深度学习之路
学习记录一、python【7.19】菜鸟教程数据类型二、cs231n1.k-最近邻算法2.线性分类
学习记录
一、机器学习
【7.19】6.1代价函数
6.2决策边界
【7.20】8.1神经网络
8.2模型表示
【7.30】9.7综合起来
二、深度学习
(1)哈佛李飞飞 cs231n
【7.19】【10.20】1.k-最近邻算法
2.线性分类
【7.22】反向传播
【9.18】激活函数
(2)同济子豪兄与导师 cs231n
【10.20】k-最近邻算法
利用L1曼哈顿距离或者L2欧氏距离的和计算相似程度
是一个惰性算法,K为1时决策边界是垂直平分线
损失函数
【10.24】
损失函数越小越好
均方误差:
分类正确时:(正确项概率 - 正确项标签为1)2 小于 分类错误时(没预测对这一项概率 - 1)2 +(预测的其他项,这一项概率较高 - 0)2
【2023.6.10】
最小二乘法: 让误差的平方和最小,是一种函数拟合的方法。

极大似然估计:王木头学科学
似然值是指真实的情况已经发生,假设有很多的概率模型,在其中一个概率模型下发生这个情况的可能性。选择其中似然值最大的可能性也就最高,但是并不意味着这种情况的概率模型确定下来了,所以只能叫做最大似然估计。
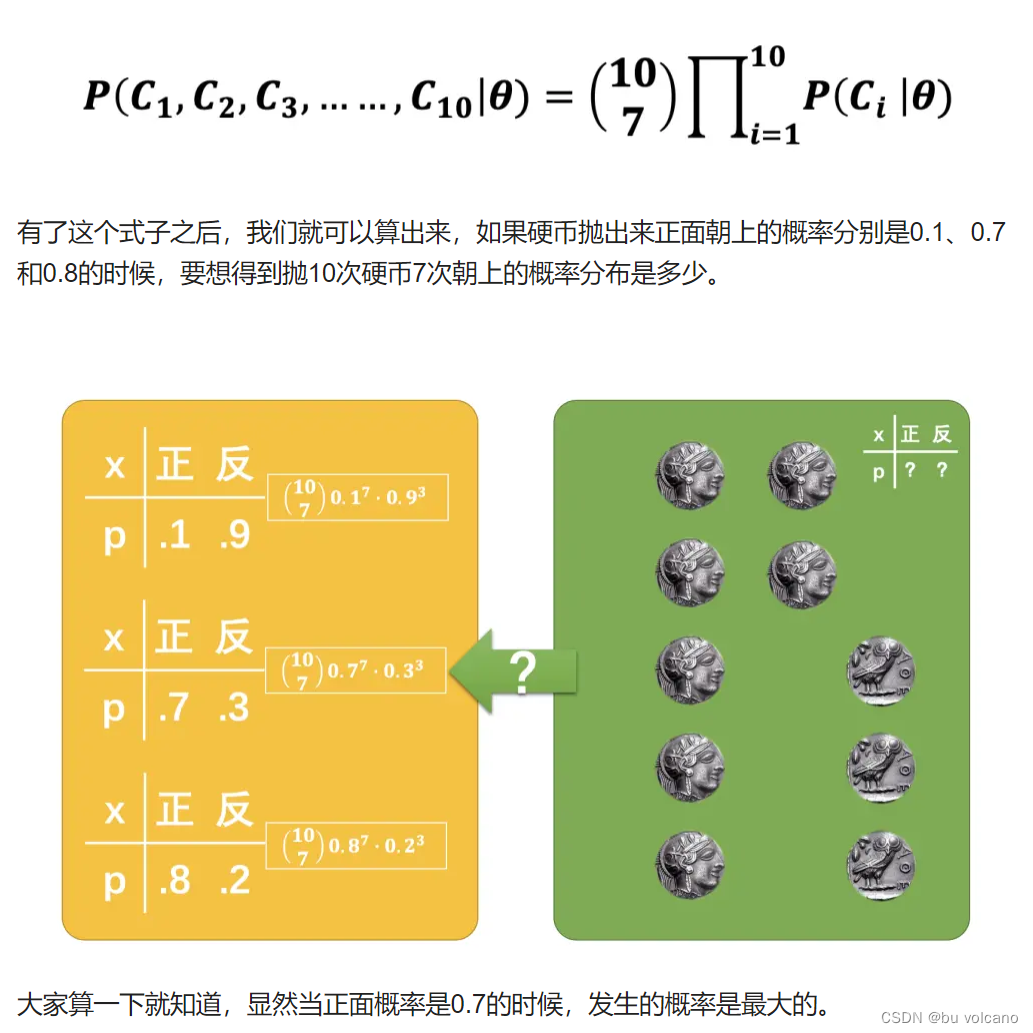
我们先来看一下前面的跑硬币的例子。在这个例子里面,我们已经知道了抛硬币的结果,求原本的硬币概率是多少。如果把抛硬币的例子和神经网络对应起来的话,抛硬币的结果对应的就是已经有的数据集<xi,yi>,求硬币的概率θ对应到神经网络里面就是求所有的参数W,b。

(在求最大值的时候灰色部分是可以忽略的。特别是P(xi),这是因为我们默认数据集是优质的数据集,数据集里的图片都是相互独立的,而且应该是等概率的。如果这部分有问题,那就需要重新整理数据集,让数据集尽可能满足这个条件。 )

折页损失函数:
惩罚–>与正确分类得分相差值小于△的一项
对于相同得分的两套权重,采用奥卡姆剃刀原理(如无必要,勿增实体),选择相对较简单的一套权重。
交叉熵误差:
【2023.06.11】
要想比较两种不同类型的分布就需要引入熵的概念。
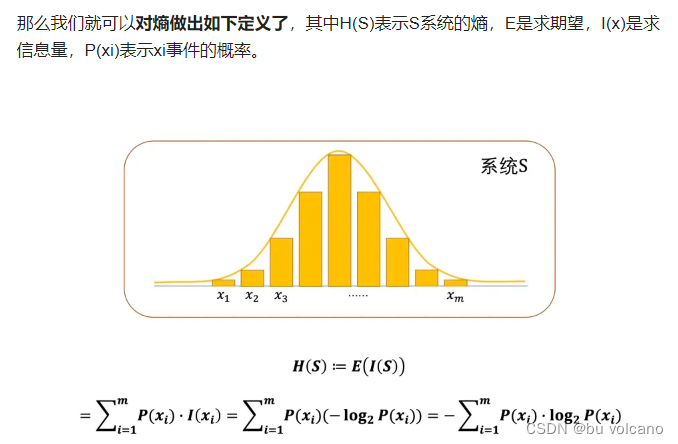
(1)熵=信息量。
是一个系统里面的混乱程度,本质上熵是信息量的期望。越有可能发生的事情,概率越大,信息量越小,熵值越小。
熵函数被定义为f(x):=-log(x)
其中x是概率
-号是因为log是单调递增函数,概率越大,熵值应该越小,所以会有负号
log是因为这是一个定义,为了使得相乘变成相加 系统能够自洽;这里的log是被定义的,本身意义不用管,但是正因为有了log整个系统才会自洽;这里的底数选择的是2,计算出单位就是比特了。
(2)整个系统的熵:因为事情发生的可能越低熵越高,如果事件没发生,那就是没有贡献啊,就不能放在系统的总和里面。所以一个事件贡献了多少信息量,就可以理解成信息量乘上对应事件发生的概率。 那么整个系统的熵就是把单个事件的信息量贡献相加。熵就是所有事件对应的信息量的加权和,那这个加权和是什么?就是这个系统里面信息量的期望值。
【10.25】
香农熵(也是熵也是信息熵):香农熵就是代表了事件发生的不确定性,不确定性越大,香农熵越大,不确定性越小,香农熵越小。
熵:=整个系统的各项概率乘以对应的熵相加,公式为: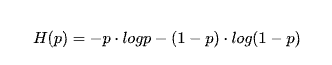
现在我们已经知道熵到底是什么了。我们最开始的目的是什么?是比较两个概率分布,一个表示真实的规律,一个表示机器学习猜测的规律,看看两个概率分布它们相差有多少。
现在有了熵,我们是不是就可以直接比较两个概率分布的差距了呢?把两个概率分布的熵都算出来,然后看看相差多少。
哪有这么简单,别忘了,真实规律我们是不知道的,既然不知道,那它的熵还怎么求呢?没有办法。
那么有没有什么方法,即便不知道一个概率分布的熵具体是多少,也能知道两个概率分布之间的差距是多少呢?
有!这就是KL散度和交叉熵了。
(2)KL散度(相对熵)
相对熵是非负的,它的大小可以用来衡量两个分布之间的差异,KL散度就不是粗暴的比较一个总体的熵了,而是比较得更细致,每一个事件xi对应的信息量,都会拿来进行比较。如果每一个事件的信息量都是相同的,那么两个概率分布肯定就是相同的了。
于是KL散度就可以做出如下定义:

当且仅当S和O具有完全相同的分布时,相对熵取值为0。
表示两个概率分布的距离,值越小,分布越近。
可以通过最小化相对熵来用分布Q逼近分布P(目标概率分布)
(log除变减–>右边是确定的香农熵+左边交叉熵–>最优化交叉熵可得到最小的损失)
(3)交叉熵:
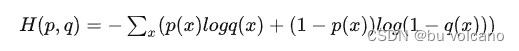
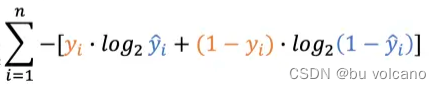
神经网络应用:
假设我们需要对数字1,2,3进行分类,它们的label依次为:
[1,0,0], [0,1,0], [0,0,1]
当输入的图像为数字1时,它的输出和label为:
[0.3,0.4,0.3] , [1,0,0]
接下来我们就可以利用交叉熵计算网络的损失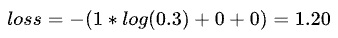
随着训练次数的增加,模型的参数得到优化,这时的输出变为:[0.8,0.1,0.1]
则 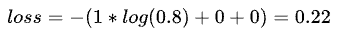
可以发现loss由1.20减小为0.22,而判断输入图像为数字1的概率由原本的0.3增加为0.8,说明训练得到的概率分布越来越接近真实的分布,这样就大大的提高了预测的准确性。
【10.26】
正则化:
在我们使得经验风险最小化的过程中,会使得模型变得特别复杂,也就产生了过拟合。
为了防止模型过拟合,用一个正则化来惩罚拟合曲线的高次项,这时将经验风险最小化变成了求得结构风险最小化。
凡是可以减少过拟合的都叫正则化,正则化有约束W和网络的dropout。
通过正则项来规定限制w的解空间只能从L1正方形和L2圆形约束中寻找。
1正则化:
具有稀疏性,可以使得很多参数为0,这也是一个特征选择的过程。
求解时,正方形与解空间的交点大概率出现在顶点,而二维顶点时w1,w2至少其中一个为0。
L2正则化:
求解时,圆形与解空间的交点大概率出现在圆弧上,而圆弧一般不为0。
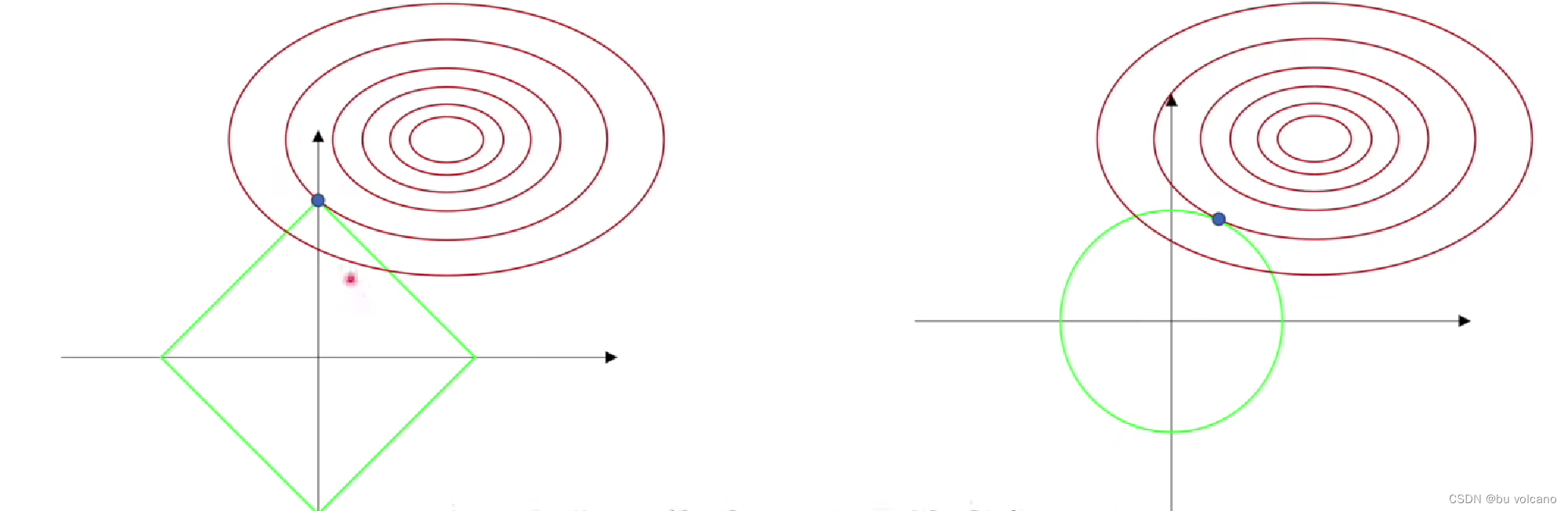
理解:
1.拉格朗日乘数法理解
在训练网络求解网络最小值的过程中,相同结果下会得到不同的a*倍w值;在预测时如果w过大的话会使得结果产生偏差,因此我们在训练过程中需要人为的通过拉格朗日乘数法给w划定一个可行域。
2.从权重衰减理解

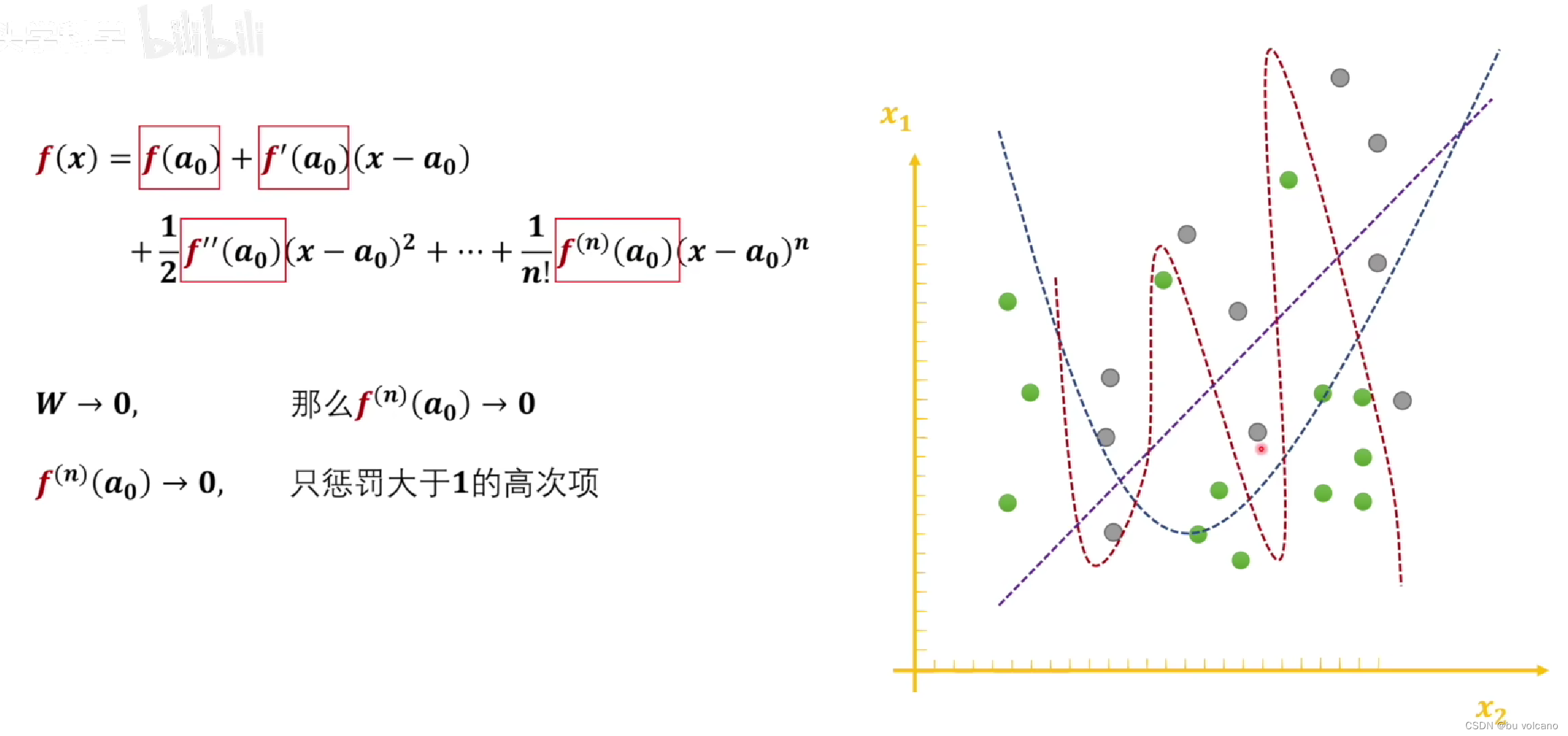
神经网络拟合出来的函数是f(x)可以通过泰勒展开,通过让w越来越小高次项会越来越小,所以惩罚了高次项从而让曲线没有那么多弯弯绕绕。
激活函数【11.4】
【2023.6.13】
激活函数的发展经历了Sigmoid -> Tanh -> ReLU -> Leaky ReLU -> Maxout这样的过程,还有一个特殊的激活函数Softmax,因为它只会被用在网络中的最后一层,用来进行最后的分类和归一化。
1、采用sigmoid等函数,指数运算,计算量大;
反向传播求误差梯度时,求导涉及除法和指数运算,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。
Sigmoid函数饱和使梯度消失。当神经元的激活在接近0或1处时会饱和,在这些区域梯度几乎为0,这就会导致梯度消失,几乎就有没有信号通过神经传回上一层。
2、对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度消失的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失。),这种现象称为饱和,从而无法完成深层网络的训练。
而ReLU就不会有饱和倾向,不会有特别小的梯度出现。
死区:放入一个小砝码在秤上,显示器没有动作,说明这个砝码在秤的死区
饱和:输入到达一定程度后变化不太明显
sigmiod存在输入为非零中心,并且使用了 s 形结构,因此,所有的梯度更新要么全部为正,要么全部为负,使得权重向同一个方向移动这导致梯度更新呈现“之字形”路径,这比直接遵循最佳方向的更新效率低:
relu存在死区问题可以通过变体解决
【11.15】
卷积过程中有多少卷积核就有多少特征图,也就是通道数
正是因为池化操作使得卷积神经网络拥有平移不变性
权值共享是每个卷积核共享
底层卷积核关注 边缘 颜色 亮度
中层卷积核关注 形状
高层卷积核关注 眼睛 头发特征
如果步长为1使输入输出长宽不变 有P = F-1 /2
多少个1*1卷积核代表着生成多少通道,每一层都需要非线性的激活可以提高非线性表示能力
梯度下降
优化:
随机方法:类似于羊驼投资法,随机猜
梯度下降法:求得损失函数对于原始数据的每一个权重的梯度,按照反方向乘以学习率更新权重使得损失函数下降
①数值梯度解法:给每个权重加上一个小值,求得每个权重的梯度(是近似解)。
②解析解:牛顿莱布尼茨
分类:
全梯度下降
随机梯度下降
小批量梯度下降
深度学习使得人工特征工程得以解放
【11.1】反向传播:
利用链式法则先求出后面部分的局部梯度,然后相乘可以的得到关于输入的全局梯度
+分支 平分局部梯度
*分支 交换局部梯度
前向传播为了求损失
反向传播求梯度
隐藏层是为了把非线性的数据处理成线性的,然后使用线性层去分类
几个神经元就相当于几条线性边界和做了几次非线性变换
最少使用3个神经元
relu的边界为明显的直线,不是圆滑曲线
梯度下降优化
【2023.06.10】
梯度下降(Gradient Descent GD)简单来说就是一种寻找目标函数最小化的方法,它利用梯度信息,通过不断迭代调整参数来寻找合适的目标值。
https://zhuanlan.zhihu.com/p/113714840
【2021.11.18】
随机梯度下降SGD:也就是mini-batch 使用一小批次数据更新损失
具体做法是在梯度较大的方向发生震荡,不能通过单纯减小学习率解决
容易陷入局部最优点和鞍点
SGD+Momentum:相当于大胖子下山,带有动量,考虑到之前的下降方向
改进的Nesterov Momentum :假设按照之前梯度下降方向更新后看是否梯度平缓
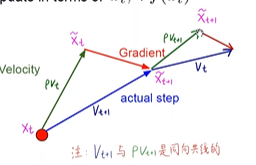
AdaGrad:
SGD在梯度较大的方向出现了问题,所以给它加一个除以根号下累加的dxdx惩罚项
RMSProp:
把累加的dxdx加上衰减因子,在累加较多时快于AdaGrad收敛
Adam:
引入第一和第二动量
(2)谷歌李沐动手学深度学习
【7.20.21.】1-16节V2版本 基本上都没听懂
【11.4】dropout
将一些隐藏层的输出项随机变成0来控制模型的复杂度
越往后比率越小
【11.5】lenet vgg
【11.7】googlenet
【11.8】
批量归一化
作用在激活函数前,通过在每个小批量里面加入噪音控制模型复杂度,没必要和droupout混合使用,会加速模型收敛但是 不会改变模型精度
resnet
在输入的地方引入使用捷径,在输出的地方相加。如果通道数不同时可以通过1*1卷积改变通道。
【11.9】
1.所有类型的resnet卷积操作的通道数(无论是输入通道还是输出通道)都是64的倍数,起始通道数都是64,128,256,512,暂且称它为“基准 通道数”
2.所有类型的resnet的卷积核只有3x3和1x1两种
3.无论哪一种resnet,除了公共部分(conv1)外,都是由4大块组成(con2_x,con3_x,con4_x,con5_x,)
4.经过conv1时输入图片就已经被缩小了4倍了(一个卷积和一个最大池化操作各1/2)。除了conv2不会缩小图片外,其余三个conv都会缩小一半图片,同时增加输出通道的同时,
4.最后一个avgpooling把图片变成1×1的。
【12.13】
Resnet的出发点是认为深层网络不应该比浅层网络性能差,所以为了防止网络退化,引入了大量identity恒等映射,这样就可以把原始信息流入更深的层,抑制了信息的退化
残差块有用是因为identity这一支路的导数是1,所以可以把深层的loss很好的保留传递给浅层,因为神经网络一个很大的问题就是梯度链式法则带来的梯度弥散
残差块就是一个差分放大器
【11.10】
GPU比CPU核多上千倍,达到2k-4k个,这是最根本上的区别
单机多个GPU数据并行计算方法:
①把参数复制放在不同GPU data parallel
②把比较大的模型的不同块放在不同的GPU model parallel
distributed data parallel 分布式数据并行计算
步骤:
①scatter: 把数据分发到GPU
②replicate:复制模型到每个显卡
③gather:把各GPU结果汇合到主GPU
【11.12】
多GPU训练有可能速度会更慢,是因为服务器显卡有别人在使用,速度快的要等速度慢的计算完毕
数据增强;
上下随机翻转取决于数据集的样子,树叶可以,猫不可以
色调是黄一点还是蓝一点
饱和度是颜色浓度
明亮度是亮度
使用条件:假如部署的时候和实验的时候没什么相差可以不使用
遇到极度偏斜数据时可以使用数据增强 或者重采样
【11.13】迁移学习
两者使用一样得网络
①因为原来数据集更加复杂,所以使用更强的正则化
使用更小的学习率,更少的数据迭代
②因为底层的特征提取更加细节,高层感受野更大提取的更加语义
所以固定底层的一些参数,使得模型复杂度低一些
【11.14】目标检测
边缘框:表示物体真实的位置
锚框:表示算法对物体边缘框的预测
①做出多个预测
②预测每个锚框是否包含所关注的物体
③如果是,预测锚框到真实边框的偏移
iou交并比:
用来计算两框之间的相似度
jaccard 指数 = 相交/相并 0表示不相似(相交为0)
—1表示完全相似(相交,相并都为1)
NMS非极大值抑制输出:去掉预测中分值比较小的
【11.15】
Rol兴趣区域池化层:把锚框当做一个图片,给定输出mn,总能得到mn均分下的最大值
R-CNN:区域卷积
Fast RCNN:不再对每一个锚框做CNN抽取
Faster RCNN:先进行糙一点预测然后再Fast RCNN
Mask RCNN:像素级别的标号,是在最高要求精度场景下使用(语义分割)
【11.16】SSD单发多框检测:不再具有RPN网络
YOLO:只看一次,将图片均分为ss个锚框,让相邻的锚框不再重叠,让计算更快速。
每一个锚框预测B个边缘框,因为有可能同时框住两个物体
【11.18】
语义分割:识别出每个像素是什么类别,背景虚化为应用
实例分割:分出每个像素属于那一个物体,如有狗类两只,分为dog1,dog2
转置卷积:用来增加输入高宽
全连接神经网络FCN:11卷积层(减少通道维度)+转置卷积(扩大图片)
样式迁移:将样式图片的样式迁移到内容图片上,得到和成图片
【11.19】
序列数据模型
自回归模型:给定前t-1个数据,对第t个数据进行预测
马尔科夫假设:假设当前数据只跟τ个过去数据相关,每次预测不需要使用过去全部数据
潜变量模型: 引入潜变量 ht来表示过去t-1个数据的信息,在预测第t时使用ht和过去t-1个数据,相当于建立了两个模型。

文本预处理:把每个句子拆成 词源token
每个token根据词汇表转换成索引,然后每一个句子是一个数字索引表
【11.20】RNN

输入‘你’时,得到h1,通过h1输出o1预测值‘好’,此时没有观察到输入x2‘好’这个字
RNN是共享的一套权重,它的梯度消失是指总梯度被近距离梯度遮挡
【11.23】GRU门控循环单元
更新门update gate:能关注的机制Zt
重置门reset gate:能遗忘的机制Rt
候选隐状态:

Rt是0-1决定是否使用前一个隐状态,如果是0则说明前面隐藏状态信息全部不需要,回到初始状态;如果是1则相当于RNN把前面隐藏状态拿来使用,这一个Rt是自动学习的
Zt是否使用当前关于Ht的信息???

【11.25】LSTM
比RNN多了一个隐藏的记忆单元

由于无法保证Ct在-1到+1之间,所以通过tanh使得Ct在-1到+1之间

Encoder Decoder
编码器:将输入编程成中间表达形式(特征)
解码器:将中间表示解码成输出,抽象后也可以有一个额外的输出
缺点:定长编码是信息瓶颈
长度越长,前面输入进RNN的信息就越被稀释

束搜索
在seq2seq中将通过贪心当前预测最大值输出到下一个序列
但是贪心搜索不一定是最优的
在第二步的时候,因为不选择最大值0.4导致(世界线收束)产生的第三步值不一样,最终右边的结果要好于贪心搜索

而束搜索是保存最好的K个候选

注意力机制
卷积、全连接、池化层都是不跟随意志考虑线索的(一块一块瞎看)
注意力机制就是显式的考虑线索,有偏向性的选择某些输入
举例:我要从外界环境中找到咖啡杯来喝咖啡
query就是我想要喝咖啡这件事
key是外界环境中的报纸,咖啡杯等
value是报纸,咖啡杯对应的值
过程:根据query选择一对key,value
背景 :
①非参数(不需要学参数)注意力池化层??未完全理解
给定数据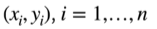
对数据做平均池化是最简单的方案,不管查询,直接对y求平均
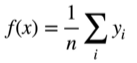
更好的方案是60年代提出来的Nadaraya-Watson核回归
给定一个query后,对所有候选的Xi(key)相减做一个K(核函数:衡量X与Xi距离的一个函数,可以是高斯核),然后除和得到一个概率,这样就拿到每一个Xi的相对重要性,之后再加权对Yi求和取出相近的Yi

②在此基础上引入可以学习的w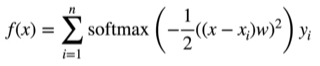
一般可以写作,α(x,y)是注意力权重,≥0的
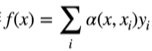

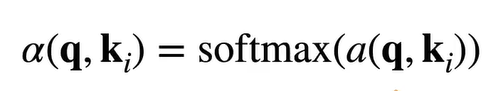
为此我们需要设计a注意力分数,有以下思路:
①可加的注意力分数计算
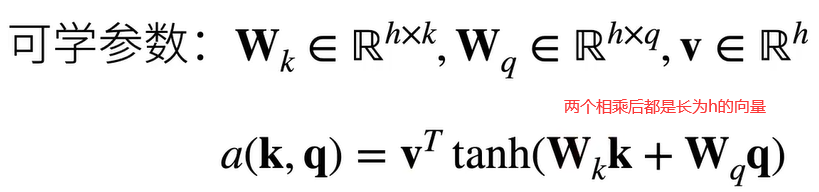
等价于将query和value合并起来后放入到一个隐藏少小为h输出大小为1的单隐藏层MLP,优点是Q,K,V可以是任意长度
②点积注意力分数计算
要求q,k,v是同一长度
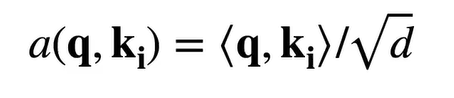 【11.27】
【11.27】
在seq2seq时仅将编码的最后一个隐藏状态传入解码之中

而加入注意力机制后,解码时不仅需要之前编码时的输出,还要将上一个解码输出值embedding后加入进去

也就是说编码器对每次词的输出作为key和value
解码器对上一个次的预测是query

自注意力机制就是将Xi当做k,v,q来对序列抽取特征,完全并行,最长序列为1,最长路径是O(1),可以无视距离,计算复杂度高
Transformer
左边n个encoder,右边n个decoder都是自己定义的个数

(3)深度学习入门-b站致敬大神
①up主也是从零刚开始入门
②东北人特别幽默
③具有特别的思考和自言自语 反正能够使我醍醐灌顶
【7.22】感知机:就相当于接收多个输入信号后合并信号
信号流动代表1
二分类感知机不能解决异或问题所以产生了人工智能寒冬
①对同心圆的异或数据做坐标轴转换成极坐标轴可以实现线性分类

②含有隐藏层的神经网络就可以实现异或
(首先进行与非和或运算然后将结果进行与运算)
激活函数:就是判断流程是1还是0,1代表流动
激活函数非线性要求的原因:因为若是线性每一层神经元的乘积相加就可以合并,也就是层数塌陷了
【7.23】
回归问题用恒等函数
二分类用sigmoid
sigmoid(饱和):可以将(-无穷,+正无穷)的值压缩到0-1之间
多分类用softmax
softmax:它的输出相当于概率
tanh双曲正切:输出是-1到1之间
relu:负值梯度为0;变体leaky relu负值乘以0.1
监督数据:概率最大的设置为1其余的 设置为0,这就是one-hot
激活函数:就是将xw得数非线性化,不非线性化多层和单层无异。
均方误差:将输出的概率减去监督数据,输出的概率最大的一项(如0.9)如果为正确项的监督数据(为1)则两者差值非常小–>也就说明均方误差总值越小,输出结果越正确
交叉熵:监督数据×ln输出概率 只有正确项监督数据为1,其余为0,也就是说只计算正确项数值 ln是在(0,1)上越接近1,越靠近0–>也就说明交叉熵越小,输出结果越正确
【7.24】梯度:是在某一点偏导值得集合,代表着函数值减小最多的方向 。
【7.25】两层神经网络的实现
【7.27】反向传播算法 基于链式求导法则,也就是将各节点偏导数相乘
通过加法点不变,通过乘法点颠倒相乘。
【8.2】优化方法:
SGD随机梯度下降 之字型向最低点前进,会存在效率慢的问题
Momentum动量下降法 小球在斜坡滚动下降,之字形会减弱,但会在最低点来回重复
Nestero梯度加速法 小球中坐了一个驾驶员,下降到最低点时会抑制上坡
AdaGrad适用学习率下降法 越靠近最低点时学习率越小
【8.3】Adam结合Momentum和AdaGrad
Nadam是结合了Adam和Nestero
(4)莫烦pytorch
【7.25】p1-p20 pytorch基本语法
(5)小土堆pytorch
【7.26】用pytorch实现CNN套路
看pytorch深度学习入门与实战完成fashion-mnist数据集cnn
【8.4】transforms工具
ToTensor
【9.1】pytorch RNN
(6)pytorch
【9.20】RNN
【9.22】数据集准备
【9.27】RNN结构搭建
【10.3】RNN训练
(7)李宏毅深度学习
【7.31】神经网络第一课
【8.1】理解了CNN的卷积池化操作原理,权值共享
【8.9】
卷积公式:新=(旧-卷积核大小+2填充)/步长+1
池化公式:新=(旧-卷积核大小+2填充)/步长+1
【8.13】RNN 概念
LSTM概念
【8.21】RNN结束
【8.22】半监督学习
【9.19】无监督学习
【10.21】注意力机制
因为计算资源有限,所需要从众多信息中选择对当前更有用的信息,有利于并行计算;解决RNN遗忘的问题
区别:
①传统聚类将样本进行分类
注意力机制将特征进行分类
②CNN是self-attention的特例
③RNN的遗忘问题,self-attention有天涯若比邻的特性
RNN只能一次吐一个输出,但是self-attention可以并行吐出一列输出
④Tom chase Jerry -->‘’汤姆‘’‘’追逐‘’‘’杰瑞‘’
在生成杰瑞时tom chase jerry 对其贡献都是一样的,这是分心模型,是不合理的
self-attention可以有权重的生成杰瑞,联系上下文有语境
【10.29】步骤:
①key为输入tom;Query为汤姆
计算两者相关性——>方法有点积(dot product:用于计算两个向量的关系,加入没有关系内积为0,在空间上表示垂直),余弦相似度
②对1步骤的得分进行softmax归一化得到权重系数
③用权重系数Value然后求和得到attention value
以上三个步骤中的q k v矩阵可以拼起来并行计算
【11.16】狗中赤兔
attention是一种思想,不依赖特定的框架
以阅读理解为例,Q是问题(查询 去匹配),K(索引 被匹配)、V(内容)是原始文本,通过计算与K的相关性找到原文中最重要的部分,通过V得到答案
以渣男从备胎中找对象为例,Q来表示他的期望,,渣男选备胎的同时。备胎也是要看他的条件的,我们就用K来表示他自身条件。被匹配到的备胎是V。无论是渣男还是备脂,都有自己的一套Q、K、V(输入X乘以三个权重矩阵)。
渣男要寻找自己的Q和备胎的K相关性最高的,运用点积的方法。
然后softmax(QK^T/√dk代表K的维度)保持梯度的稳定
多头注意力机制:使用多种变换的生成的Q,K,V进行运算,将相关性结论结合起来,增强自注意力的效果
【11.28】瓜波牛排
在神经网络中引入注意力机制有很多方法,以卷积神经网络为例,可以在空间维度增加引入attention机制(如inception网络的多尺度,让并联的卷积层有不同的权重),也可以在通道维度(channel)增加attention机制,当然也有混合维度即同时在空间维度和通道维度增加attention机制。
2017SE-net就是一个通道上的应用,这篇论文就是通道维度(channel-wise)增加注意力机制,关键的两个操作是squeeze和excitation,所以论文把这个attention结构命名为SE block,SE block是为了显式地实现特征通道的的相互依赖关系,就是说就是通过自动学习的方式(用另外一个新的神经网络实现)获取到每个特征通道的重要程度,然后用这个重要程度去给每一个特征通道赋予一个权重值,从而让神经网络重点关注某些特征通道,即提升对当前任务有用的特征通道并抑制对当前任务用处不大的特征通道。
步骤:
①在第一个卷积后先Squeeze,具体是使用全局平均池化(可以拥有全局视野)压缩成一维
②然后通过excitation,具体是通过Botleneck(两个全连接层)转换为同样数目的权重
③之后再Scale,具体是将权重加权到前面的每个通道的特征上

【11.29】爱123哈哈
encoder的每一个输出和decoder的每一个隐藏状态
EO: encoder各个位置的输出
H: decoder某一步的隐含状态
FC:全连接层
X: decoder的一个输入
score = FC(tanh(FC(EO) +FC(H))) [Bahdanau注意力]得到与EO一样维度输出
另一选项: score = EOWH [luong注意力]
attention_weights = softmax(score, axis = 1)
context = sum(attention_weights * EO, axis = 1)
final_input = concat(context, embed(x))

【11.30】NLP从入门到放弃
transformer中encoder

1.输入由两部分组成①embedding和②位置编码
①embedding是每一个字进行编码

②位置编码
多头并行处理时忽略了位置信息
通过公式对每一个字的向量加上位置数值
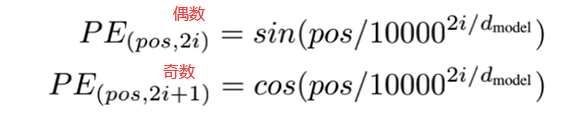

 attention
attention

残差和LayerNorm
将位置编码后的X与self-attention后得到的Z相加,以保证往后得到的结果不比原来差

为什么不使用BN
①因为BN在batchsize小的时候均值和方差代表不了整体,效果很差
②RNN输入的单词是动态的,每个单词的长度不同,不能有效的得到batchsize的均值和方差
比如前九个样本单词数量是5,最后一个样本单词数量为20
BN是针对一个单词去做缩放,在其他情况中代表体重,身高做缩放,不能够迁移过来
LN是针对一个样本的单词做缩放,对这一句话的语义信息做均值方差

transformer中Decoder

1.mask就是对当前输入单词之后的单词抹掉

2.交互层 encoder的输出和decoder的每一层去做交互

encoder输出的是K,V矩阵,和decoder的每一层的Q矩阵去做交互

【12.1】
transformer应用;
1.机器翻译类应用-Encoder和Decoder共同使用
2.只使用Encoder端-文本分类BERT和图片分类VIT
3.只使用Decoder端-生成类模型
Teachferfocing:因为在解码端输入需要根据上一个输出,所以不能并行,为解决这一问题我们在训练时把真实标签作为输入从而达到并行训练的效果
【12.3】Vision Transformer
在nlp任务中文字embdding成tocken后送入encoder

类比到图像中,对图像划分成patch

1.图片切分为patch(9个1616)
2. patch转化为embedding
①先拉平patch为1维(9个256)
②在将这个1维长度映射到embdding的长度(9个768),对应粉色框框,有两种实现方式:其一用线形层,其二用768个11卷积
3.位置embedding和tokens embedding相加
①先生成Classification的token embedding,对应粉色CLS※
这个符号出现在bert中,不是必须加的
②再生成所有序列的位置编码,对应紫色的0 1 2····
③然后tonken+position,对应粉色框+紫色框
4.输入到TRM模型
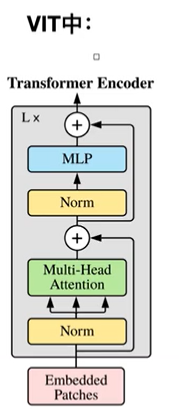
两点不同:①Norm提前了
②没有pad操作
5.把第一个CLS输出做多分类任务

【12.13】SwinTRM
创新点:①在encoder中做了厚处理,降低分辨率增加了感受野
②把注意力机制放在了窗口中

(8)王木头深度学习
【11.18】
加快神经网络的训练速度有两个思路
减少数据量
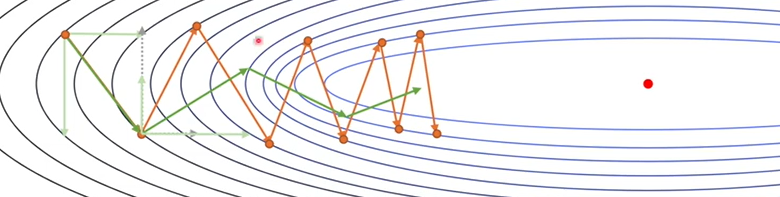
优化下降路径:
由于计算机算梯度时是有步长的,所以给优化带来了可能性

减少学习步长是不能达到效果的,因为学习率的减少意味着增加学习次数,带来了更大的计算量
①把梯度分成不同的分量去考虑
当前这一步需要更新的,去考虑上一步情况,假如考虑的次数较多的话使用指数加权移动平均法
(9)唐宇迪深度学习
【10.31】残差连接
保证模型训练至少不比原来差
将输入x分成两份,一份经过网络模型处理,一份不经过网络模型处理。让模型自己判断哪一种情况loss最小。
Decpder:
加入了mask机制,把将要输入的self=attetion的后面的给遮挡掉
【11.2】迁移学习
使用公认的训练好的网络模型和权重参数进行work
(10)霹雳吧啦
【11.23】
RNN两个问题:遗忘问题和h的隐藏状态只能一个一个计算
Transform解决以上两个问题
步骤:
①输入x做Embedding转成高维向量a
②a分别与Wq,Wk,Wv(是共享的权重)相乘得到q k v

③将q 与k进行匹配(点积计算相关性)得到α 分数
④α经过soft-max得到每一个v上的权重,越大越关注相应的v

⑤将得到的α_hat与v相乘得到b

Multi-head Self-Attention
优点是优点:
①扩展了模型专注于不同位置的能力。
②给出了注意力层的多个“表示子空间”。
两个头的情况下(也就是两套权重矩阵)
①在self-attention的第三步将q,k,v根据头数均分为2

②将第二个标号为1的q,k,v归于head1,实现均分

③对于每一个头的q,k,v做self-attention操作

④将得到的b第一个标号相同的进行拼接

⑤将b拼接乘以Wo(保持输入输出维度不变)

之后需要主动在输入时加上位置编码信息
在解码器中还要加上mask,来遮挡住预测当前值之后的值
【12.11】Swin-Transformer
与Vit的区别:
1.引入CNN中常用的层次化构建方式构建层次化Transformer (4倍下采样,8倍下采样,16倍下采样)
2.引入locality思想,对无重合的window区域内进行self-attention计算,解决transformer迁移至CV上的scale和分辨率的问题。(对每一个patch进行了分割)

整个Swin Transformer架构,和CNN架构非常相似,构建了4个stage,每个stage中都是类似的重复单元。

1.和ViT类似,通过patch partition将输入图片HxWx3(下面图片代表一个patch的一个颜色通道)划分为不重合的patch集合,其中每个patch尺寸为4x4,那么每个patch的特征维度为4x4x3=48,patch块的数量为H/4 x W/4;
Swin Transformer和ViT划分patch的方式略有不同,ViT是先确定patch的数量,然后计算确定每个patch的尺寸,而Swin Transformer是先确定每个patch的大小,然后计算确定patch数量。这个设计猜测是为了方便Swin Transformer的层级构建。
stage1部分,先通过一个linear embedding将输划分后的patch特征维度变成C,然后送入Swin Transformer Block;

2.stage2-stage4操作相同,先通过一个patch merging,将输入按照2x2的相邻patches合并,这样子patch块的数量就变成了H/8 x W/8,特征维度就变成了4C,然后再将特征压缩到2C

3.两个连续的Swin Transformer Block。一个Swin Transformer Block由一个带两层MLP的shifted window based MSA组成。在每个MSA模块和每个MLP之前使用LayerNorm(LN)层,并在每个MSA和MLP之后使用残差连接。

3.1其中W-MSA是Windows Multi-head Self-Attention
是将oatch分成2*2的window 然后每个window中的像素进行self-attention,窗口之间不进行信息交互 这样做的目的可以减少计算量 缺点是感受野变小,没有全局的信息关注

3.2SW-MSA是Shifted Windows Multi-Head Self-Attention(swin缩写)
是在W-MSA层次基础上(在两个连续的Swin Transformer Block中交替使用W-MSA和SW-MSA)向下向右偏移的Windows,目的是为了实现不同window之间的信息交互,移动window的划分方式使上一层相邻的不重合window之间引入连接,大大的增加了感受野。

根据上图,可以发现通过将窗口进行偏移后,由原来的4个窗口变成9个窗口了。后面又要对每个窗口内部进行MSA,这样做感觉又变麻烦了。为了解决这个麻烦,作者又提出而了Efficient batch computation for shifted configuration。
具体的做法是将切分的小块相互拼接,组成与原patch相同的大小。

3.2.1其中第一步就是将上面第一列放在最下面,然后将左边第一列放在最右边

【12.20】混淆矩阵Confusion Matrix
混淆矩阵是评判模型结果的一种指标,属于模型评估的一部分,常用于评判分类器模型的优劣。
横坐标是真实标签,纵坐标是预测标签

【12.21】ROC曲线 Receiver OpERATOR Characteristic

(11)leo在这
【12.29】混淆矩阵
以二分类为例有以下四种情况:
预测正确与否 ; 预测为正(pssitive)为负(negative)
真实正 预测正 TP
真实正 预测负 FN
真实负 预测正 FP
真实负 预测负 TN

性能指标:
①正确率ACC

只看正确率会有
②精确率PPV也叫查准率
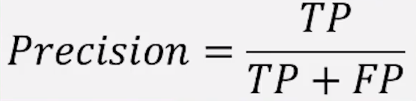
分母所有预测结果都是正,代表你做正例所有选项中正确的比例
③召回率(敏感度)也叫查全率
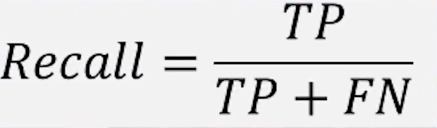
分母都是真实情况下的正例
④f1 score
为了比较模型间性能 可使用f1 score它可以综合考虑到查准率和查全率

f1 score越高模型性能越优秀
⑤假证利率 fpr
fpr表示错误的预测为正的数量 占 原本为负的数量的比例
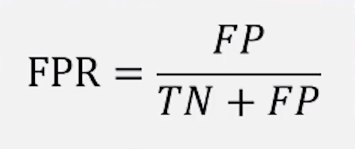
⑥真正利率tpr 也叫1-特异性
与召回率相同
tpr表示正确的预测为正的数量 占 原本正的数量的比例
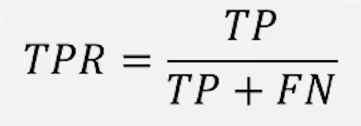
ROC曲线
全称为受试者工作特征曲线他来自于二战雷达信号分析
ROC曲线中横中坐标分别为fpr和tpr 它和pr曲线一样可反映模型分类能力
绘制步骤如下
1.所有样本按概率递减排序
原本类别:正预测概率:0.95
原本类别:正预测概率:0.86
原本类别:负预测概率:0.64
原本类别:正预测概率:0.40
原本类别:负预测概率:0.35
2.阈值从1到0变化计算各个阈值下的fpr和tpr

3.将数值绘制于直角坐标系中
举例:
假设有五个样本知道其原本类型以及模型预测出的概率结果


(9)作业
【11.2】今日学习到第一次搭建CNN时的疑惑;①带参数计算的算作一层②输出层算一层③激活层,池化层不算一层
【8.3】截止此,第一次小fashion_mnist作业完成。全程复习
【8.5】准备第二次UCI-HAR数据的作业
采集的是一维的时间序列的数据,怎么解决这个问题呢?
如何将数据转化成npy文件?
【8.6】csv是Comma-Separated Values的缩写,是用文本文件形式储存的表格数据
列表解析:
[x for x in range(5)] # [0, 1, 2, 3, 4]
l1 = [1,2,3,4]
[ x*2是表达式 for x in l1] #[2,4,6,8]
replace表示替代
strip()空参数表示默认删除开头和结尾空白符
split表示str字符串的分离,即通过单空格来进行数据的分离,相当于在Excel中的空格分隔方式。
np.transpose:交换0,1,2轴
np.asarray
将结构数据转化为ndarray。
get_dummies
是利用pandas实现one hot encode的方式
由于Pytorch默认图片数据格式为[n, c, h, w]、rgb,因此若数据集为[n, h, w, c]格式时需要进行转换:
【8.7.8】解决一般性报错
【8.9】以下函数的应用讲解在HAR_CNN中
print(np.array(a).shape)
TensorDataset()
summary()
transpose()
完成UCI_HAR_CNN作业
【8.10】训练网络时不一定是轮数越多越好,观察测试曲线,有可能提前出现精度最大值,然后过度训练导致过拟合。
【8.11】从txt导入数据绘制散点图
【8.12】了解WISDM数据集
【8.13】Read_csv()读取文件
python dropna()清洗数据,删除文件无效值
np.std()计算标准差 可以是某一列
归一化是使得预处理数据在一定的范围,消除奇异值影响
作用:加快训练网络的收敛性
【8.14】滑动窗口
序列数据中某一点的值因为间隔太小是瞬时值不能代表当时情况
因此我们需要根据固定的窗口大小选取数据包含这一点的区域,计算其平均值,使得数据更平稳一些
yield()暂停后面语句执行,将当前结果返回,然后继续执行下面语句;与return不同,执行完所有语句后返回最终值
生成器函数
生成器
迭代器
【8.15】hstack()、vstack()
将生成的x,y,z三轴数据横向合并
然后将滑动窗口纵向合并
【8.16】np.randm.rand(n)
返回n个正态分布中的值
np.randm.rand(n)<0.7 返回一组0.7比率的true
【8.18】round()四舍五入函数
【8.21】了解了滑窗,和怎么去滑窗
怎么去给滑窗的数据加上标签
怎么划分数据集和测试集
怎么去将string的标签转换成数字的标签进行训练
【9.3】准备第三次cifar作业,使用cnn,vgg,ResNet18
重写加载代码,修改卷积层网络参数,解决模型没有实例化报错
【9.4.5】学习vgg网络
是指vgg16,具有16层的深度学习网络
跑了5个epoch 精度86%
【9.6】因为vgg16笔记本跑起来已经吃力,学习云服务器训练
远程连接服务器,上传文件
【9.7】云上解压缩,运行py文件
【9.9】使用GPU训练
【9.10】云上screen操作
【9.19】准备第四次oppotunity数据集作业
整体浏览
【9.24】准备第五次作业
了解深度可分离卷积
将标准卷积分成深度卷积和逐点卷积
【9.27】Mobilenetv1代码实现
【9.28】Mobilenetv1跑Fashionmnist
【9.29】搭建深度三层可分离卷积神经网络
使用pycharm云训练CIFAR10
【10.10】准备第六次作业
【10.11】理解RNN
【10.10】使用LSTM
【10.19】训练LSTMa
【10.20】oppotunity是113通道传感器数据
【10.21】ConvLSTM
适用于时空序列问题 ,LSTM处理时间序列,CNN解决空间特征提取
九轴数据代表每个时间步有9个特征
[真挚感谢以上各位大佬,让我能够在深度学习的海洋里遨游]

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)