
FP32、FP16和INT8
FP32(Full Precise Float 32,单精度)占用4个字节,共32位,其中1位为符号位,8为指数位,23为尾数位。FP16(float,半精度)占用2个字节,共16位,其中1位为符号位,5位指数位,十位有效数字位。与FP32相比,FP16的访存消耗仅为1/2,也因此FP16是更适合在移动终端侧进行AI计算的数据格式。INT8,八位整型占用1个字节,INT8是一种定点计算方式,代表整
1、定义
FP32(Full Precise Float 32,单精度)占用4个字节,共32位,其中1位为符号位,8为指数位,23为尾数位。
FP16(float,半精度)占用2个字节,共16位,其中1位为符号位,5位指数位,十位有效数字位。与FP32相比,FP16的访存消耗仅为1/2,也因此FP16是更适合在移动终端侧进行AI计算的数据格式。
INT8,八位整型占用1个字节,INT8是一种定点计算方式,代表整数运算,一般是由浮点运算量化而来。在二进制中一个“0”或者“1”为一bit,INT8则意味着用8bit来表示一个数字。因此,虽然INT8比FP16精度低,但是数据量小、能耗低,计算速度相对更快,更符合端侧运算的特点。
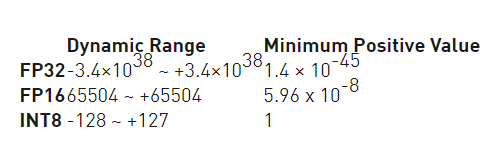
2、比较
低精度技术 (high speed reduced precision)。在training阶段,梯度的更新往往是很微小的,需要相对较高的精度,一般要用到FP32以上。在inference的时候,精度要求没有那么高,一般F16(半精度)就可以,甚至可以用INT8(8位整型),精度影响不会很大。同时低精度的模型占用空间更小了,有利于部署在嵌入式模型里面。
利用fp16 代替 fp32
优点:
1)TensorRT的FP16与FP32相比能有接近一倍的速度提升,前提是GPU支持FP16(如最新的2070,2080,2080ti等)
2)减少显存。
缺点:
1) 会造成溢出
3、测试
我用Jetson Xavier NX测试了基于TensorRT加速的yolo算法在FP32、FP16、INT8三种精度下的数据:

Ref:
TensorRT模型转换及部署,FP32/FP16/INT8精度区分
Pytorch中的cuda张量转cpu张量耗时比较大该怎么办?

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)