
Spring Boot 整合 Kafka 分布式消息系统快速入门
1、Spring boot 对 kafka 的配置以 spring.kafka.* 开头,官网提供了大量的配置选项,通常情况下,绝大部分选项直接使用默认值即可。2、比如应用只用来发送消息时,则 spring.kafka.consumer.* 不用配置,应用只用了接收消息时,则 spring.kafka.producer.* 不用配置。比如:
本文环境:Spring Boot 2.1.3.RELEASE + Java JDK 1.8 + Spring Kafka 2.2.4 + Kafka Clients 2.0.1。在 IP 为 192.168.116.128、192.168.116.129 的两台 CentOS 虚拟机上进行了 zookeeper 集群与 kafka 集群,并启动成功。
Spring Boot 整合 Kafka 快速入门
1、Spring 通过 Spring-Kafka 项目的对 Apache Kafka 提供自动配置支持。
2、强烈推荐从以下官网进行学习:
| Spring boot 支持 Apache Kafka 官方文档:Spring Boot Reference Guide Spring-Kafka 项目官方文档:Spring for Apache Kafka |
一:导入依赖:pom.xml
<!-- https://mvnrepository.com/artifact/org.springframework.kafka/spring-kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
1、内部依赖了:kafka-clients、spring-context、spring-messaging、spring-tx、spring-retry。
2、自动配置类:org.springframework.boot.autoconfigure.kafka.KafkaAutoConfiguration
3、配置属性类:org.springframework.boot.autoconfigure.kafka.KafkaProperties
二:kafka 配置:application.yml
1、Spring boot 对 kafka 的配置以 spring.kafka.* 开头,官网提供了大量的配置选项,通常情况下,绝大部分选项直接使用默认值即可。
2、比如应用只用来发送消息时,则 spring.kafka.consumer.* 不用配置,应用只用了接收消息时,则 spring.kafka.producer.* 不用配置。比如:
| spring.kafka.bootstrap-servers=localhost:9092 spring.kafka.consumer.group-id=myGroup |
3、本文对比较常用的选项进行配置说明,实际生产中,大部分都不用配置,默认即可。在线配置源码:src/main/resources/application.yml · 汪少棠/apache-kafka - Gitee.com
kafka 生产者·发送消息
1、如同使用 JdbcTemplate、RedisTemplate、ElasticsearchTemplate 一样,{@link KafkaAutoConfiguration} 中会自动根据 {@link KafkaProperties} 配置属性读取配置, 然后创建 {@link KafkaTemplate} 实例并添加到 Spring 容器中,在需要使用的时候直接获取使用即可。Spring boot 发送消息官方文档。

2、在线演示源码:java/com/wmx/apachekafka/controller/KafkaProducer.java, 参考其中 sendMessage、sendMsgDefault 方法。
这里我使用一个可视化工具来查看 kafka 服务器上的消息:Kafka 可视化工具 Kafka Tool,能清晰的看到消息所属的主题、以及所在的分区,消息的内容、长度等等。

3、注意事项:
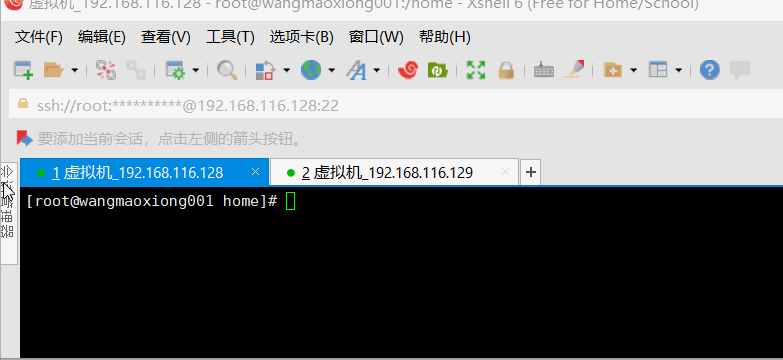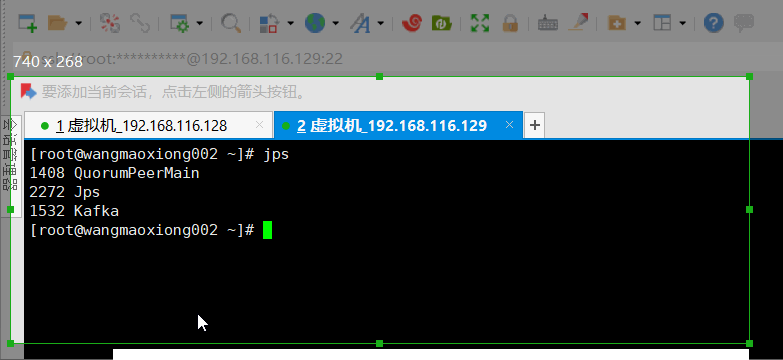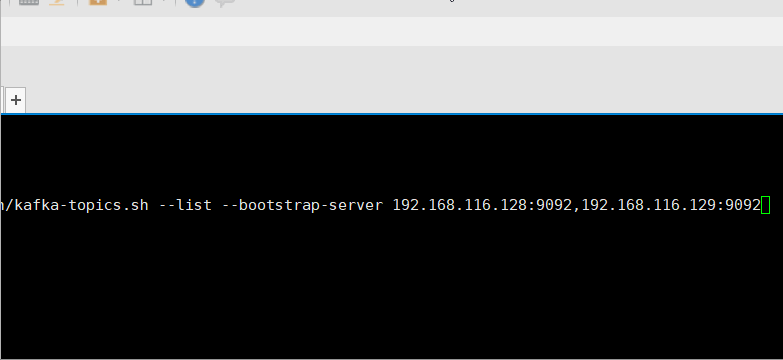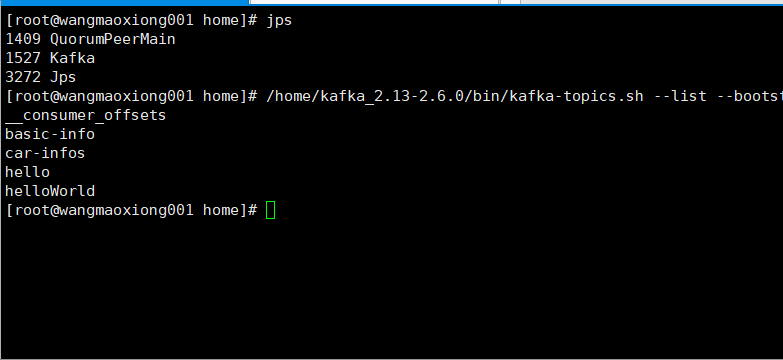
| 1)kafkaTemplate.send(String topic, @Nullable V data):向指定主题发送消息,如果 topic 不存在,则自动创建,但是创建的主题默认只有一个分区 - PartitionCount: 1、分区也没有副本 - ReplicationFactor: 1,1 表示自身。 2)对于 kafka 集群的情况下,如果主题只有一个分区,没有副本,则显然不合理,那就没必要集群了,所以解决办法之一是自己通过 kafka 命令手动新建 topic,这样 send 时发现主题已经存在,就不会再自动新建了。kafka 新建主题命令如下: |
[root@wangmaoxiong001 config]# /home/kafka_2.13-2.6.0/bin/kafka-topics.sh --create --bootstrap-server 192.168.116.128:9092,192.168.116.129:9092 --replication-factor 2 --partitions 2 --topic helloWorld
Created topic helloWorld.
[root@wangmaoxiong001 config]# /home/kafka_2.13-2.6.0/bin/kafka-topics.sh --describe --bootstrap-server 192.168.116.128:9092,192.168.116.129:9092 -topic helloWorld
Topic: helloWorld PartitionCount: 2 ReplicationFactor: 2 Configs: segment.bytes=1073741824
Topic: helloWorld Partition: 0 Leader: 129 Replicas: 129,128 Isr: 129,128
Topic: helloWorld Partition: 1 Leader: 128 Replicas: 128,129 Isr: 128,129
[root@wangmaoxiong001 config]# kafka 消费者·接收消息
1、在 Spring 组件(Component)中,新建一个方法,然后在方法上标注 @KafkaListener(topics = "someTopic") 注解即可接收指定主题的消息。Spring boot 接收消息官方文档。
2、注意:在消费者第一次启动表示自己需要监听某些主题后,凡是推送到此主题的消息,都会被监听然后接收,即使生产者推送的时候,消费者已经宕机了,或者消费者服务关闭了,都不会受影响,消费者启动后都会接收未接收的消息。
3、在线演示源码:/src/main/java/com/wmx/apachekafka/controller/KafkaConsumer.java

更多 @KafkaListener 的配置使用可以参考官网:@KafkaListener Annotation
♛♛♛棒棒哒♛♛♛
| @KafkaListener(topics = "helloWorld") | 接收 helloWorld 主题的消息 |
| @KafkaListener(topics = {"topic1", "topic2"}) | 接收 topic1、topic2 主题的消息 |
| @KafkaListener(topics = {"${app.kafka.topics.agency}"}) | 接收的主题名称通过全局配置文件配置 |
| @KafkaListener(topics = {"${app.kafka.topics.agency:topic3}"}) | 接收的主题名称通过全局配置文件配置,没有配置时,使用默认值 topic3。 |
生产者发送消息添加回调监听
1、生成者发送信息,我们非常关心消息是否发送成功,比如网络断开,或者 kafka 服务器宕机等等,消息发送之后,如果达到发送失败时的重试次数仍然未成功,则发送失败,抛出异常,此时需要有相应的处理,比如记录日志,保存到数据库,后期再次发送等。
2、实现方式是在 send(发送)后添加异步回调监听方法,用于监控消息发送成功或者失败,发送成功则可以记录日志,发送失败则应该有相应的措施,比如延期再发送等。
2、有如下两种实现方式:
| void addCallback(ListenableFutureCallback<? super T> callback) void addCallback(SuccessCallback<? super T> successCallback, FailureCallback failureCallback) |
3、在线演示源码:https://gitee.com/src/main/java/com/wmx/apachekafka/controller/KafkaProducer.java,参考其中的 sendMessageCallback、sendMessageCallback2 方法。
生产者发送消息自定义分区
1、kafka 中的 topic 可以指定多个分区,多个副本,各个分区中的数据是不同的,一条消息只会进入一个分区,生产者将消息发送到 topic 时,遵循以下策略:
| A、发送消息时直接指定分区,则直接将消息追加到指定分区中; B、若发送消息时未指定 patition,但指定了 key(kafka 允许为每条消息设置一个消息 key),则对 key 进行 hash 计算,根据计算结果路由到指定分区,这种情况下可以保证同一个 Key 的所有消息都进入到相同的分区; C、如果 patition 和 key 都未指定,则 kafka 默认轮询选出一个 patition,然后将消息追加到指定分区。 |
2、实际开发中通常使用上面默认的策略就可以了,因为更关心的是消息的发送与接收,至于消息在 kafka 中存放在哪个分区,其实意义不是很大。
kafkaTemplate.send(String topic, Integer partition, K key, @Nullable V data)
3、如果自己硬是想要自定义分区策略,即自定义消息路由到分区的规则,则可以实现 Partitioner 接口,重写方法,其中 partition 方法的返回值就表示将消息发送到几号分区。在线演示源码
4、然后在application.propertise 中配置自定义分区器:
| # 自定义分区器 spring.kafka.producer.properties.partitioner.class=com.wmx.apachekafka.beans.MyKafkaPartitioner |

生产者发送消息添加事务管理
1、很多时候发送消息是需要和系统业务相关联的,比如发送消息后还需要做其它的业务操作,比如增删改查,或者远程调用其它微服务等,当后续操作发生异常时,前面发送给 kafka 的消息是让它发送成功还是回滚取消发送呢?这通常取决于具体情况。
方式一
1、修改如下两项配置:
| spring.kafka.producer.transaction-id-prefix= # 非空时,启用对生产者的事务支持,值是什么无所谓,只要有值,则表示开启生产者事务。 spring.kafka.producer.acks=-1 #使用事务时,必须配置为 -1,表示领导者必须收到所有副本的确认消息。 |
2、使用 springframework 的 @Transactional注解,此时事务处理完全和平时 spring 事务一样,发生异常,则回滚,消息也不会发送成功。
/**
* 向指定主题(topic)发送消息:http://localhost:8080/kafka/sendMsgTransactional1?topic=car-infos
* 与 springframework 框架的事务整合到一起,此时异常处理完全和平时一样,默认所有运行时异常都将回滚。
*
* @param topic :主题名称,不存在时自动创建,默认1个分区,无副本。主题名称也可以通过配置文件配置,这里直接通过参数传入。
* @param message :待发送的消息,如:{"version":1,"text":"后日凌晨三点执行任务"}
* @return
*/
@PostMapping("kafka/sendMsgTransactional1")
@Transactional
public Map<String, Object> sendMessageTransactional1(@RequestParam String topic, @RequestBody Map<String, Object> message) {
try {
logger.info("向指定主题发送信息,带事务管理,topic={},message={}", topic, message);
String msg = new ObjectMapper().writeValueAsString(message);
kafkaTemplate.send(topic, msg);
if ("110".equals(message.get("version").toString())) {
System.out.println(1 / 0);
}
} catch (JsonProcessingException e) {
e.printStackTrace();
}
return message;
}
注意事项
1、如果 Kafka Producer 使用配置开启了事务管理,则所有发送的消息,都必须处于事务之中,即方法上必须加 @Transactional注解, 否则会抛出异常:
java.lang.IllegalStateException: No transaction is in process;
possible solutions: run the template operation within the scope of a template.executeInTransaction() operation,
start a transaction with @Transactional before invoking the template method,
run in a transaction started by a listener container when consuming a record方式二
1、使用 KafkaTemplate#executeInTransaction,此时消息发送操作是在本地事务中进行,与全局事务是分离的,外部的异常并不影响内部的发送。
/**
* 生成者发送消息事务管理方式2:使用 executeInTransaction(OperationsCallback<K, V, T> callback)
* executeInTransaction:表示执行本地事务,不参与全局事务(如果存在),即方法内部和外部是分离的,只要内部不
* 发生异常,消息就会发送,与外部无关,即使外部有 有 @Transactional 注解也不影响消息发送,此时外围有没有 @Transactional 都一样。
*
* @param topic
* @param message
* @return
*/
@PostMapping("kafka/sendMsgTransactional2")
@Transactional(rollbackFor = Exception.class)
public Map<String, Object> sendMessageTransactional2(@RequestParam String topic, @RequestBody Map<String, Object> message) {
try {
logger.info("向指定主题发送信息,带事务管理:topic={},message={}", topic, message);
String msg = new ObjectMapper().writeValueAsString(message);
/**
* executeInTransaction 表示这些操作在本地事务中调用,不参与全局事务(如果存在)
* 所以回调方法内部发生异常时,消息不会发生出去,但是方法外部发生异常不会回滚,即便是外围方法加了 @Transactional 也没用。
*/
kafkaTemplate.executeInTransaction(operations -> {
operations.send(topic, msg);
if ("120".equals(message.get("version").toString())) {
System.out.println(1 / 0);
}
return null;
});
//如果在这里发生异常,则只要 executeInTransaction 里面不发生异常,它仍旧会发生消息成功
} catch (JsonProcessingException e) {
e.printStackTrace();
}
return message;
}本文在线源码:src/main/java/com/wmx/apachekafka/controller/KafkaProducer.java · 汪少棠/apache-kafka - Gitee.com
消费者批量消费处理消息
1、默认一次只消费一条消息,注意所谓的批量消费并不是一定要满足设置的条数后才进行消费,而是最多一次消费那么多消息。修改配置如下:
# 监听器类型,可选值有:SINGLE(单条消费,默认)、BATCH(批量消息)
spring.kafka.listener.type=batch
# 一次调用poll()时返回的最大记录数,即批量消费每次最多消费多少条消息,注意是最多,并不是必须满足数量后才消费.
spring.kafka.consumer.max-poll-records=102、配置的批量消费时,必须使用 List 接收,否则会抛异常,反之如果不是配置的批量消费,则监听器不能使用 list 接收,否则也会异常。
/**
* 批量消费时,必须使用 List 接收,否则会抛异常。
* 即如果配置文件配置的是批量消费(spring.kafka.listener.type=batch),则监听时必须使用 list 接收
*
* @param records
*/
@KafkaListener(topics = "batch-msg")
public void messageListener1(List<ConsumerRecord<?, ?>> records) {
System.out.println(">>>批量消费返回条数,records.size()=" + records.size());
int count = 0;
for (ConsumerRecord<?, ?> record : records) {
System.out.println("\t消息" + (++count) + ":" + record.value());
}
}
在线演示源码:src/main/java/com/wmx/apachekafka/controller/KafkaConsumer.java · 汪少棠/apache-kafka - Gitee.com
消费者消费消息并转发消息
1、有的时候,接收消息处理之后,可能需要将其再发送给其它主题,此时当然使用 API 操作也是可以的,不过有更简单的方式,就是使用一个 @SendTo 注解。
2、SendTo 可以标注在类上,此时对类中的所有方法有效,也可以直接标注在方法上,方法的返回值表示转发的消息内容,注解的 value 值表示转发的目标主题。
/**
* 消费消息并转换。SendTo 可以标注在类上,此时对类中的所有方法有效,方法的返回值表示转发的消息内容。
*
* @param record
* @return
*/
@KafkaListener(topics = {"sendTo"})
@SendTo("car-infos")
public String messageListener3(ConsumerRecord<?, ?> record) {
System.out.println("消费单条消费并转发:" + record.value() + "," + record.timestamp());
return record.value().toString();
}在线演示源码:src/main/java/com/wmx/apachekafka/controller/KafkaConsumer.java · 汪少棠/apache-kafka - Gitee.com
官网介绍文档:Spring for Apache Kafka
消费者组(Consumer Group)测试
| spring.kafka.consumer.group-id | 标识此消费者所属的消费者组的唯一字符串 |
| spring.kafka.consumer.client-id | 消费者客户端 id,在消费者组需要唯一指定。发出请求时会传递给服务器,用于服务器端日志记录 不写时,会自动命名,比如:consumer-1、consumer-2...,原子性递增。通常不建议自定义,使用默认值即可,因为容易冲突 |
1、为了进一步提高吞吐量,Kafka 引入了消费者组的概念,由一个或者多个消费者组成一个组,相当于是消费者的集群。
2、比如消费者 A 是一个应用 A 实例,为了提高消费的吞吐量,可以多部署了几个消费者 A 实例(多实例),这样就有多个消费者形成一个消费组,但干的都是应用 A 做的事,需要与消费者B(不同的应用)区分开。
3、一般设置消费组的消费者数量与分区数(partitions)一致,这样一个消费者能负责一个分区,提高效率。如果消费组的消费者数量小于分区数,则会出现一个消费者负责多个分区。而如果消费组的消费者数量大于分区数,则会出现有消费者分不到分区,造成浪费。所以一般保持一致。
4、下面启动两个实例,如果通过 kafka 自身的生产者脚本发送消息,看消费者组内是否只有一个消费成功,演示如下。

Spring.kafka 配置属性介绍
1、Spring boot 对 kafka 的配置以 spring.kafka.* 开头,官网提供了大量的配置选项,通常情况下,绝大部分选项直接使用默认值即可,下面将一些可能常用到的汇总如下。
| spring.kafka.bootstrap-servers | kafka 服务器集群地址,默认为 localhost:9092,必须配置 |
| spring.kafka.consumer.key-deserializer | 消费者 key 反序列化方式 |
| spring.kafka.consumer.value-deserializer | 消费者 value 反序列化方式 |
| spring.kafka.consumer.group-id | 标识此消费者所属的消费者组的唯一字符串 |
| spring.kafka.consumer.client-id | 消费者客户端 id,在消费者组需要唯一指定。发出请求时会传递给服务器,用于服务器端日志记录 不写时,会自动命名,比如:consumer-1、consumer-2...,原子性递增。通常不建议自定义,使用默认值即可,因为容易冲突 |
| spring.kafka.consumer.enable-auto-commit | 消费者的偏移量是否在后台自动提交,默认为 true |
| spring.kafka.consumer.auto-commit-interval | 如果enable.auto.commit=true,则消费者偏移自动提交给Kafka的频率(以毫秒为单位),默认值为 5000 |
| spring.kafka.consumer.auto-offset-reset | 当 Kafka 中没有初始偏移量或者服务器上不再存在当前偏移量时该怎么办,可选的值有 latest、earliest、exception、none,默认值为 latest |
| spring.kafka.consumer.max-poll-records | 一次调用poll()时返回的最大记录数,即批量消费每次最多消费多少条消息,注意是最多,并不是必须满足数量后才消费. 在spring.kafka.listener.type值为 BATCH 时有效。 |
| spring.kafka.consumer.properties.session.timeout.ms | 消费会话超时时间(超过这个时间consumer没有发送心跳,就会触发 rebalance(重新平衡) 操作) |
| spring.kafka.consumer.properties.request.timeout.ms | 消费请求超时时间 |
| spring.kafka.consumer.fetch-max-wait | 如果没有足够的数据立即满足“fetch min size”给出的要求,服务器在响应fetch请求之前阻塞的最长时间。默认值为 500毫秒 |
| spring.kafka.consumer.fetch-min-size | 服务器应为获取请求返回的最小数据量。 |
| spring.kafka.consumer.heartbeat-interval | 心跳与消费者协调员之间的预期时间(以毫秒为单位),默认值为3000 |
| spring.kafka.consumer.properties.* | 用于配置客户端的其他特定于消费者的属性。 |
| spring.kafka.listener.type | 监听器类型,可选值有:SINGLE(单条消费,默认)、BATCH(批量消息) |
| spring.kafka.listener.concurrency | 在侦听器容器中运行的线程数。 |
| spring.kafka.listener.poll-timeout | 轮询消费者时的超时时间,单位毫秒。 |
| spring.kafka.producer.acks | 在考虑请求完成之前,生产者要求领导者已收到的确认数,可选值有:-1、0、1(默认为1) acks = 0 :生产者将不会等待来自服务器的任何确认,该记录将立即视为已发送成功,在这种情况下,无法保证服务器已收到记录,并且重试配置将不会生效 |
| spring.kafka.producer.key-serializer | 生产者 key 序列化方式. org.apache.kafka.common.serialization.StringSerializer |
| spring.kafka.producer.value-serializer | 生产者 value 序列化方式. org.apache.kafka.common.serialization.StringSerializer |
| spring.kafka.producer.batch-size | 默认批处理大小,如果值太小,则可能降低吞吐量,为零将完全禁用批处理,当 linger.ms=0 时,此值无效 |
| spring.kafka.producer.buffer-memory | 生产者可以用来缓冲等待发送到服务器的记录的总内存大小。单位为字节,默认值为:33554432合计为32M |
| spring.kafka.producer.retries | 发送失败时的重试次数,当大于零时,允许重试失败的发送。 |
| spring.kafka.producer.compression-type | 生产者生成的所有数据的压缩类型。 可选值有标准压缩编解码器:gzip、snappy、lz4、还接受:uncompressed、producer,分别表示没有压缩以及保留生产者设置的原始压缩编解码器,默认值为producer |
| spring.kafka.properties.linger.ms | 消息提交延时时间(单位毫秒),当生产者接收到消息 linger.ms 秒钟后,就会将消息提交给 kafka。 |
| spring.kafka.properties.partitioner | kafka 自定义分区规则 |
| spring.kafka.producer.properties.* | 用于配置客户端的其他特定于生产者的属性。 |
| spring.kafka.properties.* | 用于配置客户端的附加属性(生产者和消费者通用)。 |
| spring.kafka.template.default-topic | 将消息发送到的默认主题,KafkaTemplate.sendDefault,可以为空 |
KafkaTemplate API 介绍
1、KafkaTemplate 包装了一个 producer(生产者),并提供了向 Kafka 主题发送数据的方快捷方法,下表显示了 KafkaTemplate 中的相关方法:
ListenableFuture<SendResult<K, V>> sendDefault(V data);
ListenableFuture<SendResult<K, V>> sendDefault(K key, V data);
ListenableFuture<SendResult<K, V>> sendDefault(Integer partition, K key, V data);
ListenableFuture<SendResult<K, V>> sendDefault(Integer partition, Long timestamp, K key, V data);
ListenableFuture<SendResult<K, V>> send(String topic, V data);
ListenableFuture<SendResult<K, V>> send(String topic, K key, V data);
ListenableFuture<SendResult<K, V>> send(String topic, Integer partition, K key, V data);
ListenableFuture<SendResult<K, V>> send(String topic, Integer partition, Long timestamp, K key, V data);
ListenableFuture<SendResult<K, V>> send(ProducerRecord<K, V> record);
ListenableFuture<SendResult<K, V>> send(Message<?> message);
Map<MetricName, ? extends Metric> metrics();
List<PartitionInfo> partitionsFor(String topic);
<T> T execute(ProducerCallback<K, V, T> callback);2、sendDefault API 要求已为模板配置默认主题,execute 方法提供对底层生产者的直接访问。

鸿蒙生态一站式服务平台。
更多推荐

 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)