解决es集群Yellow与Red的问题
1. 集群健康度分片健康,在集群中节点的状态有三种:绿色、黄色、红色红色:至少有一个主分片没有分配,表示集群无法正常工作。黄色:表示节点的运行状态为警告状态,所有的主分片目前都可以直接运行,但是至少有一个副本分片是不能正常工作的。绿色:节点运行状态为健康状态。所有的主分片、副本分片都可以正常工作。索引健康:最差的分片的状态集群健康:最差的索引的状态2. Health相关的API解释API集群的状态
1. 集群健康度
-
分片健康,在集群中节点的状态有三种:绿色、黄色、红色
-
红色:至少有一个主分片没有分配,表示集群无法正常工作。
-
黄色:表示节点的运行状态为警告状态,所有的主分片目前都可以直接运行,但是至少有一个副本分片是不能正常工作的。
-
绿色:节点运行状态为健康状态。所有的主分片、副本分片都可以正常工作。
-
-
索引健康:最差的分片的状态
-
集群健康:最差的索引的状态
2. Health相关的API
| 解释 | API |
|---|---|
| 集群的状态(检查节点数量) | GET _cluster/health |
| 所有索引的健康状态(查看有问题的索引) | GET _cluster/health?level=indices |
| 单个索引的健康状态(查看具体的索引) | GET _cluster/health/my_index |
| 分片级的索引 | GET _cluster/health?level=shards |
| 返回第一个未分配 Shard 的原因 | GET _cluster/allocation/explain |
示例1:获取索引的健康值
# 浏览器查看
http://IP:9200/_cat/health
# 有问题的结果
1635313779 05:49:39 kubernetes-logging red 15 10 2128 1064 0 0 32 0 - 98.5%
# 正常的结果
1635328870 10:01:10 kubernetes-logging green 15 10 2160 1080 2 0 0 0 - 100.0%
Kibana查看
GET _cat/health
示例2:集群的状态(检查节点数量)
# 浏览器查看
http://IP:9200/_cluster/health
# 结果
{"cluster_name":"kubernetes-logging","status":"red","timed_out":false,"number_of_nodes":15,
"number_of_data_nodes":10,"active_primary_shards":1064,"active_shards":2128,"relocating_shards":0,
"initializing_shards":0,"unassigned_shards":32,"delayed_unassigned_shards":0,"number_of_pending_tasks":0,
"number_of_in_flight_fetch":0,"task_max_waiting_in_queue_millis":0,"active_shards_percent_as_number":98.51851851851852}
Kibana查看
GET _cluster/health
示例3:所有索引的健康状态
# 浏览器查看
http://IP:9200/_cluster/health?level=indices
# 结果略
Kibana 查看
GET _cluster/health?level=indices
示例4:单个索引的健康状态(查看具体的索引)
http://IP:9200/_cluster/health/dev-tool-deployment-service
# 结果
{"cluster_name":"kubernetes-logging","status":"red","timed_out":false,"number_of_nodes":15,
"number_of_data_nodes":10,"active_primary_shards":2,"active_shards":4,"relocating_shards":0,
"initializing_shards":0,"unassigned_shards":6,"delayed_unassigned_shards":0,"number_of_pending_tasks":0,
"number_of_in_flight_fetch":0,"task_max_waiting_in_queue_millis":0,"active_shards_percent_as_number":98.52534562211981}
kibana 查看
GET _cluster/health/my_index
3. 集群健康与问题排查
3.1 启动 Elasticsearch 集群
cat docker-compose.yaml
version: '2.2'
services:
cerebro:
image: lmenezes/cerebro:0.8.3
container_name: hwc_cerebro
ports:
- "9000:9000"
command:
- -Dhosts.0.host=http://elasticsearch:9200
networks:
- hwc_es7net
kibana:
image: docker.elastic.co/kibana/kibana:7.1.0
container_name: hwc_kibana7
environment:
#- I18N_LOCALE=zh-CN
- XPACK_GRAPH_ENABLED=true
- TIMELION_ENABLED=true
- XPACK_MONITORING_COLLECTION_ENABLED="true"
ports:
- "5601:5601"
networks:
- hwc_es7net
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.1.0
container_name: es7_hot
environment:
- cluster.name=geektime-hwc
- node.name=es7_hot
- node.attr.box_type=hot
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- discovery.seed_hosts=es7_hot,es7_warm,es7_cold
- cluster.initial_master_nodes=es7_hot,es7_warm,es7_cold
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- hwc_es7data_hot:/usr/share/elasticsearch/data
ports:
- 9200:9200
networks:
- hwc_es7net
elasticsearch2:
image: docker.elastic.co/elasticsearch/elasticsearch:7.1.0
container_name: es7_warm
environment:
- cluster.name=geektime-hwc
- node.name=es7_warm
- node.attr.box_type=warm
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- discovery.seed_hosts=es7_hot,es7_warm,es7_cold
- cluster.initial_master_nodes=es7_hot,es7_warm,es7_cold
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- hwc_es7data_warm:/usr/share/elasticsearch/data
networks:
- hwc_es7net
elasticsearch3:
image: docker.elastic.co/elasticsearch/elasticsearch:7.1.0
container_name: es7_cold
environment:
- cluster.name=geektime-hwc
- node.name=es7_cold
- node.attr.box_type=cold
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- discovery.seed_hosts=es7_hot,es7_warm,es7_cold
- cluster.initial_master_nodes=es7_hot,es7_warm,es7_cold
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- hwc_es7data_cold:/usr/share/elasticsearch/data
networks:
- hwc_es7net
volumes:
hwc_es7data_hot:
driver: local
hwc_es7data_warm:
driver: local
hwc_es7data_cold:
driver: local
networks:
hwc_es7net:
driver: bridge
案例1
-
症状:集群变红
-
分析:通过 Allocation Explain API 发现创建索引失败,因为无法找到标记了相应 box type 的节点
-
解决:删除索引,集群变绿,重新创建索引,并且指定正确的 routing box type,索引创建成功,保持绿色状态
# 将 hot 写成 hott 创建索引查看状态
DELETE mytest
PUT mytest
{
"settings":{
"number_of_shards":3,
"number_of_replicas":0,
"index.routing.allocation.require.box_type":"hott"
}
}
# 检查集群状态,查看是否有节点丢失,有多少分片无法分配
GET /_cluster/health/
# 查看索引级别,找到红色的索引
GET /_cluster/health?level=indices
#查看索引的分片
GET _cluster/health?level=shards
# Explain 变红的原因
GET /_cluster/allocation/explain
GET /_cat/shards/mytest
GET _cat/nodeattrs
# 将 hott 修改成正确的 hot 后,创建索引查看状态
DELETE mytest
GET /_cluster/health/
PUT mytest
{
"settings":{
"number_of_shards":3,
"number_of_replicas":0,
"index.routing.allocation.require.box_type":"hot"
}
}
GET /_cluster/health/
案例2:Explain 看 hot 上的 explain
-
症状:集群变黄
-
分析:通过 Allocation Explain API 发现无法在相同的节点上创建副本
-
解决:将索引的副本数设置为0,或者通过增加节点解决
# 错误的写法
DELETE mytest
PUT mytest
{
"settings":{
"number_of_shards":2,
"number_of_replicas":1,
"index.routing.allocation.require.box_type":"hot"
}
}
GET _cluster/health
GET _cat/shards/mytest
GET /_cluster/allocation/explain
# 修改为正确的之后再次查看
PUT mytest/_settings
{
"number_of_replicas": 0
}
4. 分片没有被分配的一些原因
-
INDEX_CREATE:创建索引失败,在索引的全部分片分配完成之前,会有短暂的 Red,不一定代表有问题
-
CLUSTER_RECOVER:集群重启阶段,会有这个问题
-
INDEX_REOPEN:Open 一个之前 Close 的索引
-
DANGLING_INDEX_IMPORTED:一个节点离开集群期间,有索引被删除,这个节点重新返回时,会导致 Dangling 的问题
5. 常见问题与解决办法
-
集群变红,需要检查是否有节点离线,如果有,通常通过重启离线的节点就可以解决问题
-
由于配置导致的问题,需要修复相关的配置(例如错误的 box_type,错误的副本数)
-
因为磁盘空间限制,分片规则(Shard Filtering)引发的,需要调整规则或者增加节点
-
对于节点返回集群,导致 danging 变红,可直接删除 dangling 索引
6. 集群 Red & Yellow 问题的总结
-
Red & Yellow 是集群运维中常见的问题
-
除了集群故障,一些创建,增加副本等操作,都会导致集群短暂的 Red 和 Yellow,所以监控和报警时需要设置一定的延时
-
通过检查节点数,使用 ES 提供的相关 API,找到真正的原因
-
可以指定 Move 或者 Reallocate 分片
POST _cluster/reroute
{
"commands": [
{
"move": {
"index": "index_name",
"shard": 0,
"from_node": "node_name_1", # 将一个索引的分片从一个 node 移动到另外一个 node,来解决集群变红或变黄的问题
"to_node": "node_name_2"
}
}
]
}
POST _cluster/reroute?explain
{
"commands": [
{
"allocate": {
"index": "index_name",
"shard": 0,
"node": "nodename"
}
}
]
}
7. 生产案例
# Kibana-Dev Tools
GET _cluster/health?level=indices
ctrl + F 搜索 red 状态的索引

"bj-task-hdfs-rpc-2021.11.24" : {
"status" : "red", # 分片状态为红色
"number_of_shards" : 5, # 主分片数
"number_of_replicas" : 1, # 每个分片的副本数
"active_primary_shards" : 4, # 活动的主分片数,说明 1 个故障
"active_shards" : 7, # 活动的总分片数,说明 3 个故障
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 3 # 未分配的分片 3 个,既故障 3 个分片(1主分片 + 2副本分片)
},
再通过 cerebro 确认

通过查看 cerebro 发现,主分片和副本分片在同一台机器中,所以,这台机器故障之后,显示分片丢失
解决办法:删除索引,集群变绿,重新创建索引
我们也可以看看 yellow 的信息

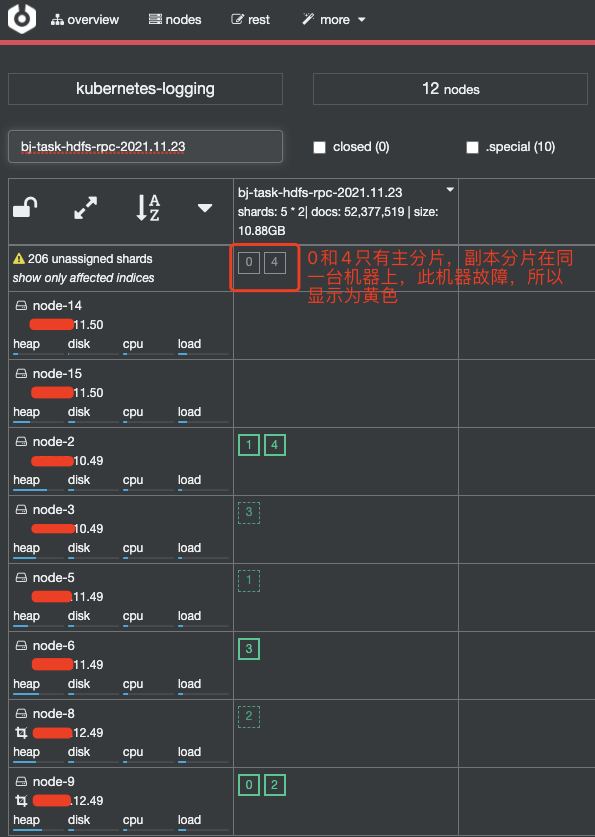
解决办法:修好机器,删除副本分片,分片将会自动重新分配

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 3
3 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)