【游戏开发岗面经总结6】(unity优化总结,全局变量和全局静态变量,NULL和nullptr的区别,拷贝构造函数和赋值运算符的区别,深浅拷贝,哈希碰撞,TOPK问题,野指针问题,堆和栈,内存泄漏)
unity优化UGUIUGUI的动静划分 尽量避免频繁增加和删除UI对象(降低界面更新频率)合理增加UI的深度以及不要图文交叉mask和Raycast Target属性尽量少的使用合理使用批处理代码尽可能少的使用foreach GetComponent尽量将string换成StringBuilder,多使用内建数组 如vector3.zero等代替vector3(0,0,0)udp可靠化确认机制,
unity优化
UGUI
UGUI的动静划分 尽量避免频繁增加和删除UI对象(降低界面更新频率)
合理增加UI的深度以及不要图文交叉
mask和Raycast Target属性尽量少的使用
合理使用批处理
可以用Image实现的功能尽量少的使用RawImage
使用图集可以减少DrawCall数量,从而达到优化的效果(批处理)我有一篇博文专门介绍图集的
代码
多使用内建数组 如vector3.zero等代替vector3(0,0,0)
减少对Transform的position和rotation的访问次数
尽可能少的使用foreach GetComponent
尽量将string换成StringBuilder,
stringbuilder与string比较你就会明白了
原因
String是固定不变的,在进行字符串连接的时候是新建一个字符串,进行连接后,最后赋值,
如果对String赋值多次,就会在内存中保存多个这个对象的副本,浪费系统资源
StringBuilder是可变的,不用生成中间对象,拼接字符串比较多,或字符串的长度比较长时有较高的效率。
StringBuilder的内存空间不够也要扩容,如果分配的空间远远大于需要量,也很浪费
所以,初始化 StringBuilder的时候最好根据需要设置容量,避免浪费
开发
Transform的子物体不应该过多
减少例子系统的play()的调用次数(我们可以修改例子系统的周期变长,以至于整个游戏中不用重复调用play方法 )
使用异步加载机制
使用对象池
程序中要尽可能多的重复使用材质(批处理)
注意静态批处理的内存的问题
全局变量和全局静态变量区别
如果程序是由一个源文件构成的,全局变量和全局静态变量没有区别
如果是由多个源文件构成的,全局静态变量对组成该程序的其他源文件无效
而全局变量对于其他源文件有效
NULL和nullptr的区别
nullptr是c++11的新特性,他是为了解决NULL表示空指针在c++中具有二义性的问题
在c++中NULL实际上为0
因为c++中不能将void*类型的指针隐式转换成为其他类型的指针,所以为了结果空指针的表示问题
c++引入了0来表示空指针
NULL代替0表示空指针在函数重载时会出现问题
void fun(int i) {
cout << "函数参数为int类型" << endl;
}
void fun(void* i) {
cout << "函数参数为vodi*类型" << endl;
}
int main() {
fun(NULL);
fun(nullptr);
return 0;
}
我们的理想情况是输出两次函数参数为void*类型
但是实际结果如下
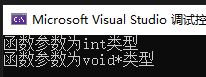
我们本来向用NULL代替空指针,但是将NULL输入到函数中 他却选择了int为参数的版本,
所以NULL在c++中是存在二义性的
所以为了解决这个问题c++11特意引入了nullptr来替代空指针
从上边例子可以看到 nullptr选择了void*为参数的版本
总之:
NULL在c++中就是0,因为c++中void*类型不允许转换为其他类型
而nullptr可以在任何情况下都表示空指针
拷贝构造函数和赋值运算符的区别(深浅拷贝)
在默认情况下,用户没有定义,也没有显式删除的情况下,编译器自动隐式生成一个拷贝构造函数和赋值运算符
系统内置的拷贝运算符和赋值运算符存在缺陷:重载“=”的问题
当存在指针成员的时候,进行拷贝构造函数的操作,会使两个对象的指针成员指向同一处空间(new出来的空间)
析构的时候,同一处空间会释放两次(指针悬挂问题)
当存在指针成员的时候,进行对象赋值运算,相当于右值完全不变的赋值给左值,这个时候不仅仅使得两个对象的指针成员指向同一处空间
析构的时候 也会对同一处空间析构两次,同时左值原来的指针成员指向的空间没有被释放 存在内存泄漏的问题
为什么建议拷贝构造函数的参数是const class&t
为什么是引用?
拷贝构造函数是用来复制对象的,使用这个对象的实例来初始化这个对象的一个实例
如果用值传递的方法,将会涉及到实参传递给形参 需要对形参进行拷贝构造 但是我们正在写拷贝构造函数 产生矛盾
为什么是const?
因为一些函数返回对象类型,这些临时对象默认都是const class类型的
如果拷贝构造函数形参是class&类型 那么就会产生const class和class&之间的赋值 是错误的
浅拷贝与深拷贝
拷贝构造函数和赋值运算符都会遇到这个问题
所谓浅拷贝,就是说编译器提供默认的拷贝构造函数和赋值运算符重载函数
仅仅将对象a中的各个数据成员的值拷贝给b中对应的数据成员
不做其他的事情
我把浅拷贝比作一个不爱思考的懒汉,把深拷贝比作一个爱思考的严谨的人
对于懒汉来说老板给他分配了任务,但是它尽量向少做一些事情,所以很多东西就是只能看到表面
不去思考细节
int a ;
对于懒汉来说他很直白看到了int a;然后就拷贝了a就不管其他了
反正我完成了任务 其他我不管
但是一旦涉及指针 就会出现问题
int * p;
懒汉仍然只能看到表面的东西,于是直接去拷贝
对于指针或者引用来说 懒汉拷贝之后的物体的指针也和原来的指针指向同一个对象
所以虽然目的是得到一个完美的克隆体 但是发现克隆体和原来之间还是存在一些关系
没有完美的分离
如果原来的物体被销毁,现在拷贝的物体还存在,那么这个时候拷贝之后的指针就是一个悬挂指针
指向了不存在的物体,如果你继续访问的话 不知道会发生什么
对于聪明的人来说 他会再去开辟一段内存 然后用指针指向它,将原来的值赋值上去
这样才会使得克隆体和原来的真正的分离
所以我们来总结一下
对于爱思考的人来说,付出的经历更多,努力更大,但是也是值得的,
而对于懒汉来说 表面上看起来没有问题,一旦产生一些考验 原形毕露
对于拷贝构造函数和赋值运算符的区别
拷贝构造函数是创建一个不存在的对象
赋值构造函数是将一个对象赋值给另一个已经存在的对象。
哈希碰撞
上次面试面试官问到了我这个问题
当时的我还没有看过这个问题 但是我之前看过关于哈希表的底层 是数组和链表或者是红黑树实现的
所以面试的时候回答出来了拉链法
拉链法
将所有的关键字为同义词的记录存储在同一个线性链表中
链地址法通常用于插入和删除的情况
优点:
处理冲突简单,无堆积现象,非同义词绝对不会产生冲突 因此查找平均长度较短
拉链法中各个链表的节点是动态申请的,更适合造表之前无法确定表长的情况
再哈希法
发生冲突的时候,使用第二个,第三个哈希函数计算地址,直至无冲突产生
不易产生聚集 但是增加了计算时间
哈希表在什么情况下效率比较低
哈希表扩容的时候,会把所有的元素重新哈希一遍,这个时候效率比较低
TOPK问题
这个问题几乎在我每次面试都会问到 牛客上好多大佬也不止一次的写过这个问题
快排思想:
利用快排的思想,我们知道快排是随机寻找标识,然后用此标识进行排序
我们进行降序的方式,第一次排序之后 就能获得该值在序列中的位置 理想状态 该值正好处于K的位置
我们返回这个位置的左边的值就行
如果返回的标志在数组的位置大于k 那么topk都在左边
我们在左边的元素也有不属于topk的元素 所以要在右边也进行排序 直至符合条件
如果标志小于k 那么左边都是topk的成员 和上边同理 但是右边也存在 所以一直这样找下去
int findpos(vector<int>& nums, int left, int right) {
int t = nums[left];
while (left < right) {
while (left < right && nums[right] <= t) {
right--;
}
nums[left] = nums[right];
while (left < right && nums[left] >= t) {
left++;
}
nums[right] = nums[left];
}
nums[left] = t;
return left;
}
void quick_sort(vector<int>& nums, int left, int right,int k) {
int pos = findpos(nums, left, right);
int leftlen = pos - left + 1;
if (leftlen == k) {
return;
}
else if (leftlen < k) {
quick_sort(nums, pos + 1, right, k - leftlen);
}
else {
quick_sort(nums, left, pos - 1, k);
}
}
int main() {
vector<int> nums = {1,5,6,9,86,36,22,10,33,22,2,56};
int k = 4;//取前几个
quick_sort(nums, 0, nums.size() - 1,k);
for (auto t : nums) {
cout << t << " ";
}
}
堆排思想:
上边的复杂度是O(nlog₂n) 当n极大的时候 内存会受不了
题目要求的是前k个 所以没必要所有都排序 做无用功
我们可以将前K个数字建立为一个最小(大)堆,如果是要取最大的K个数,则在后续遍历中,将数字与最小堆的堆顶数字进行比较,若比它大,则进行替换,然后再重新调整为最大堆。整个过程直至所有数字遍历完为止。时间复杂度为O(n*log₂K),空间复杂度为K。
野指针问题
成因:
1.指针没有初始化,任何指针变量刚刚创建不会成为NULL指针,默认值是随机的,可能指向任意位置
所以,指针变量在创建的最开始就应该及时对其初始化,将其设置为NULL,或者让其指向一块合法的内存
2.指针被free或者delete之后,仅仅释放了指针所指的内存,并没有将指针置为NULL 当后边用到它的时候,仍然是合法的
3.指针超越了变量所在作用域
避免:
1.用malloc申请内存之后,立即检查指针是否为NULL,方式使用值为NULL的指针
2.动态申请操作必须和释放操作匹配,防止内存泄漏和多次释放
3.防止数组越界,考虑使用柔性数组
4.free指针之后必须立即赋值为NULL
危害:
指向不可访问的一段地址 触发段错误
指向可用的,但是正在被使用的空间,如果此时空间解引用的时候,对其修改或者释放
但是这段空间正在被使用,这回使得程序崩溃,数据可能被破坏
堆和栈的区别以及联系
首先就是内存五大区
管理方式 栈由编译器自动管理,无需手动控制,堆由程序员控制释放和申请
空间大小堆不是连续的区域 空间比较大,且灵活 栈是连续的一段空间,且大小是预定好的
碎片问题:
对于堆 如果大量的new、delete会产生大量的碎片,使得程序效率降低
对于栈,他和数据结构中的栈类似 不会产生内存碎片
分配方式:
堆是动态分配的没有静态分配的 ,栈可以动态可以静态分配 静态通过编译器完成
效率: 堆的机制很复杂 效率比栈低很多
举个例子
使用栈就像是我们去饭店吃饭 只管点菜(发出申请)付钱,吃饭(使用内存),走人 不必理会其他工作流程 效率高
但是限制就是可能饭店的菜谱有限
使用堆就像是我们在家自己烧菜,我们要负责买菜,洗菜 洗锅刷碗等工作 但是自由度高 但是效率比去饭店吃饭要低
因为我们不用做其他多于的操作 只负责点菜,付钱,吃就完事了
然后在饭店吃饭对于我们个人来说不用考虑产生的厨余垃圾的问题 但是对于在自己家里做饭 这个是要考虑的
内存泄漏问题
常见的原因:
1.堆栈没有释放
2.内存越界访问(读写越界)
3.野指针,空指针的使用
4.引用未初始化的变量
避免
尽量避免在堆上分配内存,尽可能在栈上分配内存
但是由于堆内存区和栈内存区的性质,所以在栈上分配内存存在一定的局限性

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)