

统计学知识:相关系数
公众号:尤而小屋作者:Peter编辑:Peter大家好,我是Peter~这两周在看一本书《特征工程入门与实践》,对自己很有启发。特征工程是数据工作者建模过程中极其重要的一步,如何从众多的特征中找到或者选择与目标具有高强相关的特征显得尤为重要。本书中有提到相关系数,自己看了很多的资料,整理出这篇文章,希望对大家有所帮助。何为相关系数相关系数,也叫做关联系数(英语为:correlation coeff
公众号:尤而小屋
作者:Peter
编辑:Peter
大家好,我是Peter~
这两周在看一本书《特征工程入门与实践》,对自己很有启发。
特征工程是数据工作者建模过程中极其重要的一步,如何从众多的特征中找到或者选择与目标具有高强相关的特征显得尤为重要。
本书中有提到相关系数,自己看了很多的资料,整理出这篇文章,希望对大家有所帮助。

何为相关系数
相关系数,也叫做关联系数(英语为:correlation coefficient),它是由统计学家卡尔.皮尔逊设计的一个统计指标,我们最常用的也是Person皮尔逊相关系数。相关系数描述的是两个变量之间的关系及相关方向。但是相关系数无法确切地表明两个变量之间相关的程度。
相关系数的取值在-1到1之间:
- -1表示两个变量呈现负相关
- 0表示两个变量没有相关性
- 1表示两个变量呈现正相关
最后,相关系数是统计学中的一个概念,统计学你应该怎么入门?Peter建议你参考下面的这张图:
3种常见相关系数
** Pearson 相关系数、Spearman 相关系数、Kendall 相关系数并称统计学三大相关系数。
在分析特征相关性的时候,最常用的方法是pandas.DataFrame.corr:
DataFrame.corr(self, method=’pearson’, min_periods=1)
其中包含的方法主要为:
- pearson:Pearson相关系数
- Spearman:Spearman等级相关系数
- kendall:Kendall秩相关系数
Person相关系数
Person相关系数也叫简单相关系数或者线性相关系数,用来检测两个连续型变量之间的线性相关程度。
总体的Person相关系数用 ρ \rho ρ表示,计算公式为
ρ x , y = cov ( x , y ) σ x σ y = E [ ( x − μ x , y − μ y ) ] σ x σ y \rho_{x, y}=\frac{\operatorname{cov}(\boldsymbol{x}, \boldsymbol{y})}{\sigma_{x} \sigma_{y}}=\frac{E\left[\left(\boldsymbol{x}-\mu_{x}, \boldsymbol{y}-\mu_{y}\right)\right]}{\sigma_{x} \sigma_{y}} ρx,y=σxσycov(x,y)=σxσyE[(x−μx,y−μy)]
或者为:
ρ X , Y = E ( X Y ) − E ( X ) E ( Y ) E ( X 2 ) − ( E ( X ) ) 2 E ( Y 2 ) − ( E ( Y ) ) 2 \rho_{X, Y}=\frac{E(X Y)-E(X) E(Y)}{\sqrt{E\left(X^{2}\right)-(E(X))^{2}} \sqrt{E\left(Y^{2}\right)-(E(Y))^{2}}} ρX,Y=E(X2)−(E(X))2E(Y2)−(E(Y))2E(XY)−E(X)E(Y)
样本的Person相关系数用字母r表示,用来度量两个变量间的线性关系,计算公式为:
r ( X , Y ) = Cov ( X , Y ) Var [ X ] Var [ Y ] r(X, Y)=\frac{\operatorname{Cov}(X, Y)}{\sqrt{\operatorname{Var}[X] \operatorname{Var}[Y]}} r(X,Y)=Var[X]Var[Y]Cov(X,Y)
表示的是:用两个变量的协方差除以两个变量标准差的乘积
- Cov(X,Y):表示的是协方差
- Var[X]:表示的是方差,开根号之后就变成了标准差
⚠️总结:两个变量之间的Pearson相关系数定义为两个变量之间的协方差和标准差的商
Spearman相关系数
Spearman相关系数是以以查尔斯·爱德华·斯皮尔曼命名的斯皮尔曼等级相关系数。通常用希腊字母 ρ \rho ρ表示,Spearman相关系数也被定义成等级变量间的Person相关系数。
计算公式为:
ρ = ∑ i ( x i − x ˉ ) ( y i − y ˉ ) ∑ i ( x i − x ˉ ) 2 ∑ i ( y i − y ˉ ) 2 \rho=\frac{\sum_{i}\left(x_{i}-\bar{x}\right)\left(y_{i}-\bar{y}\right)}{\sqrt{\sum_{i}\left(x_{i}-\bar{x}\right)^{2} \sum_{i}\left(y_{i}-\bar{y}\right)^{2}}} ρ=∑i(xi−xˉ)2∑i(yi−yˉ)2∑i(xi−xˉ)(yi−yˉ)
实际应用中,变量间的连结是无关紧要的,于是可以通过简单的步骤计算ρ。被观测的两个变量的等级的差值,则ρ为:
ρ = 1 − 6 ∑ d i 2 n ( n 2 − 1 ) \rho=1-\frac{6 \sum d_{i}^{2}}{n\left(n^{2}-1\right)} ρ=1−n(n2−1)6∑di2
其中,n表示数据点的个数, d i d_i di表示数据点 ( x i , y i ) (x_i,y_i) (xi,yi)的秩次 ( r x i , r y i ) (r_{xi},r_{yi}) (rxi,ryi)的差值: d i = r x i − r y i d_i=r_{xi}-r_{yi} di=rxi−ryi
有了Person相关系数,为什么还要有Spearman相关系数?Person相关系数有一定的局限性**:第一是变量必须是连续型,第二必须服从正态分布**
Spearman相关系数只关心变量的单调关系,不考虑具体数值的影响,还能够容忍异常值,一般情况下能够用Person相关系数的地方都能够用Spearman系数。
快速理解秩次和秩和:
下面有AB两组数据,如何求秩次与秩和?

1、按照顺序排列ABL两组数据:

2、标记它们的次序,也就是秩次。如果两个值相同则取次序的均值
3、秩和就是秩次之和:
A:3.5 + 5 + 8 + 9 + 10 = 35.5
B:1 + 2 + 3.5 + 6 + 7 = 19.5
特殊情况:当两个变量有重复的数据,则计算变量之间的Spearman相关系数就是计算变量数据秩次之间的Person相关系数:
ρ s = ρ r x , r y = cov ( r x , r y ) σ r x σ r y \rho_{s}=\rho_{r_{x}, r_{y}}=\frac{\operatorname{cov}\left(r_{x}, r_{y}\right)}{\sigma_{r_{x}} \sigma_{r_{y}}} ρs=ρrx,ry=σrxσrycov(rx,ry)
其中: r x r_x rx表示变量x转换后的秩次。从上面的定义能够看出来,Spearman 相关系数实际上就是对数据做了秩次变换后的 Pearson 相关系数
Kendall秩相关系数
Kendall秩相关系数是一种秩相关系数,是用来度量两个有序变量之间单调关系强弱的相关系数,它的取值范围在-1到1之间。其绝对值越大,表示单调相关性越强,取值为 0 时表示完全不相关。Kendall系数通常用希腊字母 τ \tau τ(tau)表示。
分类变量可以理解成有类别的变量,可以是无序的,比如:性别(男女);也可以是有序的,比如成绩:优、良、中、差。
通常情况下都是求有序分类变量的相关系数。
如何求解Person相关系数
在这里我们分别介绍多种基于Python或者第三方库求解Person相关系数的方法。Person相关系数还是使用的较为频繁。
导入库
import pandas as pd
import numpy as np
import math
import random
模拟数据
模拟一份简单的数据,包含两个列(变量)

方法1:基于pandas
pandas库有一个函数corr(),我们可以直接求解变量中数值类型变量两两之间的相关系数。
在下面的结果中,我们看到:
- 主对角线的系数都是1,自身与自身的相关系数肯定都是1
- 副对角线的相关系数肯定是相同的

corr函数有个参数method,指定不同的值,我们就可以求解不同的相关系数,默认是Pearson系数,下面指定参数的值:

方法2:基于Python自定义函数
1、先求两个变量的均值

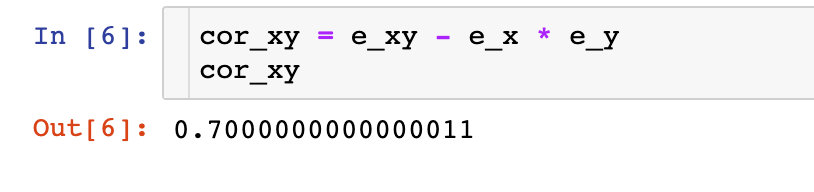
2、求出xy期望值

3、xy协方差系数
根据上面的结果求出xy的协方差系数:
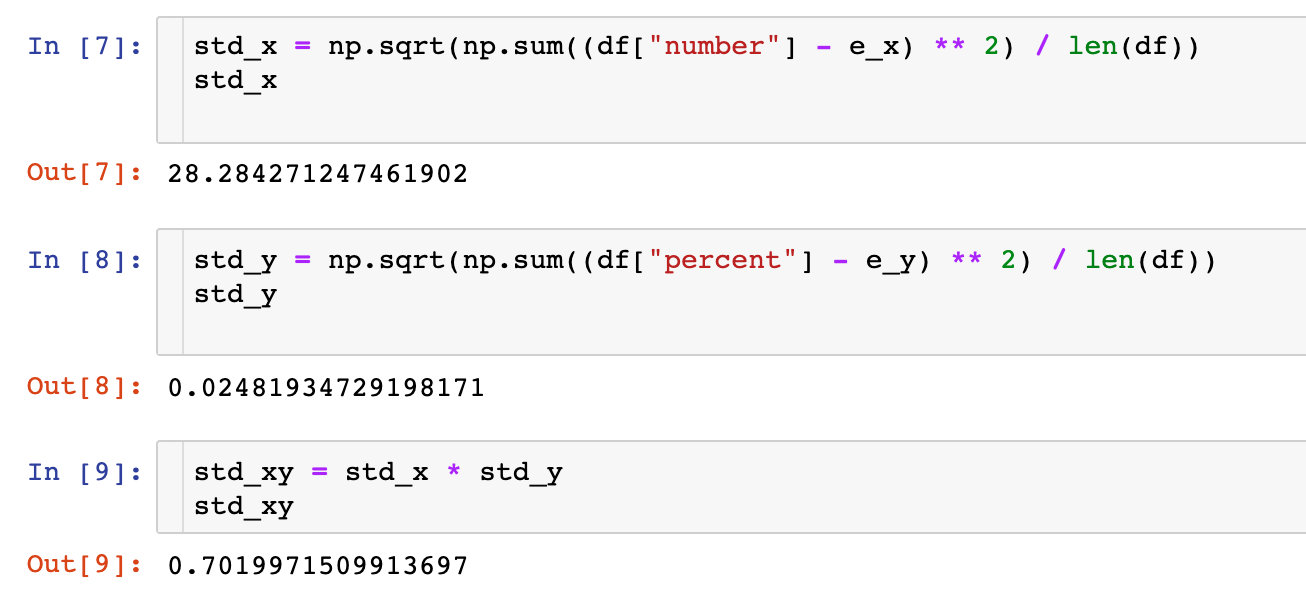
4、求出xy的标准差
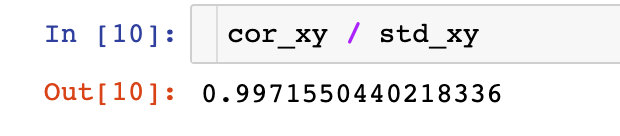
5、求解Person系数
协方差除以标准差就是Person系数
方法3:基于Numpy
Numpy库中有个函数corrcoef能够直接求解两个变量间的相关系数,返回的array数组。主对角线上的值都是1(自身和自身的相关性为1),副对角线都是两两不同变量间的相关系数:

方法4:基于Scipy
Scipy也是python的强大数据计算库,里面有个pearsonr函数也能够求解pearson相关系数。
该函数返回两个值:第一个表示Person相关系数,第二个表示p-value。
p值小于0.05,小于显著性水平,则认为两个变量是相关的

案例实战
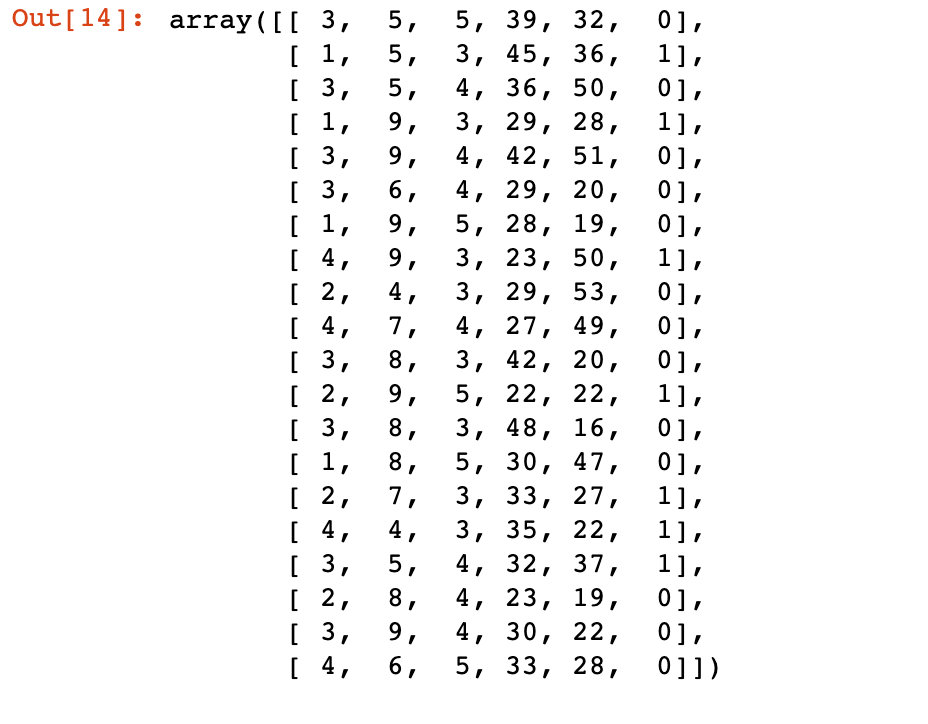
1、我们先模拟一份数据:ABCDE为5个变量,cat是最后的类别(取值在0和1之间选择一个)
import random
# 模拟一份数据:5个类+1个特征
df1 = pd.DataFrame({"A":np.random.randint(1,5,20),
"B":np.random.randint(4,10,20),
"C":np.random.randint(3,6,20),
"D":np.random.randint(22,50,20),
"E":np.random.randint(15,60,20),
"cat":np.random.randint(0,2,20),
},index=list(range(20)))
df2 = np.array(df1)
2、计算特征和类的均值
# 计算数据中特征和类的平均值
def calcMean(x,y):
"""
作用:计算特征和类的平均值
参数:
x:类的数据
y:特征的数据
返回值:特征和类的平均值
"""
x_sum = sum(x)
y_sum = sum(y)
n = len(x)
x_mean = float(x_sum) / n
y_mean = float(y_sum) / n
return x_mean,y_mean # 返回均值
3、计算pearson系数
def calcPearson(x,y):
x_mean, y_mean = calcMean(x,y) # 调用上面的函数返回均值
n = len(x)
sumTop = 0.0
sumBottom = 0.0
x_pow = 0.0
y_pow = 0.0
# 计算协方差
for i in range(n):
sumTop += (x[i] - x_mean) * (y[i] - y_mean)
# 计算标准差
for i in range(n):
x_pow += math.pow(x[i] - x_mean, 2)
for i in range(n):
y_pow += math.pow(y[i] - y_mean ,2)
sumBottom = np.sqrt(x_pow * y_pow)
p = sumTop / sumBottom # 协方差 / 标准差
return p
4、计算每个属性的贡献度
def calcAttribute(dataSet):
prr = [] # 空列表待追加数据
n,m = np.shape(dataSet) # 获取行数和列数
x = [0] * n # 初始化特征x和类别向量y
y = [0] * n
for i in range(n):
y[i] = dataSet[i][m-1] # 得到全部的类别向量
for j in range(m-1):
for k in range(n):
x[k] = dataSet[k][j]
prr.append(calcPearson(x,y)) # 计算每个特征和类别y的相关系数,存入列表
return prr
5、计算结果
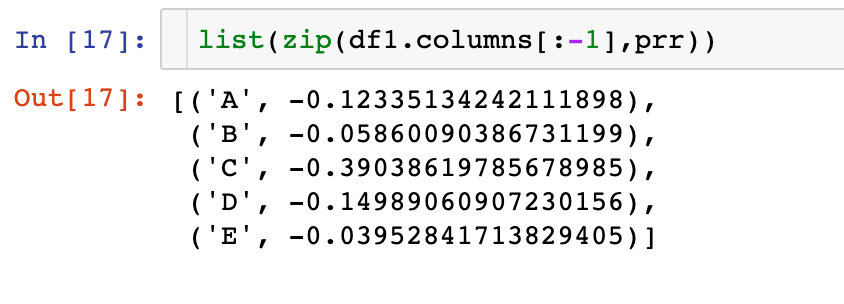
prr = calcAttribute(df2)
prr
# 结果
[-0.12335134242111898,
-0.05860090386731199,
-0.39038619785678985,
-0.14989060907230156,
-0.03952841713829405]
下面描述的是每个变量和类别cat之间的相关系数大小:
6、通过pandas中的corr函数能够直接显示Pearson相关系数,返回值就是各变量之间的相关系数DataFrame表格。
- 对角线的相关系数都是1
- 最后一行表示的就是每个变量和类别cat的相关系数(和上面自定义函数计算的结果相同)

同时,我们还可以查看任意两个变量之间的相关性:

参考资料
1、常用的特征选择方法之 Pearson 相关系数:https://guyuecanhui.github.io/2019/07/20/feature-selection-pearson/
2、怎么理解秩次与秩和:https://blog.csdn.net/weixin_42159940/article/details/86293441
3、相关性分析:Pearson、Kendall、Spearman:https://www.biaodianfu.com/pearson-kendall-spearman.html

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)