【NLP】神经网络语言模型(NNLM)
背景语言模型也经常会在NLP中提出。在深度学习大行其道的今天基于神经网络的语言模型与传统定义的又有什么区别呢?语言模型在NLP中有什么意义呢?不妨沉下心,了解一下。语言模型是一个单纯的、统一的、抽象的形式系统,语言客观事实经过语言模型的描述,比较适合于电子计算机进行自动处理,因而语言模型对于自然语言的信息处理具有重大的意义。换一句话说,语言模型其实就是看一句话是不是正常人说出来的正常的话。语言模型
背景
语言模型也经常会在NLP中提出。在深度学习大行其道的今天基于神经网络的语言模型与传统定义的又有什么区别呢?语言模型在NLP中有什么意义呢?不妨沉下心,了解一下。
语言模型是一个单纯的、统一的、抽象的形式系统,语言客观事实经过语言模型的描述,比较适合于电子计算机进行自动处理,因而语言模型对于自然语言的信息处理具有重大的意义。换一句话说,语言模型其实就是看一句话是不是正常人说出来的正常的话。语言模型在信息检索、机器翻译、语音识别中担任着重要的任务。比如机器翻译、语音识别得到若干候选之后,可以利用语言模型挑一个尽量靠谱的结果。
传统的语言模型是基于统计的,在深度学习领域那么自然而然也就有了对应的语言模型变体。
语言模型的形式化表达
基于统计的语言模型自然少不了其对应的数学表达,用概率论的专业术语描述模型就是:为长度为m的字符串圈定其概率分布 P ( w 1 , w 2 , . . . , w m ) P(w_1,w_2,...,w_m) P(w1,w2,...,wm),其中 w 1 w_1 w1到 w m w_m wm依次表示文本中的各个词语。一般采用链式发着计算其概率值,如下式:
P ( w 1 , w 2 , . . . , w m ) = P ( w 1 ) P ( w 2 ∣ w 1 ) P ( w 3 ∣ w 1 , w 2 ) . . . P ( w m ∣ w 1 , w 2 , . . . , w m − 1 ) P(w_1,w_2,...,w_m)=P(w_1)P(w_2|w_1)P(w_3|w_1,w_2)...P(w_m|w_1,w_2,...,w_{m-1}) P(w1,w2,...,wm)=P(w1)P(w2∣w1)P(w3∣w1,w2)...P(wm∣w1,w2,...,wm−1)
由上式可知,当文本过长时,公式右部从第三项开始的每一项的计算难度都很大。为解决这个问题,有人提出 n n n元模型(n-gram model)降低该计算难度。所谓 n n n元模型就是在估算条件概率时,忽略距离大于 n n n的上文词的影响,因此 P ( w i ∣ w 1 , w 2 , . . . , w i − 1 ) P(w_i|w_1,w_2,...,w_{i-1}) P(wi∣w1,w2,...,wi−1)的计算可以化简为:
P ( w i ∣ w 1 , w 2 , . . . , w i − 1 ) ≈ P ( w i ∣ w i − ( n − 1 ) , . . . , w i − 1 ) P(w_i|w_1,w_2,...,w_{i-1})\approx P(w_i|w_{i-(n-1)},...,w_{i-1}) P(wi∣w1,w2,...,wi−1)≈P(wi∣wi−(n−1),...,wi−1)
当
n
=
1
n=1
n=1时称为一元模型(unigram model),此时整个句子的概率可表示为:
P
(
w
1
,
w
2
,
.
.
.
,
w
m
)
=
P
(
w
1
)
P
(
w
2
)
.
.
.
P
(
w
m
)
P(w_1,w_2,...,w_m)=P(w_1)P(w_2)...P(w_m)
P(w1,w2,...,wm)=P(w1)P(w2)...P(wm)
观察可知,在一元语言模型中,整个句子出现的概率等于各个词语出现概率的乘积。言下之意就是各个词之间都是相互独立的,这无疑完全损失了语序信息。所以一元模型的效果并不理想。
当
n
=
2
n=2
n=2时称为二元模型(bigram model),那么一个语句出现的概率变为:
P
(
w
i
∣
w
1
,
w
2
,
.
.
.
,
w
i
−
1
)
=
P
(
w
i
∣
w
i
−
1
)
P(w_i|w_1,w_2,...,w_{i-1})= P(w_i|w_{i-1})
P(wi∣w1,w2,...,wi−1)=P(wi∣wi−1)
以此类推,当
n
=
3
n=3
n=3的时候成为三元模型(trigram model),整个句子出现的概率变为:
P
(
w
i
∣
w
1
,
w
2
,
.
.
.
,
w
i
−
1
)
=
P
(
w
i
∣
w
i
−
2
,
w
i
−
1
)
P(w_i|w_1,w_2,...,w_{i-1})= P(w_i|w_{i-2},w_{i-1})
P(wi∣w1,w2,...,wi−1)=P(wi∣wi−2,wi−1)
很显然当
n
≥
2
n\geq2
n≥2时,该模型时可以保留一定的次序信息的,而且
n
n
n越大,保留词序信息就越丰富,但计算成本也呈指数级增长。
一般使用频率计数的比例来计算 n n n元条件概率,如下式:
P ( w i ∣ w i − ( n − 1 ) , . . . , w i − 1 ) = c o u n t ( w i − ( n − 1 ) , . . . , w i − 1 , w i ) c o u n t ( w i − ( n − 1 ) , . . . , w i − 1 ) P(w_i|w_{i-(n-1)},...,w_{i-1})=\frac{count(w_{i-(n-1)},...,w_{i-1},w_i)}{count(w_{i-(n-1)},...,w_{i-1})} P(wi∣wi−(n−1),...,wi−1)=count(wi−(n−1),...,wi−1)count(wi−(n−1),...,wi−1,wi)
式中 c o u n t ( w i − ( n − 1 ) , . . . , w i − 1 ) count(w_{i-(n-1)},...,w_{i-1}) count(wi−(n−1),...,wi−1)表示词语 w i − ( n − 1 ) , . . . , w i − 1 w_{i-(n-1)},...,w_{i-1} wi−(n−1),...,wi−1在语料库中出现的总次数。
由此可见,当 n n n越大时,模型包含的次序信息越丰富,同时计算量随之增大。与此同时,长度越长的文本序列出现的次数也会越少,不过依照这种估计 n n n元条件概率时,就会出现分字分母为零的情况。因此,一般在 n n n元模型中需要配合相应的平滑算法解决该问题,例如拉普拉斯平滑算法。
NNLM
用神经网络训练语言模型的思想最早由徐伟在《Can Artificial Neural Networks Learn Language Models?》中提出。论文中提出一种用神经网络构建二元语言模型即: P ( w i ∣ w i − 1 ) P(w_i|w_{i-1}) P(wi∣wi−1)。
训练语言模型的最经典之作要数 Bengio 等人在 2001 年发表在 NIPS 上的文章《A Neural Probabilistic Language Model》。网上也有人说,现在看的话,要看他在 2003 年投到 JMLR 上的同名论文了。
了解了这个其实也有助于理解word2vector那篇文章。那么我们先来看看这个论文中的内容。
1 A Neural Probabilistic Language Model
Bengio 用了一个三层的神经网络来构建语言模型,同样也是 n-gram 模型。如下图:
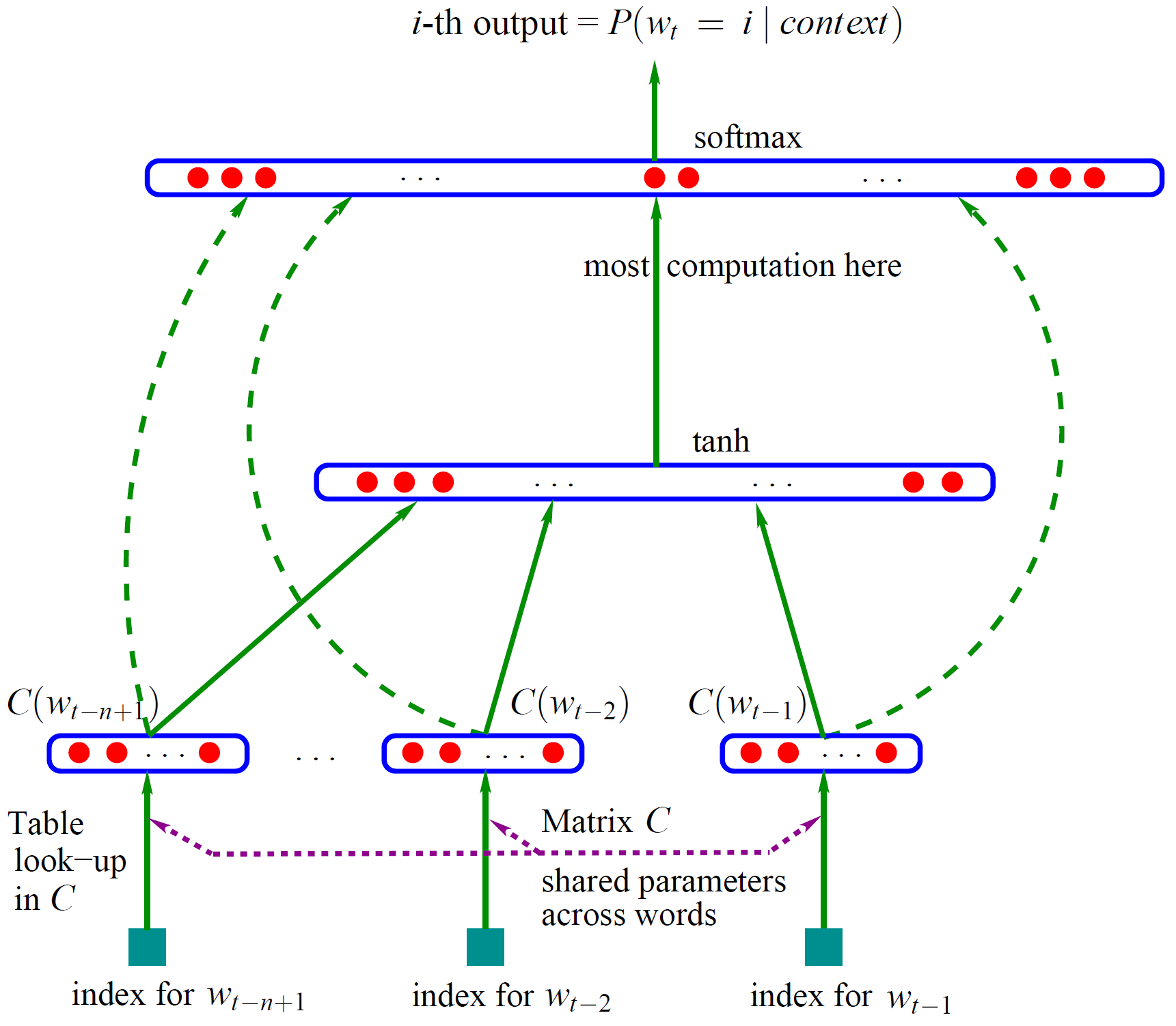
模型的输入:
w
t
−
n
+
1
,
⋯
,
w
t
−
2
,
w
t
−
1
w_{t-n+1},\cdots,w_{t-2},w_{t-1}
wt−n+1,⋯,wt−2,wt−1就是前
n
−
1
n-1
n−1个词。现在需要根据这已知的
n
−
1
n-1
n−1个词预测下一个词
w
t
w_t
wt。
C
(
w
)
C_(w)
C(w)表示
w
w
w所对应的词向量。整个模型中使用的是一套唯一的词向量,存在一个大小为
∣
V
∣
×
m
|V|\times m
∣V∣×m的矩阵
C
C
C中,
V
V
V表示语料中的总词数,
m
m
m表示词向量的维度。
w
w
w到
C
(
w
)
C(w)
C(w)的转化就是从矩阵中取出一行。
网络的第一层(输入层)是将 C ( w t − n + 1 , ⋯ , C ( w t − 2 ) , C ( w t − 1 C(w_{t-n+1},\cdots,C(w_{t-2}), C(w_{t-1} C(wt−n+1,⋯,C(wt−2),C(wt−1这 n − 1 n-1 n−1个向量首尾拼接起来形成一个 ( n − 1 ) × m (n-1)\times m (n−1)×m大小的向量,记作 x x x,
网络的第二层(隐藏层)就如同普通的神经网络,直接使用一个全连接层: d + H x d+Hx d+Hx计算得到,其中 d d d表示偏置, H H H则是对应向量的权重。通过全连接层后再使用 t a n h tanh tanh这个激活函数进行处理。
网络的第三层(输出层)一共有
V
V
V个节点,本质上这个输出层也是一个全连接层。每个输出节点
y
i
y_i
yi表示下一个词语为
i
i
i(词表中的索引)的未归一化
log
\log
log 概率。最后使用
s
o
f
t
m
a
x
softmax
softmax 激活函数将输出值
y
y
y进行归一化。那么这个
y
y
y在整个模型中的计算如下:
y
=
b
+
W
x
+
U
t
a
n
h
(
d
+
H
x
)
y=b+Wx+U \mathbf{tanh}(d+Hx)
y=b+Wx+Utanh(d+Hx)
式中的
U
U
U是一个
∣
V
∣
×
h
|V|\times h
∣V∣×h的矩阵,是隐藏层到输出层的参数,整个模型的多数计算集中在
U
U
U和隐藏层的矩阵乘法中。后文的提到的 3 个工作,都有对这一环节的简化,提升计算的速度。上式中还有一个大小为
∣
V
∣
×
(
n
−
1
)
m
|V|\times (n-1)m
∣V∣×(n−1)m矩阵
W
W
W,主要是将输入层的数据结果也放到输出层进行计算的线性变换,称为直连边。如果不需要直连边的话,将
W
W
W置为 0 就可以了。在最后的实验中,Bengio 发现直连边虽然不能提升模型效果,但是可以少一半的迭代次数。同时他也猜想如果没有直连边,可能可以生成更好的词向量。
现在万事俱备,用随机梯度下降法把这个模型优化出来就可以了。需要注意的是,一般神经网络的输入层只是一个输入值,而在这里,输入层 x x x也是参数存在与 C C C中,,也是需要优化的。优化结束之后,词向量有了,语言模型也有了。
这样得到的语言模型自带平滑,无需传统 n-gram 模型中那些复杂的平滑算法。Bengio 在 APNews 数据集上做的对比实验也表明他的模型效果比精心设计平滑算法的普通 n-gram 算法要好 10% 到 20%。
那么这篇文章到这就告一段落了。可以从上面的介绍可以看出可以利用这种语言模型去训练词向量,也可以预测一个语句中下一个词是什么等等。
Bengio 还在论文中随口(不是在 Future Work 中写的)提到:可以使用一些方法降低参数个数,比如用循环神经网络。后来 Mikolov 就顺着这个方向发表了一大堆论文,直到博士毕业。下面我们就看看Mikolv提出的RNNLM(循环神经网络模型)。
2.Mikolov 的 RNNLM
Mikolov 一直在RNNLM 上做各种改进,有速度上的,也有准确率上的。现在想了解 RNNLM,看他的博士论文《Statistical Language Models based on Neural Networks》肯定是最好的选择。
循环神经网络在之前的文章中已经介绍过了。下面的模型就比较好理解了。RNNLM结构如下:
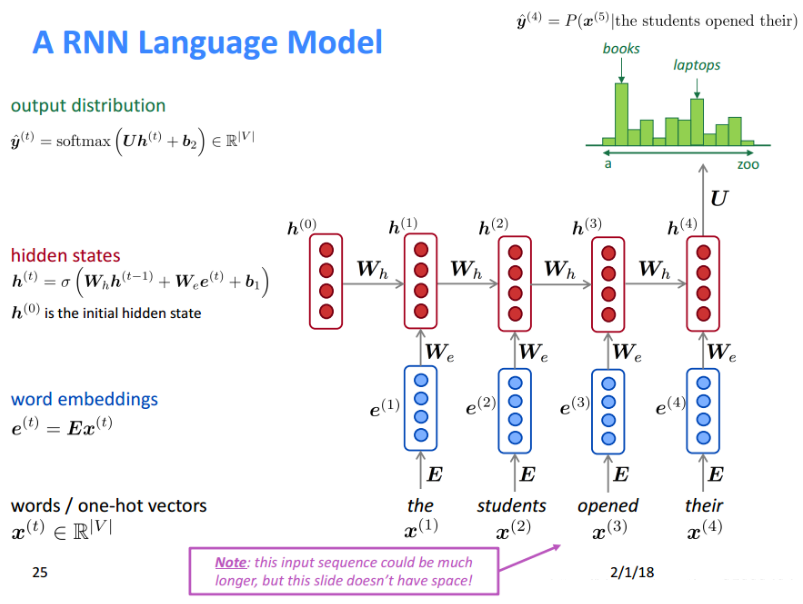
每个时间步的输入为
x
(
t
)
x^{(t)}
x(t),是句子中第
t
t
t个词的 One-hot representation 的向量,也就是说
x
(
t
)
x^{(t)}
x(t)是一个非常长的向量,里面只有一个元素是 1。
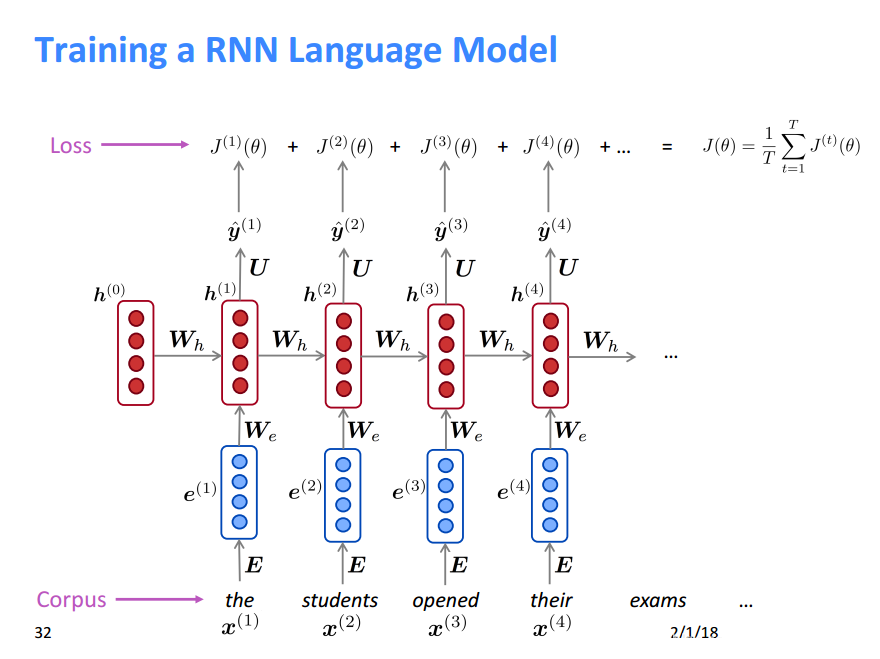
RNNLM训练过程
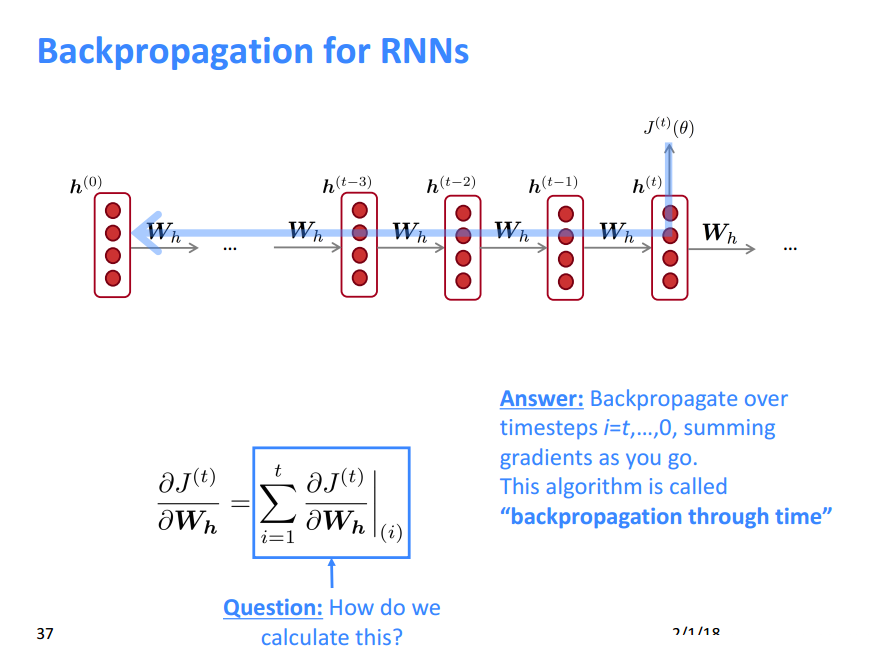
RNNLM反向传播过程
语言模型评估
迷惑度/困惑度/混乱度(perplexity),其基本思想是给测试集的句子赋予较高概率值的语言模型较好。当语言模型训练完之后,测试集中的句子都是正常的句子,那么训练好的模型就是在测试集上的概率越高越好。迷惑度越小,句子概率越大,语言模型越好。
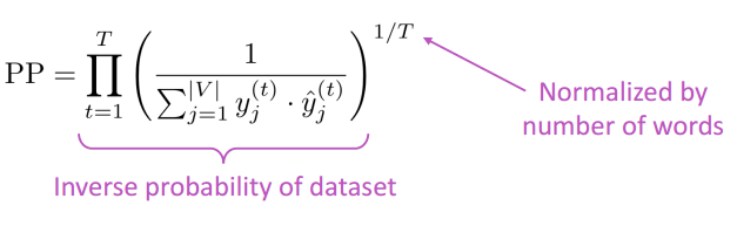
循环神经网络的最大优势在于,可以真正充分地利用所有上文信息来预测下一个词,而不像前面的其它工作那样,只能开一个
n
n
n 个词的窗口,只用前
n
n
n个词来预测下一个词。从形式上看,这是一个非常“终极”的模型,毕竟语言模型里能用到的信息,他全用上了。可惜的是,循环神经网络形式上非常好看,使用起来却非常难优化,如果优化的不好,长距离的信息就会丢失,甚至还无法达到开窗口看前若干个词的效果。Mikolov 在 RNNLM 里面只使用了最朴素的 BPTT 优化算法,就已经比 n-gram 中的 state of the art 方法有更好的效果,这非常令人欣慰。如果用上了更强的优化算法,最后效果肯定还能提升很多。
当然RNNLM更侧重的是语言模型,而不是词向量。后期谷歌发表的word2vector则是针对词向量做出的优化。
总结
神经网络语言模型在NLP任务中起到了一定作用。现如今的使用的词向量基本上都是源于这个思想。也为自然语言生成提供了很好的思路。现如今NLP技术发展训练基于Bert的技术可谓是大行其道,当然如若没有以往语言模型的提出,现在的发展也是让人难以琢磨。虽然现在的Bert效果很好,了解一下以往发展的技术,也能够清晰地了解现在技术发展的前前后后。
Reference
- Deep Learning in NLP (一)词向量和语言模型
- 《Can Artificial Neural Networks Learn Language Models?》
- Yoshua Bengio, Rejean Ducharme, Pascal Vincent, and Christian Jauvin. A neural probabilistic language model. Journal of Machine Learning Research (JMLR), 3:1137–1155, 2003. PDF
- NLP自然语言处理:神经网络语言模型(NNLM)
- Mikolov Tomáš. Statistical Language Models based on Neural Networks. PhD thesis, Brno University of Technology. 2012. PDF

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 2
2 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)