深度学习(DL)-2.2 深度学习优化技巧——优化算法 (Optimization algorithms)
1.优化算法1.1 基本概念定义: 优化算法是用来找到模型最优参数的方法,最常用的即梯度下降法分类: (1)调整学习率,使优化更稳定 (2)梯度估计修正,优化训练速度1.2 小批量梯度下降法 (Mini-batch gradient descent)原因: 由于深度学习通常数据量较大,如果每次都使用全部训练集数据来计算梯度,则会使模型训练速度很慢,且训练集数据中通常存在冗余,没必要使用整个训练集来
1.优化算法
1.1 基本概念
定义: 优化算法是用来找到模型最优参数的方法,最常用的即梯度下降法
问题: 陷入局部最优解;优化算法还需要解决这些问题
(1)鞍点:梯度为0,在高维空间中,局部最优解通常是鞍点,而不是最低点

(2)平原:梯度很小的区域,会导致训练速度很慢

原理: 每次参数的更新都由两个因素决定,梯度与学习率;其中,梯度决定了参数更新的方向,学习率决定了参数更新的步长;因此一个好的优化算法需要从这两方面进行考虑
分类:
(1)基于梯度估计修正:优化方向,使训练速度提升
(2)基于调整学习率:优化步长,使训练过程更加稳定
1.2 小批量梯度下降法 (Mini-batch gradient descent)
原因: 由于深度学习通常数据量较大,如果每次都使用全部训练集数据来计算梯度,则会使模型训练速度很慢,且训练集数据中通常存在冗余,没必要使用整个训练集来计算梯度
定义: 将训练集划分为多个小批量,每次使用一个批量来计算梯度更新模型参数,能够实现向量化并利用并行计算提高速度

功能: 提高计算效率,但会使训练过程更不稳定

实现:
每次只用一个批量数据来计算梯度并更新参数

不同批量大小(batch size)的影响:
- 随机梯度下降(stochastic gradient descent):batch size=1;一次迭代时间很快,但训练效果差,随机性强,如下图紫色路径
- 批量梯度下降(batch gradient descent):batch size=m;一次迭代时间很长,训练速度慢,训练效果好,更稳定,如下图蓝色路径
- 小批量梯度下降(mini-batch gradient descent):batch size = 1~m;在训练速度和训练效果间进行平衡折中,兼具两者优点,如下图绿色路径

批量大小选择:
小训练集(m<2000):使用批量梯度下降,数据量小,无需使用小批量梯度下降
大训练集:使用小批量梯度下降;选用2的指数作为batch-size,否则会使训练效果不稳定,如64,128,512等

2.基于学习率调整的算法
2.1 基本概念
定义: 通过一系列方法来在训练过程中自动调整学习率
原因: 学习率过大则难以收敛至最优解;学习率过小则训练速度慢;因此,固定的学习率很难满足实际需求,需要一种方法在训练过程中自动调整学习率大小
2.2 学习率衰减法
定义: 在训练过程中不断减小学习率,使得训练开始时步长大收敛速度快,训练后期步长减少更易收敛,减小震荡
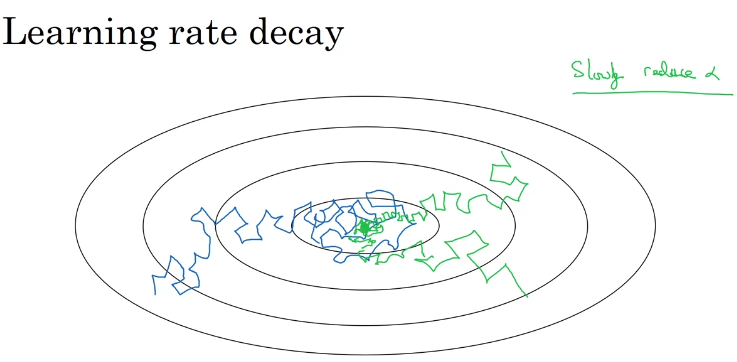
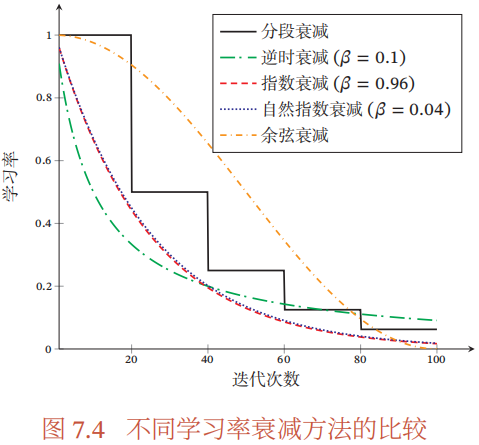
常用衰减方法:
- 分段常数衰减:每经过 T m T_m Tm次迭代,学习率减少至原来的 β m \beta_m βm倍,其中 T m T_m Tm与 β m \beta_m βm需要根据经验设置
- 逆时衰减: α t = α 0 1 1 + β ∗ t \alpha_t=\alpha_0 \frac{1}{1+\beta*t} αt=α01+β∗t1,其中 β \beta β为衰减率
- 指数衰减: α t = α 0 β t \alpha_t=\alpha_0\beta^t αt=α0βt,其中 β < 1 \beta<1 β<1为衰减率
- 自然指数衰减: α t = α 0 e x p ( − β ∗ t ) \alpha_t=\alpha_0exp(-\beta*t) αt=α0exp(−β∗t),其中 β \beta β为衰减率
- 余弦衰减:
α
t
=
1
2
α
0
(
1
+
c
o
s
(
t
π
T
)
)
\alpha_t=\frac{1}{2}\alpha_0(1+cos(\frac{t\pi}{T}))
αt=21α0(1+cos(Ttπ)),其中T为迭代次数
2.3 AdaGrad算法
定义: 借鉴L2正则化思想,每次迭代时自适应调整每个参数的学习率
原因: 不同参数的收敛速度不同,因此需要为不同参数设置不同的学习率
实现:
首先计算在第t次迭代时,每个参数梯度平方的累计值:
G t = ∑ τ = 1 t g τ ⊙ g τ G_t = \sum_{\tau=1}^{t}g_\tau \odot g_\tau Gt=∑τ=1tgτ⊙gτ
其中,
⊙
\odot
⊙为按元素相乘,
g
τ
g_\tau
gτ是第
τ
\tau
τ次迭代时的梯度
参数更新差值为:

原理: 根据各参数的累计梯度来决定当前修改值,若某参数累计梯度较大,则为其设置较小学习率,反之为其设置较大学习率;
限制更新速度较快的参数,反之其过拟合,加快更新速度较慢的参数,提高其训练速度
缺点: 学习率只能不断减少,在一定迭代次数后学习率会非常小,使得训练速度极慢,难以继续
2.4 RMSprop算法
定义: 一种对AdaGrad改进的自适应学习率调整方法,能够避免学习率不断单调下降以至于过早衰减的缺点
实现:
首先计算每次迭代梯度
g
t
g_t
gt平方的指数衰减移动平均:

其中𝛽 为衰减率,一般取值为0.9
参数更新差值为:

其中𝛼是初始的学习率,比如0.001
原理:
基本与AdaGrad相似,但其计算累计梯度的方式由累加变为指数加权平均,使得每个参数的学习率不仅能减小,也可以增大
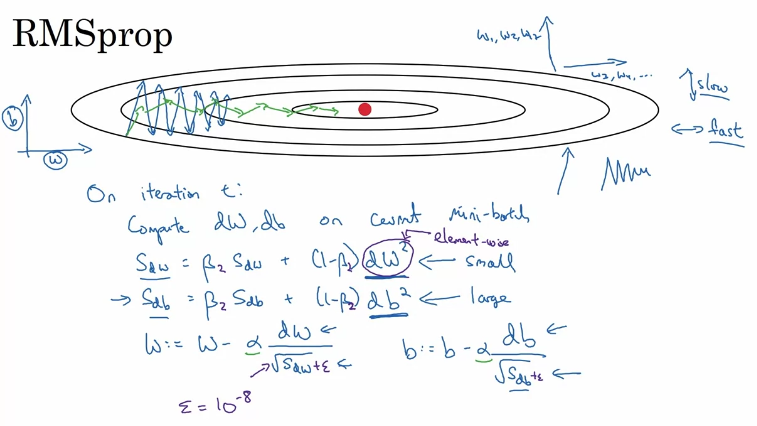
优点: 解决学习率只能减小而导致过早衰减的问题
2.5 AdaDelta算法
定义: 另一种对AdaGrad改进的自适应学习率方法,使用指数衰减移动平均来调整学习率,还引入了每次更新差值
Δ
θ
\Delta \theta
Δθ的平方的指数衰减移动平均
实现:
在第t次迭代时,参数更新值
Δ
θ
\Delta \theta
Δθ的平方的指数衰减移动平均为:

每次迭代梯度
g
t
g_t
gt平方的指数衰减移动平均为:
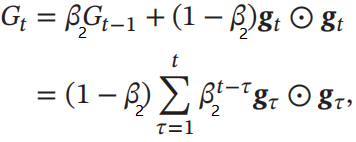
其中,
β
1
\beta_1
β1和
β
2
\beta_2
β2为衰减率
参数更新差值为:
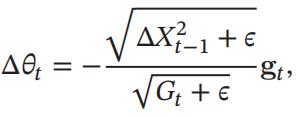
优点: 无需手动设置初始学习率,全部由算法自动调整
3.基于梯度估计修正的算法
3.1 基本概念
定义/原理: 通过对梯度进行修正,以改变参数更新的方向,使模型训练速度更快,更易收敛至全局最优解
原因: 在随机(小批量)梯度下降法中,由于每次只用部分数据计算梯度,因此得到的梯度并不是最优梯度,具有一定随机性,使得训练过程具有波动性
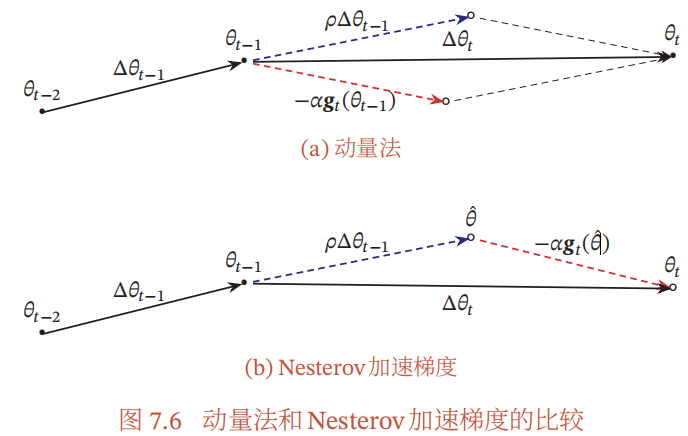
3.2 动量法 (Gradient descent with momentum)
原因:
过小学习率导致每次更新步长很短,训练速度慢
过大学习率导致难以停在最优点处,训练效果差
定义: 引入动量的概念,使参数的变化具有"惯性",用历史累计动量来代替当前梯度,考虑了历史梯度的影响

功能: 引入指数平均概念,若一段时间内梯度方向一致,则会加速,若不一致则减速,能够在训练初期加速训练并在后期减少波动
原理: 指数加权平均
定义:指数加权平均即滑动平均,在一定历史范围内求平均值,且各时期的权重不同,越靠近当前时刻的权重越大
计算公式:
v
t
=
β
v
t
−
1
+
(
1
−
β
)
θ
t
v_t = \beta v_{t-1}+(1-\beta)\theta_t
vt=βvt−1+(1−β)θt
其中,β为衰减系数,其值越大平均效果越强,曲线越平滑,但精确度下降;
θ
t
\theta_t
θt表示第t步迭代的参数
原理:通过对历史参数计算指数加权平均实现动量效果,使得历史参数值能够影响对当前参数的修改

实现:
每次迭代参数更新差值为:
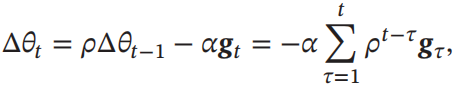
其中,
ρ
\rho
ρ为动量因子,常设为0.9,
α
\alpha
α为学习率

3.3 Nesterov动量法
定义: 一种对动量法的改进,改变计算梯度的时间点,使参数更新方向更合理
实现:
每次迭代参数更新差值为:
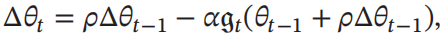
原理:
动量法中,计算的梯度实际是
θ
t
−
1
\theta_{t-1}
θt−1时刻的梯度,并不是真实的梯度;而牛顿动量法通过对
Δ
θ
\Delta \theta
Δθ进行拆分,直接对
θ
^
\hat \theta
θ^计算梯度,更加准确
3.4 Adam算法
定义: 是动量法和RMSprop算法的结合,不但使用动量作为参数更新方向,而且可以自适应调整学习率。是目前最常用的方法
实现:
首先计算梯度的指数加权平均(同动量法):
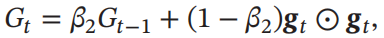
计算梯度平方的指数加权平均(同RMSprop):

然后,对偏差进行修正:
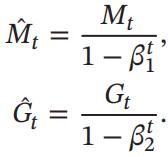
最后,参数更新的差值即为:

其中,
α
\alpha
α为学习率,通常设为0.001,
β
1
\beta_1
β1和
β
2
\beta_2
β2为衰减率,通常设为0.9和0.99
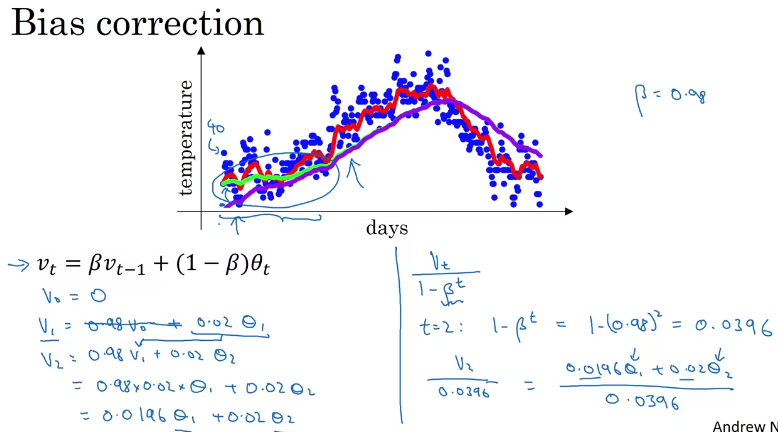
偏差修正(选修):
原因:指数加权平均中,通常设初始值
v
0
=
0
v_0=0
v0=0,因此一开始的值会很小,与实际不符产生偏置,所以需要进行修正
方法:增加修正项,
v
t
=
v
t
/
1
−
β
t
v_t ={v_t}/{1-β^t}
vt=vt/1−βt
4.总结
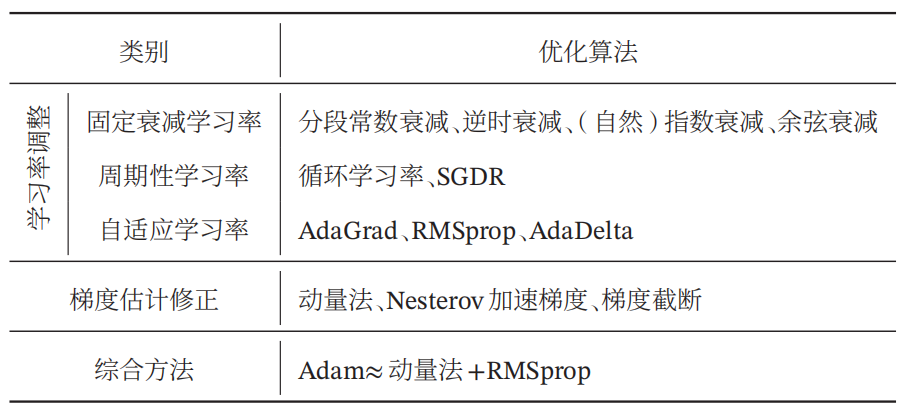
常用方法汇总:
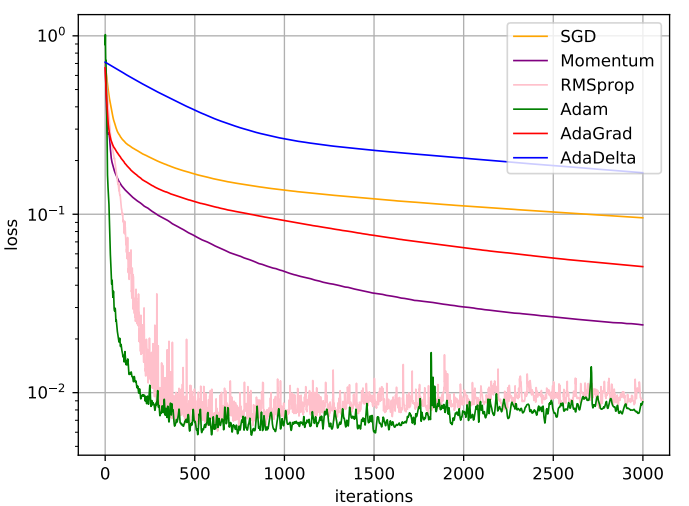
不同优化算法比较:
内容汇总:Coursera深度学习(DL)专项课-课程笔记与编程实战-汇总
参考资料:B站:“随机梯度下降、牛顿法、动量法、Nesterov、AdaGrad、RMSprop、Adam”,打包理解对梯度下降法的优化

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)