进阶之路:从零到一在k8s上部署高可用prometheus —— 总览
目录前言thanos前言最近研究了一下关于云原生的监控+告警的方案,由于prometheus对k8s的支持十分优秀,基本上已经是云原生监控的标准了,而且之前也有一些相关的知识积累,所以没花太多功夫就确认了使用prometheus + alertmanager的组合。但是由于监控系统的特殊性,我们不可避免的需要考虑到如何保证高可用。虽然prometheus的性能十分优秀,但是仍然会有性能瓶颈,而且单
导航
进阶之路:从零到一在k8s上部署高可用prometheus —— 总览
进阶之路:从零到一在k8s上部署高可用prometheus —— 准备工作
进阶之路:从零到一在k8s上部署高可用prometheus —— exporter
进阶之路:从零到一在k8s上部署高可用prometheus —— consul
进阶之路:从零到一在k8s上部署高可用prometheus —— prometheus-operator
进阶之路:从零到一在k8s上部署高可用prometheus —— prometheus
进阶之路:从零到一在k8s上部署高可用prometheus —— alertmanager
进阶之路:从零到一在k8s上部署高可用prometheus —— minio
进阶之路:从零到一在k8s上部署高可用prometheus —— thanos receive、thanos query
前言
最近研究了一下关于云原生的监控+告警的方案,由于prometheus对k8s的支持十分优秀,基本上已经是云原生监控的标准了,而且之前也有一些相关的知识积累,所以没花太多功夫就确认了使用prometheus + alertmanager的组合。但是由于监控系统的特殊性,我们不可避免的需要考虑到如何保证高可用。虽然prometheus的性能十分优秀,但是仍然会有性能瓶颈,而且单节点服务会有潜在的单点故障问题。
prometheus官方为应对上述问题,提供了联邦集群(federation)的解决方案。但是经过调研后发现由于prometheus没有数据同步的能力,该方案采用的是将多个子prometheus节点的数据汇总到一个父prometheus节点上(类似一棵树),再由父节点对外提供服务的方式。这种方案虽然一定程度上缓解了数据采集的性能瓶颈问题,但是并没有解决关键的单点问题(从子节点转移到了父节点)。
经过对比和筛选后,最终选择用thanos来实现prometheus的高可用。thanos提供了两种部署架构:thanos sidecar和thanos receive。关于两者的对比可以看这篇文章。本文选择了thanos receive部署方案。
技术支持
有的小伙伴在按照文章操作时遇到了各种各样奇奇怪怪的问题,私信上解决问题的效率又比较低。大家可以试试用AI解决自己的问题,既学到了新东西又解决了问题美滋滋~目前我用下来最好用的还是GPT,3.5模型足以解决各类编程问题了,但是使用有一定门槛(魔法上网+海外支付)。如果没有条件的小伙伴可以试试这个,送的100次对话足够解决问题了。
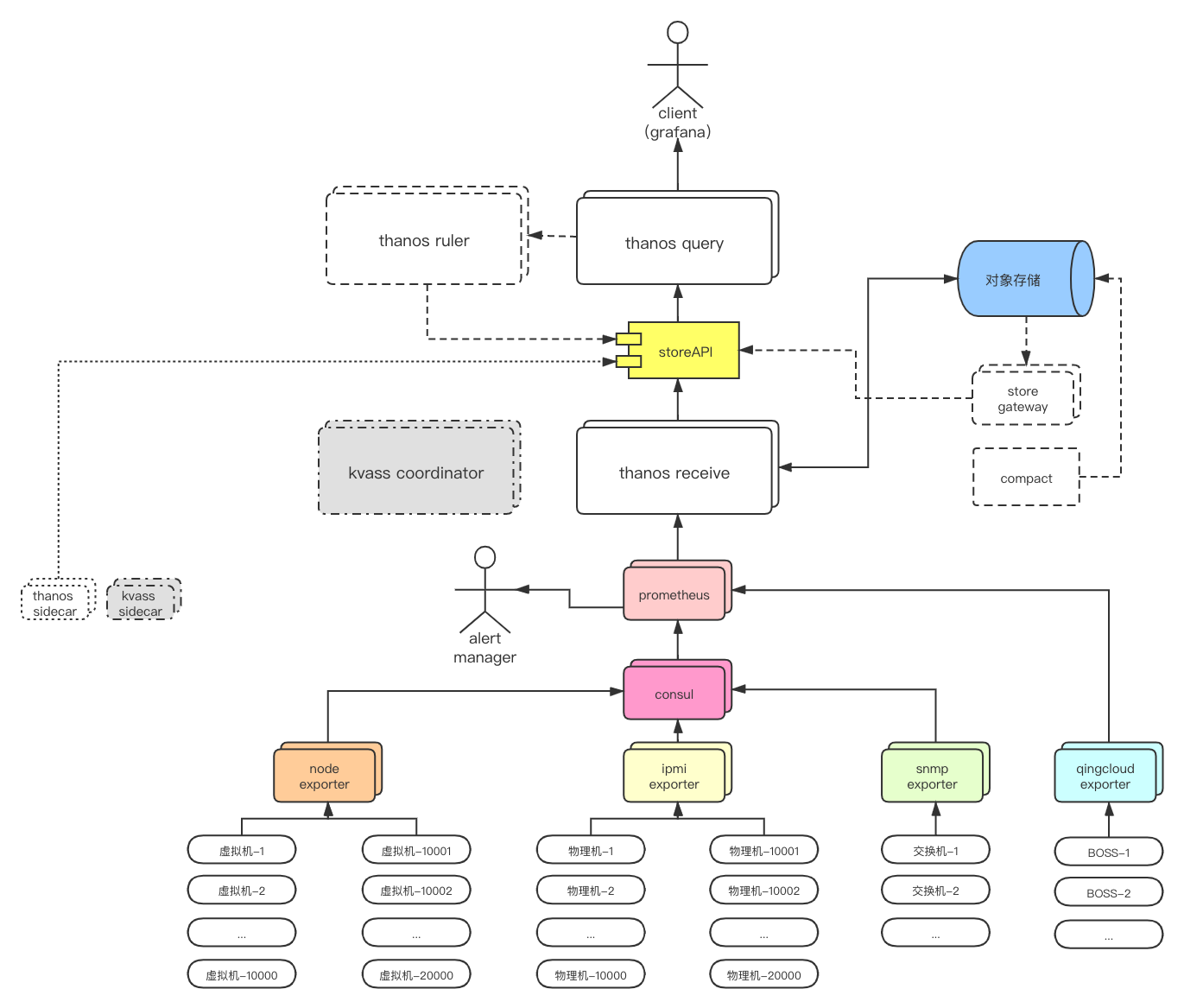
架构思路
- 动态注册:在prometheus上配置
consul_sd_configs,通过将exporter以API的方式注册到consul上,从而实现prometheus动态发现target。(参考prometheus + consul实现动态添加监控节点) - prometheus高可用:将prometheus的数据通过remote_write的方式写到
thanos receive组件,从而使prometheus本身无状态化,通过横向扩展即可达到高可用的目的。 - 数据持久化:thanos recieve支持将数据保存到
对象存储。 - 历史数据:用
thanos store组件读取。 - 数据聚合:
thanos query组件可以实现聚合数据的效果,客户端通过thanos query查询数据时可以按需获取全量数据或聚合后的数据。 - alertmanager高可用:在启动参数里加上
cluster.peer即可实现alertmanager的高可用,prometheus-operator可以自动补全相关配置,我们只需关注节点数量即可。 - 告警规则:本例中使用
prometheusRule(prometheus-operator的crd)创建并应用告警规则。
架构图
注:图中部分组件是方案的后续设计思路,在本系列文章中不会涉及到。


K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 2
2 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)