
语音识别(ASR)论文优选:WeNet之U2++
声明:平时看些文章做些笔记分享出来,文章中难免存在错误的地方,还望大家海涵。平时搜集一些资料,方便查阅学习:http://yqli.tech/page/speech.html。如转载,请标明出处。欢迎关注微信公众号:低调奋进以前阅读的是语音合成相关的代码,现在有机会做一些识别相关的工作,所以接下来也会整理识别相关的资料。U2++: Unified Two-pass BidirectionalEnd
声明:平时看些文章做些笔记分享出来,文章中难免存在错误的地方,还望大家海涵。平时搜集一些资料,方便查阅学习:http://yqli.tech/page/speech.html。如转载,请标明出处。欢迎关注微信公众号:低调奋进
以前阅读的是语音合成相关的代码,现在有机会做一些识别相关的工作,所以接下来也会整理识别相关的资料。
U2++: Unified Two-pass Bidirectional End-to-end Model for Speech Recognition
本文是出门问问联合西北工业大学在2021.06.10更新的文章,在统一streaming和non-streaming的u2基础提出u2++,使其错误率下降,具体文章链接https://arxiv.org/pdf/2106.05642.pdf
(关于u2和wenet可以参考我上一篇文章https://mp.weixin.qq.com/s/6_BIKrZ1I99NwITETiwISQ)
1 背景
端到端的ASR最近几年受到学术界和产业界的关注,诸如CTC, RNN-T,AED(attention based encoder-decoder)等等。上篇文章Wenet和U2提出了一种统一streaming和non-streaming模式的方案,使其一个模型可以支持streaming和non-streaming模式,本文在U2的基础上提出U2++,使其错误率更低。
2 具体设计
我们先回顾一下U2的设计。针对streaming 和non-streaming的U2模型即为CTC/AED的混合模型。具体的系统架构如图1所示,CTC和AED使用共同的encoder,为了实现streaming方式,encoder就要实现增量式来编码,即使用部分context来编码。我们先看一下图2展示的encoder可采用的关注context的方案,(a)full attention就是关注整句话语境,这种方式为non-streaming,效果当然很好;(b)的left attention即只关注过去,是streaming的方式,当然效果较差。(c)即为本文的提出的chunk attention,它关注本chunk以及过去的语境,及引入少量未来信息。另外我们需要分清该系统如何进行训练和推理。在训练系统时,每个batch随机在full attention和chunk attention之间进行选择,同时chunk size也随机选取,本方案即train by dynamic chunk size ,具体为公式2



以上为U2,那U2++的工作即添加了从右到左的attention decoder,具体如下图所示,相比于U2,U2++的attention存在L2R和R2L两个decoder,即Bi-directional Attention Decoder。该模型训练的loss为公式1和2,其中的超参选取大小由接下来的实验给出选择值。同时解码的score可参考公式3


另外本文优化了新的数据增广算法,可参考算法1.

3 实验
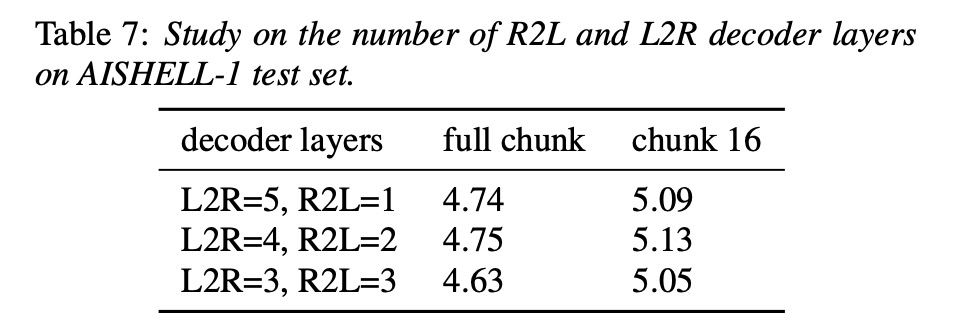
本文先在aishell-1进行试验,同时也对比使用transformer和conformer的结果。由table1显示无论ctc prefix beam search 和rescoring,u2++的cer低于u2。图2展示u2++的整体loss较低于u2。接下来在aishell-2的实验亦是如此,参考table3。table4展示本文的R2L和specSub对实验结果的影响。table 5展示了系统decoder层数和r2l l2R的效果。table 6展示了超参选取的效果。table 7展示r2l l2R层数的影响。





4 总结
U2提出了一种统一streaming和non-streaming模式的方案,使其一个模型可以支持streaming和non-streaming模式,本文在U2的基础上提出U2++,添加L2R和R2L两个attention decoder,使其错误率更低

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 2
2 0
0- 0



 已为社区贡献53条内容
已为社区贡献53条内容

所有评论(0)