
darkNet训练自己的yolov4模型
简介:Darknet项目是github上的一个开源深度学习框架,用c语言编写,布置C/C++环境比较方便。项目地址:https://github.com/AlexeyAB/darknet项目作者主页:https://pjreddie.com/darknet/前人栽树后人乘凉,多谢开源大佬1.图片数据标注labelme标注工具标注的文件是json格式的文件,在yolo检测的框架下需要txt格式的标注
简介:Darknet项目是github上的一个开源深度学习框架,用c语言编写,布置C/C++环境比较方便。
- 项目地址:https://github.com/AlexeyAB/darknet
- 项目作者主页:https://pjreddie.com/darknet/
前人栽树后人乘凉,多谢开源大佬
1.图片数据标注
labelme标注工具标注的文件是json格式的文件,在yolo检测的框架下需要txt格式的标注,但是没有关系,转换也很简单。
没有labelme的话直接,pip install labelme即可。
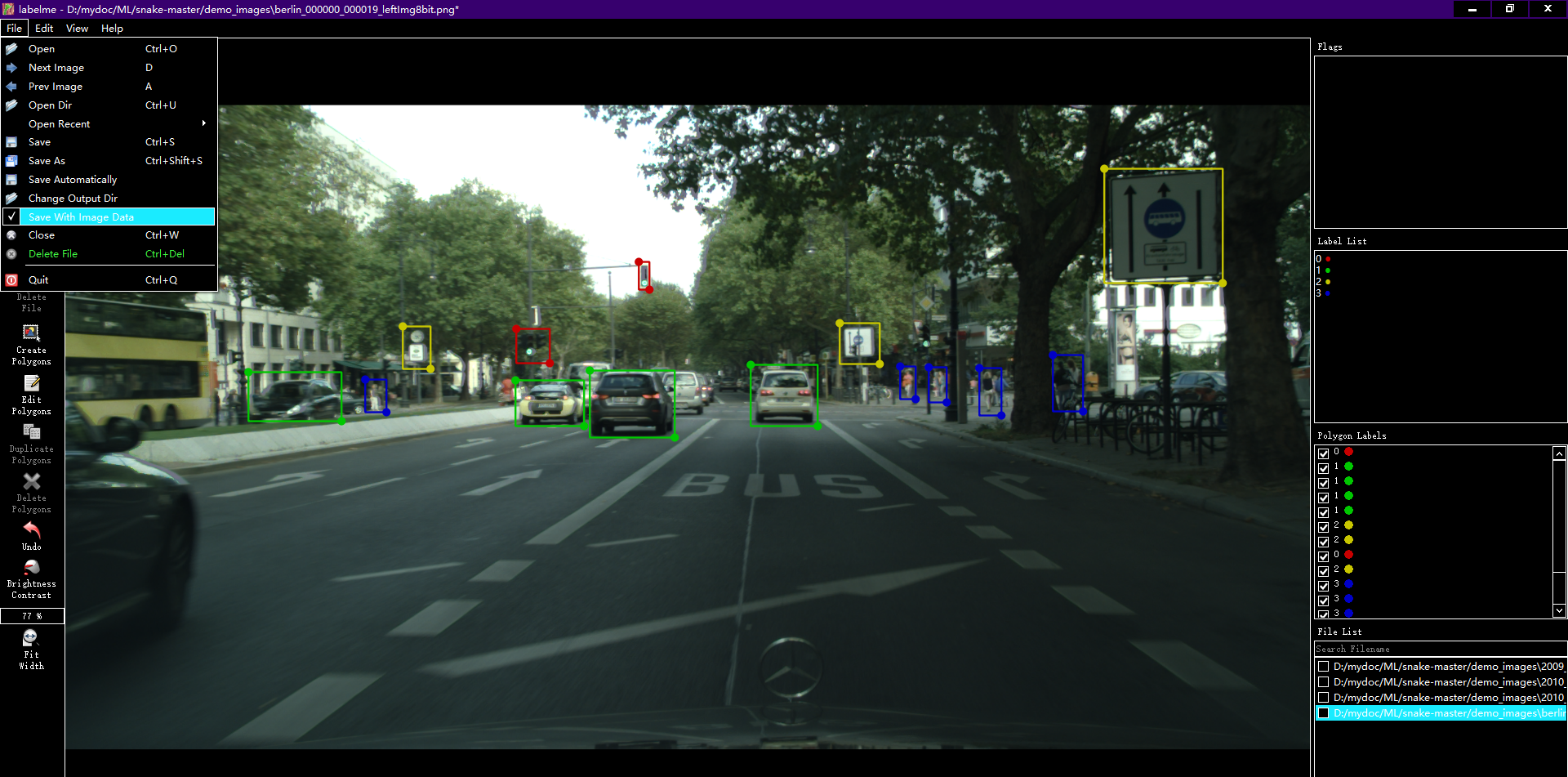
(注:labelme默认是保存图片数据的,一般来说用不到,菜单-Save With Image Data取消即可)
这里我标注了4类数据,分别用0 1 2 3表示,由于图片数据涉及到其他公司秘密不方便展示,所以随便找了个图片做标注示范。
2. annotation格式转换
json格式标签内容如下
{
"version": "4.5.6",
"flags": {},
"shapes": [
{
"label": "0",
"points": [
[
1966.75,
1436.375
],
[
2088.625,
1567.625
]
],
"group_id": null,
"shape_type": "rectangle",
"flags": {}
},
{
"label": "1",
"points": [
[
666.75,
895.75
],
[
935.5,
1186.375
]
],
"group_id": null,
"shape_type": "rectangle",
"flags": {}
},
],
"imagePath": "..\\FOV_0000.bmp",
"imageData": null,
"imageHeight": 2984,
"imageWidth": 4080
}
yolo的txt标签格式
<x_center> <y_center>
由于图片可能有尺度缩放所以YOLO里边的位置用的是图片的百分比坐标
python转换代码如下
import json
import os
import cv2
img_folder_path=r'F:\imagedata\FOV\FOV'
folder_path=r"F:\imagedata\FOV\FOV\annotation"#标注数据的文件地址
txt_folder_path = r"F:\imagedata\FOV\FOV\txt"
def create_txt(img_name,json_d,img_path):
src_img=cv2.imread(img_path)
h,w = src_img.shape[:2]
#txt文件名和图片名保持一致
txt_name = img_name.split(".")[0]+".txt"
txt_path = os.path.join(txt_folder_path,txt_name)
print(txt_path)
with open(txt_path,'a+') as f:
for item in json_d["shapes"]:
print(item['points'])
print(item['label'])
point=item['points']
x_center = (point[0][0]+point[1][0])/2
y_center = (point[0][1]+point[1][1])/2
width = point[1][0]-point[0][0]
hight = point[1][1]-point[0][1]
print(x_center)
f.write(" {} ".format(item['label']))
f.write(" {} ".format(x_center/w))
f.write(" {} ".format(y_center/h))
f.write(" {} ".format(width/w))
f.write(" {} ".format(hight/h))
f.write(" \n")
for jsonfile in os.listdir(folder_path):
temp_path=os.path.join(folder_path,jsonfile)
#如果是一个子目录就继续
if os.path.isdir(temp_path):
continue
print("json_path:\t",temp_path)
jsonfile_path=temp_path
with open(jsonfile_path, "r", encoding='utf-8') as f:
json_d = json.load(f)
#读取图片名
img_name=json_d['imagePath'].split("\\")[1]
img_path=os.path.join(img_folder_path,img_name)
print("img_path:\t",img_path)
create_txt(img_name,json_d,img_path)
生成的txt标签文件
0 0.4969822303921569 0.5033512064343163 0.029871323529411766 0.043984584450402146
1 0.19635416666666666 0.3488815348525469 0.06587009803921569 0.09739443699731903
1 0.2717984068627451 0.3488815348525469 0.07123161764705882 0.09739443699731903
1 0.19673713235294119 0.24677446380697052 0.0666360294117647 0.09425268096514745
1 0.2714154411764706 0.2483453418230563 0.0628063725490196 0.09111092493297587
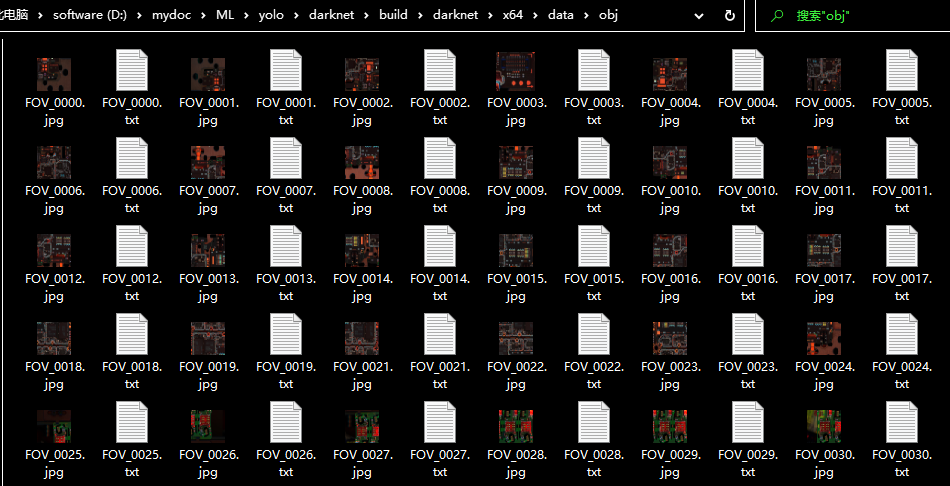
最后把图片和标签数据放到darknet\build\darknet\x64\data\obj目录下,标签和图片在同一个目录下,且标签名和图片名一样,如图
3. darknet cfg文件设置
在darknet\build\darknet\x64\cfg目录下修改yolov4-tiny-obj.cfg文件(记得备份原文件),修改bath,width,height,max_batches(下面的steps= max_batches0.8,max_batches0.9),官网的要求width height需要能被32整除,max_batches=classes*2000.
# Training
batch=4
subdivisions=4
width=2048
height=1024
............
learning_rate=0.00261
burn_in=1000
max_batches = 8000
policy=steps
steps=6400,7200
scales=.1,.1
修改classes为你训练数据的种类数,有两处,另外一个很重要的参数每一个[yolo]层前面的filters=(种类数+5)*3,有两处,例如如果有4类,则filters=(4+5)*3=27,5类:filters=(5+5)*3=30
[convolutional]
size=1
stride=1
pad=1
filters=27
activation=linear
[yolo]
mask = 3,4,5
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319
classes=4
num=6
...........
[convolutional]
size=1
stride=1
pad=1
filters=27
activation=linear
[yolo]
mask = 0,1,2
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319
classes=4
num=6
............
4.创建.data .name 文件
在darknet\build\darknet\x64\data目录下创建FOV_obj.data文件(文件名随便取),写入内容
classes= 4
train = data/train.txt
valid = data/test.txt
names = data/FOV_obj.names
backup = backup/
创建FOV_obj.name文件写入以下内容
0
1
2
3
创建train.txt文件写入你想要训练的图片
data/obj/FOV_0000.jpg
data/obj/FOV_0001.jpg
data/obj/FOV_0002.jpg
data/obj/FOV_0003.jpg
data/obj/FOV_0004.jpg
..............
创建test.txt文件写入
data/obj/FOV_0065.jpg
data/obj/FOV_0066.jpg
data/obj/FOV_0067.jpg
data/obj/FOV_0068.jpg
.............
python代码
#train.txt
txt_ = r"D:\mydoc\ML\yolo\darknet\build\darknet\x64\data\train.txt"
with open(txt_,'a+') as f:
for i in range(60):
item = "data/obj/"+"FOV_{}.jpg".format(str(i).zfill(4))
f.write(item)
f.write("\n")
#test.txt
txt_ = r"D:\mydoc\ML\yolo\darknet\build\darknet\x64\data\test.txt"
with open(txt_,'a+') as f:
for i in range(60,69):
item = "data/obj/"+"FOV_{}.jpg".format(str(i).zfill(4))
f.write(item)
f.write("\n")
最后的文件如下
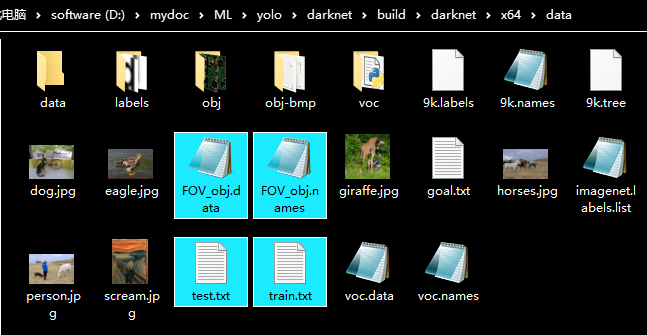
5. 下载yolo预训练模型
https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v4_pre/yolov4-tiny.conv.29
放入darknet\build\darknet\x64目录下
6.train
打开cmd进入darknet.exe所在目录
输入
darknet.exe detector train data/FOV_obj.data cfg/yolov4-tiny-obj.cfg yolov4-tiny.conv.29 29
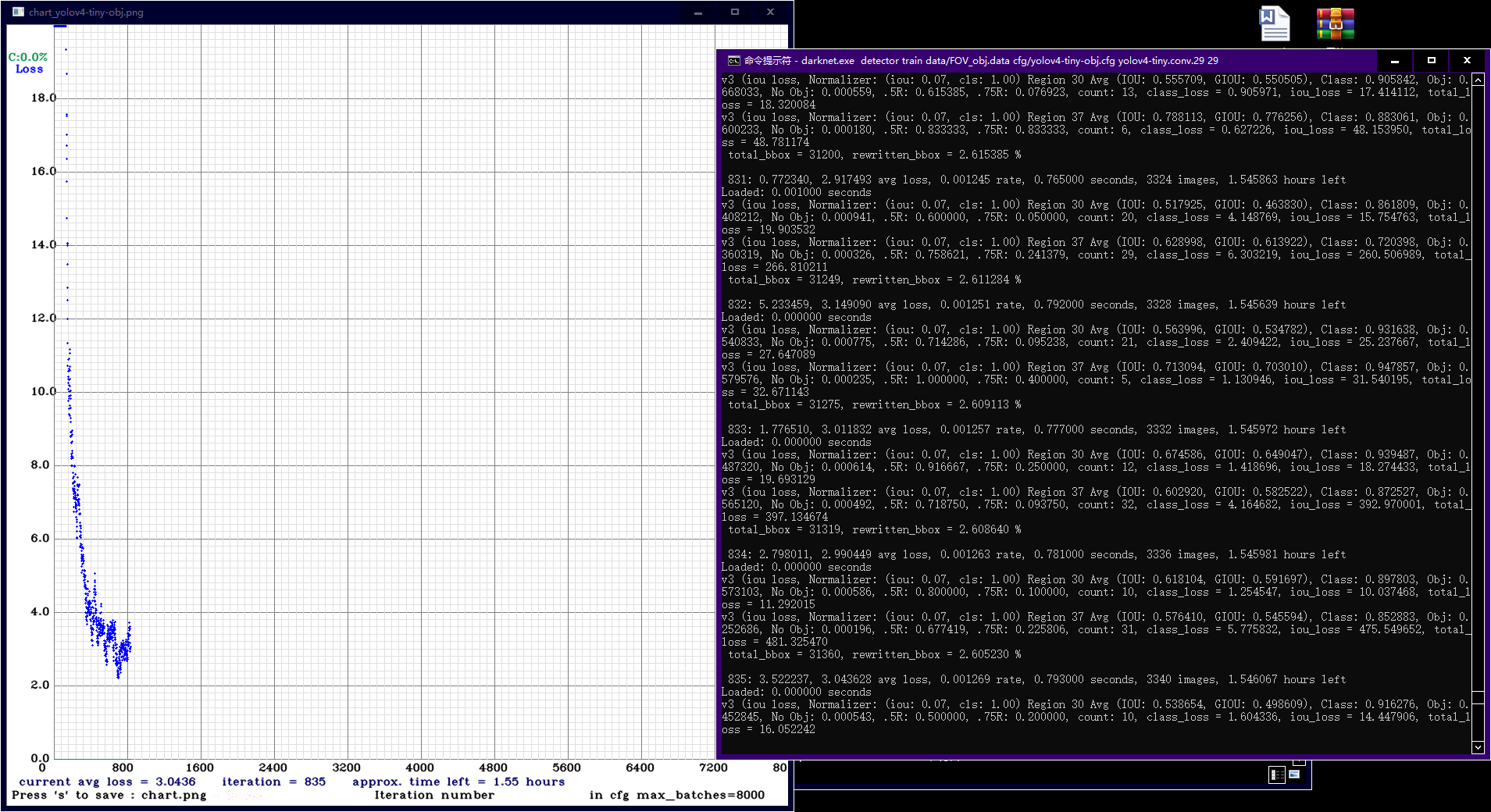
可以看到训练损失开始很大,在训练200-300个batch时下降到3点几,并在此处震荡,另外每训练1000个batch会保存一次模型。模型权值保存在darknet\build\darknet\x64\backup目录下,某次训练中断了,想要接着上一次的训练过程继续的话也很方便,输入:
darknet.exe detector train data/FOV_obj.data cfg/yolov4-tiny-obj.cfg backup\yolov4-tiny-obj_last.weights
7.demo test
使用刚刚训练的模型权重做测试
darknet.exe detector test data/FOV_obj.data cfg/yolov4-tiny-obj.cfg backup\yolov4-tiny-obj_1000.weights
在Enter Image path:处填入图片路径(eg:data/test.jpg)


######OK,至此基本训练流程走完,剩下的就是提升网络性能了。
训练过程的一点总结
- 在yolov4-tiny-obj.cfg配置中图片的高度和宽度应该能被32整除,用其他高宽也能训练,但是会出现比较大的震荡,test测试的时候找不到目标,或者是有一层的输入不匹配(图像输入0x0x0)。
- 训练yolov4完整框架,用yolov4.conv.137预训练权重,图像尺寸大一点常常会导致GPU out of memory,解决方法是在.cfg文件中提高subdivisions=4(或者8、16、32、64),另外就是改输入的尺寸width height。参考https://www.ccoderun.ca/programming/2020-09-25_Darknet_FAQ/#cuda_out_of_memory
- 网络会把尺寸*1.4,例如在.cfg文件中设置width=1024,height=768,
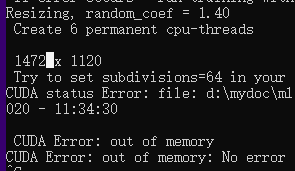
- yolov4完整版的配置和yolov4-tiny版配置差不多,就是改width,height,classes,yolo层前面卷积层的filters(classes,filters有三处需要改,因为它有三个yolo层)。

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)