

微服务框架实施
Planning a microservices-based application — where to start from? This architecture is composed of many aspects; how to break down this decoupled architecture? This article aims to review the planning and implementation considerations of a microservices-based solution. I hope that after reading this article, the picture will be clearer.
规划基于微服务的应用程序-从哪里开始? 该体系结构由许多方面组成。 如何分解这种分离的架构? 本文旨在回顾基于微服务的解决方案的规划和实现注意事项。 我希望阅读本文后,情况会更加清晰。
要点 (The Gist)
Why?
为什么?
The reasoning for choosing microservices.
选择微服务的理由。
What to consider?
要考虑什么?
The planning considerations before moving to microservices (versioning, service discovery and registry, transactions, and resourcing)
转向微服务之前的规划注意事项(版本,服务发现和注册,交易和资源配置)
How?
怎么样?
Implementation practices (resilience, communication patterns)
实施实践(弹性,沟通模式)
Who?
WHO?
Understanding the data flow (logging, monitoring, and alerting)
了解数据流(记录,监视和警报)
Building a viable microservices solution is attributed to the technical platform and supporting tools. This article focuses on the technical foundations and principles, without diving into the underlying tools and products that carry out the solution itself (Docker, Kubernetes or other containers orchestration tool, API Gateway, authentication, etc.).
构建可行的微服务解决方案归功于技术平台和支持工具。 本文重点关注技术基础和原理,而没有深入介绍可自行实现解决方案的基础工具和产品(Docker,Kubernetes或其他容器编排工具,API网关,身份验证等)。
While writing this article I noticed that each of the parts deserves a dedicated article; nevertheless, I chose to group them all into one article so we can see the forest, and not only the trees
在撰写本文时,我注意到每个部分都应专门撰写一篇文章。 不过,我选择将它们全部归为一章,这样我们就可以看到森林,而不仅仅是树木
1.微服务背后的原理 (1. The Principles Behind Microservices)
In a microservices architecture, a single application is composed of many small services; each service operates on its own process while communicating with other services over the network by some inter-process communication form, which will be discussed in later in Part 3.
在微服务体系结构中,单个应用程序由许多小型服务组成。 每个服务在自己的进程上运行,同时通过某种进程间通信形式在网络上与其他服务进行通信,这将在第3部分的稍后部分中讨论。
This decoupling allows more flexibility, compared to a monolithic application since each service is independent and can be developed, deployed, and maintained regardless of the other services that compose the application.
与单个应用程序相比,这种解耦提供了更大的灵活性,因为每个服务都是独立的,并且可以与组成应用程序的其他服务无关地进行开发,部署和维护。
Microservices characteristics include three main aspects:
微服务的特征包括三个主要方面:
Domain-Driven Design (DDD)
域驱动设计(DDD)
Each service is a separate component that can do only one thing; it is upgradable, regardless of the other services. The service is built to handle a specific domain and declares its boundaries accordingly; these boundaries are exposed as a contract, which technically can be implemented by API. The considerations for decomposing the system to domains can base on data domain (model), business functionality, or the need for atomic and consistent data-transactions.
每个服务都是一个单独的组件,只能做一件事。 无论其他服务如何,它都是可升级的。 构建该服务以处理特定域并相应地声明其边界; 这些边界作为合同公开,从技术上讲可以通过API来实现。 将系统分解为域的注意事项可以基于数据域(模型),业务功能或对原子和一致的数据事务的需求。
Not only the technology applies the DDD concepts, but also the development team can adhere to this concept too. Each microservice can be implemented, tested, and deployed by a different team.
不仅该技术应用了DDD概念,而且开发团队也可以遵守该概念。 每个微服务都可以由不同的团队实施,测试和部署。
Loose coupling, high cohesion.
耦合松散,内聚力高。
Changing one microservice does not impact the other microservices, so altering behaviour in our solution can be done only in one place while leaving the other parts intact. Nevertheless, each service communicates with other services broadly, and the system operates as one cohesive application.
更改一个微服务不会影响其他微服务,因此更改解决方案的行为只能在一个位置进行,而其他部分则保持不变。 但是,每个服务都与其他服务进行广泛的通信,并且系统作为一个内聚的应用程序运行。
Continuous delivery
持续交付
Facilitates the testing on the microservice architecture. By doing extensive use of automation, we gain fast feedback on the quality of the solution. The fast feedback goes throughout the whole SDLC (software development lifecycle). It allows releasing frequently more mature and stable versions.
促进对微服务体系结构的测试。 通过广泛使用自动化,我们可以快速获得有关解决方案质量的反馈。 快速反馈贯穿整个SDLC(软件开发生命周期)。 它允许经常发布更成熟和稳定的版本。
为什么选择微服务? (Why Microservices?)
The main objectives to make a transition towards a microservices solution is to be able to develop fast, test easily, and release more frequently. In short, it means shortening the features’ time-to-market while reducing risks. In the monolith world, a change is not isolated from the rest of the application layers. With that, every change may have a huge impact on the system’s stability. Therefore, the agility in the SDLC is affected; releasing a new feature incurs more testing time, prudent releases, and overall prolonged time-to-market.
向微服务解决方案过渡的主要目标是能够快速开发,轻松测试并更频繁地发布。 简而言之,这意味着缩短功能的上市时间,同时降低风险。 在整体世界中 ,更改并非与其余应用程序层隔离。 这样,每次更改都可能对系统的稳定性产生巨大影响。 因此,SDLC中的敏捷性受到影响; 发布新功能会导致更多的测试时间,审慎的发布以及总体上的上市时间。
Easy to develop a small-scale service that focuses only on one main use-case. It is more productive to understand the logic and maintain it.
易于开发仅关注一个主要用例的小型服务。 了解逻辑并进行维护会更有效率 。
Dividing the work between the teams is simpler. Each service can be developed solely by another team.
在团队之间分配工作更为简单 。 每种服务只能由另一个团队开发。
Start-up time of each service is faster than a monolith application.
每个服务的启动时间都比整体应用程序快 。
Scaling-out/in is effective and controlled. Adding more services when the load rises is simple, and similarly, when the load is low, the number of running services can be reduced. With that, utilizing the underlying hardware is more efficient.
向外扩展/扩展是有效且受控的。 在负载增加时添加更多服务很简单,同样,当负载较低时,可以减少正在运行的服务数量。 这样一来,利用底层硬件将更加有效。
Tackling and troubleshooting can be isolated if the source of the problem is known. After that, resolving the problem is an isolated chirurgical fix.
如果已知问题的根源,则可以将处理和故障排除隔离 。 在那之后,解决问题是一个孤立的方法。
Technology-binding is limited to the service level. Each service can be developed in another technology than the others. It allows matching the best technology to address the use-case and bypass the constraints of using the same programming language as the rest of the system. Furthermore, it allows using newer technologies; if the system is written in Java (an outdated version), we can add a newer service written in a newer version of Java or even another language, such as Scala.
技术约束仅限于服务级别。 每种服务都可以使用其他技术开发。 它允许匹配最佳技术来解决用例,并绕过使用与系统其余部分相同的编程语言的约束。 此外,它允许使用更新的技术。 如果系统是用Java(过时的版本)编写的,则我们可以添加以Java或其他语言(例如Scala)的较新版本编写的服务。
微服务-不仅收益 (Microservices — Not Only Benefits)
When you have a hammer, everything looks like a nail. This sentence is relevant for a microservice-based solution too. Along with the advantages, there are some drawbacks:
当您拿着锤子时,一切看起来都像钉子。 这句话也与基于微服务的解决方案有关。 除了优点之外,还有一些缺点:
Understanding and developing a distributes system as a whole is complex. Designing and implementing inter-service communication can involve various protocols and products. This complexity is embedded in each phase of the SDLC, starting from designing until maintaining and monitoring.
从整体上理解和开发分布式系统很复杂 。 设计和实现服务间通信可能涉及各种协议和产品。 从设计到维护和监视,这种复杂性都嵌入了SDLC的每个阶段。
Since each service has one main use-case or domain to manage, developing atomic transactions should be spread into several services (unless designing the microservices based on the data-consistency domain); it is more complicated to implement the transaction and its rollback across several services. The solution should adapt and embrace the eventual consistency concept (described in details later).
由于每个服务都有一个主要用例或域来管理,因此开发原子事务应分散到多个服务中(除非基于数据一致性域设计微服务); 跨多个服务实现事务及其回滚更加复杂。 该解决方案应适应并包含最终的一致性概念(稍后详细介绍)。
Due to the granularity of services, there might be many requests. It can be inefficient and increase latency. Although there are ways to reduce the number of calls the client sends (see the section about GraphQL), developers might drift and execute inadvertently the logic with more requests than needed.
由于服务的粒度,可能会有很多请求。 它可能效率低下并增加了延迟。 尽管有很多方法可以减少客户端发送的调用次数(请参阅有关GraphQL的部分),但是开发人员可能会不慎漂移并无意中执行了比所需数量更多请求的逻辑。
After reviewing these drawbacks, the next step is to see how to mitigate them as much as possible during the planning and the implementation stages.
在审查了这些缺点之后,下一步就是查看如何在计划和实施阶段中尽可能地减轻它们。

2.构建基于微服务的应用程序的注意事项 (2. Considerations for Building a Microservices-based Application)
After reviewing the incentives to build a microservices solution, next is to discuss the considerations during the design and planning stages, which lay the foundations for the implementation.
在回顾了构建微服务解决方案的动机之后,接下来是讨论设计和规划阶段的注意事项,为实施奠定基础。
To deploy a service in microservices solution, we need to know which service to deploy, its version, the target environment, how to publish it, and how it communicates with other services.
要在微服务解决方案中部署服务,我们需要知道要部署的服务,其版本,目标环境,如何发布以及如何与其他服务通信。
Let’s review the considerations in this planning stage:
让我们回顾一下此计划阶段中的注意事项:
服务模板-标准化 (Service Templates — Standardization)
Since each service is decoupled from the rest, the development team can be easily drifted away and build each service differently. This has its toll; lack of standardization costs more in testing, deploying, and maintaining the system. Therefore, the benefits of using standards are:
由于每个服务都与其他服务分离开来,因此开发团队可以轻松撤离,并以不同的方式构建每个服务。 这是有代价的; 缺乏标准化会在测试,部署和维护系统上付出更多的代价。 因此,使用标准的好处是:
- Creating services faster; the scaffold is already there. 更快地创建服务; 脚手架已经在那里。
- Familiarization with services is easier. 熟悉服务更容易。
- Enforcing best-practices as part of the development phase. 在开发阶段执行最佳实践。
Standardization should include not only the API the service exposes, but also the response structure and the error handling. One solution to enforce guidelines is using a service template utility, which can be tailored to the development practices you define. For example:
标准化不仅应包括服务公开的API,还应包括响应结构和错误处理。 实施准则的一种解决方案是使用服务模板实用程序,可以根据您定义的开发实践进行定制。 例如:
Dropwizard (Java), Governator (Java)
Dropwizard (Java), Governor (Java)
Cookiecutter (Python)
Cookiecutter (Python)
Jersey (REST API)
泽西 (REST API)
For more service templates tools, please refer to reference [1].
有关更多服务模板工具的信息,请参考参考文献[1]。
版本控制 (Versioning)
Each service should have a version, which updates regularly in every release. Versioning allows to identify a service and deploy a specific version of it. It also enables the consumers of the service to be aware when the service has changed, and by that avoid breaking the existing contract and the communication between the services.
每个服务都应具有一个版本,该版本会在每个发行版中定期更新。 版本控制允许识别服务并部署其特定版本。 它还使服务的使用者可以知道服务已更改的时间,从而避免破坏现有合同和服务之间的通信。
Different versions of the same service can coexist. With that, the migration from the old version of the new version can be gradual without having too much impact on the whole application.
相同服务的不同版本可以共存。 这样,可以从旧版本到新版本的逐步迁移,而不会对整个应用程序产生太大影响。
文献资料 (Documentation)
In a microservices environment, there are many small services that communicate constantly with each other, so it is easier to get lost in what the service does or how to use its API.
在微服务环境中,有许多小型服务相互持续通信,因此更容易迷失该服务的功能或如何使用其API。
Documentation can facilitate that. Keeping valid up-to-date documentation is a tedious and time-consuming task. Naturally, this can be prioritised low in the tasks list of the developer. Therefore, automation is required instead of documenting manually (readme files, notes, procedures). There are various tools to codify and automate tasks to keep the documentation updated while the code continues to change. Tools like Swagger UI or API Blueprint can do the job. They can generate a web UI for your microservices API, which alleviates the orientation efforts. once again, standardization is an advantage; for example, Swagger implements the OpenAPI specification, which is an industry-standard.
文档可以简化这一过程。 保持有效的最新文档是一项繁琐且耗时的任务。 自然,可以在开发人员的任务列表中将其排在较低的优先级。 因此,需要自动化而不是手动记录(自述文件,说明,过程)。 有多种工具可用于整理和自动化任务,以在代码不断更改的同时保持文档更新。 诸如Swagger UI或API Blueprint之类的工具可以完成此任务。 他们可以为您的微服务API生成一个Web UI,从而减轻了定向工作。 标准化再次是一个优势。 例如,Swagger实现了行业标准OpenAPI规范。
服务发现 (Service Discovery)
After discussing some code development aspect, let’s talk about planning how to add a new service to the system.
在讨论了一些代码开发方面之后,让我们讨论如何计划如何向系统添加新服务。
When deploying a new service, orientation is essential for both the new service and for the other counterpart services to establish communication. Service discovery allows services to communicate with each other, and increase the clarity in monitoring each service individually.
部署新服务时,方向对于新服务和其他对等服务建立通信至关重要。 服务发现使服务可以相互通信,并提高了分别监视每个服务的清晰度。
Service discovery is built on a service registry solution, which maintains the network locations of all the instances of a service. Service discovery can be implemented in one of two ways: static and dynamic.
服务发现基于服务注册表解决方案,该解决方案维护服务的所有实例的网络位置。 可以通过以下两种方式之一实现服务发现:静态和动态。
Static Service Discovery
静态服务发现
In a DNS solution, an IP address is associated with a name, which means a service has a unique address that allows clients to find it. DNS is a well-known standard, which is an advantage. However, if the environment is dynamic and frequent changes of services’ paths are required, choosing DNS may not be the best solution since updating the DNS entries can be painful. Revoking the old IP address depends on the DNS TTL value.Furthermore, clients can keep the DSN in memory or some cache, which leads to stale states. Using load-balancers as a buffer between the service and its consumers is one option to bypass this problem, but it may complicate the overall solution if there is no actual need to maintain laid-balancers.
在DNS解决方案中,IP地址与名称相关联,这意味着服务具有唯一的地址,允许客户端找到它。 DNS是众所周知的标准,这是一个优势。 但是,如果环境是动态的,并且需要频繁更改服务路径,则选择DNS可能不是最佳解决方案,因为更新DNS条目可能很麻烦。 撤销旧IP地址取决于DNS TTL值。此外,客户端可以将DSN保留在内存或某些缓存中,从而导致状态过时。 使用负载平衡器作为服务与其使用者之间的缓冲是避免此问题的一种选择,但是如果实际上不需要维护平衡器,则可能会使整个解决方案变得复杂。
Dynamic Service Discovery
动态服务发现
The traditional way to read the services’ addresses from a configuration file (locally or somewhere on the network) is not flexible enough, as changes are done frequently. Instances are assigned the network location automatically, so maintaining a central configuration is not efficient and almost not practical. To solve this problem, there are two dynamic service discovery approaches client-side discovery or server-side discovery. First, we describe how services are being discovered, and afterwards how there are registered into the system.
从配置文件(本地或网络上的某个地方)读取服务地址的传统方法不够灵活,因为更改频繁。 系统会自动为实例分配网络位置,因此维护中央配置效率不高,几乎不切实际。 为了解决此问题,有两种动态服务发现方法: 客户端发现或服务器端发现 。 首先,我们描述如何发现服务,然后描述如何将其注册到系统中。
Client-side Discovery
客户端发现
In this dynamic discovery approach, the client queries the service registry for instances of other services. After obtaining the information, the responsibility lies on the client to determine the network locations of these instances and how to make requests to access them, can be via load balancers or direct communication.
在这种动态发现方法中,客户端在服务注册表中查询其他服务的实例。 在获取信息之后,可以通过负载平衡器或直接通信来负责确定这些实例的网络位置以及如何提出访问它们的请求的责任由客户端承担。
This approach has several advantages:
这种方法有几个优点:
- The service registry and the service instances are the only actors. The client has to draw the information from the service registry, and straightforwardly it can communicate with the rest of the services. 服务注册表和服务实例是唯一的参与者。 客户端必须从服务注册表中提取信息,并且可以直接与其余服务进行通信。
- The client decides which route is the most efficient to connect to the other services, based on choosing the path via the load balancers. 客户端根据通过负载平衡器选择的路径来确定连接到其他服务的最有效的路由。
- For making a request there are only a few hops. 对于发出请求,只有几跳。
However, the disadvantages of the client-side discovery approach are:
但是,客户端发现方法的缺点是:
- The clients are coupled to the service registry; without it, new clients may be blind for the existence of other services. 客户端耦合到服务注册表; 没有它,新客户可能对其他服务的存在视而不见。
- The client-side routing logic has to be implemented in every service. It hurts if the services differ by their tech-stack, which means this logic should be implemented across different technologies. 客户端路由逻辑必须在每个服务中实现。 如果服务因技术栈而异,那会很痛苦,这意味着此逻辑应在不同技术之间实现。

Server-side Discovery
服务器端发现
The second dynamic discovery approach is server-side. In this approach, the client is more naive, as it communicates only with a load-balancer. This load-balancer interacts with the service-registry and routes the client’s request to the available service instance. This approach is used by Kubernetes or AWS ELB (Elastic Load Balancer).
第二种动态发现方法是服务器端。 在这种方法中,客户端更加幼稚,因为它仅与负载均衡器进行通信。 该负载平衡器与服务注册表交互,并将客户端的请求路由到可用的服务实例。 Kubernetes或AWS ELB(弹性负载平衡器)使用此方法。
The main advantage of this approach is offloading the client from figuring out the network while focusing on communicating with other services without handling the “how”. Nevertheless, the drawback is the necessity of having another tool (load-balancer) to communicate with the service registry. Although, registry services have this functionality embedded already.
这种方法的主要优点是使客户不必担心网络问题,而可以专注于与其他服务进行通信,而无需处理“方法”。 但是,缺点是必须使用另一个工具(负载均衡器)与服务注册表进行通信。 虽然,注册服务已经嵌入了此功能。

For further reading about service discovery, please refer to reference [2]
有关服务发现的更多信息,请参考参考文献[2]。
服务注册中心 (Service Registries)
So far, we discussed how a service is discovered among the other services, and how it maps the other services in the network and communicates with them. In this section, the focus is on how services are being registered into the system. Basically, a list of all services is stored in a database containing the network locations of all service instances. Although this information can be cached on the client-side, this repository should be updated, consistent and highly available to ensure services can communicate upon loading.
到目前为止,我们讨论了如何在其他服务中发现服务,以及如何映射网络中的其他服务并与之通信。 在本节中,重点是如何将服务注册到系统中。 基本上,所有服务的列表都存储在包含所有服务实例的网络位置的数据库中。 尽管此信息可以在客户端缓存,但是应该更新该存储库,使其保持一致并且高度可用,以确保服务在加载时可以进行通信。
There are two patterns of service registration:
服务注册有两种模式:
Self-Registration
自我注册
As the name implies, the responsibility on registering and deregistering is on the new instance itself. After the instantiation of an instance, as part of the start-up process, the service sends a message to the service registry “hi, I’m here”. During the period the service is alive, it sends heartbeat messages to notify the service registry that it is still functioning to avoid its expiry. In the end, before the service terminates, it sends a Goodbye message.
顾名思义,注册和注销的责任在于新实例本身。 实例化实例之后,作为启动过程的一部分,服务会向服务注册表发送一条消息“嗨,我在这里”。 在服务处于活动状态期间,它将发送心跳消息以通知服务注册表它仍在起作用以避免其过期。 最后,在服务终止之前,它将发送“再见”消息。
Similarly to the client-side registration, the main advantage of this approach is its simplicity. The implementation is solely on the service itself. However, this is also a disadvantage. The service instances are coupled to internal implementation. In case there are several tech-stacks, each should implement the registration, keep alive, and deregistration logic.
与客户端注册类似,此方法的主要优点是简单。 实施完全在服务本身上。 但是,这也是一个缺点。 服务实例耦合到内部实现。 如果存在多个技术堆栈,则每个堆栈都应实现注册,保持活动状态和注销逻辑。

Third-Party Registration
第三方注册
This approach puts in the centre a service that handles the registration by tracking changes (the Registrar service); it can be done either by subscribing to events or by pulling information from the environment. When the registrar finds a new instance, it saves it into the service registry. Only the registrar interacts with the service registry; the new microservice is not playing actively in the registration process. This registrar service ensures instances are alive using health checks messages.
这种方法将通过跟踪更改来处理注册的服务置于中心(注册服务); 可以通过订阅事件或从环境中获取信息来完成。 当注册服务商找到新实例时,会将其保存到服务注册表中。 只有注册服务商与服务注册管理器进行交互; 新的微服务在注册过程中没有积极发挥作用。 此注册服务通过使用运行状况检查消息来确保实例处于活动状态。
The benefits of choosing this approach are offloading the microservice from managing its registration, and decoupling it from the registry service. The registrar manages the registration; an implementation of proactive keep-alive is not required anymore. The drawback, similarly to server-side discovery pattern, arises if the service registry tool is not part of the microservices orchestration tool too. For example, you can use Apache Zookeeper as your service registry. Alternatively, some orchestration platforms include built-in service registry features too, Kubernetes for example.
选择这种方法的好处是可以减轻微服务的管理负担,并将其与注册表服务分离。 由注册商管理注册; 不再需要执行主动保持活动。 如果服务注册表工具也不是微服务编排工具的一部分,则会出现类似于服务器端发现模式的缺点。 例如,您可以将Apache Zookeeper用作服务注册表。 或者,某些业务流程平台也包含内置的服务注册表功能,例如Kubernetes。

For further reading about service registry, please refer to reference [3]
有关服务注册表的更多信息,请参考参考文献[3]。
数据库事务处理方法:ACID与BASE (Database Transaction Approach: ACID vs. BASE)
Another important aspect of designing a microservices solution is how and where to save data into the repositories. In a microservice architecture, databases should be private; otherwise, the services will be coupled to a common resource.
设计微服务解决方案的另一个重要方面是如何以及在何处将数据保存到存储库中。 在微服务架构中,数据库应该是私有的。 否则,服务将耦合到公共资源。
Although a shared database pattern is simple and easy to start with, it is not recommended since it breaks the autonomy of services; the implementation of one service depends on an external component. Moreover, the service is coupled with a certain technology (database), while having the need to maintain the same Data Access Layer (DAL) in more than one service. Therefore, this approach is not recommended.
尽管共享数据库模式简单易上手,但不建议这样做,因为它破坏了服务的自治性。 一项服务的实施取决于外部组件。 此外,该服务与某种技术(数据库)耦合,同时需要在多个服务中维护相同的数据访问层(DAL)。 因此,不建议使用此方法。
Instead of sharing a database between services, it can be split into the relevant microservices, based on their domain; this approach is more complex compared to the monolithic solution. In the monolithic application, transactions are ACID compliant: Atomic, Consistent, Isolated, and Durable. A transaction is either succeeded or not, keeps the defined constraints, data is visible immediately after the commit operation, and the data is available once the transaction is completed.
无需在服务之间共享数据库,而是可以根据它们的域将其拆分为相关的微服务。 与整体解决方案相比,这种方法更加复杂。 在整体应用系统,交易符合ACID: 一个托米奇,C onsistent, 我溶状,和d urable。 事务成功与否,保留定义的约束,提交操作后立即可见的数据以及事务完成后可用的数据。
In the microservice realm, ACID concepts cannot exist. One alternative is to implement a distributed transactions mechanism, but it is hard to develop and maintain. Thus, although it seems an obvious solution, it is better not to start with a distributed transactions pattern as the first choice; there is another way.
在微服务领域,ACID概念不存在。 一种替代方法是实施分布式事务处理机制,但是很难开发和维护。 因此,尽管看似显而易见的解决方案,但最好不要以分布式事务处理模式作为首选。 还有另一种方式。
The alternative is to adhere to the BASE approach: Basic Availability, Soft-state, and Eventual consistency. Meaning, data will be available on the basic level until it is fully distributed to all datastores. In this model, there is no guarantee for immediate and isolated transactions, but there is a goal to achieve consistency eventually. One implementation of this approach is called CQRS (Command and Query Responsibility Segregation); for more information, please refer to reference [4].
另一种方法是附着于BASE的方法: 乙 ASIC中的 vailability,S经常状态,和E ventual一致性。 这意味着,数据将在基本级别上可用,直到将其完全分发到所有数据存储。 在此模型中,无法保证立即进行的交易和隔离的交易,但是最终要实现一致性。 这种方法的一种实现方式称为CQRS(命令和查询责任隔离)。 有关更多信息,请参考参考文献[4]。
In any case, analysing the required transactions mode is paramount to design the suitable transactivity model. If an operation must be ACID, then a microservice should be designed to encapsulate it while implementing ACID transactions locally. However, not all transaction must be atomic or isolated (ACID-based), some can compromise on BASE approach, which gives the flexibility in defining domains, decoupling operations, and enjoying the benefits of using microservices.
无论如何,分析所需的交易模式对于设计合适的交易模型至关重要。 如果某个操作必须是ACID,则应设计微服务以在本地实现ACID事务时封装它。 但是,并非所有事务都必须是原子事务或隔离事务(基于ACID),某些事务可能会折衷于BASE方法,这为定义域,解耦操作和享受使用微服务的好处提供了灵活性。
为每个服务分配资源 (Allocating Resources for each Service)
At this article, the last aspect of planning is allocating adequate resources for our solution. The flexibility of scaling-out has its toll while planning the underlying hardware of a microservices-based application. We need to gauge the required hardware to supply a varying demand.
在本文中,规划的最后一个方面是为我们的解决方案分配足够的资源。 在计划基于微服务的应用程序的基础硬件时,横向扩展的灵活性会带来很多损失。 我们需要评估所需的硬件以提供变化的需求。
Therefore, the planner should estimate each microservice’s growth scale and its upper barrier; the consumption of service cannot be endless. Examining business needs should be the starting point for extrapolating the future use of each service. These needs define the metrics to determine whether the service will be scaled-out or not; they can include, for example, the number of incoming requests, or expected outgoing calls, frequency of calls, and how it impacts the other services too.
因此,计划者应估计每个微服务的增长规模及其上限。 服务的消费不可能是无止境的。 检查业务需求应该是推断每种服务将来使用的起点。 这些需求定义了用于确定服务是否将被横向扩展的指标。 例如,它们可以包括传入请求的数量或预期的传出呼叫的数量,呼叫的频率以及它如何影响其他服务。
The next step is to set a “price” tag for the expected growth in terms of CPU, memory, network utilization, and other metrics that impact the essential hardware to sustain the services’ growth.
下一步是在CPU,内存,网络利用率以及其他影响必要硬件以维持服务增长的指标方面,为预期增长设置“价格”标签。
You might be thinking this step is not necessary if our system runs on the cloud since the resources are (theoretically) endless, but it is a misconception. Firstly, even the cloud resources are limited in their compute and storage. Secondly, growth comes with a financial cost, mainly an unplanned growth, which impacts the budget of the project.
您可能会认为,如果我们的系统在云上运行,则由于资源(理论上)是无止境的,因此无需执行此步骤,但这是一种误解。 首先,即使云资源的计算和存储也受到限制。 其次,增长伴随着财务成本,主要是计划外的增长,这会影响项目的预算。
Once the application is in production, coping with an undervalued resource allocation may affect business aspects (SLA, budget), and thus it is essential to address this aspect before rushing to implement our solution.
一旦应用程序投入生产,处理低估的资源分配可能会影响业务方面(SLA,预算),因此在急于实施我们的解决方案之前解决此方面至关重要。
3.微服务实现 (3. Microservices Implementation)
After we reviewed the aspects to consider during the planning phase, this section focuses on the principles for implementation and maintaining the microservices application.
在审查了计划阶段要考虑的方面之后,本节重点介绍实现和维护微服务应用程序的原则。
规划弹性 (Planning for Resilience)
The microservices solution is composed of many isolated, but communicative, parts, so the nature of problems differs from the monolith world. Failures happen in every system, all the more so in a distributes interconnected system; therefore, planning how to tackle these problems on the design stage is needed.
微服务解决方案由许多孤立但可通信的部分组成,因此问题的性质与整体世界不同。 每个系统都会发生故障,在分布式互连的系统中更是如此。 因此,需要在设计阶段计划如何解决这些问题。
The existing reliability and fault-tolerant mechanisms that are used in SOA (service-oriented architectures), can be used in a microservices architecture. Some of these patterns are:
SOA(面向服务的体系结构)中使用的现有可靠性和容错机制可以在微服务体系结构中使用。 其中一些模式是:
Timeouts
超时时间
This is an effective way to abort calls that take too long or fail without returning back to the caller in a timely manner. It is better to set the timeout on the requestor side (the client) than rely on the server’s or the network’s timeout; each client should protect itself from being hung by an external party. When a timeout happens, it needs to be logged as it might be caused by a network problem or some other issue besides the service itself.
这是中止时间太长或失败而又不及时返回到呼叫者的有效方法。 最好在请求方(客户端)上设置超时,而不是依赖于服务器或网络的超时。 每个客户都应保护自己免受外界干扰。 发生超时时,需要将其记录下来,因为它可能是由网络问题或服务本身以外的其他问题引起的。
Retries
重试
Failing in receiving a valid response can be due to an error or timeout. The retry mechanism allows sending the same request more than once. It’s important to limit the number of retries, otherwise, it can be an endless cycle that generates an unnecessary load on the network. Moreover, you can widen the retries interval (the first retry after 100 milliseconds, the second retry after 250 milliseconds, and the third retry after 1 second), based on the use-case of the request.
未能收到有效的响应可能是由于错误或超时引起的。 重试机制允许多次发送相同的请求。 限制重试次数很重要,否则,这可能是一个无休止的循环,会在网络上产生不必要的负载。 此外,您可以根据请求的用例来扩大重试间隔(第一次重试100毫秒后,第二次重试在250毫秒后,第三次重试在1秒后)。
Handshaking
握手
The idea behind this pattern is to assure the service on the other side is available, before executing the actual request. If the service is not available, the requestor can choose to wait, notify back to the caller, or find another alternative to fulfil the business logic. This approach offloads the system from unproductive communication.
该模式背后的思想是在执行实际请求之前,确保另一端的服务可用。 如果该服务不可用,则请求者可以选择等待,通知给调用者或找到其他替代方案来实现业务逻辑。 这种方法使系统摆脱了无效的通信。
Throttling
节流
Throttling ensures the server can provide service for all requestors. It protects the service itself from being loaded, and also the clients from keep on sending futile requests. It can reduce the latency by signalling there is no point in executing retries.
节流确保服务器可以为所有请求者提供服务。 它可以保护服务本身免于加载,也可以防止客户端继续发送无用的请求。 它可以通过发信号通知没有重试的执行来减少等待时间。
The throttling approach is an alternative to the autoscaling, as it sets a top barrier to the service level agreement (SLA) rather than catering the increased demand. When a service reaches its max throughput, the system monitors it and raises an alert rather than scaling-out automatically. The throttling configuration can be based on various aspects; here are some suggestions. First, the number of requests per given period (millisecond/seconds/minutes) from the same client for the same or similar information. Second, the service can disregard requests from clients it deems as nonessential or not-important in a given time; it gives priority for other services instead. Lastly, to consume fewer resources and supply the demand, the service can continue providing service but with reduced quality; for example, lower resolution video streaming rather than cease the streaming totally.
节流方法是自动扩展的替代方法,因为它为服务水平协议(SLA)设置了最大障碍,而不是满足不断增长的需求。 当服务达到其最大吞吐量时,系统会对其进行监视并发出警报,而不是自动向外扩展。 节流配置可以基于各个方面;例如,基于多个方面。 这里有一些建议。 首先,每个给定时间段(相同的毫秒数/秒/分钟)中来自相同客户端的相同或相似信息的请求数。 其次,该服务可以忽略在给定时间内来自其认为无关紧要或不重要的客户端的请求; 它优先考虑其他服务。 最后,为了减少资源消耗并满足需求,服务可以继续提供服务,但质量会降低; 例如,较低分辨率的视频流而不是完全停止流。
Another benefit of using throttling is enhanced security; it limits a potential DDOS attack, prevents data harvesting, and blocks irresponsible requests.
使用限制的另一个好处是增强了安全性。 它限制了潜在的DDOS攻击,阻止了数据收集并阻止了不负责任的请求。
Bulkheads
隔板
This pattern ensures that faults in one part of the system do not take the other parts down. In a microservices architecture, when each service is isolated, naturally when a service is down the effect is limited. However, when boundaries between microservices are not well defined, or when microservices share repository (not recommended), the bulkhead pattern is not adhered to. Besides partitioning the services, consumers can be partitioned as well, meaning isolating critical consumers from standard consumers. Using the bulkheads approach increases the flexibility in monitoring each partition’s performance and SLA (for more information, please refer to reference [5]).
这种模式可确保系统某一部分的故障不会使其他部分停机。 在微服务架构中,当每个服务被隔离时,自然而然地,当一个服务关闭时,效果是有限的。 但是,当微服务之间的边界没有很好地定义时,或者当微服务共享存储库(不推荐)时,将不遵循隔板模式。 除了对服务进行分区之外,也可以对使用者进行分区,这意味着将关键使用者与标准使用者隔离开。 使用隔板方法增加了监视每个分区的性能和SLA的灵活性(有关更多信息,请参考参考文献[5])。
Circuit breakersAn electrical circuit breaker halts the electricity connection when a certain threshold has breached. Similarly, a service can be flagged as down or unavailable after clients fail to interact with it. Then, clients will avoid sending more requests to the “blown” service and offload the void calls in the system. After a cool-down period, the clients can resume their requests to the faulty service, hoping it has revived. If the requests were handled successfully, the circuit breaker is reset.
断路器当达到某个阈值时,断路器将暂停电连接。 同样,在客户端无法与服务交互后,可以将服务标记为已关闭或不可用。 然后,客户端将避免向“吹制”服务发送更多请求,并减轻系统中的无效调用的负担。 冷静期过后,客户端可以恢复对故障服务的请求,希望它恢复了。 如果成功处理了请求,则会重置断路器。
Using these safety measurements allows handling errors more gracefully. In some of the patterns above, there is a client that failed to receive a valid response from the server. How to handle these faulty requests? In the synchronous call, the solution can be logging the error and propagate it to the caller. In asynchronous communication, requests can be queued up for later retries. For more information about resiliency patterns, please refer to reference[6].
使用这些安全度量可以更优雅地处理错误。 在上述某些模式中,有一个客户端未能从服务器收到有效响应。 如何处理这些错误的请求? 在同步调用中,解决方案可以记录错误并将其传播给调用方。 在异步通信中,可以将请求排队等待以后重试。 有关弹性模式的更多信息,请参考参考文献[6]。
服务到服务的沟通与协调 (Service-to-service Communication and Coordination)
Service-to-service communication can be divided into two types: synchronous and asynchronous. The synchronous communication is easy to implement, but impractical for long-running tasks since the client hangs.
服务到服务的通信可以分为两种:同步和异步。 同步通信易于实现,但由于客户端挂起,因此对于长时间运行的任务不可行。
On the other side, asynchronous communication frees the client from waiting for a response after calling another service, but it is more complicated to manage the response. Either low-latency systems or intermittent online system, as well as long-running tasks, Can benefit from this approach
另一方面, 异步通信使客户端从调用另一个服务后不必等待响应,但是管理响应更为复杂。 低延迟系统或间歇性在线系统以及长时间运行的任务都可以从这种方法中受益
How do services coordinate? There are two collaboration patterns:
服务如何协调? 有两种协作模式:
OrchestrationSimilarly to a conductor of an orchestra, there is a central brain that manages the business processes, similarly to a command-and-control concept. This brain knows every stage of each service and able to track it. Events can flow directly via the orchestrator or through a message broker, while the communication flows between the message broker and the orchestrator. The communication is based on the request-response concept. Therefore, this approach is more associated with the synchronous approach.
编排类似于管弦乐队的指挥者,有一个中央大脑来管理业务流程,类似于命令和控制概念。 这个大脑知道每个服务的每个阶段并能够对其进行跟踪。 事件可以直接通过协调器或消息代理传递,而通信可以在消息代理和协调器之间传递。 通信基于请求-响应概念。 因此,此方法与同步方法更多相关。
The decision making relies on the orchestrator; each service executes its business logic and returns the output without any decisions about the next step or the overall flow. The next pattern, Choreography, has a different approach.
决策取决于协调者; 每个服务执行其业务逻辑并返回输出,而无需任何有关下一步或总体流程的决定。 下一个模式“编排”具有不同的方法。

ChoreographyAs opposed to Orchestrator patters, the Choreography pattern decentralizes the control to each service; each service works independently. Thus, each service decides the next step solely without being instructed by centralised control. Events are broadcasted and each service decides whether this information is relevant to its business logic or not; the “brain” is embedded in each service.
编排与Orchestrator的模式相反,编排模式将控件分散到每个服务。 每个服务独立工作。 因此,每个服务仅决定下一步,而无需集中控制的指令。 广播事件,每个服务确定此信息是否与其业务逻辑相关; 每个服务都嵌入了“大脑”。
The flow is based on sharing events, which creates a loosely coupled communication, mainly based on the event-driven concept. Therefore, this approach is more natural for asynchronous communication.
该流基于共享事件,这主要基于事件驱动的概念来创建松散耦合的通信。 因此,这种方法对于异步通信更为自然。

To make it more tangible, in the AWS platform, Orchestrator can be implemented with Step Functions, whereas Event Bridge or SNS service can be the underlying solution for a Choreography-To make it more tangible, in the AWS platform, Orchestrator can be implemented with Step Functions service, whereas Event Bridge or SNS service can be the underlying solution for a Choreography-based application.
为了使它更明显,在AWS平台中,可以使用Step Functions来实现Orchestrator,而事件桥或SNS服务可以成为编排的基础解决方案。要使它更明显,在AWS平台中,可以将Orchestrator与步骤功能服务,而事件桥或SNS服务可以是基于编排的应用程序的基础解决方案。
Each of these two patterns is legit, preferring one over the other depends on the business use cases and needs. Nevertheless, the Choreography approach is more difficult to monitor since there is no central controller, and there is no mediator to intervene and prevent cascading failures. That’s the reason that implementing timeouts or understanding the whole logic is more complicated (for delving into each approach, please refer to reference [7]).
这两种模式中的每一种都是合法的,因此优先选择一种取决于业务用例和需求。 但是,由于没有中央控制器,也没有调解人干预和防止级联故障,因此编排方法更难监控。 这就是实现超时或理解整个逻辑更加复杂的原因(要深入研究每种方法,请参考参考文献[7])。
Lastly, the decision to choose between Orchestrator to Choreography does not have to be so dichotomic. Your system may be decomposable further into subcomponents, each of which lending itself more towards Orchestration or Choreography individually.
最后,在编排与编排之间进行选择的决定不必如此二分法。 您的系统可能进一步分解为子组件,每个子组件都更适合分别用于编排或编排。
Now, let’s look at the ways to implement the communications between services.
现在,让我们看一下实现服务之间通信的方法。
同步通讯 (Synchronous Communication)
The request/response communication is more suitable for n-tier applications, in which a requestor should wait for a response.
请求/响应通信更适合于n层应用程序,在该应用程序中,请求者应等待响应。
Let’s cover three basic synchronous communication technologies: RPC, REST, and GraphQL.
让我们介绍三种基本的同步通信技术:RPC,REST和GraphQL。
RPC — Remote Process Protocol
RPC —远程处理协议
This is an inter-process communication where a client makes a local method call that executes on a remote server. The classic example is SOAP. The client calls a local stub, the call is transferred over the network and the logic runs on a remote service.
这是一种进程间通信,其中客户端进行在远程服务器上执行的本地方法调用。 经典示例是SOAP。 客户端调用本地存根,该调用通过网络转移,并且逻辑在远程服务上运行。
RPC is easy to use and it’s easy to use as if calling a local method. On the other hand, the drawbacks are the tight coupling between the client and the server, and a strict API.Recently, with the emerge of gRPC and HTTP/2, this approach flourishes again.
RPC易于使用,并且就像调用本地方法一样易于使用。 另一方面,缺点是客户端和服务器之间的紧密耦合以及严格的API。最近,随着gRPC和HTTP / 2的出现,这种方法再次兴起。
2. REST — Representational State Transfer
2. REST-代表性状态转移
REST is a strict pattern of querying and updating data, mostly in JSON or XML format. REST is protocol-agnostic but mostly associated with HTTP. At the base of this pattern, REST uses verbs to get or update data, for example, GET, POST, PUT, PATCH.REST allows to completely decouple the data representation from its actual structure, which enables flexibility in keeping the same API although the underneath logic or model might change.
REST是查询和更新数据的严格模式,大多数情况下为JSON或XML格式。 REST与协议无关,但大多数与HTTP相关。 在此模式的基础上,REST使用动词来获取或更新数据,例如GET,POST,PUT,PATCH.REST允许将数据表示形式与其实际结构完全脱钩,从而可以灵活地保持相同的API,尽管逻辑或模型下面的内容可能会发生变化。
REST follows the HATEOAS principles (Hypermedia As The Engine Of Application State) that apply links to other resources as part of the response. It enhances the API self-discoverability by allowing the client to use these links in future requests.
REST遵循HATEOAS原则(作为应用程序状态引擎的超媒体),将链接应用于其他资源作为响应的一部分。 通过允许客户端在将来的请求中使用这些链接,它增强了API的自发现性。
The abstraction that REST implements is a huge advantage. On the other hand, there are some disadvantages. The additional links the HATEOAS generates can lead to many requests in the server-side, which means a simple GET request can return many unnecessary details.
REST实现的抽象是一个巨大的优势。 另一方面,存在一些缺点。 HATEOAS生成的其他链接可以导致服务器端出现许多请求,这意味着简单的GET请求可以返回许多不必要的详细信息。
Another drawback can happen when using REST response adversely when returning more information than needed or deserializing all the underlying objects as they are represented in the data layer, which means not using the capability of abstracting the data model. Lastly, REST doesn’t allow generating client stubs easily, as opposed to RPC. Meaning the client has to build this stub if needed.
当使用REST响应时,如果返回的信息多于所需的信息或对所有底层对象进行反序列化(如在数据层中表示的那样),则可能会产生另一个缺点,这意味着不使用抽象数据模型的功能。 最后,与RPC相反,REST不允许轻松生成客户端存根。 这意味着如果需要,客户端必须构建此存根。
HTTP/1.1 200 OK
Content-Type: application/vnd.acme.account+jsonContent-Length: …
{
"account": {
"account_number": 12345,
"balance": {
"currency": "usd",
"value": 100.00
},
"links": {
"deposit": "/accounts/12345/deposit",
"withdraw": "/accounts/12345/withdraw",
"transfer": "/accounts/12345/transfer",
"close": "/accounts/12345/close"
}
}
}3. GraphQL
3. GraphQL
GrapQL is a relatively new technology, which can be considered as an evolvement for REST, but also include some RPC concepts too. GraphQL allows structured access to resources but aims to make the interactions more efficient. As opposed to REST, which is based on well-defined HTTP commands, GraphQL provides a query language to access resources and fields. The query language supports CRUD operations as well.
GrapQL是一项相对较新的技术,可以认为是REST的发展,但也包含一些RPC概念。 GraphQL允许结构化地访问资源,但旨在使交互更加有效。 与基于定义明确的HTTP命令的REST相反,GraphQL提供了一种查询语言来访问资源和字段。 查询语言也支持CRUD操作。
The client defines fields and hierarchies for querying the server, so the client’s business logic should be familiar with its need. With that, the client can receive more information with fewer requests. Receiving the same information in REST requires several GET requests along with combining them on the client-side. Therefore, GraphQL is more efficient by saving network requests.
客户端定义了用于查询服务器的字段和层次结构,因此客户端的业务逻辑应熟悉其需求。 这样,客户端可以通过更少的请求接收更多信息。 在REST中接收相同的信息需要几个GET请求,并在客户端将它们组合在一起。 因此,GraphQL通过保存网络请求更加有效。
Another advantage is being agnostic to any programming language. Similarly to RPC, GraphQL provides the schema of the objects on the server, which is very useful for orientation purposes. Not only it allowed the client to define what to query (hierarchy, fields), but also how and where to fetch data (Resolver).
另一个优势是与任何编程语言无关。 Similarly to RPC, GraphQL provides the schema of the objects on the server, which is very useful for orientation purposes. Not only it allowed the client to define what to query (hierarchy, fields), but also how and where to fetch data (Resolver).
It also has a publish/subscribe model, so the client can receive notifications when data has changed.
It also has a publish/subscribe model, so the client can receive notifications when data has changed.

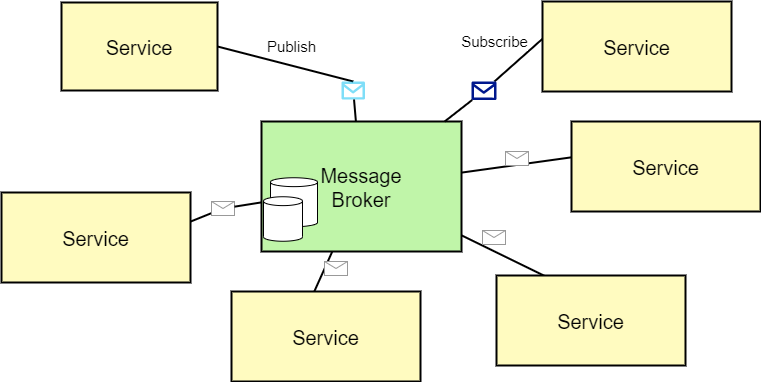
Asynchronous Communication (Asynchronous Communication)
Events-based collaboration is based on asynchronous communication. It requires the server to emit events, and clients (consumers) to be notified on the events and fetch them.
Events-based collaboration is based on asynchronous communication. It requires the server to emit events, and clients (consumers) to be notified on the events and fetch them.
This mechanism is achieved by using a message broker, which manages a publish/subscribe solution. It also keeping track of what message was seen, to avoid multiple consumers for the same message. Using message broker adheres to the concept of smart endpoint, dumb pipes. The client handles the business logic, while the broker handles the communication and transportation.
This mechanism is achieved by using a message broker, which manages a publish/subscribe solution. It also keeping track of what message was seen, to avoid multiple consumers for the same message. Using message broker adheres to the concept of smart endpoint, dumb pipes . The client handles the business logic, while the broker handles the communication and transportation.
Along with that, using a message broker adds complexity in all SDLC phases (development until monitoring the solution in production). Since communication is async, the overall solution should include advanced monitoring, correlation IDs, and tracing to tackle failures and problems (described in the Monitoring chapter, Part 4). Nevertheless, this approach allows full decoupling between all the components, as well as scalability options almost seamlessly.
Along with that, using a message broker adds complexity in all SDLC phases (development until monitoring the solution in production). Since communication is async, the overall solution should include advanced monitoring, correlation IDs, and tracing to tackle failures and problems (described in the Monitoring chapter, Part 4). Nevertheless, this approach allows full decoupling between all the components, as well as scalability options almost seamlessly.
Examples for message brokers are RabbitMQ, Kafka. In the AWS platform, it can be SNS or SQS.
Examples for message brokers are RabbitMQ, Kafka. In the AWS platform, it can be SNS or SQS.
Service to Service Authentication (Service to Service Authentication)
Although services may be communicating in the same network, it is highly advisable to ensure the communication is secured. Besides encrypting the channel (HTTPS, TLS, IPSec), we need to make sure that requests are done by authorised entities. Authentication means the system identifies the client that initiated a request and approves it. The aspect of Authorization, meaning ensuring the entity is allowed to execute the request or receive data, will be covered partially in this article.
Although services may be communicating in the same network, it is highly advisable to ensure the communication is secured. Besides encrypting the channel (HTTPS, TLS, IPSec), we need to make sure that requests are done by authorised entities. Authentication means the system identifies the client that initiated a request and approves it. The aspect of Authorization, meaning ensuring the entity is allowed to execute the request or receive data, will be covered partially in this article.
Authentication is important not only for securing the system, but also for business-domain aspects; for example, choosing the adequate SLA for each consumer.
Authentication is important not only for securing the system, but also for business-domain aspects; for example, choosing the adequate SLA for each consumer.
Authentication solution can be implemented in some ways. Lets review three of them:
Authentication solution can be implemented in some ways. Lets review three of them:
The first solution to consider is using certificates. Each microservices holds a unique certificate that identifies it. Although it is easy to understand, it is hard to manage since the certificates are all over the system; it means the certificates information should be spread across the services. This problem is magnified when dealing with certificates rotation. Therefore, this approach may be relevant for specific services, but not as a comprehensive authentication solution.
The first solution to consider is using certificates. Each microservices holds a unique certificate that identifies it. Although it is easy to understand, it is hard to manage since the certificates are all over the system; it means the certificates information should be spread across the services. This problem is magnified when dealing with certificates rotation. Therefore, this approach may be relevant for specific services, but not as a comprehensive authentication solution.
The second solution is using a single-sign-on service (SSO), like OpenID Connect. This solution routes all traffic through the SSO service on the gateway. It centralises the access-control, but on the other hand, each service should provide its credential to authenticate via the Open Connect module, so it may be a bit tedious. For further reading about OpenID, please refer to reference [8]
The second solution is using a single-sign-on service (SSO), like OpenID Connect. This solution routes all traffic through the SSO service on the gateway. It centralises the access-control, but on the other hand, each service should provide its credential to authenticate via the Open Connect module, so it may be a bit tedious. For further reading about OpenID, please refer to reference [8]
The last solution for authentication is API Keys. The underlying principle of this solution is passing a secret token alongside each request. This token allows the receiver to identify the requestor. In most implementations, there is a centralized gateway to identify the service based on its token.
The last solution for authentication is API Keys. The underlying principle of this solution is passing a secret token alongside each request. This token allows the receiver to identify the requestor. In most implementations, there is a centralized gateway to identify the service based on its token.
There are several standards for token-based authentication, such as API Keys, OAuth, or JWT. Besides authentication, tokens can be used for authorization too. Using tokens allows checking the service’s privileges and its permissions. This is outside of the scope of this article; for further reading, please refer to reference [9].
There are several standards for token-based authentication, such as API Keys, OAuth, or JWT. Besides authentication, tokens can be used for authorization too. Using tokens allows checking the service's privileges and its permissions. This is outside of the scope of this article; for further reading, please refer to reference [9].
4. Tracking the Chain of Events: Logging, Monitoring, and Alerting (4. Tracking the Chain of Events: Logging, Monitoring, and Alerting)
Although this is the last part of this article, it should be in our minds starting from the beginning. Understanding the complete flow of the data is arduous, not mentioning understanding where errors stem from. To overcome this intricacy, there’s a need to reconstruct the chain of calls to be able to reproduce a problem and remediate it thereafter.
Although this is the last part of this article, it should be in our minds starting from the beginning. Understanding the complete flow of the data is arduous, not mentioning understanding where errors stem from. To overcome this intricacy, there's a need to reconstruct the chain of calls to be able to reproduce a problem and remediate it thereafter.
Using a logging system, combined with monitoring and alerting solutions, is essential to understand the chain of events and to cope with identifying problems and rectify them.
Using a logging system, combined with monitoring and alerting solutions, is essential to understand the chain of events and to cope with identifying problems and rectify them.
Logging (Logging)
In the monolithic world, logging is quite straight forward since they are mostly sequential and can be read with a certain order. However, in a microservices architecture, there are multiple logs, so going through them and understanding the data flow can be complex. Therefore, it is paramount to have a tool that aggregate logs, store them, and allows querying them. Such a tool is called Log aggregator.
In the monolithic world, logging is quite straight forward since they are mostly sequential and can be read with a certain order. However, in a microservices architecture, there are multiple logs, so going through them and understanding the data flow can be complex. Therefore, it is paramount to have a tool that aggregate logs, store them, and allows querying them. Such a tool is called Log aggregator.
There are some leading solutions in the market. For example, ELK (Elasticsearch, Logstash, Kibana): Elasticsearch for storing logs, Logstash for collecting logs, and Kibana that provides a query interface for accessing logs.
There are some leading solutions in the market. For example, ELK (Elasticsearch, Logstash, Kibana): Elasticsearch for storing logs, Logstash for collecting logs, and Kibana that provides a query interface for accessing logs.
Another visualization tool is Grafana, which is an open-source platform used for metrics, data visualization, monitoring, and analysis. It can use Elasticsearch as the log repository too, or Graphite repository.
Another visualization tool is Grafana , which is an open-source platform used for metrics, data visualization, monitoring, and analysis. It can use Elasticsearch as the log repository too, or Graphite repository.
Finally, the last tool to present is Prometheus. Prometheus is an all-in-one monitoring system with a rich and multidimensional data model, a concise and powerful query language (PromQL). Grafana can also provide the visualization layer on top of Prometheus.
Finally, the last tool to present is Prometheus. Prometheus is an all-in-one monitoring system with a rich and multidimensional data model, a concise and powerful query language (PromQL). Grafana can also provide the visualization layer on top of Prometheus.
Distributed tracing
Distributed tracing
In any log aggregation solution it is important to standardize the log message format, and define the appropriate usage of all log levels (debug, information, warning, errors, fatal).
In any log aggregation solution it is important to standardize the log message format, and define the appropriate usage of all log levels (debug, information, warning, errors, fatal).
Since logs are spread all over with not order, one of the ways to unravel the sequence is Correlation IDs; a unique identifier is planted in each message after it has been initialized. This identifier allows tracking the message as it passes or processed in each service.
Since logs are spread all over with not order, one of the ways to unravel the sequence is Correlation IDs; a unique identifier is planted in each message after it has been initialized. This identifier allows tracking the message as it passes or processed in each service.
The centralized log finds all the instances in which the message identifier appears and generates a complete flow of this message.
The centralized log finds all the instances in which the message identifier appears and generates a complete flow of this message.
Besides tracking an individual message flow throughout its lifetime, this distributed tracking method can trace the requests between services, which is useful to obtain insights and behaviour of our system. For example, problems like latency, bottlenecks, or overload.
Besides tracking an individual message flow throughout its lifetime, this distributed tracking method can trace the requests between services, which is useful to obtain insights and behaviour of our system. For example, problems like latency, bottlenecks, or overload.
Example of open source solutions that users Correlation ID are Zipkin and Jaeger.
Example of open source solutions that users Correlation ID are Zipkin and Jaeger .
Audit Logging
Audit Logging
Another approach is Audit logging. Each client reports what messages it handles into a database. It is a pretty straightforward approach, which is an advantage; however, the auditing operation is embedded with the business logic, which makes it more complicated.
Another approach is Audit logging. Each client reports what messages it handles into a database. It is a pretty straightforward approach, which is an advantage; however, the auditing operation is embedded with the business logic, which makes it more complicated.
监控方式 (Monitoring)
As you already know, monitoring a microservices environment is much more complex than monitoring a monolith application, whereby there is one main service or several services with well-predicted communication between them.
As you already know, monitoring a microservices environment is much more complex than monitoring a monolith application, whereby there is one main service or several services with well-predicted communication between them.
The main reasons for this complexity are:
The main reasons for this complexity are:
Firstly, the focus on real-time monitoring is greater since microservices solutions are mainly implemented to cope with the large-scale system. Thus, monitoring the state and health of each service and the system as a whole is crucial. A service’s failure might be hidden, or seem negligible, but can have a big impact on the system’s functionality.
Firstly, the focus on real-time monitoring is greater since microservices solutions are mainly implemented to cope with the large-scale system. Thus, monitoring the state and health of each service and the system as a whole is crucial. A service's failure might be hidden, or seem negligible, but can have a big impact on the system's functionality.
Secondly, running many separate services in parallel, either managed by an orchestrator or working independently, can lead to unforeseen behaviour. Not only monitoring in production is complicated, but also simulating all the possible scenarios in a testing lab is not trivial. One way to mitigate this problem, by re-playing messages in a testing environment, but sometimes physical or regulatory limitations do not allow it. So, in some cases, there is no other option but testing fully the comprehensive monitoring solution only in production.
Secondly, running many separate services in parallel, either managed by an orchestrator or working independently, can lead to unforeseen behaviour. Not only monitoring in production is complicated, but also simulating all the possible scenarios in a testing lab is not trivial. One way to mitigate this problem, by re-playing messages in a testing environment, but sometimes physical or regulatory limitations do not allow it. So, in some cases, there is no other option but testing fully the comprehensive monitoring solution only in production.
After we understood the complexity in monitoring microservices-based solution, let’s see what should be monitored.
After we understood the complexity in monitoring microservices-based solution, let's see what should be monitored.
It’s trivial to start with monitoring the individual service based on predefined metrics, such as state, the number of processed messages in a time-frame, and other business-logic related metrics. These metrics can reveal whether a service is working as per normal, or there is some problems or latency. Measuring performance-based on statistics can be beneficial too. For example, if we know the throughput between 1pm to 2pm every day is 20K messages, if the system deviates from this extent, there may be a problem.
It's trivial to start with monitoring the individual service based on predefined metrics, such as state, the number of processed messages in a time-frame, and other business-logic related metrics. These metrics can reveal whether a service is working as per normal, or there is some problems or latency. Measuring performance-based on statistics can be beneficial too. For example, if we know the throughput between 1pm to 2pm every day is 20K messages, if the system deviates from this extent, there may be a problem.
The next step is to monitor the big-picture, the system as a whole using aggregative metrics. Tools like Graphite or Prometheus can gauge the response time of a single service, a group of services, or the system itself. The data is presented in dashboards, which reflect and reveal problems and anomalies. The art is how to define metrics that reflect well the system’s health; monitoring CPU, RAM, network utilization, latency, and other obvious metrics is not enough to understand whether the logic under the hood works as expected.
The next step is to monitor the big-picture, the system as a whole using aggregative metrics. Tools like Graphite or Prometheus can gauge the response time of a single service, a group of services, or the system itself. The data is presented in dashboards, which reflect and reveal problems and anomalies. The art is how to define metrics that reflect well the system's health; monitoring CPU, RAM, network utilization, latency, and other obvious metrics is not enough to understand whether the logic under the hood works as expected.
One of the ways is to use synthetic monitoring. The idea is to generate artificial events and insert them into the processing flow. The results are collected by the monitoring tools and trigger alerts in case of errors or problems.
One of the ways is to use synthetic monitoring. The idea is to generate artificial events and insert them into the processing flow. The results are collected by the monitoring tools and trigger alerts in case of errors or problems.

警示 (Alerting)
Monitoring is essential, but without exposing problems externally, it can be likened to a falling tree in a forest, but no one is there to observe it. Therefore, any system should emit alerts once a certain threshold has reached or a critical scenario should be handled by external intervening.
Monitoring is essential, but without exposing problems externally, it can be likened to a falling tree in a forest, but no one is there to observe it. Therefore, any system should emit alerts once a certain threshold has reached or a critical scenario should be handled by external intervening.
Alerts can be on the system level or the individual microservices level. An alert should be clear and actionable. It is easy to fall into the trap that many errors raise alerts, and by that, the alerts mechanism is being abused and becomes irrelevant.
Alerts can be on the system level or the individual microservices level. An alert should be clear and actionable. It is easy to fall into the trap that many errors raise alerts, and by that, the alerts mechanism is being abused and becomes irrelevant.
Beware of alerts fatigue, as it leads to overlooking critical alerts. Receiving many alerts shouldn’t be a norm, otherwise, it means the alert is mistuned or the system’s configuration should be altered. Therefore, a best-practice is to review the alerts every once in a while.
Beware of alerts fatigue, as it leads to overlooking critical alerts. Receiving many alerts shouldn't be a norm, otherwise, it means the alert is mistuned or the system's configuration should be altered. Therefore, a best-practice is to review the alerts every once in a while.
To handle alerts effectively, there should be a procedure or a guide that describes adequately what’s the nature of the alert and how to mitigate or rectify it. To tackle alerts effectively, the system should include incidents response plan for critical alerts. Not only handling the flaw is required, but also post-mortem investigation is a must in order to maintain a learning process and retain knowledge-base. Remember, every incident is an opportunity to improve.
To handle alerts effectively, there should be a procedure or a guide that describes adequately what's the nature of the alert and how to mitigate or rectify it. To tackle alerts effectively, the system should include incidents response plan for critical alerts. Not only handling the flaw is required, but also post-mortem investigation is a must in order to maintain a learning process and retain knowledge-base. Remember, every incident is an opportunity to improve.
The Human Factor and the Cultural Aspect (The Human Factor and the Cultural Aspect)
Finally, besides the technical platform to host and maintain the microservices solution, we must address the human factor too. Melvin Conway’s words summarise this concept:
Finally, besides the technical platform to host and maintain the microservices solution, we must address the human factor too. Melvin Conway's words summarise this concept:
“Any organization that designs a system, defined more broadly here than just information systems, will inevitably produce a design whose structure is a copy of the organization’s communication structure.”
“Any organization that designs a system, defined more broadly here than just information systems, will inevitably produce a design whose structure is a copy of the organization's communication structure.”
Simply put, the ownership of service is crucial to keep the microservices solution efficient by reducing the communication efforts and the cost of changes.
Simply put, the ownership of service is crucial to keep the microservices solution efficient by reducing the communication efforts and the cost of changes.
This ownership makes sure that a team is fully responsible for all aspects of service throughout the whole SDLC cycle, starting from requirements gathering until releasing and supporting in the production environment.
This ownership makes sure that a team is fully responsible for all aspects of service throughout the whole SDLC cycle, starting from requirements gathering until releasing and supporting in the production environment.
Such autonomy reduces dependencies to other teams, decreases the friction with other parties, and allow the team to work in an isolated environment.
Such autonomy reduces dependencies to other teams, decreases the friction with other parties, and allow the team to work in an isolated environment.

结语 (Wrapping Up)
That was a long ride, thank you for making it to the end!
That was a long ride, thank you for making it to the end!
I tried to be comprehensive and cover the various topics that affect the decisions in implementing a microservice-based solution. There is much to cover out there, you can continue with the references below.
I tried to be comprehensive and cover the various topics that affect the decisions in implementing a microservice-based solution. There is much to cover out there, you can continue with the references below.
The transition to microservices will only increase as systems continue to grow. You can keep in mind or adopt some of these concepts when you plan your new system or next upgrade.
The transition to microservices will only increase as systems continue to grow. You can keep in mind or adopt some of these concepts when you plan your new system or next upgrade.
Keep on building!
Keep on building!
— Lior
— Lior
____________________________________
____________________________________
翻译自: https://medium.com/swlh/the-principles-of-planning-and-implementing-microservices-3cb0eb76c172
微服务框架实施





 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)