维吉尼亚解密密钥
目录1.脚本破解前置安装numpy安装wordninja2.网站解密写在前面:参考大佬博客,加自己的一点想法,仅供学习参考1.脚本破解前置运行环境:python3 numpy 、wordninja两个库安装numpy命令pip install numpy或者python -m pip install numpy安装是否成功检验打开cmd输入python输入import numpy as nu如上图
·
目录
写在前面:参考大佬博客,加自己的一点想法,仅供学习参考
1.脚本破解
前置
运行环境:python3 numpy 、wordninja两个库
安装numpy
命令
pip install numpy
或者
python -m pip install numpy
安装是否成功检验
打开cmd
输入python
输入
import numpy as nu
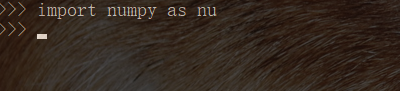
如上图所示,则安装成功
安装wordninja
命令
pip install wordninja
或者
python -m pip install wordninja
安装成功检验
输入
import wordninja
维吉尼亚密码密钥解密脚本
import numpy as np
import wordninja
def alpha(cipher): # 预处理,去掉空格以及回车
c = ''
for i in range(len(cipher)):
if (cipher[i].isalpha()):
c += cipher[i]
return c
def count_IC(cipher): # 给定字符串计算其重合指数
count = [0 for i in range(26)]
L = len(cipher)
IC = 0.0
for i in range(len(cipher)):
if (cipher[i].isupper()):
count[ord(cipher[i]) - ord('A')] += 1
elif (cipher[i].islower()):
count[ord(cipher[i]) - ord('a')] += 1
for i in range(26):
IC += (count[i] * (count[i] - 1)) / (L * (L - 1))
return IC
def count_key_len(cipher, key_len): # 对字符串按输入个数进行分组,计算每一组的IC值返回平均值
N = ['' for i in range(key_len)]
IC = [0 for i in range(key_len)]
for i in range(len(cipher)):
m = i % key_len
N[m] += cipher[i]
for i in range(key_len):
IC[i] = count_IC(N[i])
# print(IC)
print("长度为%d时,平均重合指数为%.5f" % (key_len, np.mean(IC)))
return np.mean(IC)
def length(cipher): # 遍历确定最有可能的密钥长度返回密钥长度
key_len = 0
mins = 100
aver = 0.0
for i in range(1, 10):
k = count_key_len(cipher, i)
if (abs(k - 0.065) < mins):
mins = abs(k - 0.065)
key_len = i
aver = k
print("密钥长度为%d,此时重合指数每组的平均值为%.5f" % (key_len, aver))
return key_len
def count_MIC(c1, c2, n): # n=k1-k2为偏移量,计算c1,c2互重合指数MIC
count_1 = [0 for i in range(26)]
count_2 = [0 for i in range(26)]
L_1 = len(c1)
L_2 = len(c2)
MIC = 0
for i in range(L_1):
if (c1[i].isupper()):
count_1[ord(c1[i]) - ord('A')] += 1
elif (c1[i].islower()):
count_1[ord(c1[i]) - ord('a')] += 1
for i in range(L_2):
if (c2[i].isupper()):
count_2[(ord(c2[i]) - ord('A') + n + 26) % 26] += 1
elif (c2[i].islower()):
count_2[(ord(c2[i]) - ord('a') + n + 26) % 26] += 1
for i in range(26):
MIC += count_1[i] * count_2[i] / (L_1 * L_2)
return MIC
def count_n(c1, c2): # 确定两个子串最优的相对偏移量n=k1-k2
n = 0
mins = 100
k = [0.0 for i in range(26)]
for i in range(26):
k[i] = count_MIC(c1, c2, i)
# print(i,k[i])
if (abs(k[i] - 0.065) < mins):
mins = abs(k[i] - 0.065)
n = i
return n
def group_k(cipher, key_len): # 完成分组操作并计算每一组与第一组的最优相对偏移量并返回
N = ['' for i in range(key_len)]
MIC = [0 for i in range(key_len)]
s = [0 for i in range(key_len)]
for i in range(len(cipher)): # 对密文进行分组
m = i % key_len
N[m] += cipher[i]
for i in range(1, key_len): # 计算与第一组之间的相对偏移量
s[i] = count_n(N[0], N[i]) # s[i] = k1-k(i+1)
MIC[i] = count_MIC(N[0], N[i], s[i]) # MIC[i] = MIC(1,i+1)
print("第1组和第%d组之间偏移为%d时,互重合指数为%.5f" % (i + 1, s[i], MIC[i]))
return s
def miyao(key_len, s, k): # k为第一个子串的移位,输出密钥并返回密钥所有字母的下标
mi = ['' for i in range(key_len)]
for i in range(key_len):
s[i] = -s[i] + k # k2=k1-n
mi[i] = chr((s[i] + 26) % 26 + ord('a'))
print("第一个偏移量为%d,密钥为%s时" % (k, mi))
return s
def the_end(cipher, key_len, s): # 输入密文密钥返回明文结果
plain = ''
i = 0
while (i < len(cipher)):
for j in range(key_len):
if (cipher[i].isupper()):
plain += chr((ord(cipher[i]) - ord('A') - s[j] + 26) % 26 + ord('A'))
else:
plain += chr((ord(cipher[i]) - ord('a') - s[j] + 26) % 26 + ord('a'))
i += 1
if (i == len(cipher)):
break
# print(plain)
return plain
5
if __name__ == "__main__":
fp = open("C:/Users/Jasmine/Desktop/1.txt", "r")
cipher = ''
for i in fp.readlines():
cipher = cipher + i
fp.close()
cipher = alpha(cipher)
key_len = length(cipher)
s = group_k(cipher, key_len)
m = s.copy()
for k in range(26):
s = m.copy()
s = miyao(key_len, s, k)
plain = the_end(cipher, key_len, s)
print(plain[0:20]) # 输出部分明文确定偏移量k1
print("参考输出,请输入第一个子串的偏移量:", end='')
k = int(input())
m = miyao(key_len, m, k)
plain = the_end(cipher, key_len, m)
'''对英文文本进行分词'''
word = wordninja.split(plain)
plain = ''
for i in range(len(word)):
plain += word[i]
plain += ' '
print("明文为\n" + plain)代码需要优化(菜鸡之后写bug),不是每一个都能很准确的跑出来,但还是很好用的,感谢大佬!
2.网站解密
简单的纯英文的维吉尼亚密码是可以通过密文和明文逆出来的
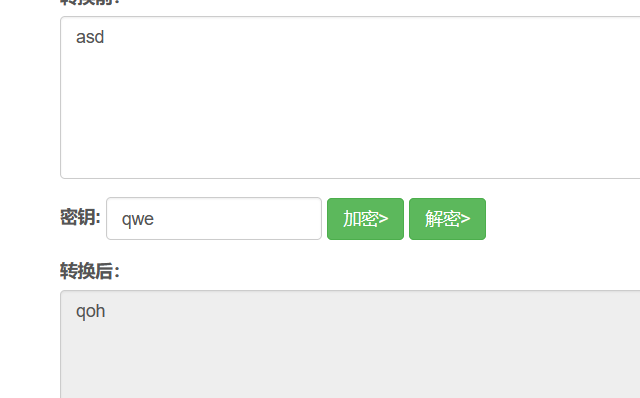
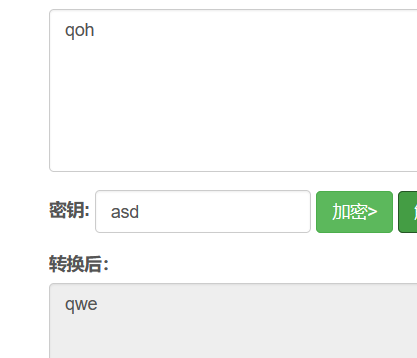
但是明文跟密钥的位数要相同,不相同密钥就会重复出现
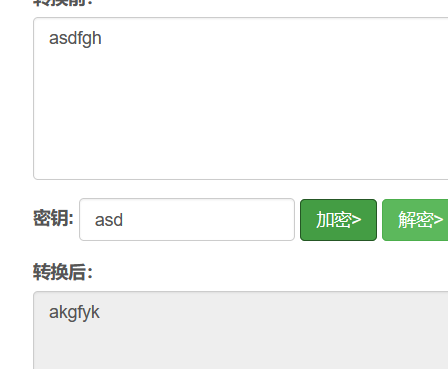
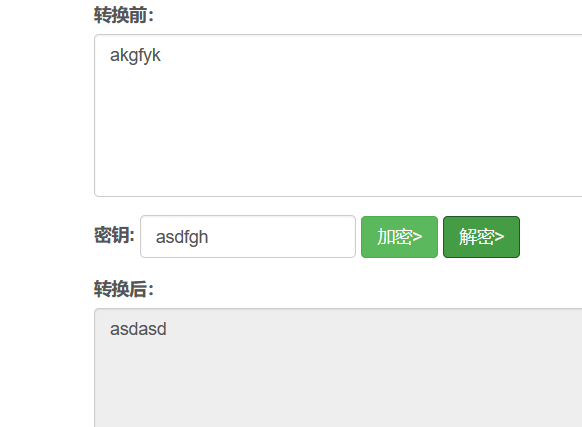
参考文章
大佬写的非常细致,学到了学到了

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)