【模式识别-北理工】02模式识别算法体系
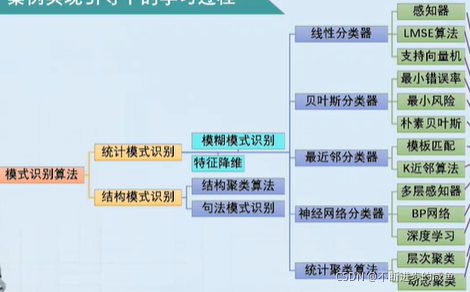
模式识别算法体系 模式识别算法体分为两大类: (1)统计模式识别(主流) 将样本转化为多维特征空间中的点,再根据样本的特征取值情况和样本集的特征值分布情况,确定分类决策规则 1)线性分类器:最基本的统计分类器通过寻找线性决策分类边界实现特征空间中的类别划分。(感知机,LMSE算法,支持向量机) 2)贝叶斯分类器:基于不同类样本在特征空间中的概率分布,以逆概率推理的贝叶斯公式,来得到类别划
·
模式识别算法体系
模式识别算法体分为两大类:
(1)统计模式识别(主流)
将样本转化为多维特征空间中的点,再根据样本的特征取值情况和样本集的特征值分布情况,确定分类决策规则
1)线性分类器:最基本的统计分类器通过寻找线性决策分类边界实现特征空间中的类别划分。(感知机,LMSE算法,支持向量机)
2)贝叶斯分类器:基于不同类样本在特征空间中的概率分布,以逆概率推理的贝叶斯公式,来得到类别划分的结果。(最小错误率,最小风险,朴素贝叶斯)
3)最近邻分类器:把学习过程隐藏到分类决策中,通过寻找训练集样本与待分类样本最相似的子集,来进行分类决策。(模板匹配,K近邻算法)
4)神经网络分类器:对生物神经网络的模拟,本质高度非线性的统计分类器,新一轮人工智能的基础。(BP网络,深度学习)
5)统计聚类算法:无监督学习的典型代表。(层次聚类,动态聚类)
(2)结构模式识别
不是抽取数值型特征,而是将样本结构上的某些特征,作为类别和个体的特征,通过结构上的相似性,来完成分类任务
1)句法模式识别:利用形式语言理论中的语法规则,将样本的结构特征,转化为句法的类型判定,从而实现模式识别的功能。
2)结构聚类分析:根据结构特征的相似性,完成样本类别的划分。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)