卷积层,生成一个8-D矢量而不是标量。在第一个卷积层,9×9个核与步长2一起应用,输出维数为((20−9)/2+1=6). 初级胶囊使用8×32粒,产生32×8×6×6(32组,8个6×6大小的神经元)。

CapsNet的整个编码和解码过程分别如 Figures 20和21所示。我们经常在CNN中使用一个最大池层来处理翻译差异。即使某个功能在最大池窗口下移动,也可以检测到它。由于胶囊包含前一层特征的加权和,因此该方法能够检测重叠特征,这对于分割和检测任务非常重要。

在传统的CNN中,使用单一的代价函数来评估在训练过程中向后传播的总体误差。然而,在这种情况下,如果两个神经元之间的权重为零,则神经元的激活不会从该神经元传播。在具有协议的迭代动态路由中,信号根据特征参数而不是一刀切的代价函数进行路由。有关此体系结构的详细信息,请参阅参考文献[79]。CNN-MNIST提供了最新的手写数字识别体系结构。然而,从应用的角度来看,与分类任务相比,该体系结构更适合于分割和检测任务。
3.4.不同模型的比较
表2中给出了基于误差、网络参数和最大连接数的最近提出的模型的比较。
Table 2. The top-5% errors with computational parameters and macs for different deep CNN models.

3.5.其他DNN模型
还有许多其他的网络架构,例如基于快速区域的CNN[80]和Exception[81],它们在计算机视觉界很流行。2015年,提出了一种使用递归卷积层的新模型,称为递归卷积神经网络或RCNN[82]。该网络的改进版本结合了初始网络和递归卷积网络中两种最流行的架构,初始卷积递归神经网络(IRCNN)[83]。在网络参数几乎相同的情况下,与RCNN和初始网络相比,IRCNN提供了更好的精度。视觉相位引导CNN(ViP CNN)是通过相位引导消息传递结构(PMPS)来建立关系组件之间的连接而提出的,它显示了更好的速度和识别精度[84]。基于查找的CNN[85]是一种快速、紧凑、准确的模型,能够进行有效的推理。2016年,针对分段任务提出了称为全卷积网络(FCN)的架构,目前在[27]中普遍使用。最近提出的其他CNN模型包括像素网络[86],一种具有随机深度的深度网络,深度监督网络和梯形网络[87–89]。此外,CNN架构模型在[90]中进行了解释。有些文章发表在深度网络真的需要深度吗[91-93]。fitNet hits[94]、initialization method[95]、deep vs wide net[96]、大型培训集上的DL培训[97]、图形处理[98]、节能网络体系结构[99,100]上发表了一些文章。
3.6.CNNs的应用
3.6.1.求解图问题的CNNs
学习图形数据结构是数据挖掘和机器学习任务中各种应用中的一个常见问题。DL技术在机器学习和数据挖掘之间架起了一座桥梁。2016年提出了一种用于任意图形处理的高效CNN[101]。
3.6.2.图像处理与计算机视觉
我们上面讨论的大多数模型都应用于不同的应用领域,包括图像分类[7-11]、检测、分割、定位、字幕、视频分类等。对于图像处理和计算机视觉相关任务(包括图像分类、分割和检测)的DL方法有一个很好的综述[102]。例如,使用CNN方法的单图像超分辨率[103],使用块匹配CNN进行图像去噪[104],使用A-Lamp进行照片美学评估(自适应布局感知多批次深度CNN)[105],用于高光谱成像分割的DCNN[106],图像配准[107],快速艺术风格转移[108],使用DCNN进行图像背景分割[109]、手写字符识别[110]、光学图像分类[111]、使用高分辨率卫星图像进行裁剪映射[112]、使用蜂窝同步递归网络和CNN进行对象识别。与现有方法相比,DL方法大量应用于人类活动识别任务,并实现了最先进的性能[114–119]。但是,分类、分割和检测任务的最先进模型如下所示:
(1) 分类问题模型:根据分类模型的结构,输入图像采用卷积和子采样层进行不同的编码,最后使用SoftMax方法计算分类概率。上面讨论的大多数模型都应用于分类问题。然而,这些具有分类层的模型可以作为分割和检测任务的特征提取。分类模型列表如下:AlexNet[55]、VGGNet[9]、GoogleNet[10]、ResNet[11]、DenseNet[68]、FractalNet[69]、CapsuleNet[79]、IRCNN[83]、IRRCNN[77]、DCRN[120]等等。
(2) 切分问题的模型:在过去的几年中,已经提出了几种语义切分模型。分段模型由两个单元组成:编码单元和解码单元。在编码单元中,执行卷积和子采样操作以编码到低维潜在空间,其中解码单元从潜在空间解码图像,执行反卷积和上采样操作。第一个分割模型是完全卷积网络(FCN)[27121]。后来提出了该网络的改进版本,命名为SegNet[122]。最近提出了几种新模型,包括RefineNet[123]、PSPNEt[124]、DeepLab[125]、UNet[126]和R2U-Net[127]。
(3) 检测问题模型:与分类和分割问题相比,检测问题有点不同。在这种情况下,模型的目标是识别具有相应位置的目标类型。该模型回答了两个问题:对象是什么(分类问题)?对象在哪里(回归问题)?为了实现这些目标,在特征提取模块的顶部计算分类和回归单元的两个损失,并根据这两个损失更新模型权重。首次提出基于区域的CNN(RCNN)用于目标检测任务[128]。最近,有一些更好的检测方法被提出,包括密集目标探测器的焦损[129],后来提出了该网络的不同改进版本,称为快速RCNN,快速RCNN[80,130]。mask R-CNN[131],你只看一次(YOLO)[132],SSD:单次激发多盒检测器[133]和UD网络,用于从病理图像中检测组织[120]。
3.6.3.语音处理
CNN还应用于语音处理,例如使用多模态深度CNN进行语音增强[134],以及使用卷积选通递归网络(CGRN)进行音频标记[135]。
3.6.4.用于医学成像的CNN
Litjens等人[136]对用于医学图像处理的DL进行了很好的调查,包括分类、检测和分割任务。几种流行的DL方法被开发用于医学图像分析。例如,MDNet开发用于使用图像和相应的文本描述进行医学诊断[137],使用短轴MRI进行心脏分割[138],使用CNN进行视盘和视网膜血管分割[139],使用具有完全卷积神经网络学习特征的随机森林进行脑肿瘤分割(FCNN)[140]。这些技术已应用于计算病理学领域,并取得了最先进的性能[28,29,120,141]。
4.先进的训练技术
需要仔细考虑的高级培训技术或组件,以便有效地培训DL方法。有不同的先进技术可用于更好地培养深度学习模式。这些技术包括输入预处理、更好的初始化方法、批量标准化、可选卷积方法、高级激活函数、可选池技术、网络正则化方法和更好的训练优化方法。以下各节分别讨论了个人高级培训技巧。
4.1.准备数据集
目前,在将数据传送到网络之前,已经采用了不同的方法。准备数据集的不同操作如下:样本重缩放、均值减法、随机裁剪、相对于地平线或纵轴翻转数据、颜色抖动、PCA/ZCA白化等。
4.2.网络初始化
深度网络的初始化对整体识别精度有很大影响[59,60]。以前,大多数网络都是用随机权重初始化的。对于具有高维数据训练的复杂任务,DNN变得困难,因为由于反向传播过程,权重不应对称。因此,有效的初始化技术对于训练此类DNN非常重要。然而,在过去几年中,有许多有效的技术被提出。LeCun[142]和Bengio[143]提出了一种简单但有效的方法。在他们的方法中,权重通过层的输入神经元数量的平方根的倒数来缩放,可以表示为1/√Nl,其中Nl是 lth 层的输入神经元数量。基于线性假设下的对称激活函数,提出了Xavier的深度网络初始化方法。这种方法称为Xavier初始化方法。最近,Dmytro M.等人[95]提出了层序列单元不变性(LSUV),这是一种数据驱动的初始化方法,在包括ImageNet在内的多个基准数据集上提供了良好的识别精度。He等人于2015年提出了一种流行的初始化方法[144]。lth 层的权重分布将为均值为零、方差为2/nl的正态分布,其可表示为:

4.3.批量标准化
批处理规范化通过移动输入样本来减少内部协方差,从而帮助加速DL过程。这意味着输入被线性转换为零均值和单位方差。对于白化输入,网络收敛速度更快,并且在训练期间表现出更好的正则性,这对整体精度有影响。由于数据白化是在网络之外执行的,因此在模型训练期间没有白化的影响。对于深度递归神经网络,第nth层的输入是第n-1th层的组合,这不是原始特征输入。随着训练的进行,归一化或白化的效果分别降低,从而导致消失梯度问题。这会减慢整个训练过程并导致饱和。为了更好地训练过程,然后将批量归一化应用于深层神经网络的内部层。这种方法确保了在理论上和在基准测试中更快地收敛。在批量标准化中,层的特征用均值零和方差一独立标准化[78145146]。算法一给出了批量归一化的算法。

参数 γ 和 β 用于规格化值的比例和移位因子,因此规格化不仅取决于图层值。如果使用规范化技术,建议在执行过程中考虑以下准则:
· 提高学习率
· 丢弃(批量标准化执行相同的任务)
· L2权正则化
· 加速学习速度衰减
· 删除本地响应规范化(LRN)(如果使用)
· 更彻底地洗牌训练样本
· 训练集中图像的无用失真
4.4.交替卷积法
已经提出了将乘法成本降低2.5倍的替代和计算效率高的卷积技术[147]。
4.5.激活函数
在过去的几十年中,传统的Sigmoid和Tanh激活函数被用于实现神经网络方法。图形和数学表示如Figure22所示。


2010年提出的称为校正线性单元(ReLU)的流行激活函数解决了用于训练深度学习方法的消失梯度问题。基本概念很简单,可以将所有值保持在零以上,并将所有负值设置为零,如图23所示[64]。ReLU激活首次用于AlexNet[7]。

从数学上讲,我们可以将ReLU表示为:

因为激活函数在学习深度体系结构的权重时起着至关重要的作用。许多研究人员把重点放在这里,因为在这方面可以做很多事情。同时,已经提出了几种改进的ReLU版本,与图24所示的ReLU激活功能相比,它们提供了更好的精度。ReLU激活函数的有效改进版本称为参数ReLU(PReLU),由He Kaiming等人于2015年提出。图25显示了泄漏ReLU和ELU激活函数的图示。这种技术可以自适应地自动学习参数,并在不增加计算成本的情况下提高精度[144]。

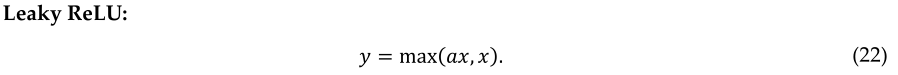
在这里 a 是一个常量,值为0.1。

最近提出的指数线性单位激活函数,使得DCNN结构的速度更快、更准确[148]。此外,调整激活函数的负部分会产生最近提出的具有多指数线性单元(MELU)的泄漏ReLU[149]。2015年提出了S形整流线性激活装置[150]。2015年对现代激活功能进行了调查[151]。

4.6.子采样层或池层
目前,有两种不同的技术用于在子采样或池层实现深度网络:平均池和最大池。LeNet[55]首次使用了平均池层的概念,AlexNet使用了最大池层,而不是2012年[7]。最大池和平均池操作的概念图如图25所示。2014年,He等人提出了特殊金字塔池的概念,如图26[152]所示。
2015年提出了多规模金字塔式联营[153]。2015年,Benjamin G.提出了一种具有分数最大池的新体系结构,它为CIFAR-10和CIFAR-100数据集提供了最先进的分类精度。这种结构通过考虑子采样层或池层的两个重要属性来概括网络。首先,非重叠最大池层限制了网络深层结构的推广,本文提出了一个3x3重叠最大池2步网络,而不是2×2作为子采样层[154]。另一篇论文对不同类型的池方法进行了研究,包括混合、选通和树作为池函数的推广[155]。

4.7.DL的正则化方法
在过去几年中,针对深度CNN提出了不同的正则化方法。Hinton在2012年提出了最简单但有效的辍学方法[156]。在退出中,层内随机选择的激活子集设置为零[157]。辍学概念如图27所示。

另一种正则化方法称为Drop-Connect。在这种情况下,不是放弃激活,而是将网络层中的权重子集设置为零。因此,每一层从上一层接收随机选择的单元子集[158]。还提出了一些其他正则化方法[159]。
4.8.DL的优化方法
有不同的优化方法,如SGD、Adagrad、AdaDelta、RMSprop和Adam[160]。对一些激活函数进行了改进,例如在SGD的情况下,提出了一种增加可变动量的激活函数,从而提高了训练和测试的准确性。在Adagrad的案例中,主要贡献是计算训练期间的自适应学习率。对于该方法,考虑梯度大小的总和来计算自适应学习率。在有大量纪元的情况下,梯度大小的总和变大。其结果是学习速度急剧下降,导致梯度迅速接近零。这种方法的主要缺点是在培训过程中会产生问题。后来,RMSprop的提出仅考虑了上一次迭代的梯度大小,从而避免了Adagrad的问题,并在某些情况下提供了更好的性能。提出了基于动量和梯度大小的Adam优化方法,用于计算类似RMSprop的自适应学习速率。Adam提高了整体精度,并通过深度学习算法的更好收敛性帮助有效训练[161]。最近提出了Adam优化方法的改进版本,称为EVE。EVE通过快速准确的收敛提供了更好的性能[162]。
5.递归神经网络(RNN)
5.1. Introduction
人的思想具有恒久性;人类不会把一件东西扔掉,然后在一秒钟内从头开始思考。当你阅读这篇文章时,你会在理解之前的单词或句子的基础上理解每个单词或句子。传统的神经网络方法,包括DNN和CNN不能处理这类问题。由于以下原因,标准的神经网络和CNN无法使用。首先,这些方法只处理固定大小的向量作为输入(例如,图像或视频帧),并产生固定大小的向量作为输出(例如,不同类别的概率)。其次,这些模型使用固定数量的计算步骤(例如,模型中的层数)。RNN是唯一的,因为它们允许在一段时间内对向量序列进行操作。Hopfield Newark在1982年引入了这一概念,但1974年很快就描述了这一想法[163]。图示如图28所示。
约旦和埃尔曼提出了不同版本的RNN[164165]。在Elman中,体系结构将隐藏层的输出与隐藏层的正常输入一起用作输入[129]。另一方面,来自输出单元的输出与Jordan网络中隐藏层的输入一起用作输入[130]。相比之下,Jordan使用输出单元输出的输入和隐藏层的输入。数学上表示为:
埃尔曼网络[1164]:
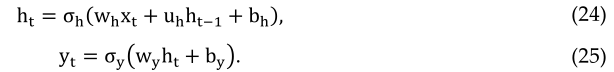
约旦网络[165]:
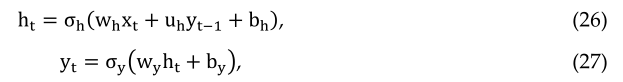
其中xt是输入向量,ht是隐藏层向量,yt是输出向量,w和u是权重矩阵,b是偏置向量。
循环允许信息从网络的一个步骤传递到下一个步骤。一个递归神经网络可以被认为是同一网络的多个副本,每个网络向后续网络传递一条消息。下图29显示了如果展开循环会发生什么。

RNN方法的主要问题是存在消失梯度问题。Hochreiter等人首次解决了这个问题[166]。1993年,为了解决深度学习任务,实施并评估了由1000个后续层组成的深度RNN[167]。在过去的几十年中,有几种解决方案被提出用于解决RNN方法的消失梯度问题。对于这个问题有两种可能的有效解决方案,第一种是裁剪梯度,如果范数太大,则缩放梯度,第二种是创建更好的RNN模型。其中一个更好的模型是由Felix A.el at介绍的。2000年命名为长短时记忆(LSTM)[168169]。从LSTM开始,在过去几年中提出了不同的高级方法,这些方法将在以下章节中解释。LSTM图如图30所示。
RNN在输入、输出或在最一般的情况下两者中接近允许的序列。例如,对于文本挖掘,在文本数据上构建深度学习模型需要表示基本的文本单元和单词。可以分层捕获文本顺序性质的神经网络结构。在大多数情况下,RNN或递归神经网络用于语言理解[170]。在语言建模中,它试图预测下一个单词或一组单词,或基于前一个单词或单词或句子的某些情况[171]。RNN是带有环路的网络,允许信息持久化。另一个例子:RNN能够将以前的信息连接到当前任务:使用以前的视频帧,理解当前,并尝试生成将来的帧[172]。

5.2.长短时记忆(LSTM)
LSTMs的关键思想是单元状态,水平线贯穿图31的顶部。LSTM删除或向称为门的单元状态添加信息:输入门(it)、遗忘门(ft)和输出门(ot)可定义为:

LSTM模型是时态信息处理的常用模型。大多数论文都包含有一些微小差异的LSTM模型。其中一些将在下一节中讨论。Gers和Schimidhuber在2000年提出了一种略加修改的带有窥视孔连接的网络版本[168]。窥视孔的概念包含在该模型中几乎所有的门控设备中。

5.3.门控循环单元(GRU)
GRU也来自LSTM,变异稍大[173]。GRU现在在社区中很受欢迎,他们与经常性网络合作。流行的主要原因是模型的计算成本和简单性,如图31所示。
就拓扑结构、计算成本和复杂性而言,GRU比标准LSTM更轻版本的RNN方法[173]。该技术将遗忘门和输入门组合成一个更新门,并将单元格状态和隐藏状态以及其他一些更改合并在一起。GRU的简单模型越来越受欢迎。从数学上讲,GRU可以用以下方程式表示:
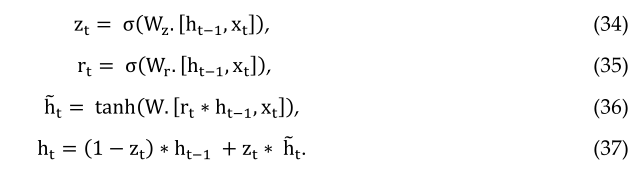
问题是哪一个是最好的?根据不同的实证研究,没有明确的证据表明胜利者。然而,GRU需要更少的网络参数,这使得模型速度更快。另一方面,如果您有足够的数据和计算能力,LSTM可以提供更好的性能[174]。有一个名为Deep LSTM的变体LSTM[175]。另一种有点不同的方法称为发条RNN[176]。对RNN方法的不同版本进行了重要的实证评估,包括Greff等人的LSTM。2015年[177]得出的最终结论是,所有LSTM变体都大致相同[177]。对数千种RNN体系结构进行了另一次实证评估,包括LSTM、GRU等,发现其中一些在某些任务上比LSTM工作得更好[178]
5.4.卷积LSTM (ConvLSTM)
完全连接(FC)LSTM和短FC-LSTM模型的问题在于处理时空数据及其在输入到状态和状态到状态事务中使用的完全连接,其中没有对空间信息进行编码。CONVLSM的内部门是3D张量,其中最后两个维度是空间维度(行和列)。CONVLSM确定网格中某个单元的未来状态,该状态与输入及其本地邻居的过去状态有关,可通过状态到状态或输入到状态转换中的卷积操作实现,如图32所示。

CONVLSM为视频数据集的时态数据分析提供了良好的性能[172]。ConvLSTM在数学上表示如下,其中*表示卷积运算,而∘ 表示Hadamard产品:

5.5.RNN结构的一种变体,并针对其应用进行了相应的研究
为了将注意机制与RNN结合起来,Word2Vec在大多数情况下用于单词或句子编码。Word2vec是一种功能强大的单词嵌入技术,具有来自原始文本输入的两层预测神经网络。这种方法被用于不同的应用领域,包括单词的无监督学习、不同单词之间的关系学习、基于相似性提取单词更高含义的能力、句子建模、语言理解等。在过去几年中,人们提出了不同的其他单词嵌入方法,用于解决困难的任务并提供一流的性能,包括机器翻译和语言建模、图像和视频字幕以及时间序列数据分析[179–181]。
从应用的角度来看,RNN可以解决不同类型的问题,这些问题需要不同的RNN体系结构,如图33所示。在图33中,输入向量表示为绿色,RNN状态表示为蓝色,橙色表示输出向量。这些结构可以描述为:
一对一:无RNN分类的标准模式(如图像分类问题),如图33(a)
多对一:输入序列和单个输出(例如,情感分析,其中输入是一组句子或单词,输出是积极或消极的表达),如图33b所示。
一对多:系统接收输入并产生一系列输出(图像字幕问题:输入是单个图像,输出是一组具有上下文的单词),如图33c所示。
多对多:输入和输出序列(例如,机器翻译:机器从英语中提取一个单词序列并翻译成法语中的一个单词序列),如图33d所示。
多对多:序列对序列学习(例如,视频分类问题,其中我们将视频帧作为输入,并希望标记图33e所示视频的每一帧)。

5.6.基于注意的RNN模型
使用RNN方法提出了不同的基于注意的模型。Xu等人于2015年提出了RNN的第一个倡议,其关注点是自动学习描述图像内容[182]。提出了一种基于双状态注意的RNN,用于有效的时间序列预测[183]。另一项困难的任务是使用GRU的可视化问答(VQA),其中输入是图像和关于图像的自然语言问题,任务是提供准确的自然语言答案。输出以图像和文本输入为条件。CNN用于对图像进行编码,RNN用于对句子进行编码[184]。谷歌发布了另一个杰出的概念,称为像素递归神经网络(Pixel RNN)。这种方法为图像完成任务提供了最先进的性能[185]。提出了称为剩余RNN的新模型,其中RNN在深度递归网络中引入有效的剩余连接[186]。
5.7.RNN应用
RNN,包括LSTM和GRU,用于张量处理[187]。使用RNN技术的自然语言处理,包括LSTMs和GRUs[188189]。2017年提出了基于多语言识别系统的卷积RNN[190]。使用RNNs进行时间序列数据分析[191]。最近,基于预先训练的深度RNN提出了时间网,用于时间序列分类(TSC)[192]。语音和音频处理,包括用于大规模声学建模的LSTM[193194]。使用卷积RNN进行声音事件预测[195]。使用卷积GRU的音频标记[196]。建议使用RNNs进行早期心力衰竭检测[197]。
RNN应用于跟踪和监控:使用图卷积RNN(GCRNN)[25]提出了数据驱动的交通预测系统。提出了一种基于LSTM的神经网络流量预测系统[198]。双向深度RNN应用于驾驶员行为预测[199]。使用RNN进行车辆轨迹预测[200]。使用带有一袋单词的RNN进行动作识别[201]。使用LSTM进行网络安全收集异常检测[202]。
6.自动编码器(AE)和受限玻尔兹曼机(RBM)
本节将讨论一种无监督的深度学习方法——自动编码器[61](例如,变分自动编码器(VAE)[203],去噪AE[65],稀疏AE[204],叠加去噪AE[205],裂脑AE[206])。本章最后还讨论了不同声发射的应用。
6.1.自动编码器(AE)综述
AE是一种用于无监督特征学习的深度神经网络方法,具有高效的数据编码和解码。autoencoder的主要目标是学习和表示(编码)输入数据,通常用于数据降维、压缩、融合等。这种自动编码器技术由两部分组成:编码器和解码器。在编码阶段,输入样本通常映射在低维特征空间中,具有构造性特征表示。这种方法可以重复,直到达到所需的特征尺寸空间。而在解码阶段,我们通过反向处理从低维特征中重新生成实际特征。具有编码和解码阶段的自动编码器的概念图如图34所示。
编码器和解码器转换可以用∅ 和φ, ∅∶ Χ→ℱ 和φ∶ ℱ→ Χ, 然后
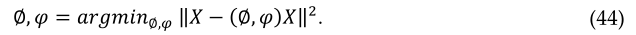
如果我们考虑一个简单的带有一个隐藏层的自动编码器,在那里输入是x∈ℝd=Χ, 它被映射到∈ℝp=ℱ, 然后可以表示为:

其中W为权重矩阵,b为偏差。σ1 表示元素激活函数,例如sigmoid或整流线性单元(RLU)。让我们考虑一下 z 再次映射或重构到 x’ 哪一个维度是相同的x。 重建可以表示为:

该模型以最小化重建误差为目标进行训练,其定义为损失函数,如下所示:
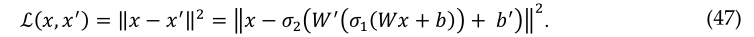
通常,图像的特征空间 ℱ 尺寸小于输入要素空间 X, 可以将其视为输入样本的压缩表示。在多层自动编码器的情况下,将根据需要在编码和解码阶段重复相同的操作。通过扩展具有多个隐藏层的编码器和解码器来构造深度自动编码器。梯度消失问题对于更深层次的AE模型来说仍然是一个大问题:当梯度通过AE模型的许多层时,它变得太小。下文将讨论不同的高级AE模型。
6.2.可变自动编码器(VAEs)
第7节讨论了使用简单生成对抗网络(GAN)的一些局限性。首先,使用GAN从输入噪声生成图像。如果有人想要生成特定的图像,那么很难随机选择特定的特征(噪声)来生成所需的图像。它需要搜索整个发行版。第二,机关区分“真”和“假”物体。例如,如果要生成一只狗,则不存在狗必须看起来像狗的约束。因此,它产生了与狗一样的风格图像,但如果我们仔细观察,则不完全相同。然而,VAE的提出是为了克服基本GANs的这些限制,其中潜在向量空间用于表示遵循单位高斯分布的图像[203,207]。VAE的概念图如图35所示。

在该模型中,有两种损失,一种是确定网络重建图像效果的均方误差,另一种是潜在变量的损失(Kullback-Leibler(KL)散度),它确定潜在变量匹配与单位高斯分布的紧密程度。例如,假设 x 是一个输入,隐藏表示为z。参数(权重和偏差)为θ。重建相位时,输入为z,期望输出为x。参数(权重和偏差)为 Φ。因此,我们可以将编码器分别表示为qθ(z|x)和解码器pΦ(z|x)。 网络和潜在空间的损失函数可以分别表示为:
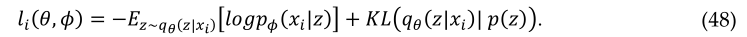
6.3. Split-Brain 自动编码器
最近,伯克利人工智能研究(BAIR)实验室提出了分裂脑AE,这是对传统无监督表征学习自动编码器的结构改进。在这种架构中,网络被分成不相交的子网络,其中两个网络试图预测整个图像的特征表示[206]。下图36显示了分割大脑自动编码器的概念。

6.4.声发射技术的应用
AE应用于生物信息学[136,208]和网络安全[209]。我们可以应用AE进行无监督的特征提取,然后应用赢家通吃(WTA)对这些样本进行聚类以生成标签[210]。在过去的十年中,AE作为编码和解码技术与其他深度学习方法一起使用,包括CNN、DNN、RNN和RL。但是,以下是最近发布的一些其他方法[207,211]
6.5.受限玻尔兹曼机器(RBM)综述
受限玻尔兹曼机器(RBM)是另一种无监督的深度学习方法。训练阶段可以使用称为受限Boltzmann机器[212]的两层网络建模,其中随机二进制像素使用对称加权连接连接到随机二进制特征检测器。RBM是一种基于能量的无向生成模型,它使用一层隐藏变量来模拟可见变量的分布。隐变量和可见变量之间相互作用的无向模型用于确保似然项对隐变量后验值的贡献近似为阶乘,这大大方便了推理[213]。受限玻尔兹曼机器(RBM)的概念图如图37所示:

基于能量的模型意味着感兴趣的变量的概率分布是通过能量函数定义的。能量函数由一组可观测变量s组成V={vi} 和一组隐藏变量={ℎi} , 其中,i是可见层中的节点,j是隐藏层中的节点。在没有可见或隐藏连接的意义上,它受到限制。RBM的可见单元对应的值,因为它们的状态被观察到;特征检测器对应于隐藏单元。联合配置,(v,h)可见和隐藏单位的能量(Hopfield,1982)由以下公式得出:
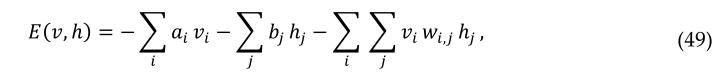
其中vi,hj是可见单元 i 和隐藏单元 j 的二元状态,ai,bj是它们的偏差,wij是它们之间的权重。网络通过该能量函数为可视向量和隐藏向量的可能对分配概率:

其中,配分函数,Z , 通过对所有可能的可见和隐藏向量对求和得到:

网络分配给可见向量v的概率通过对所有可能的隐藏向量求和得到:

可以通过调整权重和偏差来提高网络分配给训练样本的概率,以降低该样本的能量,并提高其他样本的能量,尤其是那些能量较低的样本,从而对配分函数做出很大贡献。训练向量的对数概率相对于权重的导数非常简单。
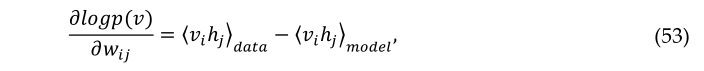
其中,尖括号用于表示以下下标指定分布下的期望值。这导致了一个简单的学习规则,用于在训练数据的对数概率中执行随机最陡上升:
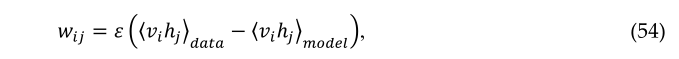
式中ε为学习率。给定一个随机选择的训练图像,v,二进制状态,ℎj, 对于每个隐藏单元,j以概率设置为1
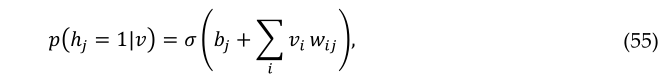
其中σ(x)是逻辑S型函数1/(1+e(-x)),vi,hj则是无偏样本。由于RBM中的可见单元之间没有直接联系,因此在给定隐藏向量的情况下,也很容易获得可见单元状态的无偏样本
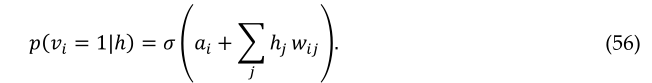
获得〈vihi〉model的无偏样本要困难得多。它可以通过在可见单元的任意随机状态下开始并执行长时间的交替吉布斯采样来完成。它可以通过在可见单元的任意随机状态下开始并执行长时间的交替吉布斯采样来完成。交替吉布斯采样的单个迭代包括使用等式(55)并行更新所有隐藏单元,然后使用以下等式(56)并行更新所有可见单元。Hinton(2002)提出了更快的学习程序。首先,将可见单元的状态设置为训练向量。然后,使用方程(55)并行计算隐藏单元的二进制状态。一旦为隐藏单元选择了二进制状态,则通过设置每个状态来生成重构 vi 以等式(56)给出的概率为1。重量的变化由下式给出:
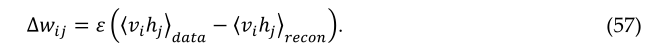
相同学习规则的简化版本使用单个单元的状态,而不是成对乘积,用于偏差[214]。该方法主要用于以无监督的方式对神经网络进行预训练以生成初始权重。在此基础上提出了一种最流行的深度学习方法,称为深度信念网络(DBN)。显示了RBM和DBN在数据编码、新闻聚类、图像分割和网络安全方面的一些应用示例,详情见参考文献[57,215-217]。
7.生成性对抗网络(GAN)
在本章的开头,我们引用了Yann LeCun的一句话,GAN是过去十年在深度学习(神经网络)领域提出的最好的概念。
7.1.GAN研究综述
机器学习中的生成模型概念由来已久,它被用于条件概率密度函数的数据建模。通常,这种类型的模型被视为概率模型,在观测值和目标(标签)值上具有联合概率分布。然而,我们以前没有看到这种生成模式的巨大成功。近年来,基于深度学习的生成模型在不同的应用领域得到了广泛的应用,并取得了巨大的成功。
深度学习是一种数据驱动技术,随着输入样本数量的增加,它的性能会更好。由于这个原因,从大量的联合国标签数据集中学习可重用的特征表示已经成为一个活跃的研究领域。我们在导言中提到,计算机视觉具有不同的任务、分割、分类和检测,这需要大量的标记数据。这个问题一直试图通过生成模型生成相似的样本来解决。
生成性对抗网络(GAN)是古德费罗在2014年发明的一种深度学习方法。GANs为最大似然估计技术提供了一种替代方法。GAN是一种无监督的深度学习方法,其中两个神经网络在零和博弈中相互竞争。在图像生成问题的情况下,生成器从高斯噪声开始生成图像,鉴别器确定生成的图像的质量。此过程将继续,直到生成器的输出接近实际输入样本。根据图38,可以认为鉴别器(D)和生成器(G)是两个播放器有V(D,G)函数的最小-最大博弈的玩家,根据本文[33,218]可以表示如下:

在实践中,该方程可能无法在早期阶段为学习G(从随机高斯噪声开始)提供足够的梯度。在早期阶段,D可以拒绝样本,因为它们与训练样本明显不同。在这种情况下,log(1−D(G(z))将饱和。而不是训练G以最小化 log(1−D(G(z)))我们可以训练G使 log(G(z))目标函数最大化,从而在学习的早期阶段提供更好的梯度。但是,在使用第一版的培训过程
中,存在一些收敛的限制。在初始状态下,GAN在以下问题上有一些限制:
· 缺乏启发式成本函数(像素近似表示平方误差(MSE))
· 训练不稳定(有时可能是因为产生无意义的输出)
GANs领域的研究一直在进行中,提出了许多改进版本[219]。GANs能够为应用程序生成照片级真实感图像,例如室内或工业设计、鞋、包和服装项目的可视化。GAN还广泛应用于游戏开发和人工视频生成领域[220]。GAN有两个不同的DL领域,它们分为半监督和非监督。这些领域的一些研究侧重于GAN架构的拓扑结构,以改进功能和训练方法。深卷积GAN(DCGAN)是2015年提出的一种基于卷积的GAN方法[221]。与无监督方法相比,这种半监督方法已显示出良好的效果。DCGAN的再生结果如下图所示[183]。根据[221]中的文章,图39显示了通过数据集进行一次训练后生成的卧室图像的输出。本节中包含的大多数图形都是通过实验生成的。理论上,该模型可以学习记忆训练示例,但这在实验上不太可能,因为我们使用小学习率和小批量SGD进行训练。我们注意到,之前没有经验证据表明SGD的记忆能力和较小的学习率[221]。


在图40中,根据[221]中的文章,顶部行在Z中的一系列九个随机点之间插值,并显示学习空间具有平滑过渡。在每张图片中,空间看起来都像卧室。在第六排,你看到一个没有窗户的房间慢慢变成了一个有巨大窗户的房间。在第十排,你可以看到一台电视正在慢慢地转变成一个窗口。下图41显示了潜在空间向量的有效应用。通过先执行加法和减法运算,然后进行解码,可以将潜在空间向量转换为意义输出。根据[221]中的文章,图41显示了一个戴眼镜的男人减去一个男人,再加上一个女人,结果是一个戴眼镜的女人。

图42,根据[221]中的文章,显示了一个转向向量是从四个平均样本中创建的,这些样本分别是左看和右看。通过沿该随机样本轴添加插值,可以可靠地变换姿势。有一些有趣的应用已经被提议用于GANs。例如,使用改进的GANs 结构生成自然的室内场景。这些CANS学习表面法线,并与Wang和Gupta的 GANs 组合[222]。在这个实现中,作者考虑了名为(S2GAN)的GAN的样式和结构,它生成一个曲面法线贴图。这是GAN的改进版本。2016年,提出了一个名为InfoGAN的GAN信息论扩展。infoGAN可以以完全无监督的方式使用更好的表示进行学习。实验结果表明,无监督InfoGAN与采用完全监督学习方法的表示学习具有竞争性[223]。
2016年,Im等人[224]提出了另一种新架构,其中反复出现的概念包含在训练期间的对抗网络中。Chen等人[225]提出了信息处理(iGAN),允许在自然图像流形上交互操作图像。2017年提出使用条件对抗网络进行图像到图像的翻译。GANs的另一个改进版本称为耦合生成对抗网络(COGA),它是多域图像的学习联合分布。现有方法不需要训练集中不同域中对应图像的元组[226]。双向生成性对抗性网络(BIGAN)通过反向特征映射学习,结果表明,所学习的特征表示对于辅助监督鉴别任务非常有用,与当代的无监督和自监督特征学习方法相竞争[227]。

最近,谷歌提出了一种称为边界平衡生成对抗网络(BEARED)的GANs扩展版本,该版本采用了一种简单但健壮的架构[228]。Start具有更好的训练过程,收敛速度快且稳定。平衡的概念有助于平衡鉴别器对发电机的功率。此外,它还可以平衡图像多样性和视觉质量之间的平衡[228]。另一项类似的工作称为Wasserstein GAN(WGAN)算法,该算法显示出比传统GAN显著的优势[229]。与传统的GANs相比,WGANs有两大优势。首先,WGAN有意义地将损失度量与生成器的收敛性和样本质量相关联。其次,WGANs提高了优化过程的稳定性。
WGAN的改进版本是通过一种新的剪裁技术提出的,该技术惩罚了批评家相对于其输入的梯度法线[230]。基于生成模型提出了一种很有前景的架构,其中图像由未经培训的DNN表示,这为更好地理解和可视化DNN提供了机会[231]。还介绍了生成模型的对抗性示例[232]。基于能源的GAN由Facebook的Yann LeCun于2016年提出[233]。GANs的训练过程比较困难,流形匹配GAN(MMGAN)提出了更好的训练过程,并在三个不同的数据集上进行了实验,实验结果清楚地证明了MMGAN相对于其他模型的有效性[234]。GAN采用有效的训练方法进行地统计学模拟和反演[235]。
概率GAN(PGAN)是一种具有改进目标函数的新型GAN。该方法背后的主要思想是将概率模型(高斯混合模型)集成到支持可能性而非分类的GAN框架中[236]。具有贝叶斯网络模型的GAN[237]。变分自动编码是一种流行的深度学习方法,使用对抗性变分贝叶斯(AVB)进行训练,这有助于建立VAE和GAN之间的原理联系[238]。基于一般前馈神经网络提出的f-GAN[239]。基于马尔可夫模型的GAN纹理合成[240]。另一种基于双随机MCMC方法的生成模型[241]。带多发生器的GAN[242]。
无监督GAN是否能够在像素级域自适应上学习,该自适应在像素空间中从一个域转换到另一个域?这种方法提供了针对几种无监督域适配技术的最先进性能,具有很大的优势[243]。提出了一种称为模式网络的新网络,它是一种面向对象的生成性物理模拟器,能够通过原因推理来分离事件的多个原因,从而实现从环境动力学数据中学习的目标[244]。有一项有趣的研究是用一种生成对抗性文本到图像合成的GAN进行的。在本文中,提出了一种新的用于GAN公式的深层结构,它可以对图像进行文本描述,并根据输入生成逼真的图像。这是一种使用字符级文本编码器和类条件GAN的基于文本的图像合成的有效技术。GAN首先在bird and flower数据集上评估,然后在MS COCO数据集上评估图像的一般文本[40]。
7.2.GAN的应用
该学习算法已应用于不同的应用领域,将在以下章节中讨论:
7.2.1.用于图像处理的GAN
GANs用于使用超分辨率方法生成照片真实感图像[245]。GAN使用半监督和弱监督方法进行语义分割[246]。文本条件辅助分类器GAN(TAC-GAN),用于根据文本描述生成或合成图像[247]。多样式生成网络(MSG-Net),保留了基于优化的方法的快速功能。该网络在多个尺度上匹配图像样式,并将计算负担投入到训练中[248]。大多数时候,视觉系统与雨、雪和雾作斗争。最近提出了一种使用GAN的单图像去雨系统[249]。
7.2.2.用于语音和音频处理的GAN
使用生成层次神经网络模型的端到端对话系统[250]。此外,GANs还被用于语音分析领域。最近,GANs被用于语音增强,称为SEGAN,它结合了进一步的以语音为中心的设计,以逐步提高性能[251]。GAN代表符号域和音乐生成,其表现与Melody RNN相当[252]。
7.2.3.用于医学信息处理的GAN
用于医学成像和医学信息处理的GANs[136],用于基于Wasserstein距离和感知损失的医学图像去噪的GANs[253]。GANs还可用于使用条件GANs(cGAN)分割脑肿瘤[254]。提出了一种通用的医学图像分割方法,使用一种称为SegAN[255]的GAN。在深度学习革命之前,压缩感知是最热门的话题之一。然而,深氮化镓用于自动进行MRI的压缩传感[256]。此外,由于隐私问题,GANs也可用于健康记录处理,电子健康记录(EHR)仅限于或不像其他数据集那样公开。GANs应用于可降低风险的综合EHR数据[257]。介绍了使用递归GAN(RGAN)和递归条件GAN(RCGAN)生成时间序列数据[258]。LOGAN由生成模型和判别模型的组合组成,用于检测过拟合和识别输入。该技术与最先进的GAN技术进行了比较,包括GAN、DCGAN和DCGAN与VAE的组合[259]。
7.2.4.其他应用
一种称为贝叶斯条件GAN(BC-GAN)的新方法,可以从确定性输入生成样本。这只是一个具有贝叶斯框架的GAN,可以处理有监督、半监督和无监督学习问题[260261]。在机器学习和深度学习社区中,在线学习是一种重要的方法。GAN用于在线学习,在这种学习中,GAN被训练用于在名为Checkov GAN 1[262]的零和游戏中寻找混合策略。基于统计假设检验的生成矩匹配网络称为最大平均差异(MMD)[263]。将GAN的鉴别器替换为基于两个样本的核MMD的有趣想法之一称为MMD-GAN。该方法明显优于生成矩匹配网络(GMMN)技术,该技术是生成模型的替代方法[264]。
GAN的一些其他应用包括姿势估计[265]、照片编辑网络[266]和异常检测[267]。使用GAN学习跨域关系的DiscoGAN[40],使用生成模型进行无监督图像到图像的翻译[268],使用GAN进行单镜头学习[269],响应生成和问答系统[270271]。最后但并非最不重要的一点是,WaveNet作为一种生成模型已在[272]中开发用于生成音频波形,并在[273]中开发了双路径网络。
8.深度强化学习(DRL)
在前面的章节中,我们重点介绍了有监督和无监督的深度学习方法,包括DNN、CNN、RNN,包括LSTM和GRU、AE、RBM、GAN等。这些类型的深度学习方法用于预测、分类、编码、解码、数据生成,还有更多的应用领域。然而,本节展示了一项关于深度强化学习(DRL)的调查,该调查基于RLL领域最近开发的方法。
8.1.DRL综述
DRL是一种学习方法,它从未知的真实环境中学习一般意义上的行为(有关详细信息,请阅读以下文章[46274])。DRL方法的概念图如图43所示。RL可应用于不同领域,包括决策基础科学、计算机科学角度的机器学习、工程和数学、最优控制、机器人控制、电站控制、风力涡轮机、,神经科学奖励策略在过去的几十年中得到了广泛的研究。它也被应用于经济效用或博弈论中,以做出更好的决策和投资选择。经典条件作用的心理学概念是动物如何学习。强化学习是一种关于做什么以及如何将情境与行动相匹配的技术。强化学习不同于监督学习技术和最近研究的其他学习方法,包括传统的机器学习、统计模式识别和人工神经网络。

与一般的有监督和无监督机器学习不同,RL不是通过描述学习方法来定义的,而是通过描述学习问题来定义的。然而,DL最近的成功对DRL的成功产生了巨大的影响,DRL被称为DRL。根据学习策略,通过观察学习RL技术。对于环境观测,根据观测空间的不同,有前途的DL技术包括CNN、RNN、LSTM和GRU。由于DL技术有效地编码数据,因此,更准确地执行以下操作步骤。根据行动,代理人分别获得适当的奖励。因此,整个RL方法在环境中学习和交互的效率更高,性能更好。
然而,现代DRL革命的历史始于2013年的Google Deep Mind,Atari游戏与DRL。其中,基于DRL的方法在几乎所有游戏中都比人类专家表现得更好。在这种情况下,在使用CNN处理的视频帧上观察环境[275276]。DRL方法的成功取决于要解决的任务的难度。在Google Deep mind的Alpha Go和Atari取得巨大成功后,他们于2017年提出了一个基于星际争霸II的强化学习环境,称为SC2LE(星际争霸II学习环境)[277]。SC2LE是一款具有多个玩家交互的多智能体游戏。该方法具有较大的行动空间,涉及数百个单元的选择和控制。它包含许多从原始特征空间观察到的状态,并且使用了数千个步骤的策略。基于Python的开源星际争霸II游戏引擎已经在网上免费提供。
8.2. Q-Learning
对于使用DRL,需要了解一些基本策略。首先,RL学习方法有一个计算状态-动作组合质量的函数,称为Q-学习(Q-函数)。算法II描述了Q-学习的基本计算流程。
Q-学习被定义为一种无模型强化学习方法,用于为任何给定(有限)马尔可夫决策过程(MDP)寻找最优的行为选择策略。MDP是一个数学框架,用于使用状态、行动和奖励对决策进行建模。Q-learning只需要了解可用状态以及每个状态下可能采取的行动。Q-Learning的另一个改进版本称为双向Q-Learning。本文讨论了Q学习,有关双向Q学习的详细信息,请参阅参考文献[278]。
在每个步骤s中,选择使以下函数Q(s,a)最大化的操作:
· Q 是一个估计的效用函数,它告诉我们在某种状态下给出的动作有多好
· r(s,a)使一个动作对结果状态的效用最大(Q)的即时奖励
这可以用递归定义来表示,如下所示:
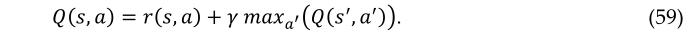
这个方程叫做贝尔曼方程,它是RL的核心方程。这里r(s,a)是即时奖励,γ是延迟与即时奖励的相对值[0,1]s’是动作a后的新状态。a和a分别是状态s和s中的动作。根据以下等式选择动作:

在每一种状态下,都会分配一个值,称为q值。当我们访问一个状态时,我们会得到相应的奖励。我们使用奖励来更新该状态的估计值。因为奖励是随机的,所以我们需要多次访问这些状态。此外,这并不能保证我们在另一集中会得到相同的奖励(Rt)。情景性任务和环境中未来奖励的总和是不可预测的,在未来,我们会进一步获得不同形式的奖励,
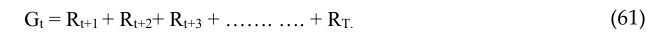
在这两种情况下,折扣后的未来奖励之和是一些标量因素。
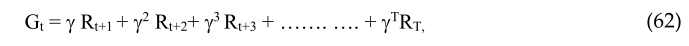
在这里 γ 是一个常数。我们在未来做得越多,我们就越不考虑回报。
Q-学习的特性:
· Q-函数的收敛性:近似将收敛到真正的Q-函数,但它必须无限多次访问可能的状态-作用对。
· 状态表的大小可能因观测空间和复杂性而异。
· 观察期间不考虑看不见的值。
解决这些问题的方法是使用神经网络(尤其是DNN)作为近似值,而不是状态表。DNN的输入是状态和动作,输出是0到1之间的数字,表示正确编码状态和动作的实用程序。在这里,深度学习方法有助于对状态信息做出更好的决策。在观察环境的大多数情况下,我们使用几种采集设备,包括摄像机或其他传感设备来观察学习环境。例如,如果您观察了Alpha Go挑战的设置,则可以看到环境、动作和奖励是基于像素值(动作中的像素)学习的。详见参考文献[275,276,279]。
然而,很难开发一种在任何观测环境中都能相互作用或表现良好的智能体。因此,该领域的大多数研究人员在为环境训练agent之前都会选择他们的行动空间或环境。在这种情况下,基准概念与有监督或无监督的深度学习方法相比有点不同。由于环境的多样性,基准取决于与之前或现有研究相比,环境的难度有多大?难度取决于不同的参数、代理的数量、代理之间的交互方式、参与者的数量等。
最近,为DRL提出了另一种很好的学习方法[46,274]。关于DRL的不同网络发表了许多论文,包括深度Q网络(DQN)、双DQN、异步方法、策略优化策略(包括确定性策略梯度、深度确定性策略梯度、引导策略搜索、信赖域策略优化、策略梯度与Q学习相结合)建议采用[46274]。策略梯度(DAGGER)超人围棋使用具有策略梯度的监督学习和具有值函数的蒙特卡罗树搜索[46280]。使用引导策略搜索的机器人操作[281]。使用策略梯度的3D游戏DRL[282]。

8.3.DRL的最新发展趋势及其应用
最近发布了一项调查,其中提出了基本RL、DRL DQN、信赖域策略优化和异步优势参与者批评家。本文还讨论了深度学习的优势,重点讨论了通过RL的视觉理解以及当前的研究趋势[283]。提出了一种基于在线RL技术的网络内聚约束方法,用于移动设备上的医疗保健,称为mHealth。该系统帮助相似的用户高效地共享信息,以改进有限的用户信息并将其转化为更好的策略[284]。小组驱动的RL的类似工作也被提议用于在移动设备上进行个性化mHealth干预的医疗保健。在这项工作中,K-均值聚类用于对人员进行分组,并最终与每个组的RL策略共享[285]。对于智能体来说,最优策略学习是一项具有挑战性的任务。选项观察启动集(OOI)允许代理在POMDP的挑战性任务中学习最优策略,POMDP的学习速度比RNN快[286]。利用DRL提出了三维装箱问题(BPP)。主要目的是放置长方体形状物品的数量,以尽量减少箱子的表面积[287]。
DRL的重要组成部分是根据观察和代理人的行动确定的奖励。现实世界中的奖励功能并非总是完美的。由于传感器错误,代理可能获得最大奖励,而实际奖励应较小。本文提出了一个基于广义马尔可夫决策问题(MDP)的公式,称为腐败报酬MDP[288]。基于信赖域优化的深度RL是使用最近发展的Kronecker因子曲率近似(K-FAC)[289]提出的。此外,在使用深度学习方法评估物理实验方面也进行了一些研究。本实验的重点是让agent学习基本属性,例如交互模拟环境中对象的质量和内聚力[290]。
最近提出了适用于连续状态和动作空间的模糊RL策略[291]。对连续控制策略梯度中的超参数、算法的一般方差进行了重点研究和讨论。本文还提供了报告结果和与基线方法比较的指南[292]。深RL也适用于高精度装配任务[293]。Bellman方程是RL技术的主要函数之一,提出了一种函数逼近方法,确保Bellman最优性方程始终成立。然后对函数进行估计,以最大化观测运动的可能性[294]。基于DRL的分层系统用于CAN计算系统中的CAN资源分配和电源管理[295]。提出了一种新的注意感知面部幻觉(Attention FC),其中深度RL用于增强应用于面部图像的单个贴片上的图像质量[296]。
9贝叶斯深度学习(BDL)
DL方法为不同的应用提供了最先进的精度。然而,由于模型的不确定性,DL方法无法处理给定任务的不确定性。这些学习方法采用输入,并在没有正当理由的情况下假设课堂概率[297,298]。2015年,两名非洲裔美国人通过图像分类系统被确认为大猩猩[299]。有几个应用领域的不确定性可能会提高,包括自驾汽车、生物医学应用。然而,BDN是DL和贝叶斯概率方法之间的交叉点,在不同的应用中显示出更好的结果,并理解问题的不确定性,包括多任务问题[297,298]。通过在模型权重上应用概率分布或映射输出概率来估计不确定性[297,298]。
BDL在DL研究界变得非常流行。此外,BDL方法已经提出了CNN技术,其中概率分布应用于权重。这些技术有助于处理模型过度拟合问题和缺少训练样本,这是DL方法的两个共同挑战[300,301]。最后,最近发表了一些其他研究论文,其中提出了一些关于BDL的先进技术[302–305]。

10迁移学习
10.1.迁移学习
解释迁移学习的一个好方法是观察师生关系。教师在收集有关该学科的详细知识后开设课程[48]。随着时间的推移,这些信息将通过一系列讲座来传达。这可以被认为是教师(专家)向学生(学习者)传递信息(知识)。在深度学习的情况下也会发生同样的情况,网络使用大量数据进行训练,在训练过程中,模型学习权重和偏差。这些权重可以转移到其他网络,用于测试或重新训练类似的新模型。网络可以从预先训练的权重开始,而不是从头开始训练。迁移学习方法的概念图如图44所示。

10.2.什么是预先培训的模型?
预训练模型是已经在与预期域相同的域中训练的模型。例如,对于图像识别任务,可以下载已经在ImageNet上训练过的初始模型。然后,初始模型可以用于不同的识别任务,而不是从头开始训练,权重可以保留一些学习的特征。当缺少样本数据时,这种训练方法很有用。model zoo中有许多经过预培训的模型(包括不同数据集上的VGG、ResNet和Inception Net),可从以下链接获得:https://github. com/BVLC/caffe/wiki/Model-Zoo。
10.3.为什么要使用预先培训过的模型?
使用预先训练好的模型有很多原因。首先,在大数据集上训练大模型需要大量昂贵的计算能力。其次,训练大型模特可能需要数周的时间。用预先训练好的权值训练新模型,可以加快收敛速度,并有助于网络泛化。
10.4.如何使用预先培训的模型?
在使用表3中所示的预先训练的权重时,我们需要考虑以下的准则:数据集的各个应用领域和数据大小。
10.5.推理工作
专门从事推理应用的研究小组研究包括模型压缩在内的优化方法。模型压缩在移动设备或专用硬件领域非常重要,因为它使模型更节能,也更快。
10.6.关于深度学习的神话
有一个神话;你需要一百万个标记样本来训练深度学习模型吗?答案是肯定的,但在大多数情况下,迁移学习方法用于培训深度学习方法,而不需要大量的标签数据。例如,下图44详细展示了迁移学习方法的策略。在这里,主要模型已使用大量标记数据(即ImageNet)进行训练,然后使用PASCAL数据集对权重进行训练。实际情况是:
· 可以从未标记的数据中学习有用的表示。
· 迁移学习有助于从相关任务中学习表征[306]。
我们可以将一个经过训练的网络用于不同的域,该域可以适用于目标任务的任何其他域[307,308]。首先训练一个具有封闭域的网络,对于该网络,可以使用标准反向传播(例如,ImageNet分类)轻松获得标记数据,从扩充数据中获得伪类。然后切断网络的顶层,并替换为目标域的监督目标。最后,使用带有目标域标签的反向传播优化网络,直到验证丢失开始增加[307,308]。有一些关于迁移学习的调查论文和书籍[309,310]。自学与迁移学习[311]。迁移学习的推进方法[312]。
11.Energy Efficient Approaches and Hardware for DL
11.1综述
DNNs已成功应用于不同的应用领域,如计算机视觉、语音处理、自然语言处理、大数据问题等,并取得了较好的识别精度。然而,大多数情况下,培训是在图形处理单元(GPU)上执行的,用于处理大量数据,这在功耗方面是昂贵的。
最近,研究人员一直在使用更深入和更广泛的网络进行培训和测试,以获得更好的分类精度,从而在某些情况下达到人类或超出人类水平的识别精度。随着神经网络规模的增大,它的功能变得更加强大,并提供了更好的分类精度。然而,存储消耗、内存带宽和计算成本呈指数级增长。另一方面,这些具有大量网络参数的大规模实现类型不适用于低功耗实现、无人机(UAV)、不同的医疗设备、低内存系统,如移动设备、现场可编程门阵列(FPGA)等。
有很多研究正在进行,以开发更好的网络结构或网络,降低计算成本,减少低功耗和低存储系统的参数数量,同时不降低分类精度。有两种方法可以设计高效的深层网络结构:
· 第一种方法是通过有效的网络结构优化内部运营成本;
· 其次,设计一个低精度操作的网络或一个硬件效率高的网络。
通过对卷积层使用低维卷积滤波器,可以减少网络结构的内部操作和参数[71,99]。
这种方法有很多好处。首先,卷积校正运算使决策更具鉴别性。其次,这种方法的主要优点是大大减少了计算参数的数量。例如,如果一个层有5×5维过滤器,可以用两个3×3维过滤器代替(中间没有池层),以更好地进行特征学习;三个3×3维滤波器可替代7×7维滤波器等。使用低维滤波器的好处是,假设当前两个卷积层都有C通道,对于3×3滤波器的三个层,参数总数为权重:3×(3×3×C×C)=27C2权重,而在滤波器尺寸为7×7时,参数总数为(7×7×C×C)=49C2,这几乎是三个3×3滤波器参数的两倍。此外,在网络中以不同间隔放置层(如卷积、池、丢弃)会影响整体分类精度。最近提到了一些优化网络架构的策略,以设计健壮的深度学习模型[99100313],并在FPGA平台上高效实现CNN[314]。
策略1:用1×1过滤器替换3×3过滤器。使用低维过滤器以减少参数总数的主要原因。通过用1×1替换3×3滤波器,可以减少9倍的参数数量。
策略2:将输入通道的数量减少到3×3个滤波器。对于图层,计算输出特征贴图的大小,该大小与使用的网络参数有关(N - F)/S+1,其中N表示输入图的大小,F表示过滤器大小,s表示步幅。为了减少参数的数量,不仅要减小滤波器的尺寸,还需要控制输入通道的数量或特征尺寸。
策略3:在网络中后期进行下采样,以便卷积层具有激活映射:当前卷积层的输出至少可以是1x1或通常大于1×1.输出宽度和高度可以通过一些标准来控制:(1)输入样本的大小(例如256×256)和(2)选择下发后采样层。最常用的池层是平均池层或最大池层,如果使用,则有一个具有卷积的替代子采样层(3×3个过滤器)并以2。如果早期的大多数层具有较大的跨步,那么大多数层将具有少量的激活贴图。
11.2.二元或三元连接神经网络
由于乘法的精度较低,且使用drop连接进行的乘法很少,因此计算成本可大幅降低[315316]。这些论文还介绍了二元连接神经网络(BNN)和三元连接神经网络(TNN)。通常,实值权重乘以实值激活(正向传播)和梯度计算(反向传播)是深层神经网络的主要操作。二进制连接或BNN是一种通过将前向传播中使用的权值转换为二进制(即二进制)来消除乘法运算的技术。E仅约束为两个值(0和1或-1和1)。因此,可以通过简单的加法(和减法)执行乘法运算,从而加快训练过程。有两种方法可以将实值转换为相应的二进制值,例如确定性和随机性。在确定性技术的情况下,直接阈值技术应用于权重。另一种方法是一种随机方法,其中基于概率将矩阵转换为二进制,其中使用硬sigmoid函数,因为其计算成本较低。实验结果表明,识别准确率非常高[317–319]。BNN有以下几个优点:
· 据观察,GPU上的二进制乘法速度几乎是GPU上传统矩阵乘法速度的七倍
· 在前向传递中,BNN极大地减少了内存大小和访问量,并用位运算取代了大部分算术运算,从而大大提高了功率效率
· 二值化内核可用于CNN,可减少专用硬件约60%的复杂性。
· 还观察到,与算术运算相比,内存访问通常消耗更多的能量,并且内存访问成本随着内存大小的增加而增加。BNN在这两方面都是有益的。
在过去几年中,还提出了一些其他技术[320–323]。另一种节能且硬件友好的网络结构已被提出用于具有XNOR操作的CNN。在基于XNOR的CNN实现中,滤波器和卷积层的输入都是二进制的。这将使卷积运算速度提高58倍,节省32倍内存。在同一篇论文中,提出了二进制加权网络,它节省了大约32倍的内存。这使得在CPU上实现最先进的网络成为可能,以供实时使用,而不是GPU。这些网络在ImageNet数据集上进行测试,仅提供2个。分类准确率比全精度AlexNet低9%(最高1%)。这种网络需要更少的功率和计算时间。这可以大大加快深度神经网络的训练过程,以实现专门的硬件实现[273274]。2016年,首次为神经形态系统提出了节能型深层神经网络(EEDN)架构。此外,他们发布了一个名为EEDN的深度学习框架,该框架提供了接近最先进的精度,几乎所有流行的基准测试(ImageNet数据集除外)[324325]。
12.DL的硬件
随着DL方法算法的发展,在过去几年中提出了许多硬件架构[326]。关于深度学习硬件当前发展趋势的详细信息最近已发布[49326]。麻省理工学院提出Eyeris作为深度卷积神经网络(DCNN)的硬件[327]。还有另一种机器学习体系结构称为Dadiannao[328]。谷歌为深度学习开发了名为Tensor Processing Unit(TPU)的硬件,并于2017年发布[329]。2016年,斯坦福大学发布并提出了用于推理的高效硬件,称为高效推理引擎(EIE)[330]。IBM于2015年发布了一个名为TrueNorth的神经形态系统[324]。
深度学习方法并不局限于HPC平台,已经开发了许多在移动设备上运行的应用程序。移动平台提供与用户日常活动相关的数据,通过使用收集的数据对系统进行再培训,可以使移动系统更加高效和健壮。目前正在进行一些研究,以开发硬件
DL的友好算法[331–333]。
13.其他主题
14.总结
在这篇论文中,我们对过去几年的深度学习及其应用进行了深入的回顾。综述了不同类别学习中的不同深度学习模型,包括有监督、无监督和强化学习(RL),以及它们在不同领域中的应用。此外,我们还详细解释了不同的监督深度学习技术,包括DNN、CNN和RNN。详细回顾了无监督的深度学习技术,包括AE、RBM和GAN。在同一节中,我们考虑并解释了基于LSTM和RL提出的无监督学习技术。在第8节中,我们介绍了一项关于深度强化学习(DRL)的调查,其基本学习技术称为Q-Learning。第9节和第10节还分别讨论了最近开发的贝叶斯深度学习(BDL)和转移学习(TL)方法。此外,我们还对节能深度学习方法、DL迁移学习以及DL硬件发展趋势进行了调查。此外,我们还讨论了一些DL框架和基准数据集,它们通常用于实施和评估深度学习方法。最后,我们还包括了相关的期刊和会议,DL社区在这些期刊和会议上发表了他们有价值的研究文章。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)