深度学习之文本处理
1.文本向量化将文本分割为单词,每个单词转换为一个向量将文本分割为字符,每个字符转换为一个向量提取单词或字符的n-gram2.单词和字符的one-hot编码单词级one-hot字符级one-hotimport numpy as npsamples = ['This is a dog','The is a cat']all_token_index = {} #构建一个字典来存储数据中的所有标记的索引
·

1.文本向量化
-
将文本分割为单词,每个单词转换为一个向量
-
将文本分割为字符,每个字符转换为一个向量
-
提取单词或字符的n-gram
2.单词和字符的one-hot编码
-
单词级one-hot
-
字符级one-hot
import numpy as np
samples = ['This is a dog','The is a cat']
all_token_index = {} #构建一个字典来存储数据中的所有标记的索引
for sample in samples:
for word in sample.split(): #拆分每一个单词
if word not in all_token_index: #为每一个单词指定一个索引
all_token_index[word] = len(all_token_index) + 1
max_length = 10
#只考虑每个样本前10个单词
result = np.zeros(shape=(len(samples), max_length, max(all_token_index.values()) + 1 ))
for i, sample in enumerate(samples): # 获取sample中的索引和值
for j, word in list(enumerate(sample.split()))[:max_length]: # 获取单词的索引和值
index = all_token_index.get(word)
result[i,j,index] = 1
{'This': 1, 'is': 2, 'a': 3, 'dog': 4, 'The': 5, 'cat': 6}
array([[[0., 1., 0., 0., 0., 0., 0.],
[0., 0., 1., 0., 0., 0., 0.],
[0., 0., 0., 1., 0., 0., 0.],
[0., 0., 0., 0., 1., 0., 0.],
[0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0.]],
[[0., 0., 0., 0., 0., 1., 0.],
[0., 0., 1., 0., 0., 0., 0.],
[0., 0., 0., 1., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 1.],
[0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0.]]])
使用keras实现单词级one-hot编码
from keras.preprocessing.text import Tokenizer
samples = ['This is a dog','The is a cat']
tokenizer = Tokenizer(num_words=10)#设置为前10个最常见的单词
tokenizer.fit_on_texts(samples)#构建单词索引
word_index = tokenizer.word_index
sequences = tokenizer.texts_to_sequences(samples)#转化为索引组成的列表
one_hot_results = tokenizer.texts_to_matrix(samples, mode='binary')#转换为one-hot二进制编码
3.词嵌入
(1)什么是词嵌入
Embedding 最酷的一个地方在于它们可以用来可视化出表示的数据的相关性,当然要我们能够观察,需要通过降维技术来达到 2 维或 3 维。最流行的降维技术是:t-Distributed Stochastic Neighbor Embedding (TSNE)。
我们可以定义维基百科上所有书籍为原始 37,000 维,使用 neural network embedding 将它们映射到 50 维,然后使用 TSNE 将它们映射到 2 维,其结果如下:
这样看好像并不能看出什么,但是如果我们根据不同书籍的特征着色,我们将可以很明显的看出结果。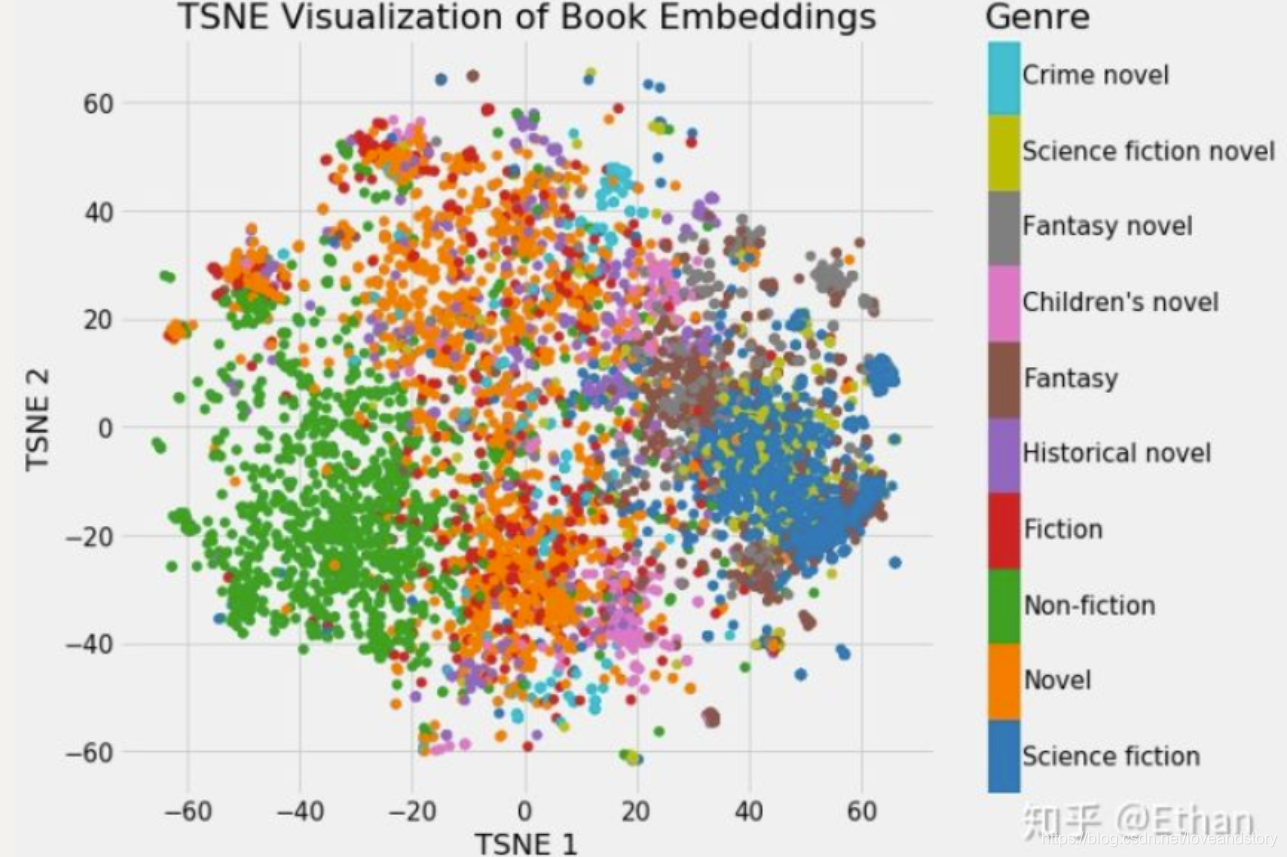
单词索引——>Embedding层——>对应词向量
(2)IMDB训练实例
from keras.datasets import imdb
from keras import preprocessing
#特征单词数
max_features = 10000
max_len = 20#取评论的前20个单词
(x_train,y_train),(x_test,y_test) = imdb.load_data(num_words=max_features)
#将整数列表转换为(samples,maxlen)二维整数张量
x_train = preprocessing.sequence.pad_sequences(x_train,maxlen=max_len)
x_test = preprocessing.sequence.pad_sequences(x_test,maxlen=max_len)
from keras.models import Sequential
from keras.layers import Flatten,Dense,Embedding
model = Sequential()
model.add(Embedding(10000,8,input_length=max_len))
model.add(Flatten())#将三维的嵌入张量展平成形状为(samples,maxlen*8)
model.add(Dense(1,activation='sigmoid'))
model.compile(optimizer='rmsprop',loss='binary_crossentropy',metrics=['acc'])
model.fit(x_train,y_train,epochs=10,batch_size=32,validation_split=0.2)
4.keras中使用Word2vec词嵌入
(1)分词
'''
对评论集的评论样本进行分词
'''
def fenciByJieba(comment_list):
seg_comment_list=[]
for comment in comment_list:
# 去除无用符号
comment = re.sub(r"[0-9\s+\.\!\/_,$%^*()?;;:-【】+\"\']+|[+——!,;:。?、~@#¥%……&*()]+", " ", comment.strip())
seg_list=[]
seg_generator_list = jieba.cut(comment, cut_all=False)
for seg in seg_generator_list:
seg_list.append(seg)
seg_comment_list.append(seg_list)
return seg_comment_list
(2)训练word2vec
模型
'''
训练word2vec
sentences:分词后的评论集文本
size:嵌入维度
window:窗口大小
min_count:忽略单词出现频率小于min_count的单词
sg=1:使用Skip-Gram,否则使用CBOW
workers:训练线程数
'''
def word2vecTrain(seg_comment_list,embedding_vector_size):
w2c_model=Word2Vec(sentences=seg_comment_list,size=embedding_vector_size,window=1,min_count=1,sg=1,workers=4)
w2c_model.save('model_w2c.h5')
return w2c_model
(3)生成神经网络的输入张量
'''
使用word2vec训练模型生成的词典来索引化分词的评论集文本,生成模型输入张量
'''
def sequenceCommentList(seg_comment_list,w2c_model,maxlen):
# 取得所有单词
vocab_list = list(w2c_model.wv.vocab.keys())
# 每个词语对应的索引
word_index = {word: index for index, word in enumerate(vocab_list)}
# 序列化分词后的评论集文本
sequence_comment_list = []
def sequenceComment(seg_comment):
sequence = []
for word in seg_comment:
try:
sequence.append(word_index[word])
except KeyError:
pass
return sequence
# 神经网络模型输入层数据
sequence_comment_list = list(map(sequenceComment, seg_comment_list))
x_data= preprocessing.sequence.pad_sequences(sequence_comment_list, maxlen=maxlen)
return x_data
(4)构建分类模型
'''
构建分类模型并训练 最终保存模型
'''
def run_model(w2v_model,maxlen,x_data,y_data,model_fileName):
# 创建模型 让 Keras 的 Embedding 层使用训练好的Word2Vec权重
embedding_matrix = w2v_model.wv.vectors
model = Sequential()
model.add(Embedding(input_dim=embedding_matrix.shape[0],output_dim=embedding_matrix.shape[1],input_length=maxlen,weights=[embedding_matrix],trainable=False))
model.add(LSTM(32))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
点击阅读全文

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 1
1 0
0- 0


 已为社区贡献1条内容
已为社区贡献1条内容










 服务器0元试用
服务器0元试用
所有评论(0)