
迁移学习论文(二):Deep Reconstruction-Classification Networks for Unsupervised Domain Adaptation论文原理及复现工作
目录前言原理阐述文章介绍模型结构标签分类器目标域重构器总结前言本文属于我迁移学习专栏里的一篇,该专栏用于记录本人研究生阶段相关迁移学习论文的原理阐述以及复现工作。本专栏的文章主要内容为解释原理,论文具体的翻译及复现代码在文章的github中。原理阐述文章介绍这篇文章于2016年发表在ECCV,作者是Muhammad Ghifary, W. Bastiaan Kleijn, Mengjie Zhan
·
前言
- 本文属于我迁移学习专栏里的一篇,该专栏用于记录本人研究生阶段相关迁移学习论文的原理阐述以及复现工作。
- 本专栏的文章主要内容为解释原理,论文具体的翻译及复现代码在文章的github中。
原理阐述
文章介绍
- 这篇文章于2016年发表在ECCV,作者是Muhammad Ghifary, W. Bastiaan Kleijn, Mengjie Zhang, David Balduzzi, Wen Li
- 这篇文章作者设计了两个网络,一个是源域数据分类网络,一个目标域数据重构网络。两个网络同时训练。这样做的目的是想编码网络上共享的,希望它能学到数据的共有特征,既能用于重构,也能用于标签预测。
模型结构
- DRCN的模型是这样的:
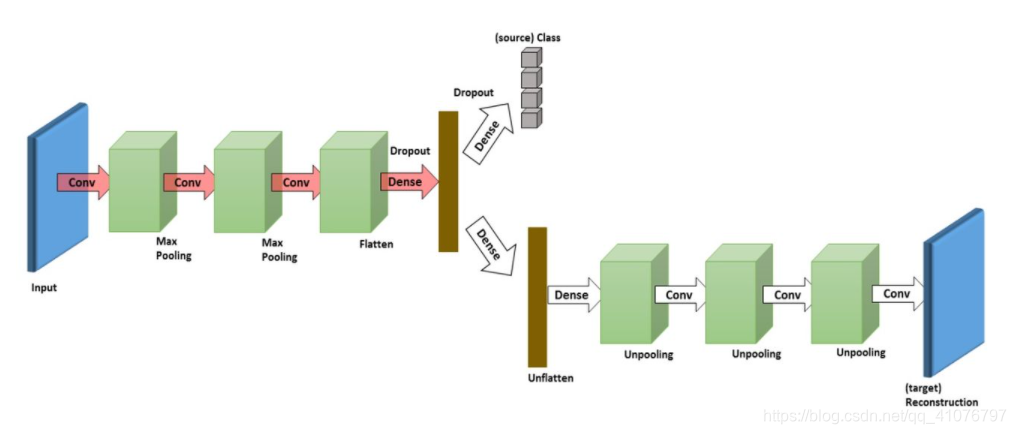
标签分类器
- 标签分类器这个不用多说了,用于减低源域数据标签分类损失。
目标域重构器
- 这里目标域重构器是用来降低目标域重构损失,即使得提取的特征能够经过重构器之后尽可能重现目标域样本,如果Decoder最终的输出和原始Encoder的输入差距很小,我们就可以认为Encoder部分学习到的关于目标域的特征表达是有效的。但是这里有个疑问, 即便你可以很准确的提取目标域特征,那然后呢?对于域分类有什么帮助呢?分类器的参数可没根据目标域特征来进行调整,分类器的参数是用来最大提高源域数据分类精准度的,你目标域提取到的特征再准确,它未必能够被分类器来正向利用,只有提取域不变特征才能被分类器利用。
损失函数
- 见下图:
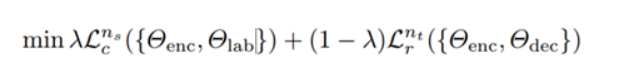
训练伪代码
- 见下图:

总结
- 感觉这篇论文提出的模型比较基础,而且有些地方感觉并不是很合理,但也提供了重构器这么一种思路。

鸿蒙生态一站式服务平台。
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)