深度学习:前馈网络 Feedforward Networks
深度学习深度学习是机器学习的分支,也就是神经网络。称之为 深度 因为有很多连接在一起的神经层。前馈网络前馈神经网络是指单元之间不形成循环的人工神经网络。因此,它不同于递归神经网络。前馈神经网络是设计出来的第一个也是最简单的一类人工神经网络。在这个网络中,信息只向一个方向移动,从输入节点,通过隐藏节点(如果有的话),再到输出节点。网络中没有循环。前馈神经网络是一个人工神经网络,并且没有循环,单向传播
深度学习
深度学习是机器学习的分支,也就是神经网络。
称之为 深度 因为有很多连接在一起的神经层。
前馈网络
前馈神经网络是指单元之间不形成循环的人工神经网络。因此,它不同于递归神经网络。
前馈神经网络是设计出来的第一个也是最简单的一类人工神经网络。
在这个网络中,信息只向一个方向移动,从输入节点,通过隐藏节点(如果有的话),再到输出节点。网络中没有循环。
前馈神经网络是一个人工神经网络,并且没有循环,单向传播,是最简单的人工神经网络。
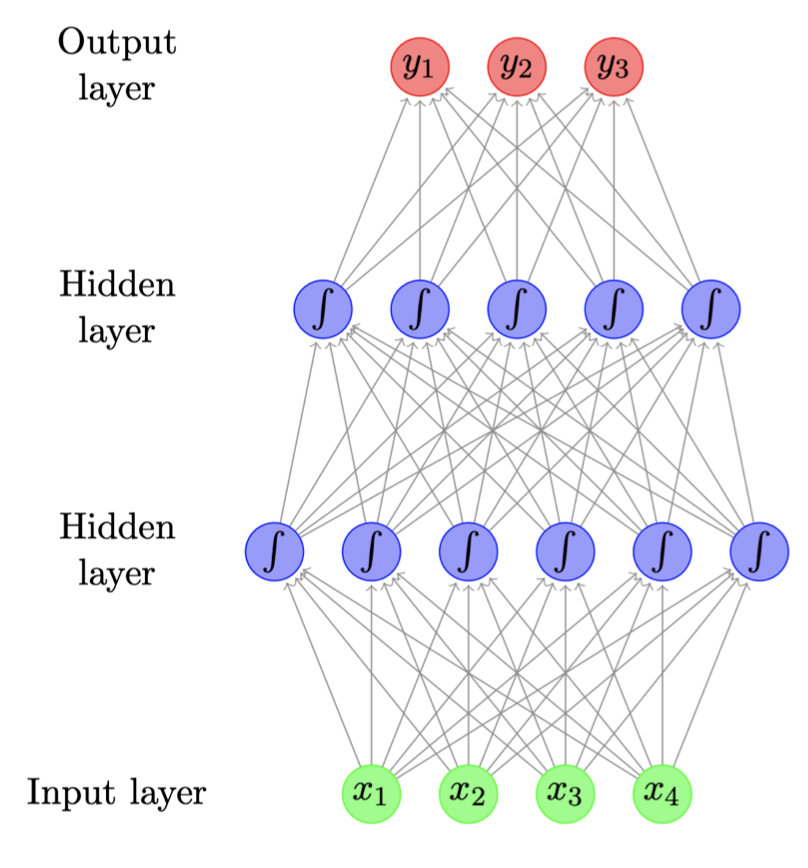
结构如下:
网络计算异或的两层神经网络。
神经元内的数字代表每个神经元的明确阈值(可以分解出来,以便所有神经元都有相同的阈值,通常是1)。标注箭头的数字代表输入的权重。
这个网络假设如果没有达到阈值,则输出0(不是-1)。请注意,输入的底层并不总是被认为是真正的神经网络层。
计算XOR的两层神经网络。 神经元内的数字表示每个神经元(Perceptron层)的显式阈值(可以将其分解,以便所有神经元具有相同的阈值,通常为1)。
注释箭头的数字代表输入的权重。 该网络假定如果未达到阈值,则输出零。 请注意,最后一层(Output层)的输入并不是一个真正的神经网络层。
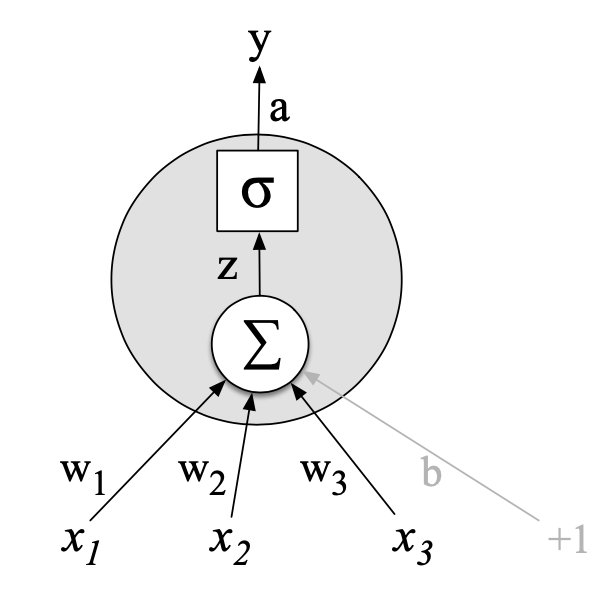
其中,每一个节点都可以看做是一个函数,将上一层传过来的输入信息做线性变换,再经过一个激活函数输出给下一层。
如下图所示
表示权重weight,
表示偏差bias,
是一种激活函数
对于最后的输出层,我们可以根据任务的种类来选择激活函数。
如二分类任务中我们使用sigmoid函数(也就是logistic函数),多分类任务中使用softmax函数(得到的值都在0-1之间,看做概率)。
Word Embedding
在NLP的深度学习中,现在最流行的表示词的方法就是Word Embedding,它将词map成(一般较低纬度的)向量的形式,而这些向量的背后也是具有含义的,比如猫和狗的向量表示会比猫和石头来的接近(cosine距离)。那么要怎么得到词的Word Embedding呢?也是可以用神经网络来训练得到(其实就是神经层的weights)。在后面的例子中可以看到具体是怎么实现的。
训练
模型的输入可以是one-hot,也可以是词袋,词向量,或者TF-IDF之类的表示,训练过程其实就是参数的学习过程,通过最大化概率L=∏mi=0P(yi|xi)L=∏i=0mP(yi|xi),或者最小化−logL−logL来训练,这里就需要用到梯度下降的方法,具体不再展开,实际中都是学习框架完成的,如TensorFlow,pytorch等。
优缺点
优点:
‣ Robust to word variation, typos, etc
‣ Excellent generalization
‣ Flexible — customised architecture for different tasks
缺点:
‣ Much slower than classical ML models... but GPU acceleration
‣ Lots of parameters due to vocabulary size
‣ Data hungry, not so good on tiny data sets
‣ Pre-training on big corpora helps

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)