

Darknet-YOLOv4训练步骤
1、打开终端,克隆项目git clone https://github.com/AlexeyAB/darknet.git2、修改Makefile文件其中,GPU和CUDNN是GPU加速,CUDNN_HALF是特定硬件加速,OPENCV是否使用OpenCV,AVX和OPENMP是CPU加速3、编译cd darknetmake 或者 make -j8(加速编译)4、制作数据集制作数据集,进入桌面 “y
1、打开终端,克隆项目
git clone https://github.com/AlexeyAB/darknet.git
2、修改Makefile文件
其中,GPU和CUDNN是GPU加速,CUDNN_HALF是特定硬件加速,OPENCV是否使用OpenCV,AVX和OPENMP是CPU加速
opencv编译问题https://blog.csdn.net/qq_40297851/article/details/107031700
3、编译
cd darknet
make 或者 make -j8(加速编译)
4、制作数据集
制作数据集,进入桌面 “yolov4Detection/darknet”我们只需要对里面的“train_data”文件夹进行操作即可
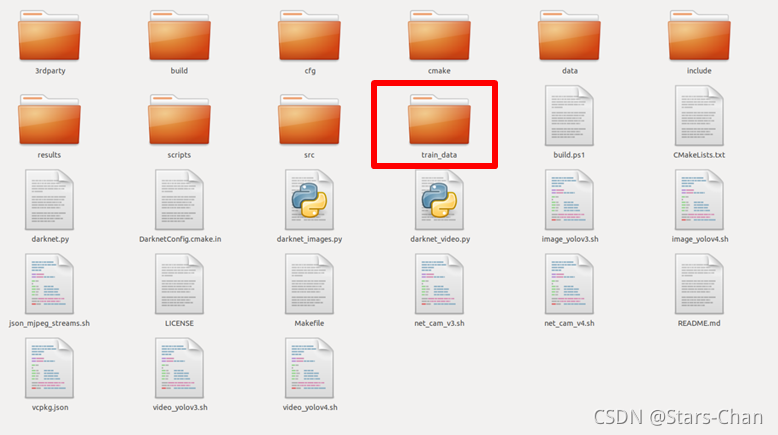
image”和“xml”放到“train_data”里面,并把“data”里面的“predefined_classes.txt” 放到“train_data”里面,改为“voc.names”
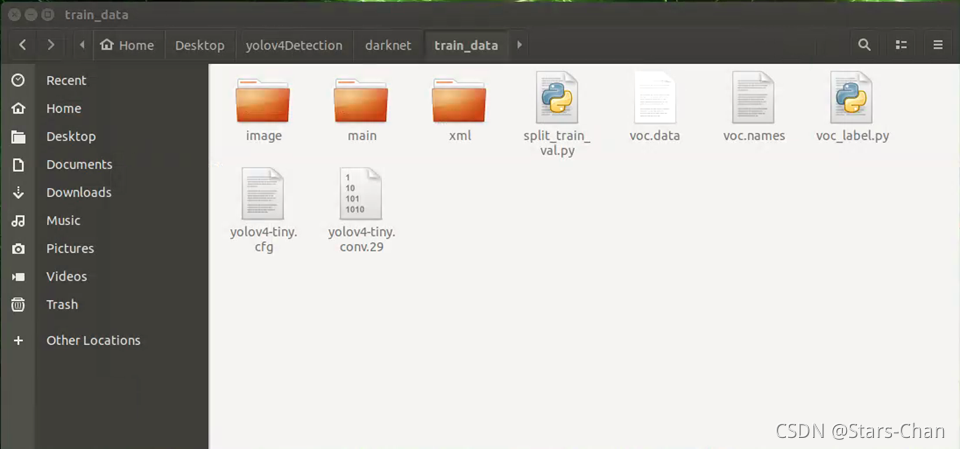
打开“spilt_train_val.py”文件,将数据集划分为训练集以及验证集指定xml文件路径,以及生成的训练集和验证集txt文件保存路径
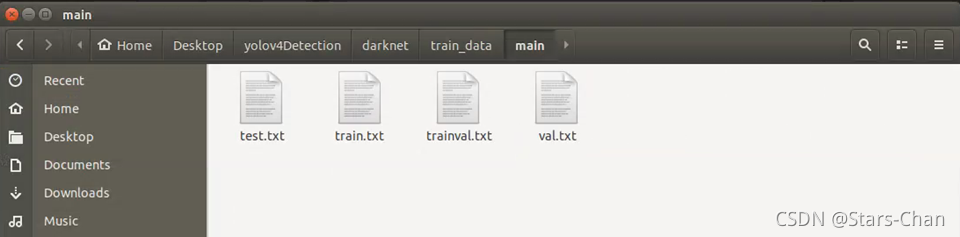
Ctrl + F5 运行,打开“train_data/main”
# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
#xml文件的地址,根据自己的数据进行修改
parser.add_argument('--xml_path', default='/home/nx/Desktop/yolov4Detection/darknet/train_data1/xml', type=str, help='input xml label path')
#数据集的划分,根据自己的数据进行修改
parser.add_argument('--txt_path', default='/home/nx/Desktop/yolov4Detection/darknet/train_data1/main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 1.0
train_percent = 0.9
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()

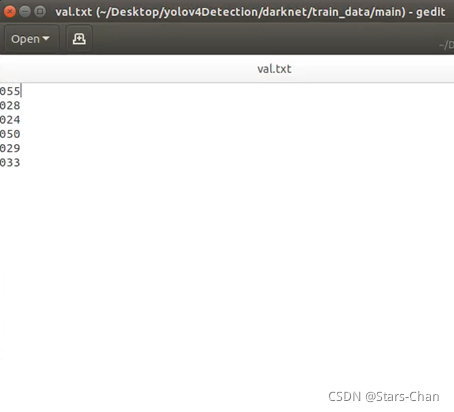
打开“train.txt”和 “val.txt”,数据集划分完毕
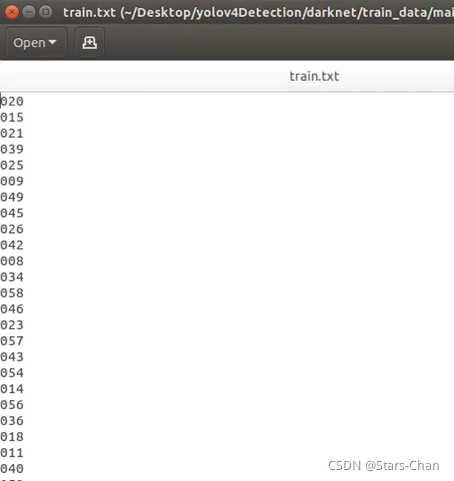
打开“voc_label.py”文件,将每个xml标注文件转换成txt格式,并把训练和验证图片的路径信息保存到“train_data”文件夹下的“train.txt”和“val.txt”需要修改以下路径
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
# 改成自己的类别
# classes = ["bolt","couch","nut","gasket","pillar"]
classes = ["1","2","3","4","5","6","7","8","9"]
abs_path = os.getcwd()
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open('/home/nx/Desktop/yolov4Detection/darknet/train_data1/xml/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('/home/nx/Desktop/yolov4Detection/darknet/train_data1/image/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
#difficult = obj.find('Difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
image_ids = open('/home/nx/Desktop/yolov4Detection/darknet/train_data1/main/%s.txt' % (image_set)).read().strip().split()
list_file = open('/home/nx/Desktop/yolov4Detection/darknet/train_data1/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write('/home/nx/Desktop/yolov4Detection/darknet/train_data1/image/%s.png\n' % (image_id))
convert_annotation(image_id)
list_file.close()

Ctrl + F5 运行,打开“train_data”
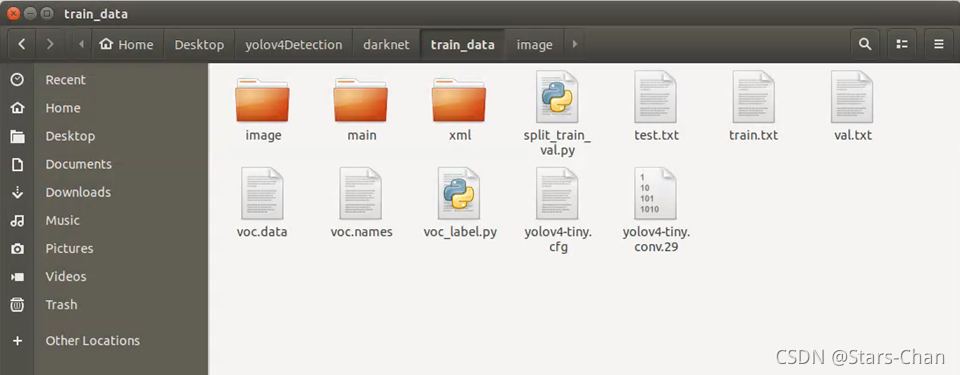
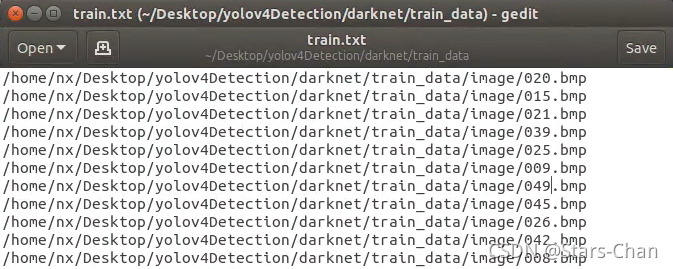
打开“train.txt”、“val.txt”,确认图片路径没问题
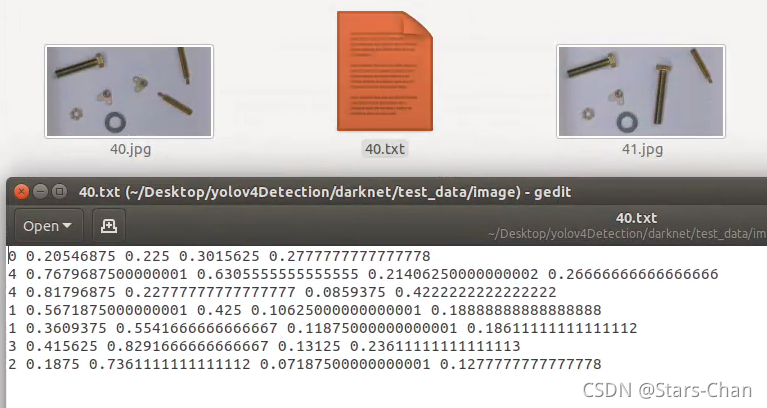
打开“image”文件夹,打开txt文件,确认标注信息转换正确
6、设置训练参数
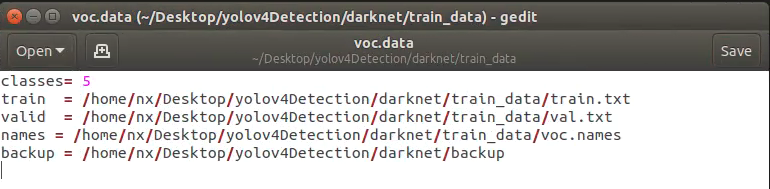
打开train_data文件夹下的“voc.data”
修改类别数目为:5
修改train.txt、val.txt、voc.names文件路径
修改训练生成模型保存路径backup
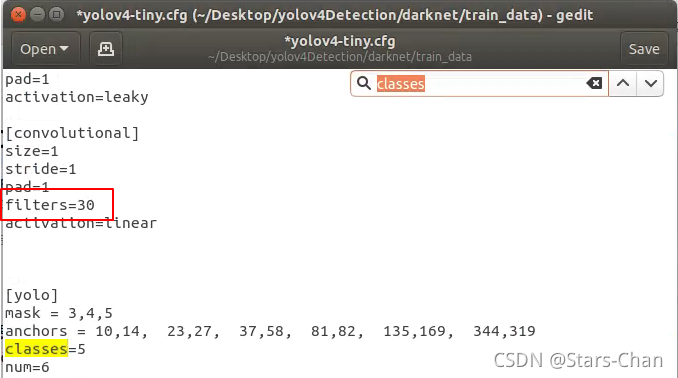
需要把“yolov4-tiny.cfg”里面的classes、filter进行修改
Ctrl + F,查找“classes”修改为5,共两处
并把上方的filter修改为(classes+5)*3 = 30
7、开始训练
在“darknet”文件夹下,右键,打开“Open in Terminal”
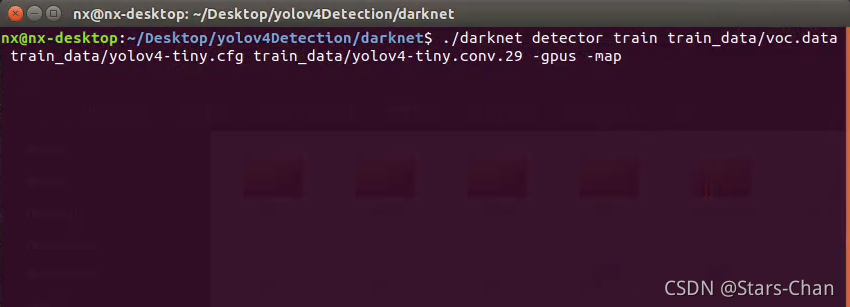
输入下面命令,回车,开始训练
./darknet detector train train_data/voc.data train_data/yolov4.cfg train_data/yolov4.conv.137 -gpus -map
# 评估,比较最后一行,选mAP (mean average precision) 最大的 ,或者IoU(intersect over union)最好的
./darknet detector map data/VOC.data yolo-obj.cfg backup\yolo-obj_6000.weights

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)