
从零开始学人脸检测之Retinaface篇(内含魔改版GhostNet+mbv2)
前言Retinaface是Insightface团队在2019年提出的新人脸检测模型,该模型在 WiderFace 数据集上刷新了AP。源代码开源于insightface,原模型使用mxnet框架进行搭建,目前社区也有其他框架复现的版本,最让人熟知的莫过于pytorch版的retinaface。Retinaface是基于检测网络RetinaNet的改进版(没错,和centerface基于cente
从零开始学人脸检测之Retinaface篇(内含魔改版)

代码已开源,欢迎白嫖和star:
github.com/pengtougu/Retinaface_Ghost
一、论文解读
论文研读工作由Sansa大佬完成:
https://www.zhihu.com/people/0e4e23de534ba625a13b39a3153fa942
前言
Retinaface是Insightface团队在2019年提出的新人脸检测模型,该模型在 WiderFace 数据集上刷新了AP。源代码开源于insightface,原模型使用mxnet框架进行搭建,目前社区也有其他框架复现的版本,最让人熟知的莫过于pytorch版的retinaface。Retinaface是基于检测网络RetinaNet的改进版(没错,和centerface基于centernet类似),添加了SSH网络的三层级联检测模块,提升检测精度。作者提供了两种网络的复现版本(mobilenet and resnet),基于MobileNet的构建版旨在提供更加快速的检测,基于ResNet的构建版则更重于精度的指标。
摘要:
尽管在场景单一的人脸检测方面已经取得了巨大的进步,但在自然场景下对人脸进行准确有效的定位仍然是一个挑战。本文提出了一个强大的单阶人脸检测器,我们称之为RetinaFace,该检测器通过联合外监督(extra-supervised)和自监督(self-supervised)的多任务学习,对各种尺寸的人脸进行像素级别的定位。
具体来说,我们在以下五个方面做出了贡献。
(1) 在WIDER FACE数据集上手动标注了五个面部关键点,在外监督信号的辅助下获得了难人脸检测的显著提升。
(2)添加了一个自监督网格编码分支,用于预测一个逐像素的3D人脸信息,并使该分支与已存在的监督分支并行。
(3) 在WIDER FACE硬测试集上。RetinaFace比最先进的平均精度(AP)高出1.1%(达到AP等于91.4%,指ISRN)
(4) 在IJB-C测试集上,RetinaFace使当时最好的人脸特征提取模型ArcFace在人脸认证(face verification)的性能上进一步得到提升(TAR=89.59 FAR=1e-6)
(5) 采用轻量级的骨干网络,RetinaFace可以在单个CPU上实时运行。
介绍
与通用的目标检测方法不同的是,人脸检测的特征宽高比变化很小(1:1到1:1.5),但是尺度变化非常大(一张图包含多张人脸,从几个像素到几千个像素)。最近最好的方法关注于单级设计,在特征金字塔上进行密集的人脸位置和尺度采样,相比双级级联方法,这种设计获得了不错的性能和速度提升。依据这种路线,我们提升的单级人脸检测框架,并且通过利用强监督和自监督型号的多任务损失,提出了当前最好的密集人脸定位方法。思想如图:
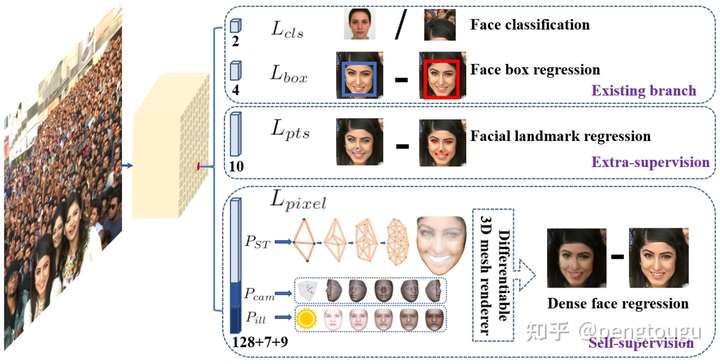
单级逐像素人脸定位方法利用外监督和自监督的多任务学习同时包含人脸框分类及回归分支。每个positive anchor输出:人脸得分,人脸框,5个人脸关键点,投射到平面上的3D人脸顶点
在Mask R-CNN【1】中,通过增加目标淹没的分支并与检测框识别和回归分支并行,检测性能显著提升。这证实了密集像素级别的标注对于提升检测性能也有用。然而,WIDER FACE中较难检测到的那部分人脸无法获取人脸标注信息。既然监督信号不易获取,那么问题就变成了我们是否可以利用无监督的方法进一步提升人脸检测呢。
FAN【2】提出一种anchor级别的注意力图来提升遮挡人脸检测,然而,提出的注意力图比较粗糙且不包含语义信息。最近,自监督3D形变模型获得了在自然场景下效果不错的的3D人脸。特别的,Mesh Decoder【3】利用在形状和纹理上的图卷积获得了超实时的速度,然而,将mesh decoder应用到单级检测器上的最大挑战是:(1)相机参数很难准确估计(2)联合潜在形状和纹理估计是从一个简单的特征向量预测的(特征金字塔上的1x1卷积)而不是通过RoI池化特征,这样就存在特征漂移的风险。本文利用网络编码(mesh decoder),通过自监督学习来预测一个像素级3D人脸形状,与现有的监督分支并行。
总之,论文提出了几个主要贡献:
- 基于单级设计,提出一个新的像素级人脸定位方法RetinaFace,利用多任务学习策略同时预测人脸评分,人脸框,5个关键点以及对应于每个人脸像素的3D位置。
- 在WIDER FACE数据的hard子集上,RetinaFace的AP=91.4%,比最好的两级级联方法ISRN【4】提升1.1%
- 在IJB-C测试集上,RetinaFace将ArcFace在人脸认证(face verification)上进一步提升(TAR=89.59%,FAR=1e-6),这表示更好的人脸定位可以显著提升人脸识别
- 通过利用轻量级的骨架网络,RetinaFace可以在单一CPU上对一张VGA分辨率的图像实时运行
| VGA | HD | 4K |
|---|---|---|
| 640×480 | 1920×1080 | 4096×2160 |
相关工作
图像金字塔vs特征金字塔: 滑动窗策略可以追溯到几十年前。里程碑式的工作是Viola-Jones提出级联来拒绝图像金字塔中的人脸误检并追求实时,引领尺度不变形人脸检测框架框架的广泛引用。尽管在图像金字塔上的滑动窗是主要的检测方式,随着特征金字塔的出现,在多个尺度特征图上的滑动anchor被快速应用于人脸检测。
双阶vs单阶: 当前人脸检测方法继承了一些通用检测方法的成果,主要分为两类:双阶方法如Faster RCNN和单阶方法如SSD和RetinaNet。两阶方法应用一个“proposal and refinement”机制提取高精度定位。而单阶方法密集采样人脸位置和尺度,导致训练过程中出现极度不平衡的正样本和负样本。为了处理这种不平衡,unsample和facal loss被广泛使用。相比双阶方法,单阶方法更高效并且有更高的召回率,但是有获取更高误报率的风险,影响定位精度。
上下文建模: 为了增强模型对小人脸的上下文推理能力,SSH和PyramidBox在特征金字塔上采用了上下文模块来增强欧几里得网格中获取的感受野。为了增强CNN的非严格变换模拟能力,形变卷积网络(DCN)利用一个新的形变层来模拟几何形变。WIDER Face挑战2018的冠军方案说明对于人脸检测来说,严格(扩大)和非严格(变形)上下文建模是互补并且正交。
多任务学习: 人脸检测和对齐的组合被广泛应用,这是因为对齐后的人脸可以为人脸分类提供更好的特征。在Mask R-CNN中,通过增加一个预测目标掩模的并行分支,检测性能得到显著提升。Densepose利用Mask-RCNN的架构,来获取每个选择区域的密集标签和位置。尽管如此,密集回归标签是通过监督学习训练的。此外,dense分支是一个很小的FCN网络,应用于每一个RoI上来预测像素到像素的密集映射。
RetinaFace原理
详见sansa大佬的博客,这里不展开细讲
https://zhuanlan.zhihu.com/p/103005911
实验部分
4.1 数据集
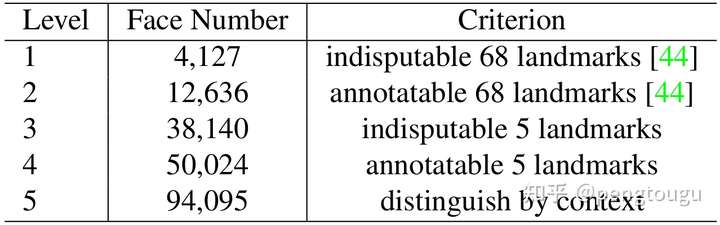
WIDER FACE数据集包含32,203个图像和393,703个人脸框,尺度, 姿态,表情,遮挡和光照变化都很大。WIDER FACE数据集被分为训练40% 验证10% 和测试50%三个子集,通过在61个场景分类中随机采样。基于EdgeBox的检测率,通过递增合并难样本,困难程度分为3级:容易,中性和困难。
额外标注: 如图4和表1,我们定义的5个人脸质量级别,依据人脸关键点标注困难程度并且标注5个关键点(眼睛中心,鼻尖,嘴角)。我们总共标注了84.6k个训练集人脸和18.5k个验证集人脸。

4.2 应用详情
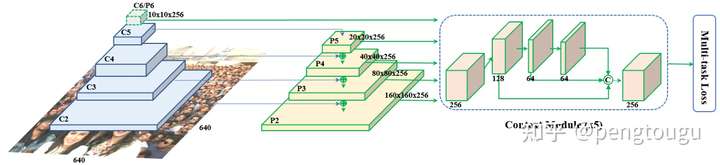
特征金字塔 RetinaFace应用特征金字塔从P2到P6,其中P2到P5是从Resnet残差级(C2到C5)计算而来。P6将C5通过一个3x3,s=2的卷积得到。C1到C5来自于在ImageNet-11k数据集上预训练的ResNet-152分类框架而P6通过Xavier随机初始化。
上下文模块 受启发于SSH和PyramidBox,我们也把独立上下文模块应用于5个特征金字塔上用于提高感受野和加强严格上下文建模能力。从WIDER Face Challenge 2018中总结经验,我们将所有侧连的3x3卷积层和上下文模块都替换为了DCN【6】,可以进一步加强非严格上下文建模能力
损失头(Loss Head) 对于所有的负样本anchors,仅仅使用了分类损失。对于正样本anchors,则计算多任务损失。我们在不同的特征图之间 H n ∗ W n ∗ 256 , n ∈ 2 , . . . , 6 H_{n}*W_{n}*256,n∈{2, . . . , 6} Hn∗Wn∗256,n∈2,...,6利用一个共享损失头(1x1卷积).对于网格编码,我们利用一个预训练模型【3】,计算开销很小。
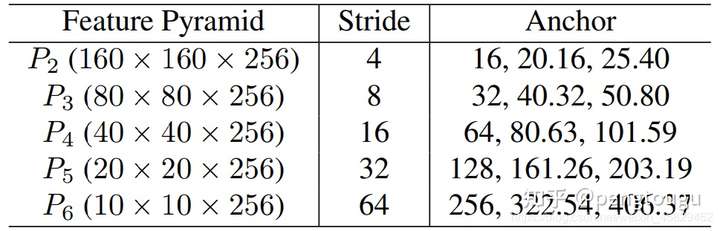
Anchor设置 如表2所示,在从P2到P6的特征金字塔上使用特定尺度anchor。P2用于抓取小脸,通过使用更小的anchor,当然,计算代价会变大同时误检会增多。设置尺度步长为 2 1 / 3 2^{1/3} 21/3(这里没懂,先做个标记), 宽高比1:1。输入图像640x640,anchor从16x16到406x406在特征金字塔上。总共有102,300个anchors,75%来自P2层。给大家解释一下这个102300怎么来的:(160160+8080+4040+2020+10)*3(SSH一共有三层)= 102300。
在训练阶段 ground-truth的IOU大于0.5的anchor被任务是正样本,小于0.3的anchor认为是背景。anchors中有>99%的都是负样本,使用标准OHEM避免正负样本的不均衡。通过loss值选择负样本,正负样本比例1:3
数据增强 WIDER FACE有20%的小脸,从原始图像随机crop 方形patch并缩放至640*640来生成更大的人脸。方形patch的截取规则为,随机选择[0.3,1]比例的原始图像短边长度。在crop边界上的人脸,保留中心在crop patch内的人脸框。除了随机crop,我们通过水平旋转一半的图像以及对称颜色的扰动。
训练细节 使用SGD优化器训练RetinaFace(momentum=0.9,weight decay = 0.0005,batchsize=8x4),Nvidia Tesla P40(24G) GPUs。起始学习率0.001,5个epoch后变为0.01,然后在第55和第68个epoch时除以10.
测试细节 在WIDER FACE上测试,利用了flip和多尺度(选定图像的短边,尺寸在【500,800,1100,1400,1700】之间)策略。使用IoU 阈值0.4,预测人脸框的集合使用投票策略。
4.3 消融实验
叠加了tricks的几个模型在WIDER FACE验证集上的AP和mAP如表格3所示。通过使用FPN、上下文信息、形变卷积等策略,得到了一个很好的baseline。通过增加5点分支,在hard子集样本上显著提升,说明5点对人脸检测的提升很明显。对比而言,密集回归分支提升了easy和medium子集人脸的检测,但是对hard子集人脸的提升不大。把5点分支和密集分支一起使用,性能依然有提升。
4.4 人脸框准确率
如图6所示,展示了密集人脸情况下的检出质量,在0.5以上的人脸检出900个,总共是1151人脸。除了人脸框准确之外,5点定位在不同的姿态遮挡分辨率下也都很鲁棒。尽管在严重遮挡的情况下密集人脸定位依然有失败的案例,但在一些清晰的大人脸上效果很好。

4.5 五点定位准确率
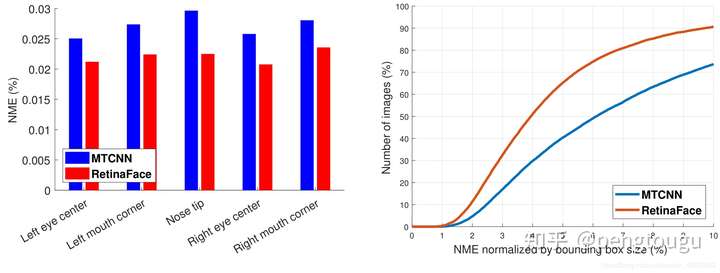
为了评价五点定位准确率,我们在AFLW数据集上(24386人脸)和WIDER FACE验证集(18.5k人脸)比较了MTCNN和RetinaFace。使用人脸框大小归一化距离。如图7a所示,给出在AFLW上每个点的平均误差。RetinaFace将归一化平均误差 NME从MTCNN的2.72%下降为2.21%。在图7b中,展示了在WIDER FACE 验证集上的累积误差分布CED。与MTCNN相比,在NME阈值为10%时的漏报率由26.31%降到9.37%。
4.7人脸识别准确率
本文展示了我们的人脸检测方法是如何提升Arcface人脸识别方法准确率的。本文分别比较了使用MTCNN和Retinaface来检测和对齐所有的训练数据(MS1M)以及测试数据(LFW,CFP-FP,AGEDB-30,IJBC),保留原Arcface中使用的Resnet100基础网络以及损失函数。比较解过如表4所示,基于CFP-FP,证明Retinaface可以提升Arcface的验证正确率从98.37%到99.49%。这个结果展示了正脸-侧脸的人脸认证已经达到了正脸-正脸的人脸认证水平。

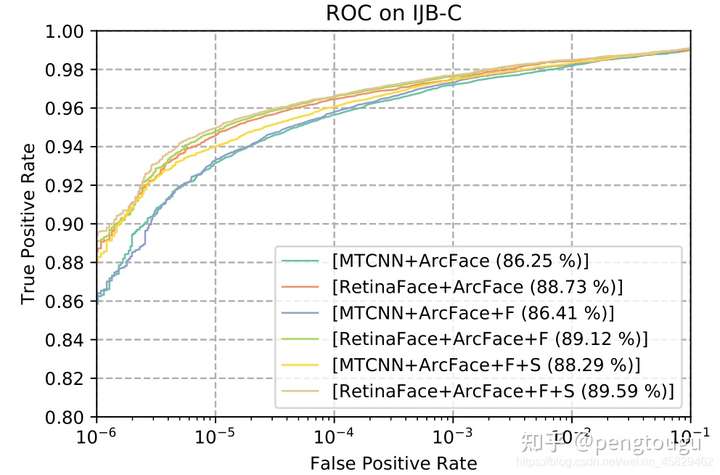
如图9所示展示了在FAR=1e-6时IJB-C数据中的ROC曲线。我们使用了两个tricks(镜像测试以及人脸检测评分去加权模板中的样本)来提升人脸认证准确率。使用retinaface代替mtcnn,TAR从88.29%提升到了89.59%。这表示(1)人脸检测和对齐对人脸识别影响很大(2)Retinaface相比MTCNN更加强大。
4.8 inference效率
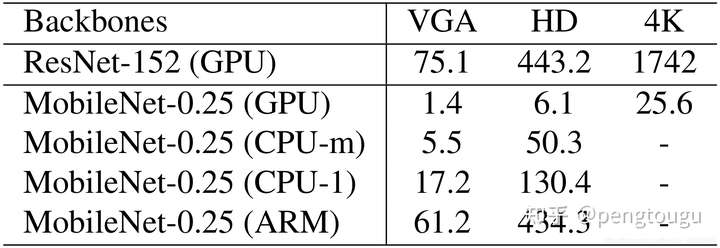
在测试时,retianface灵活而高效的进行人脸定位。除了权值较多的模型(ResNet-152,262M,AP=91.8%(hard)),我们也开发了一个轻量级的模型(MobileNet-0.25,1M,AP=78.2%(hard))来加速预测。
对于轻量级网络,我们可以通过一个步长为4,7x7的卷积,快速地减少数据大小,在P3,P4,P5后面添加密集anchors,并删除了形变层。此外,前两个卷积层使用imagenet预训练初始化后再训练时固定下来以获得更高的准确率。
表格5展示了不同输入尺寸下两个模型的耗时。其中,密集回归分支的时间没有统计进去。使用TVM来加速模型预测,测试平台为NVIDIA Tesla P40 GPU,Intel i7-6700k cpu和ARM-RK3399.
参考
【1】 K. He, G. Gkioxari, P. Dollar, and R. Girshick. Mask r-cnn. In ICCV, 2017.
【2】 J. Wang, Y. Yuan, and G. Yu. Face attention network: an effective face detector for the occluded faces. arXiv:1711.07246, 2017.
【3】 Y. Zhou, J. Deng, I. Kotsia, and S. Zafeiriou. Dense 3d face decoding over 2500fps: Joint texture and shape convolutional mesh decoders. In arxiv, 2019.
【4】 S. Zhang, R. Zhu, X. Wang, H. Shi, T. Fu, S. Wang, and T. Mei. Improved selective refinement network for face detection. arXiv:1901.06651, 2019.
【5】 VGA分辨率:图像大小640x480 // HD图像:1920x1080 // 4K图像:4096x2160
【6】 J. Dai, H. Qi, Y. Xiong, Y. Li, G. Zhang, H. Hu, and Y. Wei. Deformable convolutional networks. In ICCV, 2017
【7】 A. Shrivastava, A. Gupta, and R. Girshick. Training regionbased object detectors with online hard example mining. In CVPR, 2016.
二、pytorch_retinaface版本跑库测试
retinaface效果如何,只能通过对比实验才能得到验证。这里对pytorch_retinaface版本进行测试,该版本是社区所有版本中star最高的一版。
数据集准备
该地址包含干净的Wideface数据集:https://github.com/Linzaer/Ultra-Light-Fast-Generic-Face-Detector-1MB

下载后的数据集一共包含这三个:

此时的文件夹是只有图片的,然而作者要求的数据格式是:
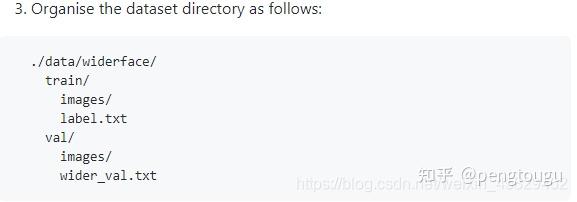
所以我们还少了数据的索引文件,这时候要使用作者提供的脚本wider_val.py,将图片信息导出成txt文件:
# -*- coding: UTF-8 -*-
'''
@author: mengting gu
@contact: 1065504814@qq.com
@time: 2020/11/2 上午11:47
@file: widerValFile.py
@desc:
'''
import os
import argparse
parser = argparse.ArgumentParser(description='Retinaface')
parser.add_argument('--dataset_folder', default=r'E:\pytorch\Retinaface\data\widerface\WIDER_val\images/', type=str, help='dataset path')
args = parser.parse_args()
if __name__ == '__main__':
# testing dataset
testset_folder = args.dataset_folder
testset_list = args.dataset_folder[:-7] + "label.txt"
with open(testset_list, 'r') as fr:
test_dataset = fr.read().split()
num_images = len(test_dataset)
for i, img_name in enumerate(test_dataset):
print("line i :{}".format(i))
if img_name.endswith('.jpg'):
print(" img_name :{}".format(img_name))
f = open(args.dataset_folder[:-7] + 'wider_val.txt', 'a')
f.write(img_name + '\n')
f.close()
导出后的完整格式如下:
每份数据集都有一份包含样本信息的txt文件
txt文件内容大致是这样(以train.txt为例),包含图片信息和人脸位置信息:
# 0--Parade/0_Parade_marchingband_1_849.jpg
449 330 122 149 488.906 373.643 0.0 542.089 376.442 0.0 515.031 412.83 0.0 485.174 425.893 0.0 538.357 431.491 0.0 0.82
# 0--Parade/0_Parade_Parade_0_904.jpg
361 98 263 339 424.143 251.656 0.0 547.134 232.571 0.0 494.121 325.875 0.0 453.83 368.286 0.0 561.978 342.839 0.0 0.89
模型训练
python train.py --network mobile0.25
如有需要,请先下载预训练模型,放在weights文件夹中。如果想从头开始训练,则在data/config.py文件中指定'pretrain': False,
模型评估
mobile0.25
cd ./widerface_evaluate
python setup.py build_ext --inplace
python test_widerface.py --trained_model ./weights/mobilenet0.25_Final.pth --network mobile0.25
python widerface_evaluate/evaluation.py
执行完第二条语句后会编译出.so文件,最好在linux系统上进行所有操作:

执行完第三句后,模型会对数据进行批次检测:
执行完第三句,评估结果如下:

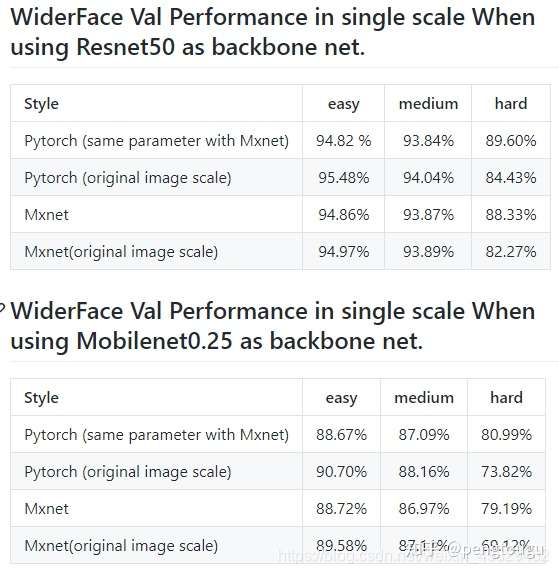
作者给出的实验结果:
三、GhostNet和MobileNetv3移植骨架
3.1 pytorch_retinaface源码修改
上节测试后,又拿了一张只包含一张人脸的图片进行检测,可以发现,resnet50对于检测单张图片且图片仅含单张人脸耗时比较久,如果项目注重实时性的话mb0.25是个更好的选择,但对于人脸密集且尺度较小的场景就显得比较吃力。
倘若骨架替换成其他网络,是否能兼顾实时性和精度?
这里的骨架替换暂时使用ghostnet和mobilev3网络(主要也想测试下这两个网络的效果是否能像论文一样出众)。
我们在config.py文件中添置这两个网络的相关参数信息:
cfg_gnet = {
'name': 'ghostnet',
'min_sizes': [[16, 32], [64, 128], [256, 512]],
'steps': [8, 16, 32],
'variance': [0.1, 0.2],
'clip': True,
'loc_weight': 2.0,
'gpu_train': True,
'batch_size': 16,
'ngpu': 1,
'epoch': 300,
'decay1': 190,
'decay2': 220,
'image_size': 640,
'pretrain': False,
'return_layers': {'blocks1': 1, 'blocks2': 2, 'blocks3': 3},
'in_channel': 32,
'out_channel': 64
}
cfg_mnetv3 = {
'name': 'mobilev3',
'min_sizes': [[16, 32], [64, 128], [256, 512]],
'steps': [8, 16, 32],
'variance': [0.1, 0.2],
'clip': True,
'loc_weight': 2.0,
'gpu_train': True,
'batch_size': 16,
'ngpu': 1,
'epoch': 350,
'decay1': 190,
'decay2': 220,
'image_size': 680,
'pretrain': False,
'return_layers': {'bneck1': 1, 'bneck2': 2, 'bneck3': 3},
'in_channel': 32,
'out_channel': 64
}
我们在retinaface.py文件的父类指定相关引用,并在IntermediateLayerGetter(backbone, cfg[‘return_layers’])指定需要调用的网络层ID,该ID在config.py文件中已经指明:
def __init__(self, cfg=None, phase='train'):
"""
:param cfg: Network related settings.
:param phase: train or test.
"""
super(RetinaFace, self).__init__()
self.phase = phase
backbone = None
if cfg['name'] == 'mobilenet0.25':
backbone = MobileNetV1()
if cfg['pretrain']:
checkpoint = torch.load("./weights/mobilenetV1X0.25_pretrain.tar", map_location=torch.device('cpu'))
from collections import OrderedDict
new_state_dict = OrderedDict()
for k, v in checkpoint['state_dict'].items():
name = k[7:] # remove module.
new_state_dict[name] = v
# load params
backbone.load_state_dict(new_state_dict)
elif cfg['name'] == 'Resnet50':
import torchvision.models as models
backbone = models.resnet50(pretrained=cfg['pretrain'])
elif cfg['name'] == 'ghostnet':
backbone = ghostnet()
elif cfg['name'] == 'mobilev3':
backbone = MobileNetV3()
self.body = _utils.IntermediateLayerGetter(backbone, cfg['return_layers'])
我们指定FPN的网络通道数,并为模型中制定的三层FPN结构固定每一层的in_channels:
in_channels_stage2 = cfg['in_channel']
in_channels_list = [
in_channels_stage2 * 2,
in_channels_stage2 * 4,
in_channels_stage2 * 8,
]
out_channels = cfg['out_channel']
# self.FPN = FPN(in_channels_list, out_channels)
self.FPN = FPN(in_channels_list, out_channels)
以mobile0.25为例,从下往上的in_channels分别为64,128,256(在config.py定义的初始 'in_channel': 32,分别*2,*4,*8依次类推)
正如论文所说的,pytorch版本定义了SSH的三层结构,并将FPN迭代的结果封装成三组Tensor,分别代入计算。得出三组features,再合并成一类大组。
"""
retinaface.py → line 91 - line 97
"""
self.ssh1 = SSH(out_channels, out_channels)
self.ssh2 = SSH(out_channels, out_channels)
self.ssh3 = SSH(out_channels, out_channels)
self.ClassHead = self._make_class_head(fpn_num=3, inchannels=cfg['out_channel'])
self.BboxHead = self._make_bbox_head(fpn_num=3, inchannels=cfg['out_channel'])
self.LandmarkHead = self._make_landmark_head(fpn_num=3, inchannels=cfg['out_channel'])
"""
retinaface.py → line 123 - line 133
"""
fpn = self.FPN(out)
# SSH
feature1 = self.ssh1(fpn[0])
feature2 = self.ssh2(fpn[1])
feature3 = self.ssh3(fpn[2])
features = [feature1, feature2, feature3]
bbox_regressions = torch.cat([self.BboxHead[i](feature) for i, feature in enumerate(features)], dim=1)
classifications = torch.cat([self.ClassHead[i](feature) for i, feature in enumerate(features)], dim=1)
ldm_regressions = torch.cat([self.LandmarkHead[i](feature) for i, feature in enumerate(features)], dim=1)
我们在models/ghostnet.py中插入ghontnet网络,网络结构来源于诺亚方舟实验室开源地址https://github.com/huawei-noah/ghostnet:
分类效果对比:
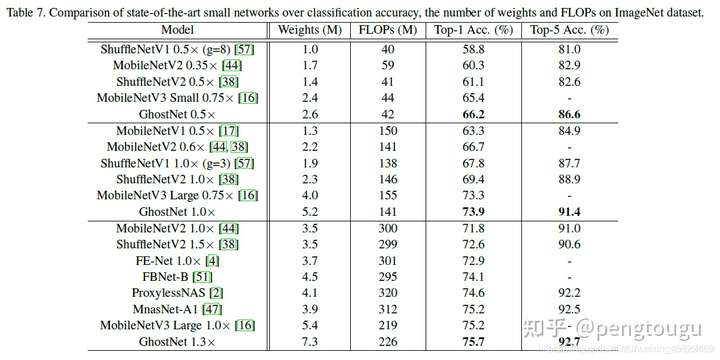
因为包含残差卷积分离模块和SE模块,源码相对较长,修改后的网络源码如下:
class GhostNet(nn.Module):
def __init__(self, cfgs, num_classes=1000, width=1.0, dropout=0.2):
super(GhostNet, self).__init__()
# setting of inverted residual blocks
self.cfgs = cfgs
self.dropout = dropout
# building first layer
output_channel = _make_divisible(16 * width, 4)
self.conv_stem = nn.Conv2d(3, output_channel, 3, 2, 1, bias=False)
self.bn1 = nn.BatchNorm2d(output_channel)
self.act1 = nn.ReLU(inplace=True)
input_channel = output_channel
# building inverted residual blocks
stages = []
block = GhostBottleneck
for cfg in self.cfgs:
layers = []
for k, exp_size, c, se_ratio, s in cfg:
output_channel = _make_divisible(c * width, 4)
hidden_channel = _make_divisible(exp_size * width, 4)
layers.append(block(input_channel, hidden_channel, output_channel, k, s,
se_ratio=se_ratio))
input_channel = output_channel
# print(output_channel)
stages.append(nn.Sequential(*layers))
# print(len(stages))
# output_channel = _make_divisible(exp_size * width, 4)
# stages.append(nn.Sequential(ConvBnAct(input_channel, output_channel, 1)))
# input_channel = output_channel
# self.blocks = nn.Sequential(*stages)
# 此处封装第一层block,对应于config.py文件中
self.blocks1 = nn.Sequential(
stages[0],
stages[1],
stages[2],
stages[3],
stages[4],
)
# 此处封装第二层block,对应于config.py文件中
self.blocks2 = nn.Sequential(
stages[5],
stages[6],
)
# 此处封装第三层block,对应于config.py文件中
self.blocks3 = nn.Sequential(
stages[7],
stages[8],
)
# building last several layers
output_channel = 256
self.global_pool = nn.AdaptiveAvgPool2d((1, 1))
self.conv_head = nn.Conv2d(input_channel, output_channel, 1, 1, 0, bias=True)
self.act2 = nn.ReLU(inplace=True)
self.classifier = nn.Linear(output_channel, num_classes)
# 网络架构重新封装,前推理部分跟着响应改变
def forward(self, x):
x = self.conv_stem(x)
x = self.bn1(x)
x = self.act1(x)
x = self.blocks1(x)
x = self.blocks2(x)
x = self.blocks3(x)
# x = self.blocks(x)
x = self.global_pool(x)
x = self.conv_head(x)
x = self.act2(x)
x = x.view(x.size(0), -1)
if self.dropout > 0.:
x = F.dropout(x, p=self.dropout, training=self.training)
x = self.classifier(x)
return x
我们在models/mobilev3.py中插入MobileNetv3网络,网络结构来源于github网友复现的pytorch版本,真即插即用!https://github.com/kuan-wang/pytorch-mobilenet-v3:
分类效果:
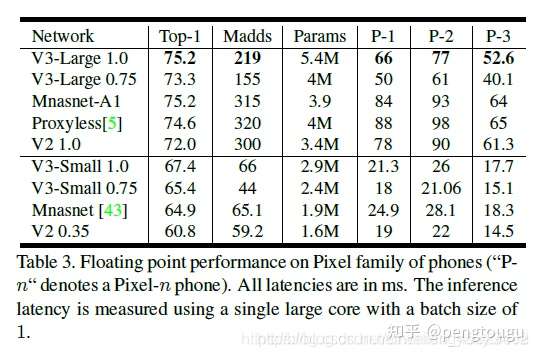
修改后的源码如下:
#!/usr/bin/env python
# coding:utf-8
"""
Name : mobilenetv3.py
Author : @ Chenxr
Create on : 2021/5/8 22:45
Desc: None
class MobileNetV3(nn.Module):
def __init__(self, num_classes=1000):
super(MobileNetV3, self).__init__()
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=2, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(16)
self.hs1 = hswish()
self.bneck1 = nn.Sequential(
Block(3, 16, 16, 16, nn.ReLU(inplace=True), None, 1),
Block(3, 16, 64, 32, nn.ReLU(inplace=True), None, 2),
Block(3, 32, 72, 32, nn.ReLU(inplace=True), None, 1),
Block(5, 32, 72, 64, nn.ReLU(inplace=True), SeModule(64), 2),
Block(5, 64, 120, 64, nn.ReLU(inplace=True), SeModule(64), 1),
Block(5, 64, 120, 64, nn.ReLU(inplace=True), SeModule(64), 1),
)
self.bneck2 = nn.Sequential(
Block(3, 64, 240, 80, hswish(), None, 2),
Block(3, 80, 200, 80, hswish(), None, 1),
Block(3, 80, 184, 80, hswish(), None, 1),
Block(3, 80, 184, 128, hswish(), None, 1),
)
self.bneck3 = nn.Sequential(
Block(3, 128, 480, 128, hswish(), SeModule(128), 1),
Block(3, 128, 672, 128, hswish(), SeModule(128), 1),
Block(5, 128, 672, 256, hswish(), SeModule(256), 1),
Block(5, 256, 672, 256, hswish(), SeModule(256), 2),
Block(5, 256, 960, 256, hswish(), SeModule(256), 1),
)
self.conv2 = nn.Conv2d(256, 960, kernel_size=1, stride=1, padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(960)
self.hs2 = hswish()
self.linear3 = nn.Linear(960, 1280)
self.bn3 = nn.BatchNorm1d(1280)
self.hs3 = hswish()
self.linear4 = nn.Linear(1280, num_classes)
self.init_params()
在train.py中,我们将植入的网络导进来,并指定相关配置(在detect.py文件中同样的处理):
from models.retinaface import RetinaFace
parser = argparse.ArgumentParser(description='Retinaface Training')
parser.add_argument('--training_dataset', default='./data/widerface/train/label.txt', help='Training dataset directory')
parser.add_argument('--network', default='ghostnet', help='Backbone network mobile0.25 & resnet50 & ghostnet & mobilev3')
parser.add_argument('--num_workers', default=4, type=int, help='Number of workers used in dataloading')
parser.add_argument('--lr', '--learning-rate', default=0.01, type=float, help='initial learning rate')
parser.add_argument('--momentum', default=0.9, type=float, help='momentum')
parser.add_argument('--resume_net', default=None, help='resume net for retraining')
parser.add_argument('--resume_epoch', default=0, type=int, help='resume iter for retraining')
parser.add_argument('--weight_decay', default=5e-4, type=float, help='Weight decay for SGD')
parser.add_argument('--gamma', default=0.1, type=float, help='Gamma update for SGD')
parser.add_argument('--save_folder', default='./mobilev3/', help='Location to save checkpoint models')
if args.network == "mobile0.25":
from models.retinaface_m import RetinaFace
cfg = cfg_mnet
elif args.network == "resnet50":
from models.retinaface_m import RetinaFace
cfg = cfg_re50
elif args.network == "ghostnet":
from models.retinaface_g import RetinaFace
cfg = cfg_gnet
elif args.network == "mobilev3":
from models.retinaface_g import RetinaFace
cfg = cfg_mnetv3
3.2 模型训练
执行命令:nohup python train.py --network ghostnet > ghostnet.log 2>&1 &开始训练
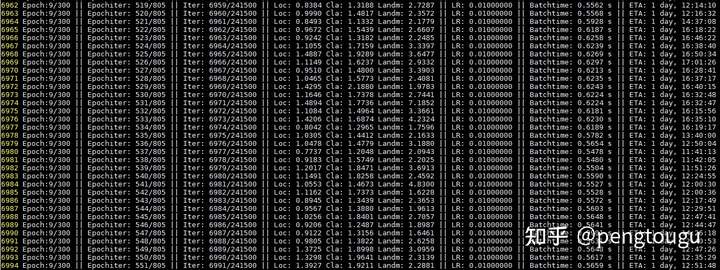
统计每个网络训练单个epoch的时长:
- resnet50>>mobilenetv3>ghostnet-m>ghostnet-s>mobilenet0.25
3.3 模型测试与评估
评估的具体步骤在上节已经讲过,这里不再累述
测试ghostnet(se-ratio=0.25):
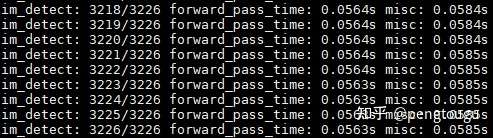
可以看出,一份batch的测试大概在56ms左右
评估ghostnet(se-ratio=0.25):

可以看出,ghostnet对小样本数据和人脸遮挡的情况识别相对较差。
测试MobileNetV3(se-ratio=1):
可以看出,一份batch的测试大概在120ms左右
评估MobileNetV3(se-ratio=1):

(这里的比对其实是有点不科学的,因为是用的mbv3的se_ratio全开对标ghostnet的se_ratio开1/4,但ghostnet的se_ratio全开会导致模型内存暴涨的情况(se-ratio=0时weights=6M,se-ratio=0.25时weights=12M,se-ratio=1时weights=30M,且精度勉强超过se-ratio=1的MobileNetV3,个人感觉性价比过低))
3.4 resnet & mbv3 & gnet & mb0.25对比测试
推理性能对比:
| Backbone | Computing backend | size(MB) | Framework | input_size | Run time |
|---|---|---|---|---|---|
| resnet50 | Core i5-4210M | 106 | torch | 640 | 1571 ms |
| G h o s t N e t − m S e = 0.25 GhostNet-m^{Se=0.25} GhostNet−mSe=0.25 | Core i5-4210M | 12 | torch | 640 | 403 ms |
| MobileNet v3 | Core i5-4210M | 8 | torch | 640 | 576 ms |
| MobileNet0.25 | Core i5-4210M | 1.7 | torch | 640 | 187 ms |
| MobileNet0.25 | Core i5-4210M | 1.7 | onnxruntime | 640 | 73 ms |
可以看出,resnet推理耗时最久,且模型内存最大(但效果肯定是最好的),mb0.25耗时最少,但精度最低,但gnet和mbv3在以上模型中更兼容实时与精度,大家可以试着在gpu下跑一跑,会有意想不到的收获~
检测性能对比:
| Backbone | Easy | Medium | Hard |
|---|---|---|---|
| resnet50 | 95.48% | 94.04% | 84.43% |
| MobileNet v3 S e = 1 ^{Se=1} Se=1 | 93.48% | 91.23% | 80.19% |
| G h o s t N e t − m S e = 0.25 GhostNet-m^{Se=0.25} GhostNet−mSe=0.25 | 93.35% | 90.84% | 76.11% |
| MobileNet0.25 | 90.70% | 88.16% | 73.82% |
单图测试效果对比:
补充:
- 测试的单帧Infer Time=推理一分钟/该分钟内处理的帧数
- 实际生产中其实并不需要这么高的input_size(主测2-3m内的检测性能)
- 以上测试均为CPU下进行,且笔者的笔记本已经待机6年有余,即将达到寿命大限(昨天电脑拿去修了。。。难受的一天)
- 个人电脑不同,测试出来的性能可能会有所偏差,但应该不大
总结:
- 对于背景单一的业务场景,似乎更注重实时性,我个人还是更喜欢mb0.25的版本和ghostnet版本
- 5月10日后,过客团队提出了一个更强更优越的人脸检测框架,可以参照本人其他博客进行了解 后期会贡献onnxruntime调用模型的脚本
- 代码已开源,欢迎白嫖和star:
github.com/pengtougu/Retinaface_Ghost
致谢
感谢Sansa shi大佬扎实的文献研读功底,才能呈现出如此完美的论文研读报告,十分收益
感谢biubug6大佬出色的pytorch复现版本,才能让笔者得以在一座大厦上构建自己的屋架
里面有很多的研究生大佬和各行各业的大咖~


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)