学习笔记——深度学习模型CNN做Stock预测
一、卷积神经网络CNN最经典卷积神经网络有三层:Convolution LayerPooling Layer(Subsampling)上采样Fully Connected Layer卷积的计算:红框框里与蓝色矩阵filter做矩阵乘法,即:(2*1+5*0+5*1)+(2*2+3*1+4*3)+(4*1+3*1+1*2)= 35之后红色框框往后移一列,继续上述计算卷积神经计算完成得到的数据与深度神
本文搭建一个简单的CNN网络去做股票趋势预测。
另一篇文章(学习笔记——深度学习模型LSTM做Stock预测_远在远方_hh的博客-CSDN博客_lstm 预测模型)用LSTM也做了股票预测可对比参考
一、卷积神经网络CNN

最经典卷积神经网络有三层:
- Convolution Layer
- Pooling Layer(Subsampling)上采样
- Fully Connected Layer
卷积的计算:
红框框里与蓝色矩阵filter做矩阵乘法,即:
(2*1+5*0+5*1)+(2*2+3*1+4*3)+(4*1+3*1+1*2)= 35
之后红色框框往后移一列,继续上述计算

卷积神经计算完成得到的数据
与深度神经网络的区别 CNN不是全连接 Filter中的每个数据是学出来的

用在提取图片特征上

Pooling Layer池化层
max pooling顾名思义去最大的那一个 对应的有平均池化average pooling 即取平均值

全连接

非全连接

计算出loss 使用反向传播法 往回传 在使用梯度下降法 减小误差
二、一维卷积的应用

本次股价的预测三层:卷积层——池化层——全连接神经网络
用20天的股价预测第21天的股价 用mse计算和真实数据的误差
三、代码实现
(1)数据集准备
在finance.yaoo.com 这个网站下载用到的数据集
这次预测股价用到的是苹果的股价预测 直接输入AAPL搜索

 下载完成是一个csv文件,我们这里用5年的股价 每天的收盘价来预测
下载完成是一个csv文件,我们这里用5年的股价 每天的收盘价来预测
看一下我们的数据

(2)代码实现
- 代码运行环境是基于tensorflow的,本文使用jupyter notebook编译环境,可视化结果较好
- 文末附完整代码,这里记录讲解每段代码含义
使用pandas读取数据,df.head()打印前五行数据
df = pd.read_csv('AAPL.csv')
df.head()
我们用调整后的收盘价 Adj Close来预测股价,首先取出数据保存到x0中,用values属性把它转成numpy形式,len(x0)看下x0有多少个数据
x0 = df['Adj Close'].values
x0.shape
len(x0)
接下来对数据做预处理,我们希望每个数据都介于0-1之间,方便我们做预测
首先我们去除x0中最大的数据,之后所有的数据都与最大数据做除法
x0[:10] 输出看下x0中的数据
m = max(x0)
x0 = x0/m
x0[:10] n代表有多少个数据,p代表以20个数据预测下一个值
n代表有多少个数据,p代表以20个数据预测下一个值
x是训练数据的一部分 从k到k+p,k是从总数量中减去p再加1取
n = len(x0)
p = 20
x = np.array([x0[k:k+p] for k in range(n-p+1)])
x.shape1240笔数据 每个数据都包含20个数据
 计算y标签
计算y标签
y = np.array(x0[p:])
y.shapey.shape()看到y有1239个数据,会发现比x少一个数据,因为前20个数据才预测出一个y
![]() 接下来给x做一下调整,让x、y有相同个数据,方便接下来预测
接下来给x做一下调整,让x、y有相同个数据,方便接下来预测
因为keras读入的数据有三个维度,这里我们给x加上一个新的维度,方便keras读取数据
X.shape()可以看到X变成了三维的数据
X = x[:-1]
X = X[:, :, np.newaxis]
X.shape 把X拆分为4个部分来做训练和预测,
把X拆分为4个部分来做训练和预测,
test_size = 0.2 表示 20%的数据做训练,80%的数据做预测
shuffle=True,让数据重新洗过(当shuffle设置为False时,可以发现预测效果差很多)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=True)接下来进行模型搭建,主要用到的是keras中的Sequential来搭建
下面是搭建模型用到的一些包,这里用到一维的卷积,一维的最大池化,优化器我这里导入了两个,可以分别尝试下看看预测效果
- Dense全连接网络
- Flatten可以把二维数据摊成一维
- Dropout防止过拟合
- Activate激活函数
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, Reshape, Dropout, Activation
from tensorflow.keras.layers import Conv1D, MaxPooling1D
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.optimizers import Adam模型搭建的较为简单,只有三层。一维的卷积层、最大池化层、摊平数据之后连接了一个全连接网络。激活函数这里用到的是sigmoid。(softmax通常用在分类问题上,我们今天的数据类似于回归问题,所以这里使用sigmoid)
model.sumary() 看下model的详细信息
#模型搭建
model = Sequential()
#50个filter卷积核 学习到更多的特征,same保证维度不变
model.add(Conv1D(50,4,padding='same',activation='relu',input_shape=(p,1)))
model.add(MaxPooling1D(2))#每两个取一个大的 数据会减少一半
model.add(Flatten())#把二维数据变成一维的
model.add(Dense(20))#20个神经元的全连接层
model.add(Dropout(0.2))#防止过拟合 20%权重冻结
model.add(Activation('relu'))
model.add(Dense(1))#输出层 是一个一维的全连接神经网络
model.add(Activation('sigmoid'))
#model.compile(loss='mse',optimizer=SGD(lr=0.2), metrics['accuracy'])
model.compile(loss='mse', optimizer=SGD(lr=0.2))
model.summary() 
下面开始训练模型,用到model.fit()这个函数
model.fit(X_train,y_train,epochs=50,batch_size=32) 训练50个epoch
下面进行绘图数据可视化
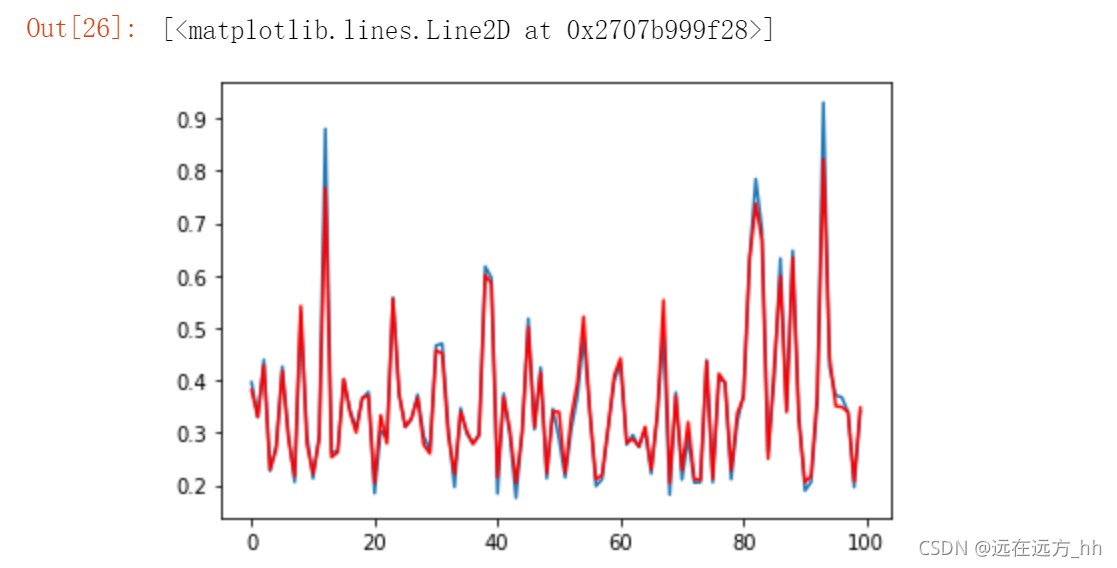
y_predict = model.predict(X_test)
plt.plot(y_test[:100])#取前一百个 真实数据
plt.plot(y_predict[:100],'r') #模型学到的
其实可以看到预测效果还是比较好的。
大家可以试下不同的优化器,激活函数,以及不同的epoch和batch_size......的预测结果
四、与LSTM预测股价的比较
直接跑下代码程序体验会更直观。
完整代码
%matplotlib inline
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, Reshape, Dropout, Activation
from tensorflow.keras.layers import Conv1D, MaxPooling1D
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.optimizers import Adam
from sklearn.model_selection import train_test_split
df = pd.read_csv('AAPL.csv')
df.head()
#len(df) out:1259
x0 = df['Adj Close'].values
#plt.plot(x0[:100])
x0.shape
#len(x0)
#取出x0中最大的数据 让所有的x0与这个最大的值做除法 得到的都是小于1的数据 便于训练神经网络
m = max(x0)
x0 = x0/m
x0[:10]
n = len(x0)
#用20天的数据去预测下一天的数据
p = 20
x = np.array([x0[k:k+p] for k in range(n-p+1)])
#1240笔数据 每个数据都包含20个数据
x.shape
y = np.array(x0[p:])
y.shape
X = x[:-1]
X.shape
X = X[:, :, np.newaxis]
X.shape
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=True)
X_train.shape
#模型搭建
model = Sequential()
model.add(Conv1D(50,4,padding='same',activation='relu',input_shape=(p,1)))#50个filter卷积核 大小4
model.add(MaxPooling1D(2))#每两个取一个大的 数据会减少一半
model.add(Flatten())#把二维数据变成一维的
model.add(Dense(20))#20个神经元的全连接层
model.add(Dropout(0.2))#防止过拟合 20%权重冻结
model.add(Activation('relu'))
model.add(Dense(1))#输出层 是一个一维的全连接神经网络
model.add(Activation('sigmoid'))
#model.compile(loss='mse',optimizer=SGD(lr=0.2), metrics['accuracy'])
model.compile(loss='mse', optimizer=SGD(lr=0.2))
model.summary()
#模型训练
model.fit(X_train,y_train,epochs=50,batch_size=32)
#数据可视化
y_predict = model.predict(X_test)
#plt.plot(y_test)
#plt.plot(y_predict,'r')
plt.plot(y_test[:100])#取前一百个数据绘图 真实数据
plt.plot(y_predict[:100],'r') #模型学到的
CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)