
[深度学习-实战篇]情感分析之卷积神经网络-TextCNN,包含代码
使用Tensorflow的Keras搭建卷积神经网络来进行情感分析在自然语言领域,卷积的作用在于利用文字的局部特征。一个词的前后几个词必然和这个词本身相关,这组成该词所代表的词群。词群进而会对段落文字的意思进行影响,决定这个段落到底是正向的还是负向的。对比传统方法,利用词包,和TF-IDF 等,其思想有相通之处。但最大的不同点在于,传统方法是人为构造用于分类的特征,而深度学习中的卷积让神经网络去构
0. 前言
在“卷积神经网络”中我们探究了如何使用二维卷积神经网络来处理二维图像数据。在之前的语言模型和文本分类任务中,我们将文本数据看作是只有一个维度的时间序列,并很自然地使用循环神经网络来表征这样的数据。其实,我们也可以将文本当作一维图像,从而可以用一维卷积神经网络来捕捉临近词之间的关联。
一. 什么是TextCNN
TextCNN 是利用卷积神经网络对文本进行分类的算法,由 Yoon Kim 在 《Convolutional Neural Networks for Sentence Classification》中提出。
TextCNN结构图:

第一层将单词嵌入到低维矢量中。下一层使用多个过滤器大小对嵌入的单词向量执行卷积。例如,一次滑动3,4或5个单词。接下来,将卷积层的结果最大池化为一个长特征向量,添加dropout正则,并使用softmax对结果进行分类。与传统图像的CNN网络相比, textCNN 在网络结构上没有任何变化(甚至更加简单了), 从图中可以看出textCNN 其实只有一层卷积,一层max-pooling, 最后将输出外接softmax 来n分类。

与图像当中CNN的网络相比,textCNN 最大的不同便是在输入数据的不同:
- 图像是二维数据, 图像的卷积核是从左到右, 从上到下进行滑动来进行特征抽取。
- 自然语言是一维数据, 虽然经过word-embedding 生成了二维向量,但是对词向量做从左到右滑动来进行卷积没有意义. 比如
“今天” 对应的向量[0, 0, 0, 0, 1], 按窗口大小为 1* 2 从左到右滑动得到[0,0], [0,0], [0,0],
[0, 1]这四个向量, 对应的都是"今天"这个词汇, 这种滑动没有帮助.
二. TextCNN 的优势
1.Word Embedding 分词构建词向量
如下图所示, textCNN 首先将 “今天天气很好,出来玩” 分词成"今天/天气/很好/,/出来/玩, 通过word2vec或者GLOV 等embedding 方式将每个词成映射成一个5维(维数可以自己指定)词向量, 如 “今天” -> [0,0,0,0,1], “天气” ->[0,0,0,1,0], “很好” ->[0,0,1,0,0]等等。

这样做的好处主要是将自然语言数值化,方便后续的处理。从这里也可以看出不同的映射方式对最后的结果是会产生巨大的影响, nlp 当中目前最火热的研究方向便是如何将自然语言映射成更好的词向量。我们构建完词向量后,将所有的词向量拼接起来构成一个6*5的二维矩阵,作为最初的输入
2. Convolution 卷积

卷积是一种数学算子。我们用一个简单的例子来说明一下
step.1 将 “今天”/“天气”/“很好”/“,” 对应的4*5 矩阵 与卷积核做一个point wise 的乘法然后求和, 便是卷积操作:
feature_map[0] =0*1 + 0*0 + 0*1 + 0*0 + 1*0 + //(第一行)
0*0 + 0*0 + 0*0 + 1*0 + 0*0 + //(第二行)
0*1 + 0*0 + 1*1 + 0*0 + 0*0 + //(第三行)
0*1 + 1*0 + 0*1 + 0*0 + 0*0 //(第四行)
= 1
step.2 将窗口向下滑动一格(滑动的距离可以自己设置),“天气”/“很好”/“,”/“出来” 对应的4*5 矩阵 与卷积核(权值不变) 继续做point wise 乘法后求和
feature_map[1] =0*1 + 0*0 + 0*1 + 1*0 + 0*0 + //(第一行)
0*0 + 0*0 + 1*0 + 0*0 + 0*0 + //(第二行)
0*1 + 1*0 + 0*1 + 0*0 + 0*0 + //(第三行)
1*1 + 0*0 + 0*1 + 0*0 + 0*0 //(第四行)
= 1
step.3 将窗口向下滑动一格(滑动的距离可以自己设置) “很好”/“,”/“出来”/“玩” 对应的4*5 矩阵 与卷积核(权值不变) 继续做point wise 乘法后求和
feature_map[2] = 0*1 + 0*0 + 1*1 + 1*0 + 0*0 + //(第一行)
0*0 + 1*0 + 0*0 + 0*0 + 0*0 + //(第二行)
1*1 + 0*0 + 0*1 + 0*0 + 0*0 + //(第三行)
0*1 + 0*0 + 0*1 + 1*0 + 1*0 //(第四行)
= 2
feature_map 便是卷积之后的输出, 通过卷积操作 将输入的65 矩阵映射成一个 31 的矩阵,这个映射过程和特征抽取的结果很像,于是便将最后的输出称作feature map。一般来说在卷积之后会跟一个激活函数,在这里为了简化说明需要,我们将激活函数设置为f(x) = x
3. 关于channel 的说明

在CNN 中常常会提到一个词channel, 图三 中 深红矩阵与 浅红矩阵 便构成了两个channel 统称一个卷积核, 从这个图中也可以看出每个channel 不必严格一样, 每个4*5 矩阵与输入矩阵做一次卷积操作得到一个feature map. 在计算机视觉中,由于彩色图像存在 R, G, B 三种颜色, 每个颜色便代表一种channel。
根据原论文作者的描述, 一开始引入channel 是希望防止过拟合(通过保证学习到的vectors 不要偏离输入太多)来在小数据集合获得比单channel更好的表现,后来发现其实直接使用正则化效果更好。
不过使用多channel 相比与单channel, 每个channel 可以使用不同的word embedding, 比如可以在no-static(梯度可以反向传播) 的channel 来fine tune 词向量,让词向量更加适用于当前的训练。
对于channel在textCNN 是否有用, 从论文的实验结果来看多channels并没有明显提升模型的分类能力, 七个数据集上的五个数据集 单channel 的textCNN 表现都要优于 多channels的textCNN。

我们在这里也介绍一下论文中四个model 的不同
- CNN-rand (单channel), 设计好 embedding_size 这个 Hyperparameter 后, 对不同单词的向量作随机初始化, 后续BP的时候作调整.
- CNN-static(单channel), 拿 pre-trained vectors from word2vec, FastText or GloVe 直接用, 训练过程中不再调整词向量.
- CNN-non-static(单channel), pre-trained vectors + fine tuning , 即拿word2vec训练好的词向量初始化, 训练过程中再对它们微调.
- CNN-multiple channel(多channels), 类比于图像中的RGB通道, 这里也可以用 static 与 non-static 搭两个通道来做.
4.max-pooling

得到feamap = [1,1,2] 后, 从中选取一个最大值[2] 作为输出, 便是max-pooling。max-pooling 在保持主要特征的情况下, 大大降低了参数的数目, 从图五中可以看出 feature map 从三维变成了一维, 好处有如下两点:
- 降低了过拟合的风险, feature map = [1, 1, 2] 或者[1, 0, 2] 最后的输出都是[2], 表明开始的输入即使有轻微变形, 也不影响最后的识别。
- 参数减少, 进一步加速计算。
pooling 本身无法带来平移不变性(图片有个字母A, 这个字母A 无论出现在图片的哪个位置, 在CNN的网络中都可以识别出来),卷积核的权值共享才能.
max-pooling的原理主要是从多个值中取一个最大值,做不到这一点。cnn 能够做到平移不变性,是因为在滑动卷积核的时候,使用的卷积核权值是保持固定的(权值共享), 假设这个卷积核被训练的就能识别字母A, 当这个卷积核在整张图片上滑动的时候,当然可以把整张图片的A都识别出来。
5.使用softmax k分类

如上图所示, 我们将 max-pooling的结果拼接起来, 送入到softmax当中, 得到各个类别比如 label 为1 的概率以及label 为-1的概率。如果是预测的话,到这里整个textCNN的流程遍结束了。
如果是训练的话,此时便会根据预测label以及实际label来计算损失函数, 计算出softmax 函数,max-pooling 函数, 激活函数以及卷积核函数 四个函数当中参数需要更新的梯度, 来依次更新这四个函数中的参数,完成一轮训练 。
三.textCNN的总结
本次我们介绍的textCNN是一个应用了CNN网络的文本分类模型。
- textCNN的流程:先将文本分词做embeeding得到词向量, 将词向量经过一层卷积,一层max-pooling,
最后将输出外接softmax 来做n分类。 - textCNN 的优势:模型简单, 训练速度快,效果不错。
- textCNN的缺点:模型可解释型不强,在调优模型的时候,很难根据训练的结果去针对性的调整具体的特征,因为在textCNN中没有类似gbdt模型中特征重要度(feature importance)的概念, 所以很难去评估每个特征的重要度。
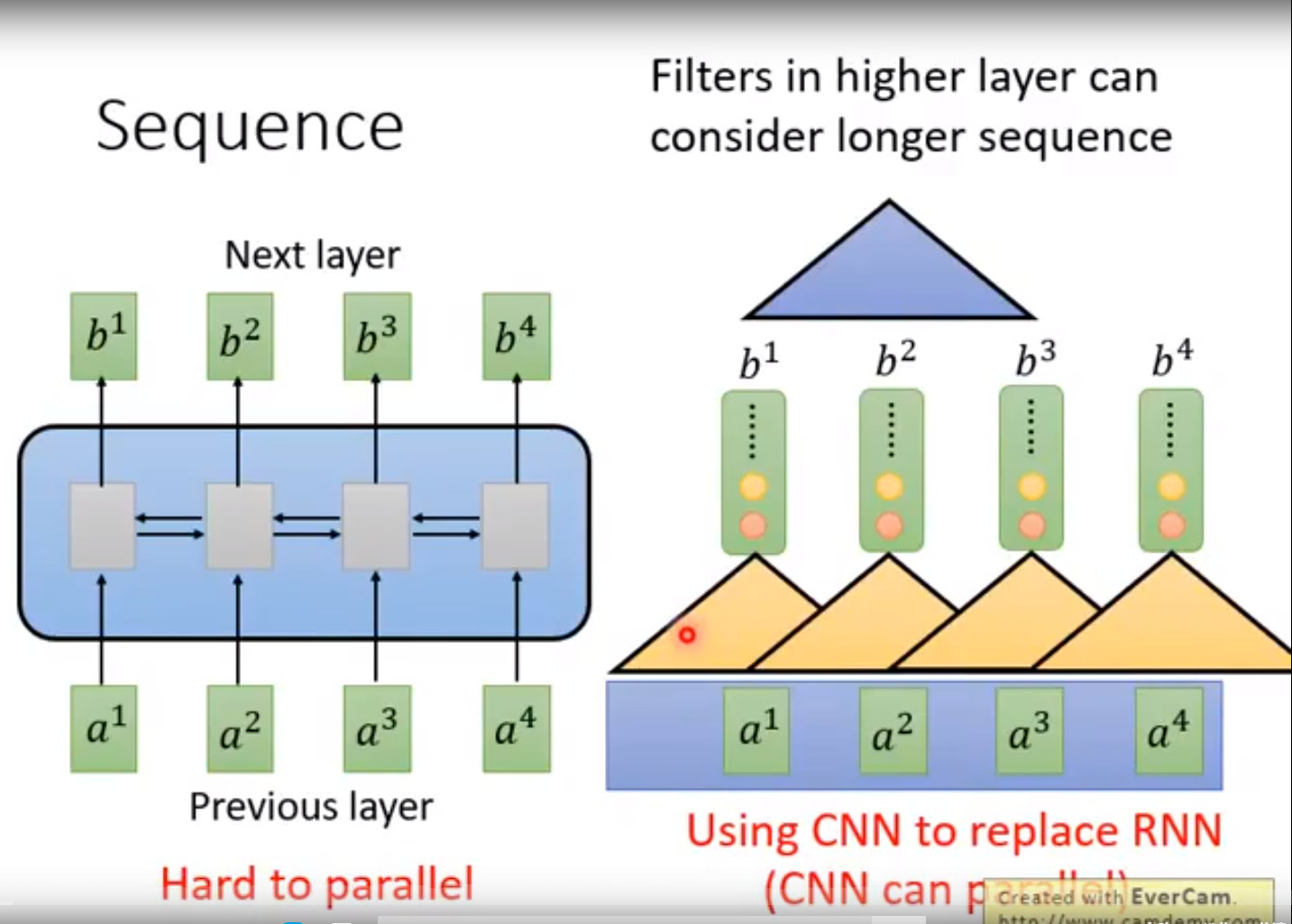
RNN与CNN比较-Seq2Seq的模型
CNN可以并行化,也就是可以并行训练和执行. 但RNN不行。
CNN可以经过多层的叠加实现和RNN一样的长序列依赖
四. 代码实践
运行环境
python : 3.6.13
pip install tensorflow==2.4.1
使用Tensorflow的Keras搭建卷积神经网络来进行情感分析

实验代码一
用tensorflow keras提供的IMDB数据集训练我们的模型。这个数据集是被keras事先被预处理过的。模型是用Conv2D来搭建的。
import keras as keras
import keras.layers as layers
from keras.datasets import imdb
import tensorflow as tf
import os
import numpy as np
from keras.utils import pad_sequences
from keras.callbacks import EarlyStopping, ModelCheckpoint
max_word = 400
def get_dataset():
(x_train, y_train), (x_test, y_test) = imdb.load_data()
print(len(x_train[0]))
print(x_train[0])
print(x_train.shape, ' ', y_train.shape)
print(x_test.shape, ' ', y_test.shape)
X_train = pad_sequences(x_train, maxlen=max_word, padding='post')
X_test = pad_sequences(x_test, maxlen=max_word, padding='post')
print(X_train[0])
print(np.max(X_train[0]))
print(X_train.shape, ' ', y_train.shape)
print(X_test.shape, ' ', y_test.shape)
return X_train, y_train, X_test, y_test
def my_model(X_train):
vocab_size = np.max([np.max(X_train[i]) for i in range(X_train.shape[0])]) + 1 # 这里1 代表空格,其索引被认为是0。
print(vocab_size)
inputs = keras.Input(shape=(400), name='img')
x = keras.layers.Embedding(input_dim=vocab_size, output_dim=64, input_length=max_word)(inputs)
x = keras.layers.Reshape((400, 64, 1), input_shape=(400, 64))(x)
x1 = keras.layers.Conv2D(filters=32, kernel_size=(5, 64), padding='valid', activation='relu')(x)
x1 = layers.BatchNormalization()(x1)
x1 = keras.layers.GlobalMaxPool2D()(x1)
x2 = keras.layers.Conv2D(filters=32, kernel_size=(4, 64), padding='valid', activation='relu')(x)
x2 = layers.BatchNormalization()(x2)
x2 = keras.layers.GlobalMaxPool2D()(x2)
x3 = keras.layers.Conv2D(filters=32, kernel_size=(3, 64), padding='valid', activation='relu')(x)
x3 = layers.BatchNormalization()(x3)
x3 = keras.layers.GlobalMaxPool2D()(x3)
x = layers.Concatenate(axis=1)([x1, x2, x3])
outputs = layers.Dense(2, activation='softmax')(x)
model = keras.Model(inputs, outputs, name='txt_cnn')
model.compile(optimizer=keras.optimizers.Adam(),
loss=keras.losses.SparseCategoricalCrossentropy(),
# metrics=['accuracy'])
metrics=[keras.metrics.SparseCategoricalAccuracy()])
# model.compile(loss='binary_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
print(model.summary())
return model
def train_my_model(model, X_train, y_train):
# 定义保存模型的路径和文件名
model_path = './model.h5'
# 定义早停回调函数
early_stop = EarlyStopping(monitor='val_sparse_categorical_accuracy', patience=3, mode='max', verbose=1)
# 定义ModelCheckpoint回调函数
checkpoint = ModelCheckpoint(model_path, monitor='val_sparse_categorical_accuracy', save_best_only=True, mode='max', verbose=1)
callbacks = [
early_stop,
checkpoint,
tf.keras.callbacks.TensorBoard(log_dir='logs_cnn2')
]
history = model.fit(X_train, y_train, batch_size=100, epochs=20, validation_split=0.1, callbacks=callbacks)
import matplotlib.pyplot as plt
plt.plot(history.history['sparse_categorical_accuracy'])
plt.plot(history.history['val_sparse_categorical_accuracy'])
plt.legend(['training', 'validation'], loc='upper left')
plt.show()
def test_my_module( X_test, y_test):
model = keras.models.load_model('./model.h5')
scores = model.evaluate(X_test, y_test)
print(scores)
def predict():
model = keras.models.load_model('./model.h5')
max_word = 200 # 每个评论最多保留200个单词
# 假设待分类的文本保存在变量text中
# text = "这是一个很好的电影。"
# text = "这是一个很不好的电影。"
text = "this is bad movie"
# text = "I do not like it"
# text = "this is bad movie "
# text = "This is good movie"
# text = "This isn‘t good movie"
# text = "This is not good movie"
# text = "i think this is bad movie"
# 使用与训练数据相同的预处理步骤对文本进行处理
word_index = imdb.get_word_index()
words = text.lower().split()
encoded = [word_index[word] if word in word_index else 0 for word in words]
print(encoded)
input_data = pad_sequences([encoded], maxlen=max_len, padding='post')
print(input_data)
# 对文本进行情感分类预测
prediction = model.predict(input_data)
# 获取预测结果(0代表负面情感,1代表正面情感)
sentiment = "Positive" if prediction > 0.5 else "Negative"
print("Predicted sentiment:", sentiment)
if __name__ == '__main__':
X_train, y_train, x_test, y_test = get_dataset()
model = my_model(X_train)
train_my_model(model, X_train, y_train)
# print(x_test.shape)
# print(y_test.shape)
test_my_module(x_test, y_test)
predict()
训练集准确率100%, 验证集上准确率90.12%
Epoch 8: val_sparse_categorical_accuracy did not improve from 0.90200
225/225 [==============================] - 29s 131ms/step - loss: 4.3386e-04 - sparse_categorical_accuracy: 1.0000 - val_loss: 0.3308 - val_sparse_categorical_accuracy: 0.9012
Epoch 9/20
225/225 [==============================] - ETA: 0s - loss: 3.2644e-04 - sparse_categorical_accuracy: 1.0000
Epoch 9: val_sparse_categorical_accuracy did not improve from 0.90200
225/225 [==============================] - 29s 130ms/step - loss: 3.2644e-04 - sparse_categorical_accuracy: 1.0000 - val_loss: 0.3380 - val_sparse_categorical_accuracy: 0.9012
Epoch 10/20
225/225 [==============================] - ETA: 0s - loss: 2.5350e-04 - sparse_categorical_accuracy: 1.0000
Epoch 10: val_sparse_categorical_accuracy did not improve from 0.90200
225/225 [==============================] - 29s 131ms/step - loss: 2.5350e-04 - sparse_categorical_accuracy: 1.0000 - val_loss: 0.3447 - val_sparse_categorical_accuracy: 0.9012
用下面命令查看训练的整个过程。
tensorboard --logdir=logs_cnns

测试集上准确率是89%
782/782 [==============================] - 5s 6ms/step - loss: 0.3307 - sparse_categorical_accuracy: 0.8943
[0.3306916058063507, 0.894320011138916]
实验代码二(用自己的数据集)
关于生成训练的数据集。我之前的博客有写,请看下面这一篇我的博客。
[深度学习TF2][RNN-LSTM]文本情感分析包含(数据预处理-训练-预测)
IMDB数据集是从官网下载的,然后经过自己的预处理-训练-测试,最后可以做预测。
模型是用Conv2D来搭建的。
import tensorflow.keras as keras
import tensorflow.keras.layers as layers
import tensorflow as tf
import os
import numpy as np
root_folder = '.\cnn3'
def get_dataset():
train_set = np.load('./train_data_new1/train.npz')
X_train = train_set['x']
y_train = train_set['y']
test_set = np.load('./train_data_new1/test.npz')
X_test = test_set['x']
y_test = test_set['y']
print("X_train:", X_train.shape)
print("y_train:", y_train.shape)
print("X_test:", X_test.shape)
print("y_test:", y_test.shape)
return X_train, y_train, X_test, y_test
def my_model():
embedding_matrix = np.load('./train_data_new1/embedding_matrix.npy')
inputs = keras.Input(shape=(200))
x = layers.Embedding(input_dim=30001, output_dim=50, input_length=200, weights=[embedding_matrix])(inputs)
x = keras.layers.Reshape((200, 50,1), input_shape=(200,50))(x)
x1 = keras.layers.Conv2D(filters=32, kernel_size=(5, 50), padding='valid', activation='relu')(x)
x1 = layers.BatchNormalization()(x1)
x1 = keras.layers.GlobalMaxPool2D()(x1)
x2 = keras.layers.Conv2D(filters=32, kernel_size=(4, 50), padding='valid', activation='relu')(x)
x2 = layers.BatchNormalization()(x2)
x2 = keras.layers.GlobalMaxPool2D()(x2)
x3 = keras.layers.Conv2D(filters=32, kernel_size=(3, 50), padding='valid', activation='relu')(x)
x3 = layers.BatchNormalization()(x3)
x3 = keras.layers.GlobalMaxPool2D()(x3)
x= layers.Concatenate(axis=1)([x1, x2, x3])
outputs = layers.Dense(2, activation='softmax')(x)
model = keras.Model(inputs, outputs, name='txt_cnn')
model.compile(optimizer=keras.optimizers.Adam(),
loss=keras.losses.SparseCategoricalCrossentropy(),
#metrics=['accuracy'])
metrics=[keras.metrics.SparseCategoricalAccuracy()])
#keras.utils.plot_model(model, 'textcnn.png', show_shapes=True)
#model.compile(loss='binary_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
print(model.summary())
return model
def train_my_model(model, X_train, y_train):
if os.path.isfile(root_folder+'\model.h5'):
print('load weight')
model.load_weights(root_folder+'\model.h5')
def save_weight(epoch, logs):
print('save_weight', epoch, logs)
model.save_weights(root_folder+'\model.h5')
batch_print_callback = keras.callbacks.LambdaCallback(
on_epoch_end=save_weight
)
callbacks = [
tf.keras.callbacks.EarlyStopping(patience=4, monitor='loss'),
batch_print_callback,
# keras.callbacks.ModelCheckpoint('./weights/model.h5', save_best_only=True),
tf.keras.callbacks.TensorBoard(log_dir=root_folder+'\logs')
]
history = model.fit(X_train, y_train, batch_size=100, epochs=20, validation_split=0.1, callbacks=callbacks)
import matplotlib.pyplot as plt
plt.plot(history.history['sparse_categorical_accuracy'])
plt.plot(history.history['val_sparse_categorical_accuracy'])
plt.legend(['training_accuracy', 'valivation_accuracy'], loc='upper left')
plt.show()
def test_my_module(model, X_test, y_test):
if os.path.isfile(root_folder+'\model.h5'):
print('load weight')
model.load_weights(root_folder+'\model.h5')
scores = model.evaluate(X_test, y_test)
print(scores)
def load_my_model(model):
if os.path.isfile(root_folder+'\model.h5'):
print('load weight')
model.load_weights(root_folder+'\model.h5')
return model
def predict_my_module(model):
small_word_index = np.load('./train_data_new1/small_word_index.npy', allow_pickle=True)
review_index = np.zeros((1, 200), dtype=int)
review = "I do not like it"
# review = "this is bad movie "
# review = "This is good movie"
# review = "This isn‘t good movie"
# review = "This is not good movie"
# review = "i think this is bad movie"
counter = 0
for word in review.split():
try:
print(word, small_word_index.item()[word])
review_index[0][counter] = small_word_index.item()[word]
counter = counter + 1
except Exception:
print('Word error', word)
print(review_index.shape)
s = model.predict(x=review_index)
print(s)
if __name__ == '__main__':
X_train, y_train, x_test, y_test = get_dataset()
model = my_model()
train_my_model(model, X_train, y_train)
#print(x_test.shape)
#print(y_test.shape)
test_my_module(model,x_test, y_test)
#load_my_model(model)
#predict_my_module(model)
训练集上结果

测试集结果是86.7%
14112/15000 [===========================>..] - ETA: 0s - loss: 0.7871 - sparse_categorical_accuracy: 0.8673
15000/15000 [==============================] - 1s 76us/sample - loss: 0.7860 - sparse_categorical_accuracy: 0.8675
[0.7860029630283515, 0.8675333]
预测模型代码,注释掉加载数据集,训练模型和测试模型。代码修改如下:
if __name__ == '__main__':
# X_train, y_train, x_test, y_test = get_dataset()
model = my_model()
# train_my_model(model, X_train, y_train)
#print(x_test.shape)
#print(y_test.shape)
# test_my_module(model,x_test, y_test)
load_my_model(model)
predict_my_module(model)
运行结果如下:
[[0.8423267 0.15767324]]
0:negative , 1: postive ,第一个代表negative的概率是0.8423267,第二个代表postive的概率是 0.15767324
实验代码三
用tensorflow keras提供的IMDB数据集训练我们的模型。这个数据集事先被预处理过的。但是我们不知道它是怎么处理的,所以无法预测(也就是无法把预测的句子中的单词转化为词向量)。只能验证你的模型搭建的效果怎么样(训练-测试)。
模型是用Conv1D搭建的。
import tensorflow.keras as keras
import tensorflow.keras.layers as layers
import tensorflow as tf
import os
import numpy as np
max_word = 400
def get_dataset():
(x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data()
print(len(x_train[0]))
print(x_train[0])
print(x_train.shape, ' ', y_train.shape)
print(x_test.shape, ' ', y_test.shape)
X_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen=max_word, padding='post')
X_test = keras.preprocessing.sequence.pad_sequences(x_test, maxlen=max_word, padding='post')
print(X_train[0])
print(np.max(X_train[0]))
print(X_train.shape, ' ', y_train.shape)
print(X_test.shape, ' ', y_test.shape)
return X_train, y_train, X_test, y_test
def my_model(X_train):
vocab_size = np.max([np.max(X_train[i]) for i in range(X_train.shape[0])]) + 1 # 这里1 代表空格,其索引被认为是0。
print(vocab_size)
model = keras.Sequential([
layers.Embedding(input_dim=vocab_size, output_dim=64, input_length=max_word),
keras.layers.Conv1D(filters=64, kernel_size=3, padding='same', activation='relu'),
keras.layers.MaxPooling1D(pool_size=2),
keras.layers.Dropout(0.25),
keras.layers.Conv1D(filters=128, kernel_size=3, padding='same', activation='relu'),
keras.layers.MaxPooling1D(pool_size=2),
keras.layers.Dropout(0.25),
keras.layers.Flatten(),
keras.layers.Dense(64, activation='relu'),
keras.layers. Dense(32, activation='relu'),
keras.layers.Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
#print(model.summary())
return model
def train_my_model(model, X_train, y_train):
if os.path.isfile('./weights_cnn/model.h5'):
print('load weight')
model.load_weights('./weights_cnn/model.h5')
def save_weight(epoch, logs):
print('save_weight', epoch, logs)
model.save_weights('./weights_cnn/model.h5')
batch_print_callback = keras.callbacks.LambdaCallback(
on_epoch_end=save_weight
)
callbacks = [
tf.keras.callbacks.EarlyStopping(patience=4, monitor='loss'),
batch_print_callback,
# keras.callbacks.ModelCheckpoint('./weights/model.h5', save_best_only=True),
tf.keras.callbacks.TensorBoard(log_dir='logs_cnn')
]
history = model.fit(X_train, y_train, batch_size=100, epochs=20, validation_split=0.1, callbacks=callbacks)
import matplotlib.pyplot as plt
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.legend(['training', 'valivation'], loc='upper left')
plt.show()
def test_my_module(model, X_test, y_test):
if os.path.isfile('./weights_cnn/model.h5'):
print('load weight')
model.load_weights('./weights_cnn/model.h5')
scores = model.evaluate(X_test, y_test)
print(scores)
if __name__ == '__main__':
X_train, y_train, x_test, y_test = get_dataset()
model = my_model(X_train)
#train_my_model(model, X_train, y_train)
print(x_test.shape)
print(y_test.shape)
test_my_module(model,x_test, y_test)
Angular写的UI展示

参考资料
https://www.biaodianfu.com/textcnn.html
https://zh.gluon.ai/chapter_natural-language-processing/sentiment-analysis-cnn.html
https://www.cnblogs.com/ModifyRong/p/11319301.html

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐
 30
30 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容







所有评论(0)