
JAVA技术体系之分布式篇(五)——Kafka消息中间件
1
1、Kafka概述
1.1 Kafka定义
Apache Kafka 是一款开源的消息系统。可以在系统中起到“肖峰填谷”的作用,也可以用于异构、分布式系统中海量数据的异步化处理。
1.2 Kafka使用场景
- 消息中间件: 作为消息中间件进行消息传递,作为TCP HTTP或者RPC的替代方案,可以实现异步、解耦、削峰(RabbitMQ和RocketMQ能做的事情,它也能做)。因为kafka的吞吐量更高,在大规模消息系统中更有优势。
- 大数据领域: 例如日志归集、行为跟踪、应用监控。
- 数据集成+流计算: 对流式数据进行继承和实时计算。
2、Kafka服务端基本认识
目前比较流行的服务端管理界面主要是 kafka-manager 和 kafka-eagle (国产)。
2.1 Kafka与ZK的关系
总结起来:利用ZK的有序节点、临时节点和监听机制,ZK帮kafka做了这些事情:配置中心(管理Broker、Topic、Partition、Consumer的信息,包括元数据的变动)、负载均衡、命名服务、分布式通知、集群管理和选举、分布式锁。
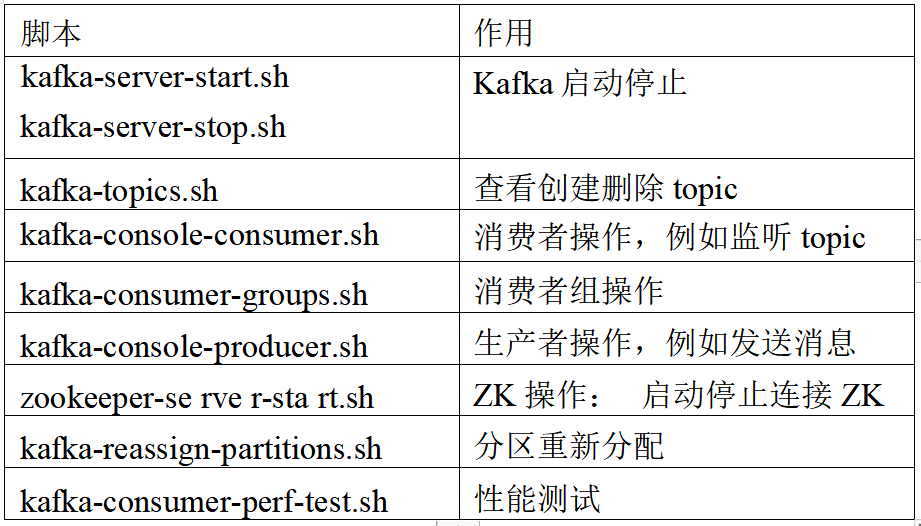
2.2 Kafka脚本介绍
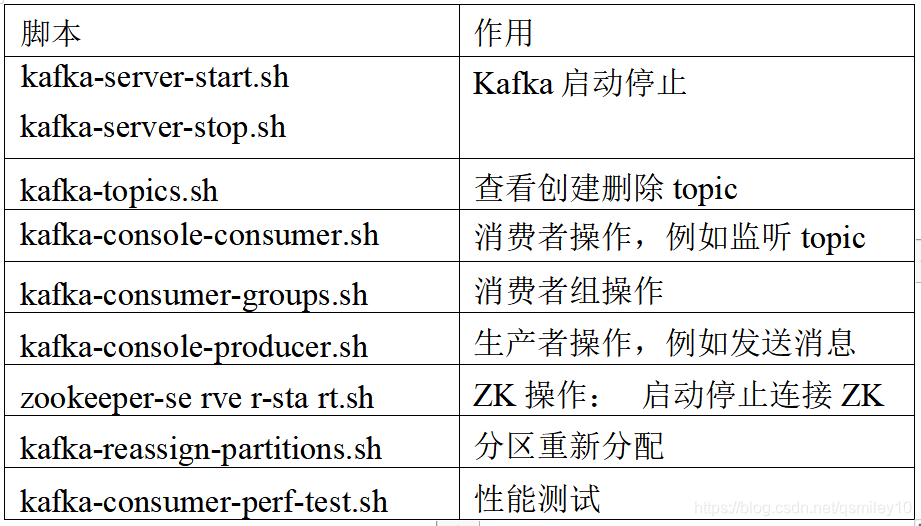
3、Kafka架构分析
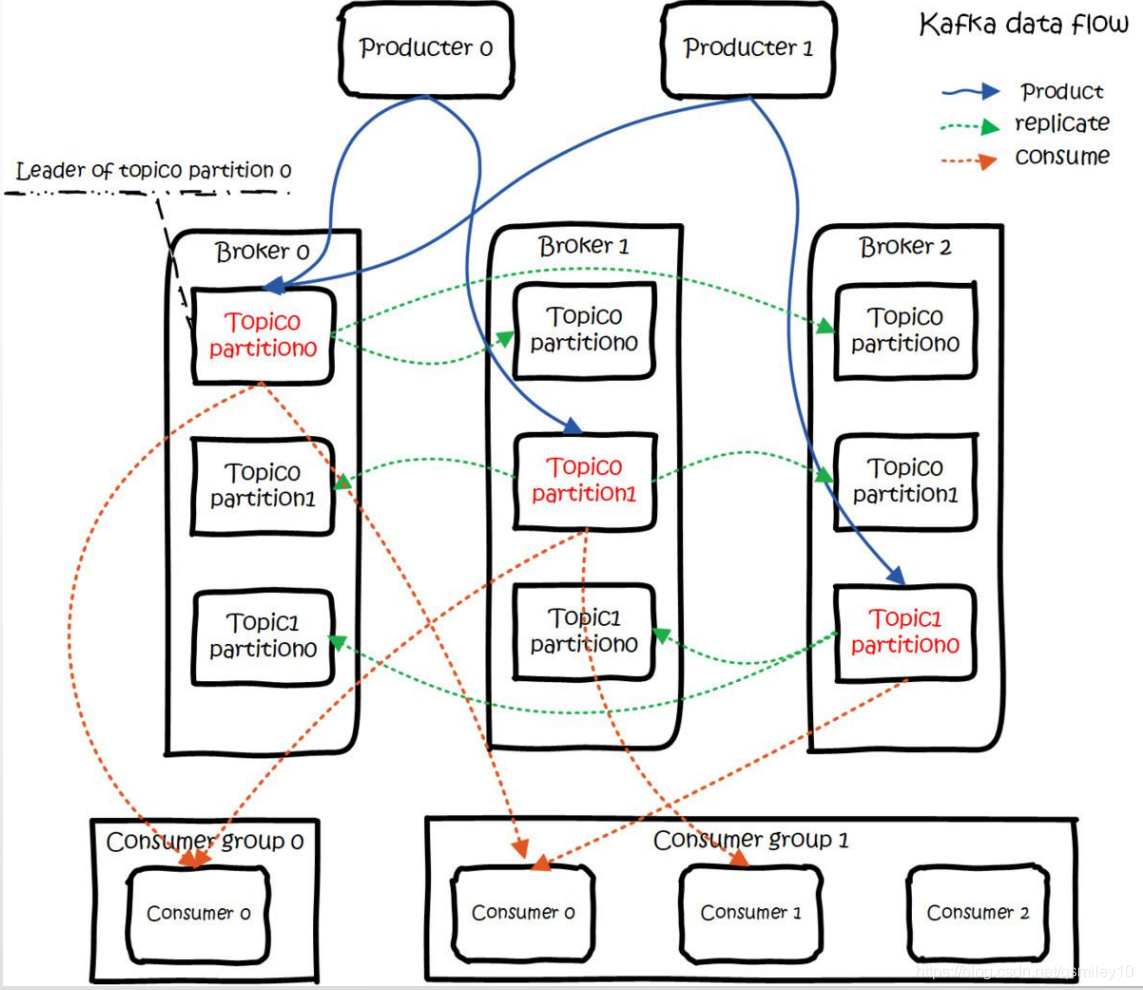
3.1 Broker
Kafka作为一个中间件,是帮我们存储和转发消息的,它做的事情有点像中介,所以我们把kafka的服务叫做Broker,默认是9092的端口。生产者和消费者都需要跟这个Broker建立一个连接,才可以实现消息的收发。
3.2 消息
客户端之间传输的数据叫做消息,或者叫做记录(Record)。在客户端的代码中,Record可以是一个KV键值对,生产者的封装类是ProducerRecord,消费者的封装类是ConsumerRecord。
消息在传输过程中需要序列化,所以在代码中要指定序列化工具。
3.3 生产者
发送消息的一方叫做生产者。为了提升发送效率,生产者不是逐条发送消息给Broker,而是批量发送的,发送的数据大小和时间间隔由以下参数决定:
batch.size=16384
linger.ms=0
3.4 消费者
接收消息的一方叫做消费者。
—般来说消费者获取消息有两种模式,一种是pull模式,一种是push模式。Pull模式就是消费放在Broker,消费者自己决定什么时候去获取。Push模式是消息放在Consumer,只要有消息到达Broker,都直接推给消费者。
Kafka只支持pull模式,因为在push模式下,如果消息产生速度远远大于消费者消费消息的速率,那消费者就会不堪重负(你已经吃不下了,但是还要不断地往你嘴里塞),直到挂掉。而且在pull模式下消费者一次pull获取多少条消息由以下参数决定:
max.poll.records=500
3.5 Topic
生产者跟消费者是怎么关联起来的呢?或者说,生产者发送的消息,怎么才能到达某个特定的消费者?他们要通过队列关联起来,也就是说,生产者发送消息,要指定发给哪个队列。消费者接收消息,要指定从哪个队列接收。在Kafka里面,这个队列叫做Topic。它是一个逻辑的概念,可以理解为一组消息的集合(用以区分不同业务用途的消息)。
注意,生产者发送消息时,如果Topic不存在,会自动创建。由以下参数决定:
auto.create.topics.enable=true
3.6 Partition
如果说一个Topic中的消息太多,会带来两个问题:
第一个是不方便横向扩展,比如我想要在集群中把数据分布在不同的机器上实现扩展,而不是通过升级硬件做到,如果一个Topic的消息无法在物理上拆分到多台机器的时候,这个是做不到的。
第二个是并发或者负载的问题,所有的客户端操作的都是同一个Topic,在高并发的场景下性能会大大下降。
怎么解决这个问题呢?我们想到的就是把一个Topic进行拆分。 Kafka引入了一个分区(Partition)的概念。一个Topic可以划分成多个分区。 分区在创建topic的时候指定,每个topic至少有一个分区。
在创建topic时需要指定分区数由以下参数决定:
num.partitions=1
Partition思想上有点类似于分库分表,实现的也是横向扩展和负载的目的。举个例子,Topic有3个分区,生产者依次发送9条消息,对消息进行编号。 第一个分区存1 4 7,第二个分区存2 5 8,第三个分区存3 6 9,这个就实现了负载。
3.7 Replica
如果partition的数据只存储一份,在发生网络或者硬件故障的时候,该分区的数据就无法访问或者无法恢复了。
Kafka在0.8的版本之后增加了副本机制。每个partition可以有若干个副本(Replica),副本必须在不同的Broker 上面。—般我们说的副本包括其中的主节点。由 replication-factor指定一个Topic 的副本数。默认副本数由以下参数决定
offsets.topic.replication.factor=1
举例:部署了 3个Broker,该topic有3个分区,每个分区一共3个副本。
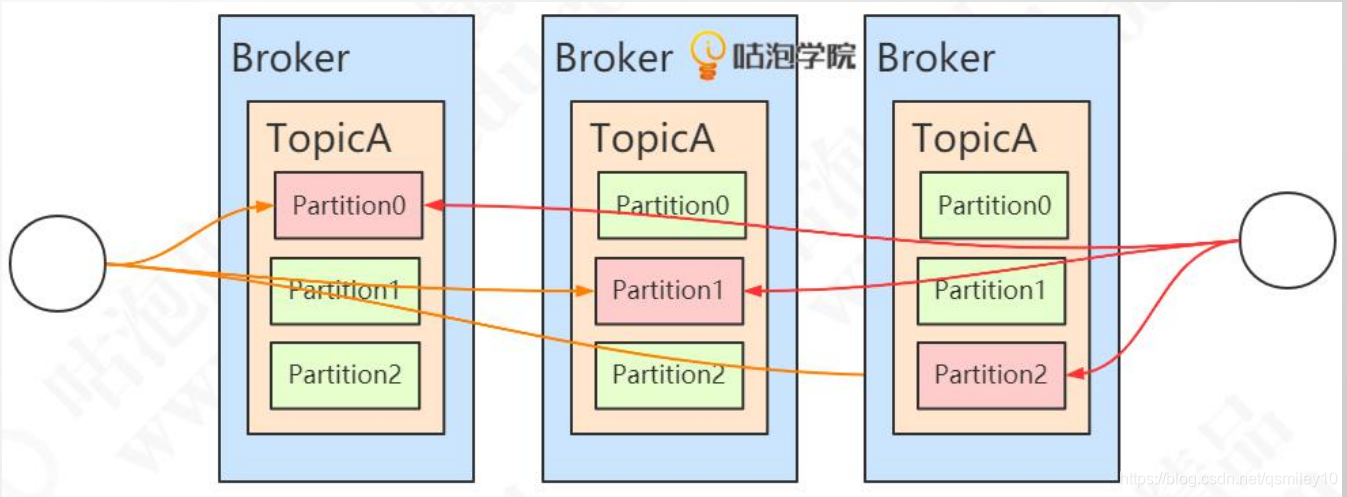
注意:这些存放相同数据的partition副本有leader(图中红色)和follower(图中绿色)的概念。leader在哪台机器是不一定的,选举岀来的。
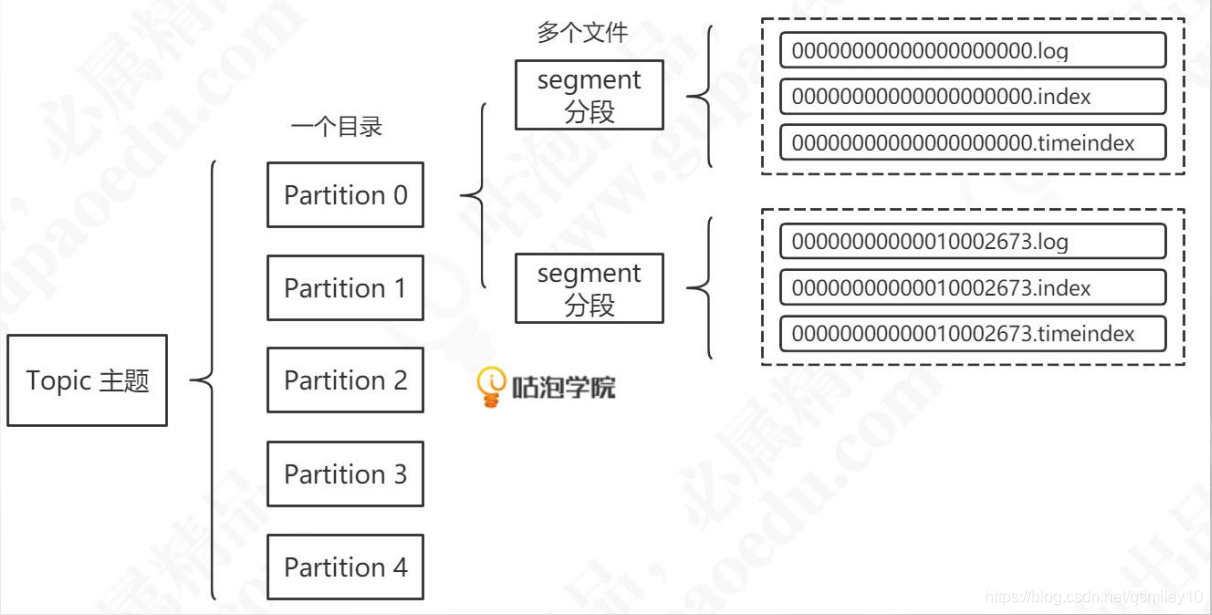
3.8 Segment
Kafka的数据是放在后缀.log的文件里面的。如果一个partition只有一个log文件,消息不断地追加,这个log文件也会变得越来越大,这个时候要检索数据效率就很低了。所以干脆把partition再做一个切分,切分岀来的单位就叫做段(segment)。实际上kafka的存储文件是划分成段来存储的。默认存储路径:/tmp/kafka-logs/ 。每个segment都有至少有1个数据文件和2个索引文件,这3个文件是成套出现的。
3.9 Consumer Group
我们知道消息中间件一般会支持发布/订阅模式和广播模式,那么在Kafka中是如何实现的呢?或者换一种问法,当多个消费者订阅了同一个topic的时候,该如何区分这条消息是要单发还是群发呢?
Kafka引入了消费者组Consumer Group的概念,通过group.id来配置,group.id相同的消费者属于同一个消费者组,Kafka对不同消费者组进行广播,而同一个消费者组中的消费者只消费一次消息。
具体点说,同一个消费者组的消费者不能订阅相同的分区。当消费者数量小于分区数时,一个消费者消费多个分区,当消费者数量大于分区数时,多余的消费者将不进行工作。
3.10 Consumer Offset
我们已经知道Kafka消息是写在日志文件中,并且不会在消费过后就被删除。那么当一个消费者组在消费一半时重启了,该如何继续上一次的位置读取消息呢?为此,Kafka引入Consumer Offset的概念。
Consumer Offset是标记一个消费者组在一个partition即将消费的下一条记录,这个信息直接保存在Kafka本身一个特殊的topic中,叫__consumer_offsets,默认创建50个分区。
4、Kafka原理
4.1 Kafka生产者原理
4.1.1 生产者发送流程
消息发送的整体流程。生产端主要由两个线程协调运行。这两条线程分别为main线程和sender线程(发送线程)。
在创建KafkaProducer的时候,创建了一个Sender对象,并且启动了—个IO线程。
4.1.1.1 拦截器
第二步是执行拦截器的逻辑,在producer.send方法中:
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);
拦截器的作用是实现消息的定制化(类似于Spring Interceptor、MyBatis的插件、Quartz的监听器)。那这个拦截器是在哪里定义的呢?生产者代码:
List<String> interceptors = new ArrayList<>();
interceptors.add(" com.xxx.interceptor.Charginginterceptor");
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, interceptors);
举个例子,假设发送消息的时候要扣钱,发一条消息1分钱(我把这个功能叫做按量付费),就可以用拦截器实现。
public class Charginginterceptor implements ProducerInterceptor<String, String> {
//发送消息的时候触发
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
System.out.println("1分钱1条消息,不管那么多反正先扣钱”);
return record;
}
//收到服务端的ACK的时候触发
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
System.out.pnntln(n消息被服务端接收啦”);
}
@Override
public void close() {
System.out.printin(”生产者关闭了");
}
//用键值对配置的时候触发
@Override
public void configure(Map<String, ?> configs) {
System. out.piintln(n configure...H);
}
}
4.1.1.2 序列化
接下来是利用指定的工具对key和value进行序列化:
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
kafka针对不同的数据类型自带了相应的序列化工具。
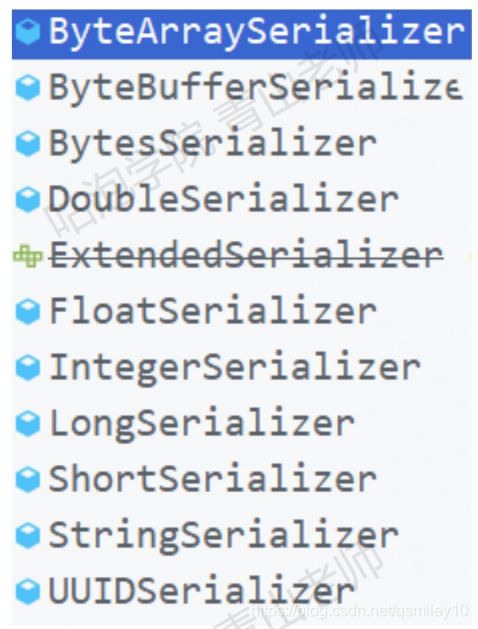
除了自带的序列化工具之外,可以使用如Avro、JSON、Thrift. Protobuf等,或者使用自定义类型的序列化器来实现,实现Serializer接口即可。
4.1.1.3 分区路由
然后是分区指定:
int partition = partition(record, serializedKey, serialized Value, cluster);
一条消息会发送到哪个partition呢?它返回的是一个分区的编号,从0开始。有四种情况:
- 指定了partition——直接将指定的值直接作为partiton值。
- 没有指定partition,自定义了分区器——将使用自定义的分区器算法选择分区。
- 没有指定partition,没有自定义分区器,但是key不为空——使用默认分区器DefaultPartitioner,将
key的hash值与topic的partition数进行取余得到partition值; - 没有指定partition,没有自定义分区器,但是key是空的——第一次调用时随机生成一个整数(后面每次调用在这个整数上自增),将这个值与topic可用的partition总数取余得到 partition值,也就是常说的round-robin算法。
4.1.1.4 消息累加器
选择分区以后并没有直接发送消息,而是把消息放入了消息累加器:
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey, serializedValue, headers, interceptcallback, remainingWaitMs);
RecordAccumulator 本质上是一个 ConcurrentMap:
ConcurrentMap<TopicPailition Deque<ProducerBatc>> batches;
—个partition —个Batch。batch满了之后,会唤醒Sender线程,发送消息:
if (result.batchlsFull || result.newBatchCreated) {
log.trace(Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
this.sender.wakeup();
}
4.1.2 消息应答机制ACK
4.1.2.1 服务端响应策略
生产者的消息是不是发出去就完事了?如果说网络出了问题,或者说kafka服务端接收的时候出了问题,这个消息发送失败了,生产者是不知道的。所以,kafka服务端应该要有一种响应客户端的方式,只有在服务端确认以后,生产者才发送下一轮的消息,否则重新发送数据。
服务端什么时候才算接收成功呢?因为消息是存储在不同的partition里面的,所以是写入到partition之后响应生产者。当然,单个partition (leader)写入成功,还是不够可靠,如果有多个副本,follower 也要写入成功才可以。
为了安全性考虑,Kafka会等待所有的follower全部完成同步,才发送ACK给客户端,延迟相对来说高一些,但是节点挂掉的影响相对来说小一些,因为所有的节点数据都是完整的。
4.1.2.2 ISR
然而以上方案仍然存在问题:假设leader收到数据,所有follower都开始同步数据,但是有一个follower出了问题,没有办法从leader同步数据。按照这个规则,leader就要一致等待,无法发送 ack。
从概率的角度来讲,这种问题肯定是会出现的,就是某个follower出问题了,怎么解决呢?所以我们的规则就不能那么粗暴了,把规则改一下,不是所有的follower都有权利 让我等待,而是只有那些正常工作的follower同步数据的时候我才会等待。
我们应该把那些正常和leader保持同步的replica维护起来,放到一个动态set里面,这个就叫做in-sync replica set (ISR)。现在只要ISR里面的follower同步完数据之后,我就给客户端发送ACK。如果一个follower长时间不同步数据,就要从ISR剔除。同样,如果后面这个follower重新与leader保持同步,就会重新加入ISR。时间间隔由以下参数决定:
replica.lag.time.max.ms=10000
4.1.2.3 ACK应答
当然,如果所有的数据都一视同仁,而且这种策略只能由服务端决定,这就不是很灵活了。有一些数据丢了无所谓,我只想要快,不管它落没落盘同没同步,怎么办呢?
Kafka为客户端提供了三种可靠性级别,用户根据对可靠性和延迟的要求进行权衡,选择相应的配置。
- acks=0: producer不等待broker的ack,这一操作提供了一个最低的延迟,broker一接收到还没有写入磁盘就已经返回,当broker故障时有可能丢失数据;
- acks=1(默认): producer 等待 broker 的 ack, partition 的 leader 落盘成功后 返回ack,如果在follower同步成功之前leader故障,那么将会丢失数据;
- acks=-1 (all) : producer等待 broker 的 ack, partition 的 Ieader和 follower全部落盘成功后才返回ack。
三种机制,性能依次递减(producer吞吐量降低),数据健壮性则依次递增。我们可 以根据业务场景使用不同的参数。
4.2 Kafka消息存储原理
4.2.1 数据存储目录
目录配置在配置文件config/env.properties,由以下参数决定:
logs.dir=/tmp/kafka-logs
4.2.2 partition分区
为了实现横向扩展,把不同的数据存放在不同的Broker上,同时降低单台服务器的访问压力,我们把一个topic中的数据分隔成多个partition。—个partition中的消息是有序的,顺序写入,但是全局不一定有序。
在服务器上,每个partition都有一个物理目录,topic名字后面的数字标号即代表分区。

4.2.3 replica副本
为了提高分区的可靠性,kafka又设计了副本机制。创建topic的时候,通过指定replication-factor确定topic的副本数。
注意:副本数必须小于等于节点数,而不能大于Broker的数量,否则会报错。
这些所有的副本分为两种角色,leader对外提供读写服务。follower唯一的任务就是从leader异步拉取数据。
4.2.4 副本分布规则
副本在Broker的分布有什么规则吗?例如有个topic:a4part2rep, 4个分区每个2个副本,一共8份副本,怎么分布到3台机器呢?
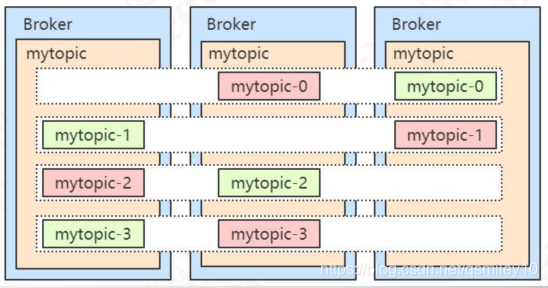
实际副本分布规则是由AdminUtils.scala——assignReplicasToBrokers决定的,具体规则如下:
- 副本因子不能大于Broker的个数;
- 第一个分区(编号为0)的第一个副本放置位置是随机从 brokerList 选择的;
- 其他分区的第一个副本放置位置相对于第0个分区依次往后移 (nextReplicaShift)。
这样设计可以提高容灾能力。在每个分区的第一个副本错开之后,一般第一个分区的第一个副本(按Broker编号排序)都是leader。leader是错开的,不至于一挂影响太大。
4.2.5 Segment
为了防止log不断追加导致文件过大,导致检索消息效率变低,一个partition又被划分成多个segment来组织数据。在磁盘上,每个segment由一个log文件和2个index文件组成。这三个文件是成套出现的。另外还有一个leader-epoch-checkpoint文件中保存了每一任leader开始写入消息时的offset。
1 .log日志文件(日志就是数据)
在一个segment文件里面,日志是追加写入的。如果满足一定条件,就会切分日志文件,产生一个新的segment什么时候会触发segment的切分呢?
第一种是根据日志文件大小。当一个segment写满以后,会创建一个新的segment, 用最新的offset作为名称。文件大小由以下参数控制(默认1G):
log.segment.bytes=1073741824
第二种是根据消息的最大时间戳,和当前系统时间戳的差值。还可以从更加精细的时间单位进行控制,如果配置了毫秒级别的日志切分间隔,会优先使用这个单位。否则就用小时的。间隔时间由以下参数决定:
log.roll.hours=168
log.roll.ms
还有第三种情况,offset索引文件或者timestamp索引文件达到了一定的大小。由参数log.index.size.max.bytes(默认10M) 控制。如果要减少日志文件的切分,可以把这个值调大一点。
2. .index偏移量(offset)索引文件
3. .timeindex 时间戳(timestamp)索引文件
4.2.6 索引
由于一个segment的文件里面可能存放很多消息,如果要根据offset获取消息,必须要有一种快速检索消息的机制。这个就是索引。在Kafka中设计了两种索引:偏移量索引文件记录的是。offset和消息物理地址(在log文件中的位置)的映射关系。时间戳索引文件记录的是时间戳和offset的关系。
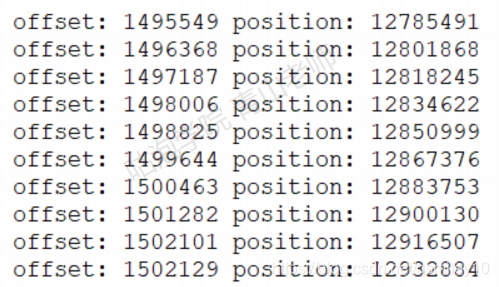
内容是二进制的文件,不能以纯文本形式查看。bin目录下有dumplog工具。 查看最后10条offset索引:
./kafka-dump-log.sh —files /tmp/kafl<a-logs/mytopic-0/00000000000000000000.index|head -n 10
注意,Kafka的索引并不是每一条消息都会建立索引,而是一种稀疏索引sparse index(DB2和Mongdb中都有稀疏索引)。至于这个索引有多稀疏,由以下参数决定:
log.index.interval.bytes=4096
只要写入的消息超过了 4KB,偏移量索引文件index和时间戳索引文件.timeindex就会増加一条索引记录(索引项)。这个值设置越小,索引越密集。值设置越大,索引越稀疏。相对来说,越稠密的索引检索数据更快,但是会消耗更多的存储空间。越的稀疏索引占用存储空间小,但是插入和删除时所需的维护开销也小。Kafka索引的时间复杂度为O(log2n)+O(m),n是索引文件里索引的个数,m为稀疏程度。
第二种索引类型是时间戳索引。时间戳有两种,一种是消息创建的时间戳,一种是消费在Broker追加写入的时间。到底用哪个时间由以下参数控制:
log.message.timestamp.type=CreateTime
默认是创建时间。如果要改成日志追加时间,则修改为LogAppendTime。査看最早的10条时间戳索引:
./kafka-dump-log.sh —files /tmp/kafka-logs/mytopic-0/00000000000000000000.timeindex|head -n 10
那么Kafka如何基于索引快速检索消息?比如我要检索偏移量是10002673的消息。
- 消费的时候是能够确定分区的,所以第一步是找到在哪个segment中。Segment 文件是用base offset命名的,所以可以用二分法很快确定(找到名字不大于10002673 的 最大segment)。
- 这个segment有对应的索引文件,它们是成套出现的。所以现在要在索引文件中根据offset找position。
- 得到position之后,到对应的log文件开始査找offset,和消息的offset进行比较,直到找到消息。
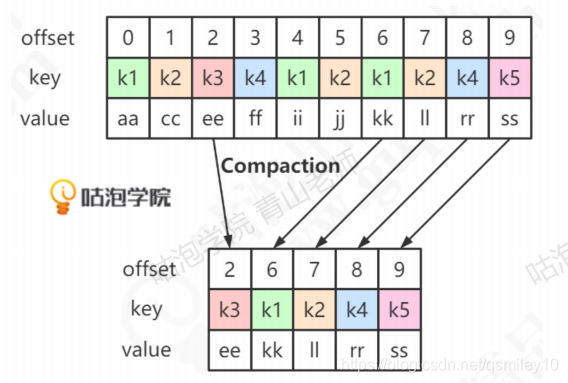
4.2.7 日志清理策略
由于Kafka的日志并没有在消费后马上删除,随着时间的推移,日志越来越多,需要有相应的清理策略来保证系统的健康,日志清理的开关由以下参数控制:
log.cleaner.enable=true
Kafka提供了两种清理方式,分别是删除delete和压缩compact,由以下参数控制:
log.cleanup.policy=delete
日志删除的功能是由定时任务完成的,定时任务运行的时间间隔由以下参数控制:
log.retention.check.interval.ms=300000
删除多久以前的数据由以下参数控制(精度越小优先级越高):
log.retention.hours=168
log.retention.minutes
log.retention.ms
还可以根据保留日志的大小来删除数据,超出该大小则删除最早的数据,由以下参数控制(默认-1代表不限制):
log.retention.bytes=-1
若采取压缩的清理方式,则会根据相同的key进行压缩,当消息的key相同时,只保留最新的value。
4.2.8 Controller选举
当创建添加一个的分区或者分区增加了副本的时候,都要从所有副本中选举一个新的Leader出来。
投票怎么玩?是不是所有的partition副本直接发起投票,开始竞选呢?比如用ZK 实现。
利用ZK怎么实现选举?ZK的什么功能可以感知到节点的变化(增加或者减少)? 或者说,ZK为什么能实现加锁和释放锁?
3个特点:watch机制;节点不允许重复写入;临时节点。
这样实现是比较简单,但是也会存在一定的弊端。如果分区和副本数量过多,所有的副本都直接进行选举的话,一旦某个出现节点的增减,就会造成大量的watch事件被触发,ZK的负载就会过重。
Kafka早期的版本(0.82及以前)就是这样做的,后来换了一种实现方式。
不是所有的repalica都参与leader选举,而是由其中的一个Broker统一来指挥, 这个Broker的角色就叫做Controller(控制器)。
就像Redis Sentinel的架构,执行故障转移的时候,必须要先从所有哨兵中选一个负责做故障转移的节点一样。Kafka也要先从所有Broker中选出唯一的一个Controller,所有的Broker会尝试在zookeeper中创建临时节点/controller,只有一个能创建成功(先到先得)。
如果Controller挂掉了或者网络出现了问题,ZK上的临时节点会消失。其他的Broker通过watch监听到Controller下线的消息后,开始竞选新的Controller。方法跟之前还是一样的,谁先在ZK里面写入一个/controller节点,谁就成为新的Controller。
一个节点成为Controller之后,它肩上的责任也比别人重了几份,正所谓劳力越戴, 责任越大:
- 监听Broker变化。
- 监听Topic变化。
- 监听Partition变化。
- 获取和管理Broker、Topic、Partition的信息。
- 管理Partiontion的主从信息。
4.2.9 分区副本Leader选举
Controller确定以后,开始进行leader选举。副本有3个概念:
- Assigned-Replicas (AR):一个分区的所有副本
- In-Sync Replicas (ISR):一个分区中跟leader数据保持一定程度的同步的副本
- Out-Sync-Replicas (OSR):跟leader副本同步滞后过多的副本
只有ISR有资格参加leader选举。而且这个ISR不是固定不变的,它是一个动态的列表。
如果同步延迟超过30秒,就踢出ISR,进入OSR。如果赶上来了, 就加入ISR。默认情况下,当leader副本发生故障时,只有在ISR集合中的副本才有资格被选举为新的leader。极端情况下,如果ISR为空,则可以允许ISR之外的副本参与选举,由以下参数控制:
unclean.leader.election.enable=true
注意,这种情况下可能造成数据丢失。
那么leader的选举规则是什么呢?它使用一种类似微软的PacificA算法,在这种算法中,默认是让ISR中第一个replica变成leader。比如ISR是1、5、9, 优先让1成为leader。这个跟中国古代皇帝传位是一样的,优先传给皇长子。
4.2.10 主从同步
Leader确定之后,客户端的读写只能操作leader节点。follower需要向leader同步数据。不同的raplica的offset是不一样的,同步到底怎么同步呢?
首先需要认识几个概念:
LEO (Log End Offset): 下一条等待写入的消息的offset (最新的offset + 1),图中分别是9, 8, 6。
HW (Hign Watermark): ISR中最小的LEO。Leader会管理所有ISR中最小的 LEO作为HW,目前是6。
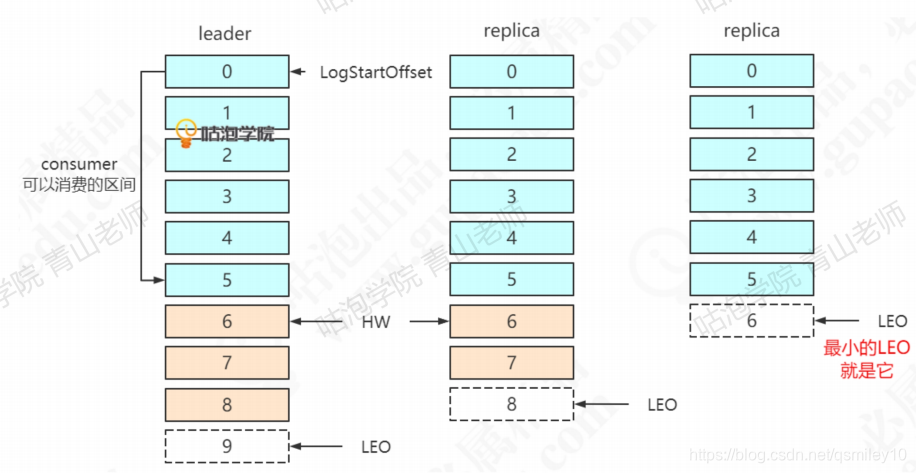
consumer最多只能消费到HW之前的位置(消费到offset 5的消息)。也就是说: 其他的副本没有同步过去的消息,是不能被消费的。
有了这两个offset之后,再来看看消息怎么同步:
followerl同步了1条消息,follower2同步了2条消息。此时HW推进了2,变成8。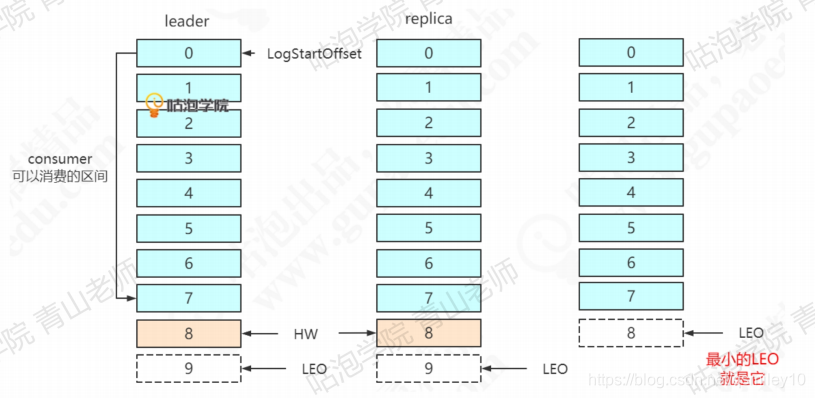
followerl同步了0条消息,follower2同步了1条消息。此时HW推进了1,变成9。LEO和HW重叠,所有的消息都可以消费了。
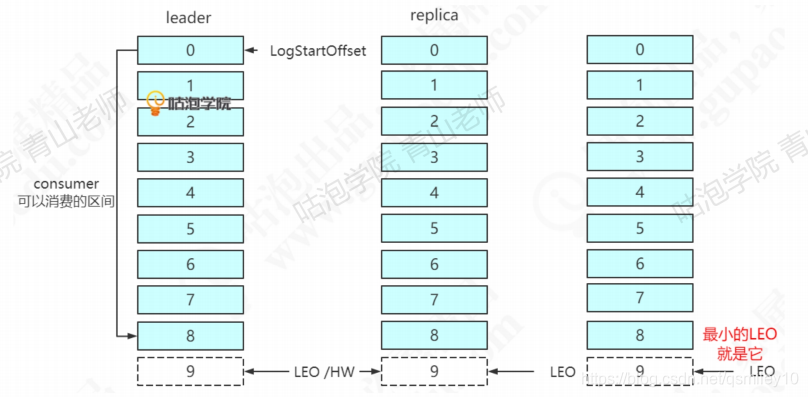
这里,我们关注一下,从节点怎么跟主节点保持同步?
- follower节点会向Leader发送一个fetch请求,leader向follower发送数据后,既需要更新follower的LEO。
- follower接收到数据响应后,依次写入消息并且更新LEO。
- leader 更新 HW (ISR 最小的 LEO)。
kafka设计了独特的ISR复制,可以在保障数据一致性情况下又可提供高吞吐量。
4.2.11 replica故障处理
4.2.11.1 follower故障
首先follower发生故障,会被先踢出ISR。follower恢复之后,从哪里开始同步数据呢?假设第1个replica宕机(中间这个)。
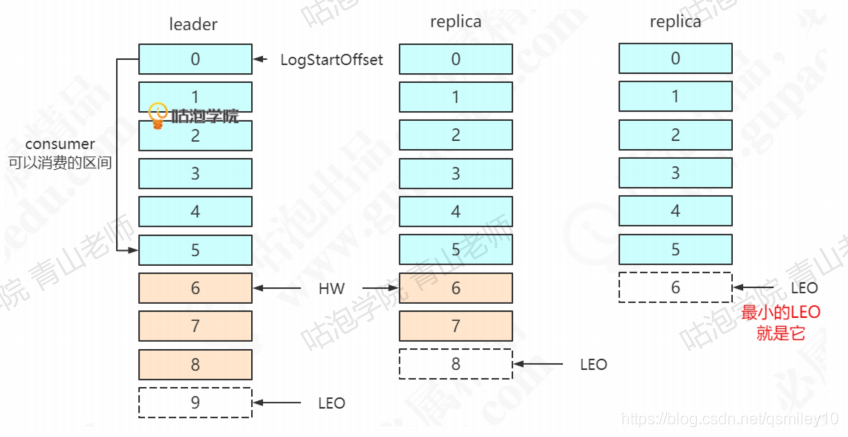
恢复以后,首先根据之前记录的HW (6),把高于HW的消息截掉(6、7)。然 后向leader同步消息。追上leader之后(30秒),重新加入ISR。
4.2.11.2 leader故障
假设图中leader发生故障。首先选一个leader。因为replica 1 (中间这个)优先,它成为leader。为了保证数据一致,其他的follower需要把高于HW的消息截取掉(这里没有消息需要截取)。然后replica2同步数据。注意:这种机制只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复。
4.2.11.3 上面这两种方式没有问题吗?(全文重点!!!)
实际上,副本同步机制并没有上面说的那么简单。假设有A(leader)、B两个副本——
作为leader,A还会维护每个副本的远程LEO值remoteLEO;
作为follower,B会定时发送fetch请求给A拉取数据,在fetch时将自己当前的LEO和HW发送给A。
1)初始化状态时:
LEO(A)=0, HW(A)=0,remoteLEO=0;
LEO(B)=0,HW(B)=0;
2)当生产者发送一条数据m1时:
LEO(A)=1, HW(A)=0,remoteLEO=0;[m1]
LEO(B)=0,HW(B)=0;
3)B向A发起fetch请求,发送自己当前的LEO给A:
LEO(A)=1, HW(A)=0,remoteLEO=0;[m1]
LEO(B)=0,HW(B)=0;
4)A根据B发送的LEO,更新remoteLEO=0,更新HW(A)=min(LEO(A), remoteLEO(B))=0,同时将HW(A)和未同步的数据m1发送给B:
LEO(A)=1, HW(A)=0,remoteLEO=0;[m1]
LEO(B)=0,HW(B)=0;
5)B根据A返回的HW(A),写入数据m1,同时更新LEO(B)=1,HW(B)=min(HW(A), LEO(B))=0,
LEO(A)=1, HW(A)=0,remoteLEO=0;[m1]
LEO(B)=1,HW(B)=0;[m1]
6)B向A发起第二次fetch请求,发送自己当前的LEO(B)=1:
LEO(A)=1, HW(A)=0,remoteLEO=0;[m1]
LEO(B)=1,HW(B)=0;[m1]
7)此时A更新remoteLEO=1,HW(A)=min(LEO(A), remoteLEO(B))=1,同时返回HW给B:
LEO(A)=1, HW(A)=1,remoteLEO=1;[m1]
LEO(B)=1,HW(B)=0;[m1]
8)B根据A返回的HW(A),更新HW(B)=min(HW(A), LEO(B))=1,
LEO(A)=1, HW(A)=1,remoteLEO=1;[m1]
LEO(B)=1,HW(B)=1;[m1]
这是一轮常规的数据同步,设想一下,当leader或者follower出现故障时,会导致什么问题?我们知道可以通过acks来控制消息的可靠性,那么当acks=-1(all)的时候是否数据一定不会丢失?
首先,我们要明白数据丢失的概念,一定是在leader返回ack但是数据不存在的情况下才叫数据丢失,如果leader没有返回ack,也就是说生产者知道消息没发送成功的话,不算数据丢失。那么假设acks=-1的话,实际上leader是在步骤7)执行完毕后就返回ack给生产者。在这个前提下我们分析几个场景。
场景一:
假设ISR中只有一个leader副本,且成功写入数据。此时leader挂掉,若参数设置允许OSR中的副本抢占leader的话,可能导致数据丢失。
这种场景系统也无法处理,所以Kafka交给用户自行选择,若unclean.leader.election.enable=true则无法保证消息的可靠性,若unclean.leader.election.enable=false则无法保证系统的效率和可用性。
场景二:
在执行完步骤7)之后B挂掉了,而当B重启之后(注意此时HW(B)=0),根据4.2.11.1的做法,会先将超出HW(B)的消息m1抛弃,重新从A拉取数据。更极端的情况下,此时A恰好也挂掉,这时候B就会通过选举成为leader。而A重启之后成为follower,会通过截取m1的方式与leader保持同步。至此,消息m1丢失。更严重的是,若A重启之前,B又接收了生产者发送的新的数据m2,那么A重启后由于HW(A)=1,将不会从B拉取到消息m2,结果如下:
LEO(A)=1, HW(A)=1,remoteLEO=1;[m1]
LEO(B)=1,HW(B)=1;[m2]
鉴于场景2,Kafka在0.11版本后增加了一个leader-epoch-checkpoint的概念,以文件的形式保存在日志目录下,当一个新的leader在写入第一条消息时,会在文件中记录一条信息,包括leader年代(即leader更换次数)epoch和当前leader写入的第一个offset。
举个例子,当这个分区写入第一条消息时,leader-epoch-checkpoint文件中会记录一条信息(0 0),在写入50条消息之后leader挂掉并发生选举,leader-epoch-checkpoint会增加一条记录(1 50)。
有了这种机制,当follower重启之后就不需要直接丢弃HW之后的数据,而是会发起一次请求对比leader中的epoch与自身的epoch:
若epoch相等则只丢弃自身LEO大于leader的LEO的部分(即,若自身LEO不大于leader的LEO则不进行截取,与原来直接截取到HW有所差别);
若epoch不相等(自身小于leader的LEO)则将自身LEO与leader-epoch-checkpoint中epoch大于自身epoch的最小值的LEO相比较,丢弃自身LEO大于该LEO的数据。
这部分有点绕,以刚才的例子说明,假设步骤7)执行完毕后B重启,此时:
若B重启期间未发生leader选举,则A的leader-epoch-checkpoint文件与B一致,都是(0 0),即epoch(A)=epoch(B),此时LEO(B)=LEO(A)=1,无需截取。
若B重启期间发生过leader选举(假设存在副本C、D),则leader-epoch-checkpoint文件存在多条记录(0 0),(1 10),(2 50)(又发生两次选举),此时B的epoch小于2,会将B的LEO与10比较(大于epoch(B)的最小epoch是1),同样不会丢弃数据。
以上,就是0.11版本Kafka的数据同步方案。
4.3 Kafka消费者原理
4.3.1 Offset的维护
4.3.1.1 Offset的存储
我们知道在partition中,消息是不会删除的,所以才可以追加写入,写入的消息连续有序的。这种特性决定了 kafka可以消费历史消息,而且按照消息的顺序消费指定消息,而不是只能消费队头的消息。正常情况下,我们希望消费没有被消费过的数据,而且是从最先发送(序号小的) 的开始消费(这样才是有序和公平的)。
那么对于一个partition,消费者组怎么才能做到接着上次消费的位置(offset)继续消费呢?肯定要把这个对应关系保存起来,下次消费的时候查找一下。
首先这个对应关系确实是可以查看的。比如消费者组gp-assign-group-1和 ass5part (5个分区)的partition的偏移量关系,可使用如下命令査看:
./kafka-consumer-groups.sh “bootstrap-server 192.168.44.161:9093,192.168.44.161:9094,192.168.44.161:9095 —describe —group gp-assign-group-1
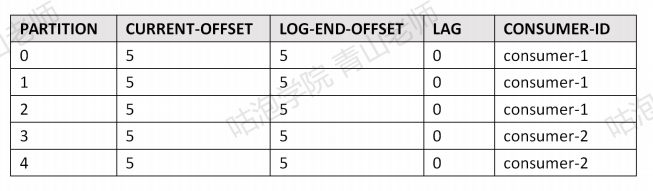
- CURRENT-OFFSET指的是下一个未使用的offset。
- LEO , Log End Offset:下一条等待写入的消息的offset (最新的offset + 1)
- LAG是延迟量
注意:这不是表示一个消费者和一个Topic的关系,而是一个consumer group和topic中的一个partition的关系(offset在partition中连续编号而不是全局连续编号)。
那么这个对应关系到底是保存在哪里的呢?
首先肯定是不可能放在消费者本地的。因为所有的消费者都可以使用这个consumer group id,放在本地是做不到统一维护的,肯定要放到服务端。
Kafka早期的版本把消费者组和partition的offset直接维护在ZK中,但是读写的性能消耗太大了。后来就放在一个特殊的topic中,名字叫—consumer_offsets,默认有 50 个分区(offsets.topic.num.partitions 默认是 50),每个分区默认一个replication。
./kafka・topics・sh —topic consumer_offsets —describe —zookeeper localhost:2181
那么这样一个特殊的Topic怎么存储消费者组gp-assign-group-1对于分区的偏移量的?Topic里面是可以存放对象类型的value的(经过序列化和反序列化)。这个Topic 里面主要存储两种对象:
GroupMetadata:保存了消费者组中各个消费者的信息(每个消费者有编号)。
OffsetAndMetadata:保存了消费者组和各个partition的offset位移信息元数据。
./kafka-console-consumer.sh —topic consumer_offsets --bootstrap-server 192.168.44.161:9093,192.168.44.161:9094,192.168.44.161:9095 -formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" —from-beginning

怎么知道一个consumer group的offset会放在这个特殊的Topic的哪个分区呢? 可以通过哈希取模计算得到:
Math.abs("gp-assign-group-1".hashCode()) % 50;
4.3.1.2 如果找不到Offset
如果增加了一个新的消费者组去消费—个topic的某个partion,没有offset的记录,这个时候应该从哪里开始消费呢? 由以下参数控制:
auto.offset.reset=latest
latest: 从最新的消息(最后发送的)开始消费。
earliest: 从最早的(最先发送的)消息开始消费。可以消费到历史消息。
none: 如果consumer group在服务端找不到offset会报错。
4.3.1.3 Offset的更新
我们知道消费者组的offset是保存在Broker的,但是是由消费者上报给 Broker的。并不是消费者组消费了消息,Offset就会更新,消费者必须要有一个commit (提交)的动作。消费者可以自动提交或者手动提交。由以下参数控制:
enable.auto.commit=true
另外还可以使用一个参数来控制自动提交的频率:
auto.commit.interval.ms=5000
如果我们要在消费完消息做完业务逻辑处理之后才commit,就要把这个值改成 false。如果是false,消费者就必须要调用一个方法让Broker更新offset。有两种方式:
consumer.commitSync()手动同步提交。
consumer.commitAsync()手动异步提交。
如果不提交或者提交失败,Broker的Offset不会更新,消费者下次消费的时候会受到重复消息。
4.3.2 消费者和消费策略
4.3.2.1 分区分配策略
我们已经知道,在同一个消费者组中,一个分区只能被一个消费者消费。所以当消费者数量大于分区数量时,多余的消费者是无法消费消息的。那么如果分区数大于消费者数呢,Kafka又是如何分配的?
为了保证系统最大的利用率,Kafka的分配策略一定会遵循一个最基本的原则——平均分配,简单理解,不会有任意两个消费者消费的分区数差大于1。在此基础上,Kafka有3种分区分配方式。以8个partition分配给3个consumer为例:
1)Range(范围)
顾名思义,无需解释。
C1:P0 P1 P2
C2:P3 P4 P5
C3:P6 P7
2)RoundRobin(轮询)
顾名思义,无需解释。
C1:P0 P3 P6
C2:P1 P4 P7
C3:P2 P5
3)sticky(粘滞)
粘滞的分配策略较为复杂,它的核心思想是在分区重新分配时保证最小的移动(类似Redis的一致性hash思想,实现方式不同)。
第一次分配类似轮询,结果如下:
C1:P0 P3 P6
C2:P1 P4 P7
C3:P2 P5
假设此时C2挂掉:
若按照RoundRobin,结果如下:
C1:P0 P2 P4 P6
C3:P1 P3 P5 P7
sticky结果如下(尽量保证P0 P3 P6 P2 P5不动):
C1:P0 P3 P6 P1
C3:P2 P5 P4 P7
我们知道在分区分配时是会造成性能损耗的,若采用sticky分配策略可以尽可能减少性能损耗。该思想与Redis的一致性Hash是类似的,只是实现方式不同。
4.3.2.2 分区重分配Rebalance
那么什么时候会触发分区重分配Rebalance呢?显然有两种情况,一种是消费者数量发生变化,一种是分区数量发生变化。Rebalance过程如下:
- 确定协调者coordinator,通常由集群中负载最小的Broker承担。
- 所有consumer向coordinator发送join group请求,确认自己是该组成员。
- coordinator在所有consumer中确定leader(通常是第一个)并由leader确定分区分配结果。
- coordinator向所有consumer发送分区分配结果。
4.3.3 Kafka为什么这么快?
4.3.3.1 顺序读写
首先我们需要了解随机I/O和顺序I/O。
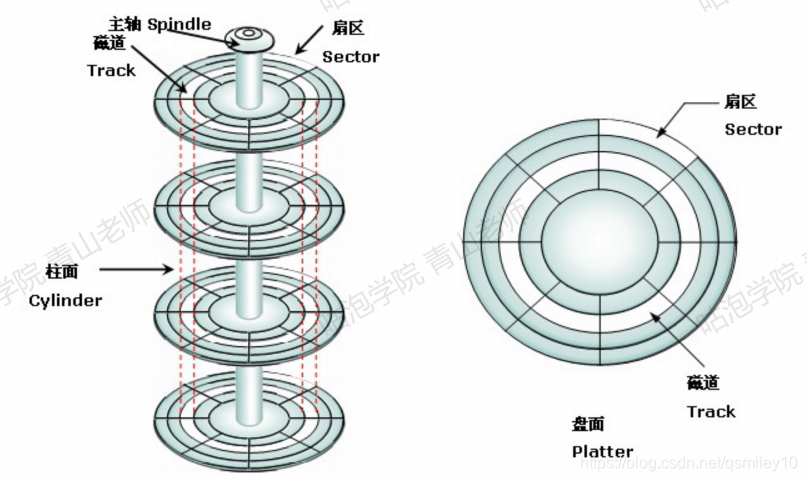
磁盘的构造如图。磁盘的盘片不停地旋转,磁头会在磁盘表面画出一个圆形轨迹,这个就叫磁道。从内到位半径不同有很多磁道。然后又用半径线,把磁道分割成了扇区(两根射线之内的扇区组成扇面)。如果要读写数据, 必须找到数据对应的扇区,这个过程就叫寻址。
随机I/O:读写的多条数据在磁盘上是分散的,寻址会很耗时。
顺序I/O:读写的数据在磁盘上是集中的,不需要重复寻址的过程。
Kafka的message是不断追加到本地磁盘文件末尾的,而不是随机的写入,这使得 Kafka写入吞吐量得到了显著提升。
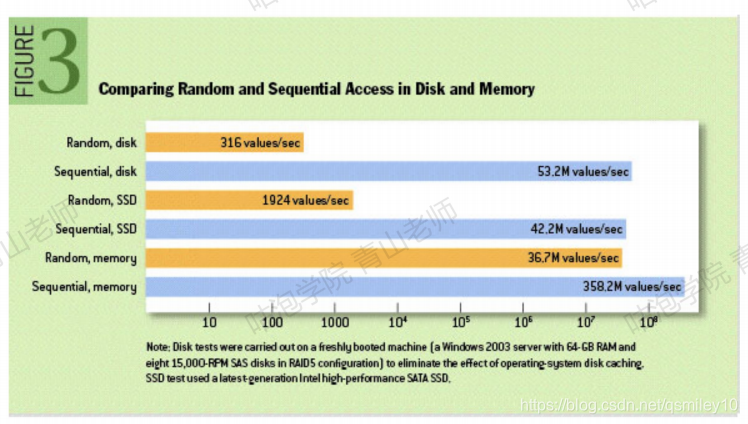
顺序IO到底有多快呢?下图显示,在一定条件下测试,磁盘的顺序读写可以达到53.2M每秒,比内存的随机读写还要快。
4.3.3.2 索引
我们在写入日志的时候会建立关于Offset和时间的稀疏索引,提升了查找效率,这个上面已经提到过了。
4.3.3.3 批量读写
Kafka无论是生产者发送消息还是消费者消费消息都是批量操作的,大大提高读写性能。
4.3.3.4 零拷贝
首先需要了解两个名词。
第一个是操作系统虚拟内存的内核空间和用户空间。操作系统的虚拟内存分成了两块,一部分是内核空间,一部分是用户空间。这样就可以避免用户进程直接操作内核,保证内核安全。进程在内核空间可以执行任意命令,调用系统的一切资源;在用户空间必须要通过
—些系统接口才能向内核发出指令。如果用户要从磁盘读取数据(比如kafka消费消息),必须先把数据从磁盘拷贝到内核缓冲区,然后在从内核缓冲区到用户缓冲区,最后才能返回给用户。

第二个是DMA拷贝。没有DMA技术的时候,拷贝数据的事情需要CPU亲自去做, 这个时候它没法干其他的事情,如果传输的数据量大那就有问题了。DMA技术叫做直接内存访问(Direct Memory Access),其实可以理解为CPU给 自己找了一个小弟帮它做数据搬运的事情。在进行I/O设备和内存的数据传输的时候, 数据搬运的工作全部交给DMA控制器,解放了 CPU的双手。
理解了这两个东西之后,我们来看下传统的I/O模型:
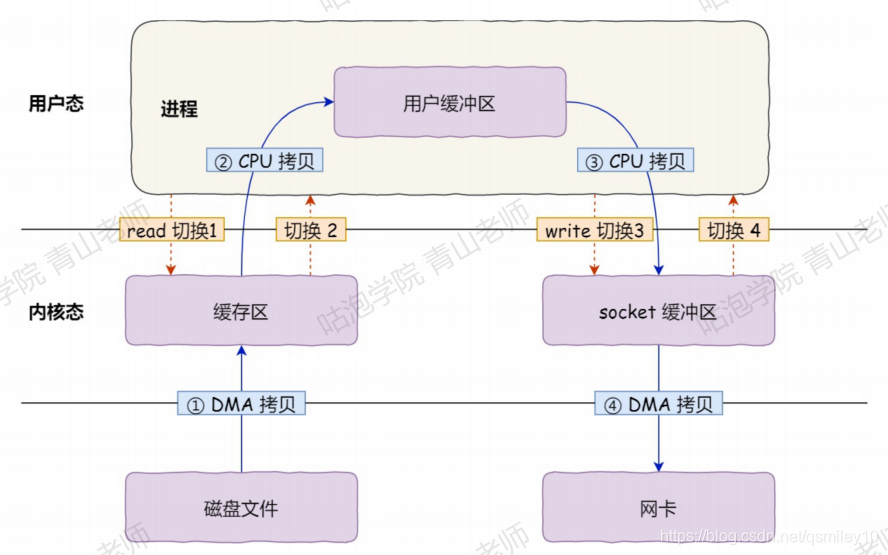
比如kafka要消费消息,比如要先把数据从磁盘拷贝到内核缓冲区,然后拷贝到用户缓冲区,再拷贝到socket缓冲区,再拷贝到网卡设备。这里面发生了 4次用户态和内核态的切换和4次数据拷贝,2次系统函数的调用(read、write),这个过程是非常耗费时间的。怎么优化呢?
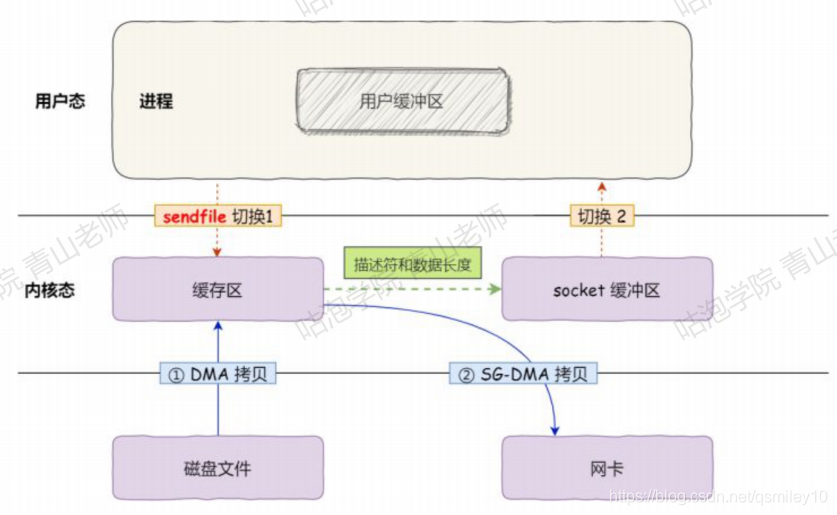
在Linux操作系统里面提供了一个sendfile函数(并不是所有操作系统都支持sendfile),可以实现"零拷贝"。这个时候就不需要经过用户缓冲区了,直接把数据拷贝到网卡(这里画的是支持SG-DMA拷贝的情况)。因为这个只有DMA拷贝,没有CPU拷贝,所以叫做”零拷贝”。零拷贝至少可以提高一倍的性能。
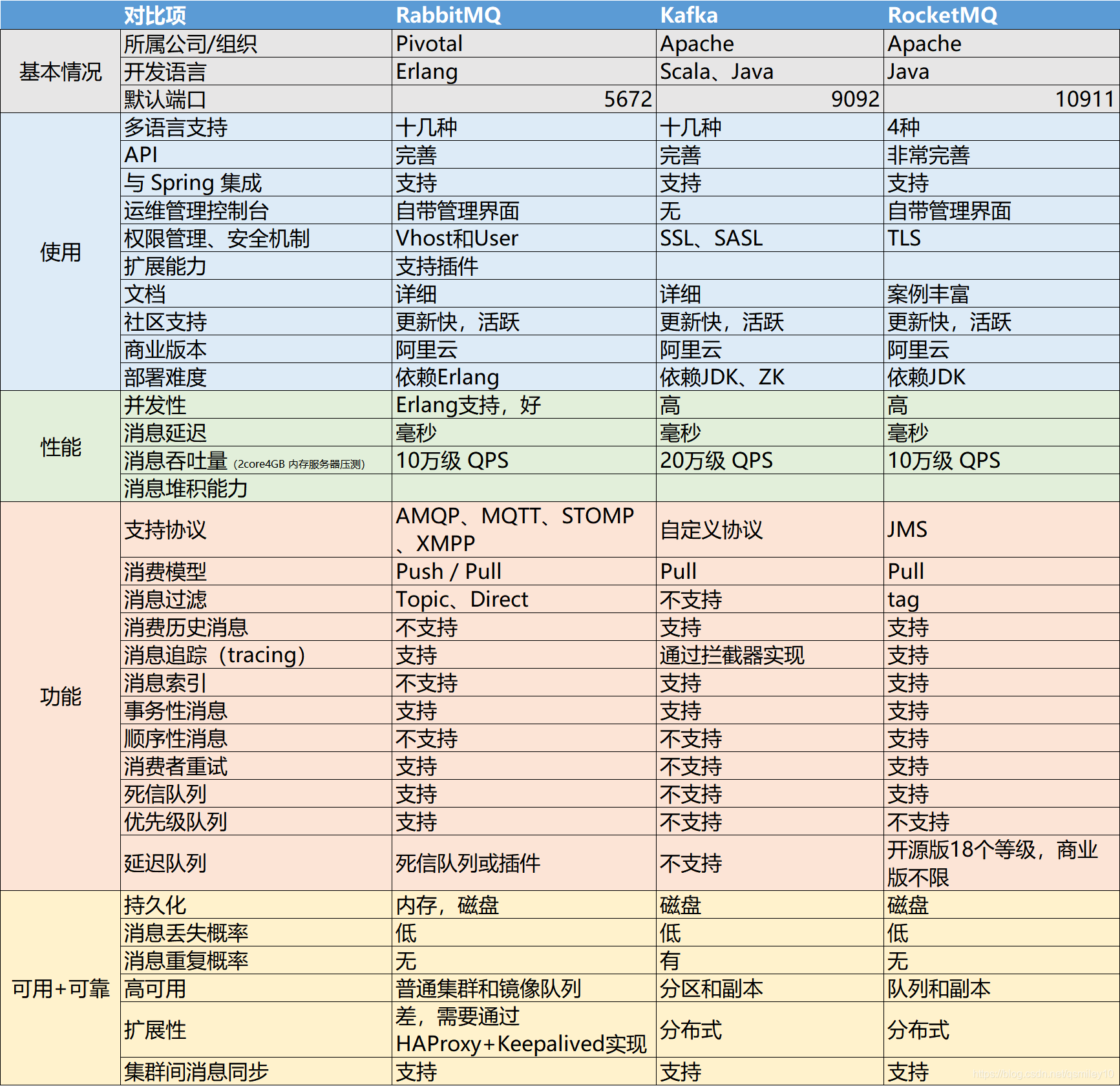
5、MQ选型:Kafka对比RabbitMQ/RocketMQ
5.1 Kafka特性
- 高吞吐、低延迟: kakfa最大的特点就是收发消息非常快,kafka每秒可以处理几十万条消息,它的最低延迟只有几毫秒;
- 高伸缩性: 如果可以通过增加分区partition来实现扩容。不同的分区可以在不同的Broker中。通过ZK来管理Broker实现扩展,ZK管理Consumer可以实现负载;
- 持久性、可靠性: Kafka能够允许数据的持久化存储,消息被持久化到磁盘,并支持数据备份防止数据丢失;
- 容错性: 允许集群中的节点失败,某个节点宕机,Kafka集群能够正常工作;
- 高并发: 支持数千个客户端同时读写。
5.2 Kafka对比RabbitMQ
- 产品侧重:kafka:流式消息处理、消息引擎;RabbitMQ:消息代理。
- 性能:kafka有更高的吞吐量。RabbitMQ主要是push, kafka只有pull。
- 消息顺序:分区里面的消息是有序的,同一个consumer group里面的一个消费者只能消费一个partition,能保证消息的顺序性。
- 消息的路由和分发:RabbitMQ更加灵活。
- 延迟消息、死信队列:RabbitMQ支持。
- 消息的留存:kafka消费完之后消息会留存,RabbitMQ消费完就会删除。Kafka可以设置retention,清理消息。
优先选择RabbitMQ的情况:
- 高级灵活的路由规则;
- 消息时序控制(控制消息过期或者消息延迟);
- 高级的容错处理能力,在消费者更有可能处理消息不成功的情景中(瞬时或者持久);
- 更简单的消费者实现。
优先选择Kafka的情况:
- 严格的消息顺序;
- 延长消息留存时间,包括过去消息重放的可能;
- 传统解决方案无法满足的高伸缩能力。
5.3 MQ选型分析
6、Kafka参数配置说明
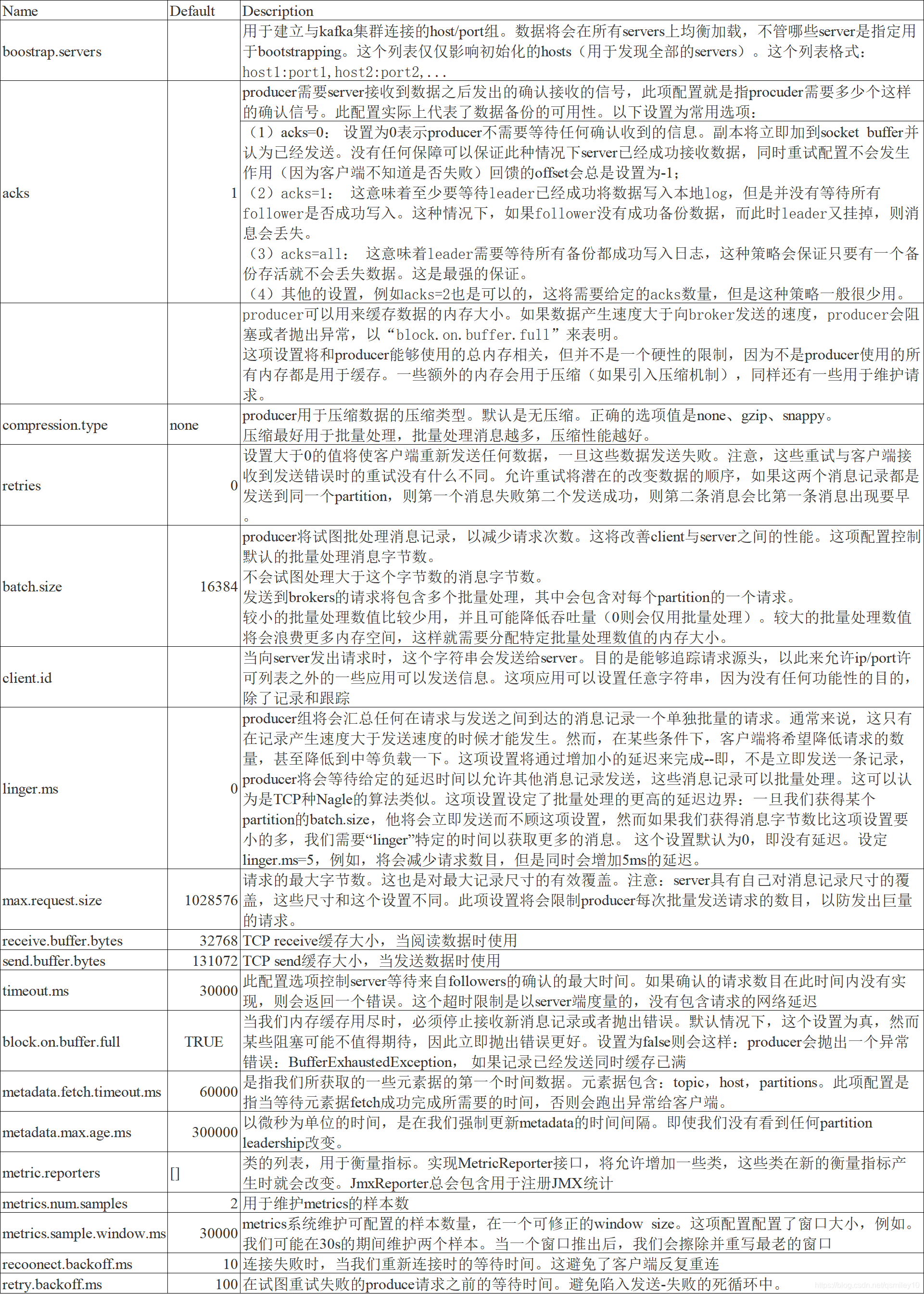
6.1 Kafka生产者参数配置
6.2 Kafka服务端参数配置

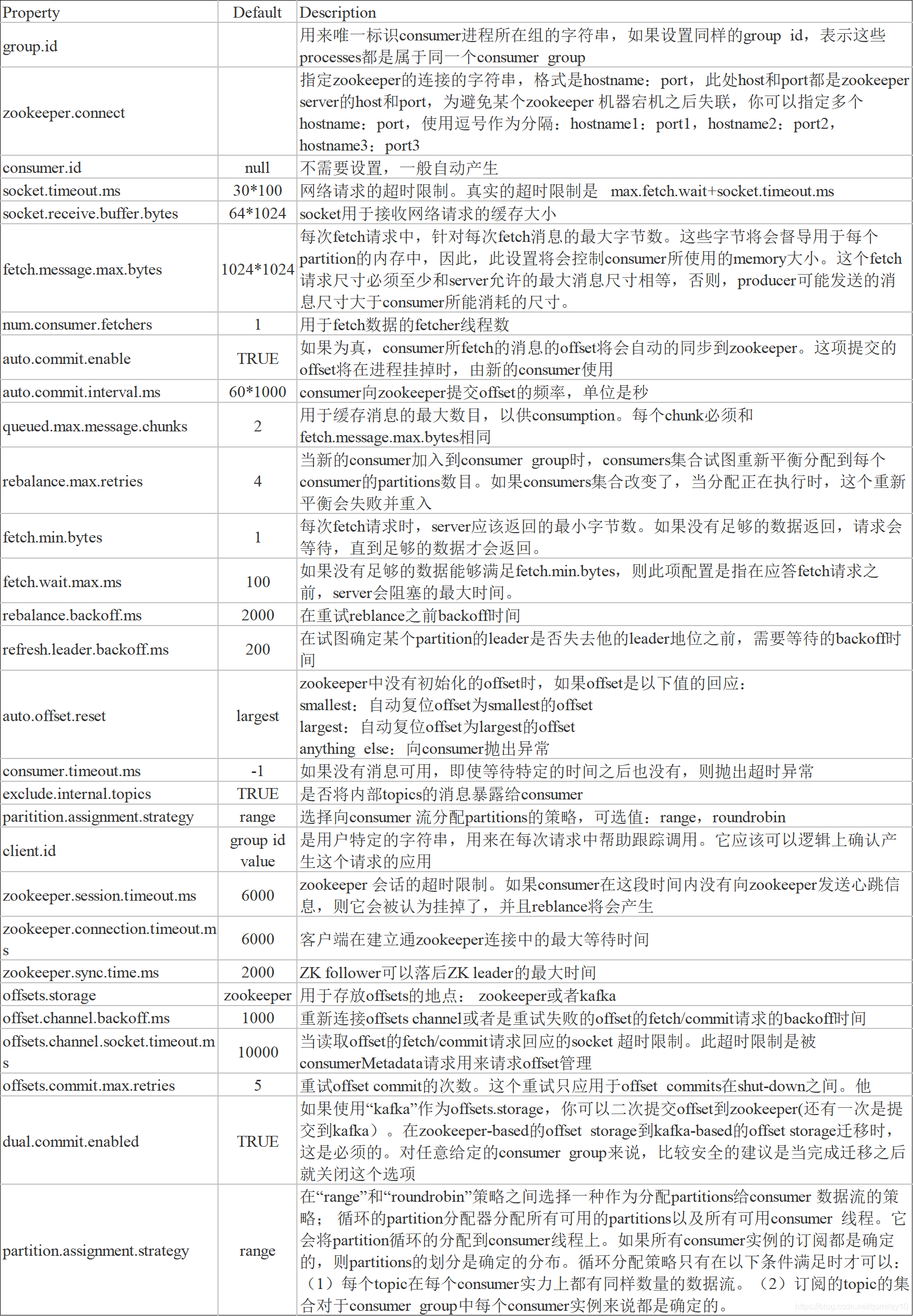
6.3 Kafka消费者参数配置
6.4 Kafka增加数据可靠性的配置
- 设置acks = all。acks是Producer的一个参数,代表已提交消息的定义。如果设置成all,则表明所有Broker都要接收到消息,该消息才算是”已提交”。
- 设置retries为一个较大的值。同样是Producer的参数。当出现网络抖动时,消息发送可能会失败,此时配置了retries的Producer能够自动重试发送消息,尽量避免消息丢失。
- 设置 unclean.leader.election.enable=false。
- 设置replication.factor >= 3。需要三个以上的副本。
- 设置min.insync.replicas > 1。Broker端参数,控制消息至少要被写入到多少个副本才算是"已提交"。设置成大于1可以提升消息持久性。在生产环境中不要使用默认值1。确保replication.factor > min.insync.replicas。如果两者相等,那么只要有 —个副本离线整个分区就无法正常工作了。推荐设置成replication.factor = min.insync.replicas + 1。
- 确保消息消费完成再提交。Consumer端有个参数enable.auto.commit,最好设置成false,并自己来处理offset的提交更新。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)