
黄金时代 —— 深度学习 (目标检测)
IoU
文章目录
- `0 指标 & 技巧`
- IoU
- mAP / mmAP
- NMS及其变种
- `1 深度网络发展历程`
- `2 Two-Stage Network`
- R-CNN 2014
- Fast R-CNN 2015
- Faster R-CNN 2016
- Mask R-CNN 2017
- FCN 2014
- R-FCN 2016
- CoupleNet 2017
- Cascade R-CNN 2017
- `3 One-Stage Network`
- YOLOv1 2015
- YOLOv2 & YOLO9000 2016
- SSD 2016
- DSSD 2017
- YOLOv3 2018
- RefineDet 2018
- YOLOv4 2020
- `4 Scale Problem`
- OverFeat 2014
- SPPNet 2015
- FPN 2017
- PANet 2018
- M2Det 2018
- RFBNet 2018
- TridentNet 2019
- `5 形变卷积`
- Deformable ConvNets V1 2017
- Deformable ConvNets V2 2018
- `6 样本困难和不平衡`
- OHEM 2016
- RetinaNet 2017
- GHM 2019
- Generalized Focal Loss 2020
- `7 Anchor-free Network`
- DenseBox 2015
- CornerNet 2018
- CornerNet-Lite 2019
- FSAF 2019
- FoveaBox 2019
- FCOS 2019
- ExtremeNet 2019
- CenterNet(Triplets) 2019
- CenterNet(Objects as Points) 2019
- ATSS 2019
- `8 NAS 网络结构搜索优化`
- NASNet 2016
- EfficientNet 2019
- NAS-FPN 2019
- Detnas 2019
- `Mess`
- DetNet 2018
- STDNet 2018
- RFBNet 2018
- Relation-Network 2018
- PFPNet 2018
- MetaAnchor 2018
- Pelee 2018
- SNIPER 2018
- Non-local Neural Networks 2018
- Bag of Freebies 2019
0 指标 & 技巧
IoU
交并比
x 1 = max ( b o x 1 x 1 , b o x 2 x 1 ) , y 1 = max ( b o x 1 y 1 , b o x 2 y 1 ) x 2 = min ( b o x 1 x 2 , b o x 2 x 2 ) , y 2 = min ( b o x 1 y 2 , b o x 2 y 2 ) i n t e r s e c t i o n = ( x 2 − x 1 + 1 ) × ( y 2 − y 1 + 1 ) I o U = i n t e r s e c t i o n a r e a 1 + a r e a 2 − i n t e r s e c t i o n x 1=\max \left(b o x 1_{x 1}, b o x 2_{x 1}\right), y 1=\max \left(b o x 1_{y 1}, b o x 2_{y 1}\right) \\ x 2=\min \left(b o x 1_{x 2}, b o x 2_{x 2}\right), y 2=\min \left(b o x 1_{y 2}, b o x 2_{y 2}\right)\\ intersection=(x 2-x 1+1) \times(y 2-y 1+1)\\ I o U=\frac{intersection}{area_1+area_2-intersection} x1=max(box1x1,box2x1),y1=max(box1y1,box2y1)x2=min(box1x2,box2x2),y2=min(box1y2,box2y2)intersection=(x2−x1+1)×(y2−y1+1)IoU=area1+area2−intersectionintersection
代码
- numpy
import numpy as np
def get_inter_matrix(boxes_pd, boxes_gt):
A = boxes_pd.shape[0]
B = boxes_gt.shape[0]
lt_xy = np.maximum( # left top
np.repeat(np.expand_dims(boxes_pd[:, :2], axis=1), B, axis=1),
np.repeat(np.expand_dims(boxes_gt[:, :2], axis=0), A, axis=0)
)
rb_xy = np.minimum( # right bottom
np.repeat(np.expand_dims(boxes_pd[:, 2:], axis=1), B, axis=1),
np.repeat(np.expand_dims(boxes_gt[:, 2:], axis=0), A, axis=0)
)
inter = np.clip(rb_xy - lt_xy, a_min=0, a_max=None) # (A, B, 2): (h, w)
return inter[:, :, 0] * inter[:, :, 1] # return (A, B), inter_matrix
def get_iou_matrix(boxes_pd, boxes_gt):
"""
Args:
box_pd: (tensor) Prior boxes from priorbox layers, Shape: [num_priors,4]
box_gt: (tensor) Ground truth bounding boxes, Shape: [num_objects,4]
Return:
jaccard overlap: (tensor) Shape: [box_a.size(0), box_b.size(0)]
"""
A = boxes_pd.shape[0]
B = boxes_gt.shape[0]
area_pd = (boxes_pd[:, 3]-boxes_pd[:, 1]) * (boxes_pd[:, 2]-boxes_pd[:, 0]) # h * w
area_gt = (boxes_gt[:, 3]-boxes_gt[:, 1]) * (boxes_gt[:, 2]-boxes_gt[:, 0]) # h * w
inter_matrix = get_inter_matrix(boxes_pd, boxes_gt)
return inter_matrix / (area_gt + area_pd - inter_matrix) # (A, B), iou_matrix
- Pytorch
import torch
def intersect(box_a, box_b):
""" We resize both tensors to [A,B,2] without new malloc:
[A,2] -> [A,1,2] -> [A,B,2]
[B,2] -> [1,B,2] -> [A,B,2]
Then we compute the area of intersect between box_a and box_b.
Args:
box_a: (tensor) bounding boxes, Shape: [A,4].
box_b: (tensor) bounding boxes, Shape: [B,4].
Return:
(tensor) intersection area, Shape: [A,B].
"""
A = box_a.size(0)
B = box_b.size(0)
max_xy = torch.min(box_a[:, 2:].unsqueeze(1).expand(A, B, 2),
box_b[:, 2:].unsqueeze(0).expand(A, B, 2))
# print(box_a[:, :2])
# print(box_a[:, :2].unsqueeze(1))
# print(box_a[:, :2].unsqueeze(1).expand(A, B, 2))
min_xy = torch.max(box_a[:, :2].unsqueeze(1).expand(A, B, 2),
box_b[:, :2].unsqueeze(0).expand(A, B, 2))
inter = torch.clamp((max_xy - min_xy), min=0)
return inter[:, :, 0] * inter[:, :, 1]
def jaccard(box_a, box_b):
"""Compute the jaccard overlap of two sets of boxes. The jaccard overlap
is simply the intersection over union of two boxes. Here we operate on
ground truth boxes and default boxes.
E.g.:
A ∩ B / A ∪ B = A ∩ B / (area(A) + area(B) - A ∩ B)
Args:
box_a: (tensor) Ground truth bounding boxes, Shape: [num_objects,4]
box_b: (tensor) Prior boxes from priorbox layers, Shape: [num_priors,4]
Return:
jaccard overlap: (tensor) Shape: [box_a.size(0), box_b.size(0)]
"""
inter = intersect(box_a, box_b)
area_a = ((box_a[:, 2]-box_a[:, 0]) *
(box_a[:, 3]-box_a[:, 1])).unsqueeze(1).expand_as(inter) # [A,B]
area_b = ((box_b[:, 2]-box_b[:, 0]) *
(box_b[:, 3]-box_b[:, 1])).unsqueeze(0).expand_as(inter) # [A,B]
union = area_a + area_b - inter
return inter / union # [A,B]
box_a = torch.Tensor([[1,2,3,4],[2,3,4,5]])
box_b = torch.Tensor([[1,2,3,4],[2,3,4,5],[4,5,6,7]])
iou = jaccard(box_a, box_b)
print(iou)
mAP / mmAP
- 准确率 Acc
A c c = T P + T N F P + F N + T P + T N A c c=\frac{T P+T N}{F P+F N+T P+T N} Acc=FP+FN+TP+TNTP+TN - 精确度 Pre
P r e = T P F P + T P P r e=\frac{T P}{F P+T P} Pre=FP+TPTP - 召回率 Recall
R e c a l l = T P T P + F N Recall=\frac{T P}{T P+F N} Recall=TP+FNTP - 目标检测中没有正确的负样本这一说,所以一般 A c c = P r e Acc = Pre Acc=Pre
- PR曲线的AUC指标 ∑ k = 1 N max k ′ ≥ k P ( k ′ ) Δ r ( k ) \sum_{k=1}^{N} \max _{k^{\prime} \geq k} P\left(k^{\prime}\right) \Delta r(k) ∑k=1Nmaxk′≥kP(k′)Δr(k)计算复杂,所以使用AP(Average Precision)近似
AP计算
- 注意,AP是一个和IoU阈值和类别相关函数。设IoU阈值为0.5,表示可以选择所有和A类物体的GT-BBox的IoU大于0.5的候选框BBox用于计算该A类物体的PR曲线!
- 例子,设定IoU为0.5。对于某一类物体的检测,网络给了10个候选框,按照每个框的置信度从高到低排序:

P = # T r u e s − u p p e r − t h r e s # A l l − u p p e r − t h r e s R = # T r u e s − u p p e r − t h r e s # A l l − T r u e s \begin{aligned} P &=\frac{\#Trues-upper-thres}{\#All-upper-thres} \\ R &=\frac{\#Trues-upper-thres}{\# All-Trues} \end{aligned} PR=#All−upper−thres#Trues−upper−thres=#All−Trues#Trues−upper−thres - PR曲线

- 计算方法:
- ① voc2010之前,选取 Recall >= 0, 0.1, …, 1 的11处Percision最值的均值

- 2010之后,绘制出平滑后的PR曲线后,用积分的方式计算平滑曲线下方的面积作为最终的AP值。

mAP / mmAP
- mAP:mean Average Precision 指的是分别求每个类别的 AP, 然后取其平均值.
AP对于类别的均值,是IoU阈值的函数 - mmAP:给定一组IOU阈值,在每个IOU阈值下面,求所有类别的AP,并将其平均起来,作为这个IOU阈值下的检测性能,称为mAP(比如mAP@0.5就表示IOU阈值为0.5时的mAP);最后,将所有IOU阈值下的mAP进行平均,就得到了最终的性能评价指标。
AP对于类别和IoU阈值的均值
AP计算代码
- 1 计算Precisions和Recalls
# input:
# - score: 样本为正样本的概率
# - label: 样本的真实标签
import numpy as np
def get_pre_rec(scores, labels):
sort_index = np.argsort(scores)[::-1]
scores = scores[sort_index]
labels = labels[sort_index]
y_preds = scores >= 0.5
tps = np.cumsum((y_preds == True) & (labels == True))
fps = np.cumsum((y_preds == True) & (labels == False))
tns = np.cumsum((y_preds == False) & (labels == False))
fns = np.cumsum((y_preds == False) & (labels == True))
print("tps:", tps)
print("fps:", fps)
print("tns:", tns)
print("fns:", fns)
pres = tps / (tps + fps)
recs = tps / (tps[-1]+fns[-1])
return pres, recs
scores = np.array([0.9, 0.89, 0.8, 0.78, 0.7, 0.7, 0.7, 0.67, 0.62, 0.58, 0.4, 0.3])
labels = np.array([1, 1, 0, 0, 0, 1, 0, 0, 1, 1, 1, 1])
pres, recs = get_pre_rec(scores, labels)
print("pres:", pres)
print("recs:", recs)
- 计算方法1 - 11个点
import numpy as np
def average_precision(precision, recall):
if pre is None or rec is None:
return np.nan
psum = 0
for t in np.arange(0., 1.1, 0.1):
if np.sum(recall >= t) == 0:
break # 如果后面已经不存在大于阈值的 recall 了, 则可跳出
else: # 找到大于阈值的所有对应精度中, 最大的那个
psum += np.max(np.nan_to_num(precision)[recall >= t])
return psum / 11.0 # 除以采样点个数(11个)
- 计算方法2 - 平滑计算
import numpy as np
def average_precision_rec(pre, rec):
pre = np.nan_to_num(pre)
# pre = np.concatenate([[0], pre, [0]]) # 添加哨兵元素
pre = np.concatenate([[1], pre, [0]]) # 添加哨兵元素
rec = np.concatenate([[0], rec, [1]]) # 添加哨兵元素
n = len(pre)
for i in range(n-1, 0, -1): # 将pre置为后面最大的
pre[i-1] = max(pre[i-1], pre[i]) # 对于每一个阈值, 我们选取大于该 recal 阈值的最大精度作为积分精度
i = np.where(rec[1:] != rec[:-1])[0] # i = 0 ~ n-2, 找到 rec 变化的点
print((rec[i+1] - rec[i]), pre[i+1]) # 输出相乘元素, 方便检查
return np.sum((rec[i+1] - rec[i]) * pre[i+1])
COCO上的12个度量指标
- AR是对每张图片在给定一定数量的检测个数下最大的召回率,取所有类别和IoU下的均值。

- COCO 介绍
NMS及其变种
NMS(贪心算法)
- 1 将所有框的得分排序,选中最高分及其对应的框;
- 2 遍历其余的框,如果和当前最高分框的重叠面积 (IOU) 大于一定阈值,我们就将框删除;
- 3 从未处理的框中继续选一个得分最高的,重复上述过程。
- 问题:如果两个物体重叠较大,就会漏检一个
代码
import cv2
import numpy as np
def nms(bounding_boxes, confidence_score, threshold):
if len(bounding_boxes) == 0:
return [], []
bboxes = np.array(bounding_boxes)
score = np.array(confidence_score)
# 计算 n 个候选框的面积大小
x1 = bboxes[:, 0]
y1 = bboxes[:, 1]
x2 = bboxes[:, 2]
y2 = bboxes[:, 3]
areas =(x2 - x1 + 1) * (y2 - y1 + 1)
# 对置信度进行排序, 获取排序后的下标序号, argsort 默认从小到大排序
order = np.argsort(score)
picked_boxes = [] # 返回值
picked_score = [] # 返回值
while order.size > 0:
# 将当前置信度最大的框加入返回值列表中
index = order[-1]
picked_boxes.append(bounding_boxes[index])
picked_score.append(confidence_score[index])
# 获取当前置信度最大的候选框与其他任意候选框的相交面积
x11 = np.maximum(x1[index], x1[order[:-1]])
y11 = np.maximum(y1[index], y1[order[:-1]])
x22 = np.minimum(x2[index], x2[order[:-1]])
y22 = np.minimum(y2[index], y2[order[:-1]])
w = np.maximum(0.0, x22 - x11 + 1) # 这一步千万不要忘了, 因为在求 iou 时, 如果不相交, 则会出现负值
h = np.maximum(0.0, y22 - y11 + 1)
intersection = w * h
# 利用相交的面积和两个框自身的面积计算框的交并比, 将交并比大于阈值的框删除
ratio = intersection / (areas[index] + areas[order[:-1]] - intersection)
left = np.where(ratio < threshold) # 当 left 进行计算时, 如 left+1, 才使用 [0], 详见求 AP 的代码
order = order[left]
return picked_boxes, picked_score
#include <iostream>
#include <vector>
#include <algorithm>
struct Bbox {
int x1;
int y1;
int x2;
int y2;
float score;
Bbox(int x1_, int y1_, int x2_, int y2_, float s):
x1(x1_), y1(y1_), x2(x2_), y2(y2_), score(s) {};
};
float iou(Bbox box1, Bbox box2) {
float area1 = (box1.x2 - box1.x1 + 1) * (box1.y2 - box1.y1 + 1);
float area2 = (box2.x2 - box2.x1 + 1) * (box2.y2 - box2.y1 + 1);
int x11 = std::max(box1.x1, box2.x1);
int y11 = std::max(box1.y1, box2.y1);
int x22 = std::min(box1.x2, box2.x2);
int y22 = std::min(box1.y2, box2.y2);
float intersection = (x22 - x11 + 1) * (y22 - y11 + 1);
return intersection / (area1 + area2 - intersection);
}
std::vector<Bbox> nms(std::vector<Bbox> &vecBbox, float threshold) {
auto cmpScore = [](Bbox box1, Bbox box2) {
return box1.score < box2.score; // 升序排列, 令score最大的box在vector末端
};
std::sort(vecBbox.begin(), vecBbox.end(), cmpScore);
std::vector<Bbox> pickedBbox;
while (vecBbox.size() > 0) {
pickedBbox.emplace_back(vecBbox.back());
vecBbox.pop_back();
for (size_t i = 0; i < vecBbox.size(); i++) {
if (iou(pickedBbox.back(), vecBbox[i]) >= threshold) {
vecBbox.erase(vecBbox.begin() + i);
}
}
}
return pickedBbox;
}
Soft NMS 2017
- 将重合率高的得分减少,而不是直接为0(即删掉)
- 有线性加权和高斯加权
s i = { s i , iou ( M , b i ) < N t s i ( 1 − iou ( M , b i ) ) , iou ( M , b i ) s_{i}=\left\{\begin{array}{ll} s_{i}, & \text { iou }\left(\mathcal{M}, b_{i}\right)<N_{t} \\ s_{i}\left(1-\operatorname{iou}\left(\mathcal{M}, b_{i}\right)\right), & \text { iou }\left(\mathcal{M}, b_{i}\right) \end{array}\right. si={si,si(1−iou(M,bi)), iou (M,bi)<Nt iou (M,bi)
s i = s i e − i o u ( M , b i ) 2 σ , ∀ b i ∉ D s_{i}=s_{i} e^{-\frac{i o u\left(\mathcal{M}, b_{i}\right)^{2}}{\sigma}}, \forall b_{i} \notin \mathcal{D} si=sie−σiou(M,bi)2,∀bi∈/D - 流程:

- Soft NMS:将重叠bbox加权抑制,减少得分。但还是会设置一个阈值,当得分小于这个阈值(如0.001)的时候,把这个框删掉。
- 优缺点:
优点:
1、Soft-NMS可以很方便地引入到object detection算法中,不需要重新训练原有的模型、代码容易实现,不增加计算量(计算量相比整个object detection算法可忽略)。并且很容易集成到目前所有使用NMS的目标检测算法。
2、soft-NMS在训练中采用传统的NMS方法,仅在推断代码中实现soft-NMS。作者应该做过对比试验,在训练过程中采用soft-NMS没有显著提高。
3、NMS是Soft-NMS特殊形式,当得分重置函数采用二值化函数时,Soft-NMS和NMS是相同的。soft-NMS算法是一种更加通用的非最大抑制算法。
缺点:
soft-NMS也是一种贪心算法,并不能保证找到全局最优的检测框分数重置。除了以上这两种分数重置函数,我们也可以考虑开发其他包含更多参数的分数重置函数,比如Gompertz函数等。但是它们在完成分数重置的过程中增加了额外的参数。
代码
import numpy as np
def soft_nms(bboxes, scores, iou_thresh=0.3, sigma2=0.5, score_thresh=0.001, method=2):
# 在 bboxes 之后添加对于的下标[0, 1, 2...], 最终 bboxes 的 shape 为 [n, 5], 前四个为坐标, 后一个为下标
N = bboxes.shape[0] # 总的 box 的数量
indexes = np.array([np.arange(N)]) # 下标: 0, 1, 2, ..., n-1
bboxes = np.concatenate((bboxes, indexes.T), axis=1) # concatenate 之后, bboxes 的操作不会对外部变量产生影响
# 计算每个 box 的面积
x1 = bboxes[:, 0]
y1 = bboxes[:, 1]
x2 = bboxes[:, 2]
y2 = bboxes[:, 3]
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
# for i in range(N):
for i in range(N-1): # 实际上, i = N-1 时, 循环内不会发生任何改变, 因此, 可以令 i 最大循环到 N-2
# 找出 i 后面的最大 score 及其下标
pos = i + 1
maxscore = np.max(scores[pos:], axis=0)
maxpos = np.argmax(scores[pos:], axis=0)
# 因为现在 i 为 0 ~ n-2, 因此无序进行下面的判断, 可以直接利用上面的式子代替
"""
if i != N-1:
maxscore = np.max(scores[pos:], axis=0)
maxpos = np.argmax(scores[pos:], axis=0)
else:
maxscore = scores[-1]
maxpos = 0
"""
# 如果当前 i 的得分小于后面的最大 score, 则与之交换, 确保 i 上的 score 最大
if scores[i] < maxscore:
bboxes[[i, maxpos + i + 1]] = bboxes[[maxpos + i + 1, i]]
scores[[i, maxpos + i + 1]] = scores[[maxpos + i + 1, i]]
areas[[i, maxpos + i + 1]] = areas[[maxpos + i + 1, i]]
# IoU calculate, 注意, 这里使用 bboxes 而不使用 x1, y1, ... 的原因是因为上面只交换了 bboxes, 而没有交换 x1, y1, ...
xx1 = np.maximum(bboxes[i, 0], bboxes[pos:, 0])
yy1 = np.maximum(bboxes[i, 1], bboxes[pos:, 1])
xx2 = np.minimum(bboxes[i, 2], bboxes[pos:, 2])
yy2 = np.minimum(bboxes[i, 3], bboxes[pos:, 3])
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
intersection = w * h
iou = intersection / (areas[i] + areas[pos:] - intersection)
# Three methods: 1.linear 2.gaussian 3.original NMS
if method == 1: # linear
weight = np.ones(iou.shape)
weight[iou > iou_thresh] = weight[iou > iou_thresh] - iou[iou > iou_thresh]
elif method == 2: # gaussian
weight = np.exp(-(iou * iou) / sigma2)
else: # original NMS
weight = np.ones(iou.shape)
weight[iou > iou_thresh] = 0
scores[pos:] = weight * scores[pos:]
# select the boxes and keep the corresponding indexes
inds = bboxes[:, 4][scores > score_thresh]
keep = inds.astype(int)
return keep
# boxes and scores
boxes = np.array([[200, 200, 400, 400], [220, 220, 420, 420],
[240, 200, 440, 400], [200, 240, 400, 440],
[1, 1, 2, 2]], dtype=np.float32)
boxscores = np.array([0.9, 0.8, 0.7, 0.6, 0.5], dtype=np.float32)
index = soft_nms(boxes, boxscores, method=2)
print(index) # 按照 scores 的排序指明了对应的 box 的下标
print(boxes[index])
print(boxscores) # 注意, scores 不需要用 index 获取, scores 已经是更新过的排序 scores
ConvNMS 2015
- A Convnet for Non-maximum Suppression
- 其主要考虑IoU阈值设定得高一些,则可能抑制得不够充分,而将IoU阈值设定得低一些,又可能多个ture positive被merge到一起。其设计一个卷积网络组合具有不同overlap阈值的greedyNMS结果,通过学习的方法来获得最佳的输出。
- 介绍
Pure NMS Network 2017
- 和ConvNMS是相同作者
- Learning non-maximum suppression
- 检测器对于每个目标仅产生一个检测结果有两个关键点是必要的,一是一个loss惩罚double detections以告诉检测器我们对于每个目标仅需一个检测结果,二是相邻检测结果的joint processing以使得检测器具有必要的信息来分辨一个目标是否被多次检测。论文提出Gnet,其为第一个“pure”NMS网络。
Softer NMS 2018
- Rethinking Bounding Box Regression for Accurate Object Detection
- 论文的motivation来自于NMS时用到的score仅仅是分类置信度得分,不能反映Bounding box的定位精准度,既分类置信度和定位置信非正相关的。NMS只能解决分类置信度和定位置信度都很高的,但是对其它三种类型:“分类置信度低-定位置信度低”,“分类置信度高-定位置信度低”,“分类置信度低-定位置信度高“都无法解决。
- 首先假设Bounding box的是高斯分布,ground truth bounding box是狄拉克delta分布(即标准方差为0的高斯分布极限)。KL 散度用来衡量两个概率分布的非对称性度量,KL散度越接近0代表两个概率分布越相似。
- 提出的KL loss,即为最小化Bounding box regression loss,既Bounding box的高斯分布和ground truth的狄拉克delta分布的KL散度。直观上解释,KL Loss使得Bounding box预测呈高斯分布,且与ground truth相近。而将包围框预测的标准差看作置信度。

- 提出的Softer-NMS,基于soft-NMS,对预测标注方差范围内的候选框加权平均,使得高定位置信度的bounding box具有较高的分类置信度。
- 流程:

- 预测的四个顶点坐标,分别对IoU>Nt的预测加权平均计算,得到新的4个坐标点,第i个矩形框的x1:
x 1 i : = ∑ j x 1 j / σ x 1 , j 2 ∑ j 1 / σ x 1 , j 2 subject to IoU ( x 1 j , x 2 ) = N t \begin{array}{l} x 1_{i}:=\frac{\sum_{j} x 1_{j} / \sigma_{x 1, j}^{2}}{\sum_{j} 1 / \sigma_{x 1, j}^{2}} \\ \text { subject to } \operatorname{IoU}\left(x_{1 j}, x_{2}\right)=N_{t} \end{array} x1i:=∑j1/σx1,j2∑jx1j/σx1,j2 subject to IoU(x1j,x2)=Nt
代码
import cv2
import numpy as np
def nms(bounding_boxes, confidence_score, threshold):
if len(bounding_boxes) == 0:
return [], []
bboxes = np.array(bounding_boxes)
x1 = bboxes[:, 0]
y1 = bboxes[:, 1]
x2 = bboxes[:, 2]
y2 = bboxes[:, 3]
score = np.array(confidence_score)
picked_boxes = []
picked_score = []
areas =(x2 - x1 + 1) * (y2 - y1 + 1)
order = np.argsort(score)
while order.size > 0:
index = order[-1]
picked_boxes.append(bounding_boxes[index])
picked_score.append(confidence_score[index])
x11 = np.maximum(x1[index], x1[order[:-1]])
y11 = np.maximum(y1[index], y1[order[:-1]])
x22 = np.minimum(x2[index], x2[order[:-1]])
y22 = np.minimum(y2[index], y2[order[:-1]])
w = np.maximum(0.0, x22 - x11 + 1)
h = np.maximum(0.0, y22 - y11 + 1)
intersection = w * h
ratio = intersection / (areas[index] + areas[order[:-1]] - intersection)
left = np.where(ratio < threshold)
order = order[left]
return picked_boxes, picked_score
def main():
img_path = "/home/zerozone/Pictures/testimg/face.jpg"
bounding_boxes = [(187, 82, 337, 317), (150, 67, 305, 282),
(246, 121, 368, 304)]
confidence_score = [0.9, 0.75, 0.8]
image = cv2.imread(img_path)
orig = image.copy()
font = cv2.FONT_HERSHEY_SIMPLEX
font_scale = 0.7
thickness = 2
threshold = 0.5
# Draw bboxes and score
for (x1, y1, x2, y2), confidence in zip(bounding_boxes, confidence_score):
(w, h), baseline = cv2.getTextSize(
str(confidence), font, font_scale, thickness)
cv2.rectangle(orig, (x1, y1 - (2 * baseline + 5)),
(x1 + w, y1), (0, 255, 255), -1)
cv2.rectangle(orig, (x1, y1), (x2, y2), (0, 255, 255), 2)
cv2.putText(orig, str(confidence), (x1, y1),
font, font_scale, (0, 0, 0, thickness))
# Draw bboxes and score after NMS
picked_boxes, picked_score = nms(bounding_boxes, confidence_score, threshold)
for (x1, y1, x2, y2), confidence in zip(picked_boxes, picked_score):
(w, h), baseline = cv2.getTextSize(
str(confidence), font, font_scale, thickness)
cv2.rectangle(image, (x1, y1 - (2 * baseline + 5)),
(x1 + w, y1), (0, 255, 255), -1)
cv2.rectangle(image, (x1, y1), (x2, y2), (0, 255, 255), 2)
cv2.putText(image, str(confidence), (x1, y1),
font, font_scale, (0, 0, 0, thickness))
cv2.imshow("origin", orig)
cv2.imshow("NMS", image)
cv2.waitKey(0)
if __name__ == "__main__":
main()
#include <iostream>
#include <vector>
#include <algorithm>
struct Bbox {
int x1;
int y1;
int x2;
int y2;
float score;
Bbox(int x1_, int y1_, int x2_, int y2_, float s):
x1(x1_), y1(y1_), x2(x2_), y2(y2_), score(s) {};
};
float iou(Bbox box1, Bbox box2) {
float area1 = (box1.x2 - box1.x1 + 1) * (box1.y2 - box1.y1 + 1);
float area2 = (box2.x2 - box2.x1 + 1) * (box2.y2 - box2.y1 + 1);
int x11 = std::max(box1.x1, box2.x1);
int y11 = std::max(box1.y1, box2.y1);
int x22 = std::min(box1.x2, box2.x2);
int y22 = std::min(box1.y2, box2.y2);
float intersection = (x22 - x11 + 1) * (y22 - y11 + 1);
return intersection / (area1 + area2 - intersection);
}
std::vector<Bbox> nms(std::vector<Bbox> &vecBbox, float threshold) {
auto cmpScore = [](Bbox box1, Bbox box2) {
return box1.score < box2.score; // 升序排列, 令score最大的box在vector末端
};
std::sort(vecBbox.begin(), vecBbox.end(), cmpScore);
std::vector<Bbox> pickedBbox;
while (vecBbox.size() > 0) {
pickedBbox.emplace_back(vecBbox.back());
vecBbox.pop_back();
for (size_t i = 0; i < vecBbox.size(); i++) {
if (iou(pickedBbox.back(), vecBbox[i]) >= threshold) {
vecBbox.erase(vecBbox.begin() + i);
}
}
}
return pickedBbox;
}
int main() {
std::vector<Bbox> vecBbox;
vecBbox.emplace_back(Bbox(187, 82, 337, 317, 0.9));
vecBbox.emplace_back(Bbox(150, 67, 305, 282, 0.75));
vecBbox.emplace_back(Bbox(246, 121, 368, 304, 0.8));
auto pickedBbox = nms(vecBbox, 0.5);
for (auto box : pickedBbox) {
std::cout << box.x1 << ", " <<
box.y1 << ", " <<
box.x2 << ", " <<
box.y2 << ", " <<
box.score << std::endl;
}
return 0;
}
Fitness NMS 2017
- Improving Object Localization with Fitness NMS and Bounded IoU Loss
-
- 这种方法考虑了大于估计的重叠的IoU和预测的bounding boxes的分类得分。
1 深度网络发展历程

2 Two-Stage Network
R-CNN 2014
*对深度网络和检测任务的说明
- 纯粹的NN网络适合图像识别或分类
- 目标检测任务可以拆分为:图像分类和定位,后者如何通过深度网络解决呢?
- 定位的解决思路:① 将边框定位问题看作四个参数的回归问题,即Classification + Regression;② 传统的滑动窗搜索思路
- 上述两种思路,在多类目标检测时,复杂度爆炸
R-CNN方案简化复杂度的思路
- 先使用传统人工特征(纹理,边缘和颜色等)进行Region Proposal (Selective Search)
- 再对候选区域进行暴力枚举,计算候选区域的深度特征,用SVM进行分类,并对每个框进行回归(线性回归模型),将特征图上的候选框调整到原图上!
流程

- 1 S e l e c t i v e S e a r c h Selective Search SelectiveSearch提取出候选区域框;
- 2 根据候选区域框与真实框的
交并比决定正负样本标签(此时不关心框内物体的类别); - 3 送入到 A l e x N e t AlexNet AlexNet 中提取 C N N CNN CNN 特征
- 4 将提取到的特征送入到 S V M SVM SVM 分类器中进行分类, 每一个类别都单独训练了一个 SVM 分类器;
- 5 对每一个框进行
边框回归, 学习特征图谱候选区域框到真实框的转换, 调整框的位置.
说明
- 特征提取网络采用AlexNet
- 输入图片227x227
- 正负样本划分: 与 gt-box 的 IoU 大于 0.5 的认为是正样本, 反之认为是负样本. 训练时, mini-batch 中正样本采样数为32(over all classes), 负样本的采样数为 96. 负样本数量多是因为在真实情况下, 背景的区域数量远大于物体数量.
- 分类器: 为每个类别训练了一个 SVM.
Selective Search
- 首先利用分割算法(Graph-Based Image Segmentation, 2004, IJCV, 贪心)得到一些初始化的区域,
- 然后计算每个相邻区域的相似性, 相似性的计算依赖于颜色相似性和纹理相似性, 同时给较小的区域赋予更多的权重, 也就是优先合并小区域(否则大区域有可能会不断吞并周围区域, 使得多尺度之应用了在局部区域, 而不是在每个位置都具有多尺度),
- 接着找出相似性最大的区域, 将它们合并, 并计算新合并的区域与其他相邻区域的相似性, 重复这个过程, 直到所有的区域被合并完为止.
R-CNN分类器为什么不采用Softmax
- 作者尝试过但是 mAP 从 54.2% 降到了 50.9%
- 下降的原因是多因素造成的, 比如对正负样本的定义, 再比如在训练 Softmax 时使用的负样本是随机采样的, 而训练 SVM 时的负样本更像是 “hard negatives” 的子集, 导致训练精度更高等等.
- 后续的 Fast RCNN 使用 Softmax 也达到了和 SVM 差不多的准确率, 训练过程更加简单.
BBox回归方式
- 在 R-CNN 的边框回归中, 我们不是直接学习真实框的坐标, 而是学习从 Proposals 到 真实框的一个偏移变换函数,
- 具体来说, 对于中心点, 需要学习的是 proposal 和 真实框相对位移, 这个位移会用 proposal 的宽和高进行归一化, 对于宽和高, 需要学习的是真实框相对于 proposal 的 log 缩放度.
t x = ( G x − P x ) / P w t y = ( G y − P y ) / P h t w = log ( G w / P w ) t h = log ( G h / P h ) t_{x}=\left(G_{x}-P_{x}\right) / P_{w} \\ t_{y}=\left(G_{y}-P_{y}\right) / P_{h} \\ t_{w}=\log \left(G_{w} / P_{w}\right) \\ t_{h}=\log \left(G_{h} / P_{h}\right) tx=(Gx−Px)/Pwty=(Gy−Py)/Phtw=log(Gw/Pw)th=log(Gh/Ph)
BBox回归为什么不直接对坐标进行回归
- 尺度不变性(宽高):不归一化对于固定的偏移量,就会导致小物体偏移了很多,大物体偏移了一点
- 平移不变性(中心点)
为什么当 Region Proposals 和 Ground Truth 较接近时, 即 IoU 较大时, 可以认为是边框回归函数是线性变换?
- 当输入的 Proposal 与 Ground Truth 相差较小时(RCNN 设置的是 IoU>0.6), 可以认为这种变换是一种线性变换, 那么我们就可以用线性回归来建模对窗口进行微调, 否则会导致训练的回归模型不 work (当 Proposal跟 GT 离得较远,就是复杂的非线性问题了,此时用线性回归建模显然不合理).
lim x → 0 log ( 1 + x ) = x t w = log ( G w / P w ) = log ( G w + P w − P w P w ) = log ( 1 + G w − P w P w ) \lim _{x \rightarrow 0} \log (1+x)=x \\ t_{w}=\log \left(G_{w} / P_{w}\right)=\log \left(\frac{G_{w}+P_{w}-P_{w}}{P_{w}}\right)=\log \left(1+\frac{G_{w}-P_{w}}{P_{w}}\right) x→0limlog(1+x)=xtw=log(Gw/Pw)=log(PwGw+Pw−Pw)=log(1+PwGw−Pw) - G w − P w = 0 G_{w}-P_{w}=0 Gw−Pw=0 的时候, 回归函数 t w t_{w} tw 可以看做是线性函数.
R-CNN缺点
- 训练过程是分阶段的(Training is a multi-stage pipeline)
- 耗费资源(Training is expensive in space and time)
- 目标检测速度太慢(Object detection is slow)
- R-CNN对于将近2000个候选框都要进行CNN提取+SVM分类!完全可以值进行一次卷积特征提取,每个region proposal的尺度不同,而全连接层输入必须是固定的长度,所以直接这样输入全连接层肯定是不行的。SPP Net解决这个问题!
Fast R-CNN 2015


有哪些改进
- 直接采用在特征图谱上的候选框组成 mini-batch, 共享卷积计算结果, 大大加速训练和推演速度.
- 提出了 RoI Pooling, 从而可以在特征图谱上截取任意尺寸的候选框
- 联合训练Smooth L1 损失的边框回归和Softmax交叉熵分类损失,训练过程更加统一.
- 对于计算量较大的全连接层, 使用奇异值分解加速计算
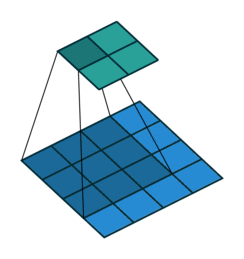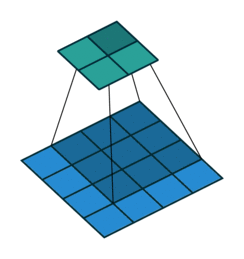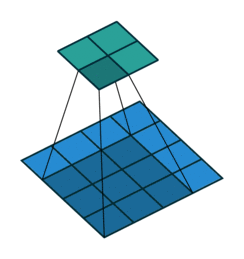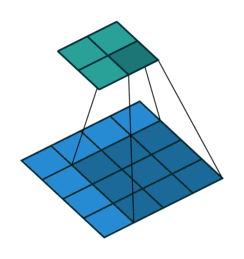
ROI Pooling
前向传播
- 任意给定尺寸为 h × w h×w h×w 的feature map的 RoI 窗口, 将其划分成 W × H W×H W×H 的网格大小
- 网格中的尺寸大约为 h / H × w / W h/H×w/W h/H×w/W(就近取整,PS:这里会导致精度损失), 然后我们在网格中执行max pooling操作
- RoI pooling 在卷积图谱上的各个通道之间是独立计算的
- 对于任意size的输入, 都可以获得固定长度的输出
- RoI layer ≈ ≈ ≈ single spatial pyramid pooling layer
- 相比于金字塔池化, RoI池化只确定了唯一大小的pooling 窗口, 以便于可以使用反向传播更新池化层之前的网络层参数, 进而提高准确率(而SPP不能更新前面的Conv层参数,只能fine tuning后面fc层的参数)
反向传播
- RoI Pooling 的反向传播过程和 Max Pooling 类似, 不同的是, 对于每个 mini-batch 的 RoI r r r 和每个 pooling 单元 j j j 及其输出 y r j y_{rj} yrj ,偏导数 ∂ L / ∂ y r j ∂L/∂y_{rj} ∂L/∂yrj 是所有 RoI 反向传播回来的累加和.
- 具体如下图所示, 当不同的 RoI 区域出现重叠时, 恰好这两个区域都选取了
x
2
,
3
x_{2,3}
x2,3 作为激活点, 那么对这个点的反向传播值
∂
L
/
∂
x
2
,
3
∂L/∂x_{2,3}
∂L/∂x2,3 就应该等于
∂
L
/
∂
y
0
,
2
+
∂
L
/
∂
y
1
,
0
∂L/∂y_{0,2}+∂L/∂y_{1,0}
∂L/∂y0,2+∂L/∂y1,0

∂ L ∂ x i = ∑ r ∑ j [ i = i ∗ ( r , j ) ] ∂ L ∂ y r j \frac{\partial L}{\partial x_{i}}=\sum_{r} \sum_{j}\left[i=i^{*}(r, j)\right] \frac{\partial L}{\partial y_{r j}} ∂xi∂L=r∑j∑[i=i∗(r,j)]∂yrj∂L
为什么 RoI Pooling 比 SPP 效果好
- SPP的Pooling方式是组合不同划分粒度下feature map的max pooling. 它也具有和RoI Pooling 类似的效果, 可以接受任意尺度的特征图谱, 并将其提取成固定长度的特征向量
- 但是 SPPNet 池化方式使得无法用恰当的方式来进行反向传播(
注意这里不是说不能反传,只不过计算代价十分昂贵!在当时情况下近乎于不能反传!), 即SPPNet 没有对浅层的网络进行 fine-tuning, 而是直接在最后两个全连接层上进行fine-tune, 虽然最后也取得了不错的成果 - 但是Roos认为, 虽然离输入层较近的前几层卷积层是比较generic和task independent的, 但是靠近输出层的卷积层还是很有必要进行fine-tune的, 他也通过实验证实了这种必要性
- 于是他简化了SPP的Pooling策略, 用一种更简单粗暴的Pooling方式来获得固定长度的输出向量, 同时也设计了相应的RoI Pooling的反向传播规则, 并对前面的基层卷积层进行了fine-tune, 最终取得了不错的效果.
Multi-task Loss
L ( p , u , t u , v ) = L c l s ( p , u ) + λ [ u ≥ 1 ] L l o c ( t u , v ) L c l s ( p , u ) = − log p u L l o c ( t u , v ) = ∑ i ∈ x , y , w , h smooth L 1 ( t i u − v i ) smooth L 1 ( x ) = { 0.5 x 2 ∣ x ∣ < 1 ∣ x ∣ − 0.5 otherwise L\left(p, u, t_{u}, v\right)=L_{c l s}(p, u)+\lambda[u \geq 1] L_{l o c}\left(t^{u}, v\right) \\ L_{c l s}(p, u)=-\log p_{u} \\ L_{l o c}\left(t^{u}, v\right)=\sum_{i \in x, y, w, h} \operatorname{smooth}_{L_{1}}\left(t_{i}^{u}-v_{i}\right) \\ \operatorname{smooth}_{L_{1}}(x)=\left\{\begin{array}{ll}0.5 x^{2} & |x|<1 \\ |x|-0.5 & \text { otherwise }\end{array}\right. L(p,u,tu,v)=Lcls(p,u)+λ[u≥1]Lloc(tu,v)Lcls(p,u)=−logpuLloc(tu,v)=i∈x,y,w,h∑smoothL1(tiu−vi)smoothL1(x)={0.5x2∣x∣−0.5∣x∣<1 otherwise
Smooth L1 相比于 L2 损失, 在回归时有什么优势
- smooth L1 损失对离异点的敏感度更低,更鲁棒;smooth L1 在值相差很大时, 其梯度为 ±1,L1 在 x 绝对值较大时, 是线性的
- L2 损失在当预测值与目标值相差很大时, 梯度很容易爆炸, 因为梯度里面包含了 ( t u i − v i ) (t_{ui}−v_i) (tui−vi) 这一项
SVD 奇异值分解简介
- 简化了计算量较大的全连接层的参数
W ≈ U Σ t V T W \approx U \Sigma_{t} V^{T} W≈UΣtVT - 矩阵 W W W 的参数量从 u v uv uv 降低到了 u t + t ut+t ut+t
- t t t为矩阵的奇异值数量,奇异值有一个性质,很多情况下,前 10% 甚至 1% 的奇异值的和就站了全部奇异值之和的 99% 以上的比例. 也就是说, 我们可以用最大的 k k k 个奇异值来近似描述矩阵. 由于 k k k 远远小于 m i n ( u , v ) min(u,v) min(u,v)
- 将单个的全连接网络层的权重矩阵 W 用两层全连接层所替代, 第一个全连接层使用的权重矩阵为 Σ t V T Σ_tV^T ΣtVT (没有偏置项), 第二个权重矩阵为 U U U (带有原始矩阵 W W W 的偏置项).
Faster R-CNN 2016
- Faster R-CNN 主要由两部分组成. 其一是用于生成候选区域框的深度全卷积网络(RPN), 其二是 Fast R-CNN 检测模型. 二者在训练的时候会进行参数共享.

RPN网络
- RPN 主要是通过在 BackBone 网络输出的特征图谱上设置一组固定大小的
anchor boxes实现. - 对于图谱上的每一个像素点, 都会枚举
k
k
k 个具有预设尺寸的 anchor boxes. 对于一个
W
×
H
W×H
W×H 大小的特征图谱, 总共会产生
W
H
k
WHk
WHk个 anchor boxes. 对于每一个 anchor box, 我们需要预测 (4+2) 个值,代表 location 偏移量和是否包含物体的二分类预测(正负样本,类别位置)



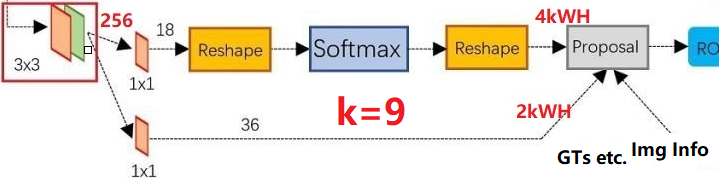
- RPN分为两条线,分别进行正负样本分类和边框回归!
- 上面一条线:① 使用 3 × 3 3×3 3×3的filter对feature map进行卷积,目的是使提取出来的feature更鲁棒;② 使用 3 × 3 3×3 3×3的filter对feature map进行卷积,目的是使提取出来的feature更鲁棒;③ 使用 1 × 1 1×1 1×1的filter进行卷积,一共为18个;④ reshape操作 ( W , H , D = 18 ) (W,H,D=18) (W,H,D=18)reshape成 ( 2 , 9 × W × H ) (2,9×W×H) (2,9×W×H);⑤ 然后我们进行softmax,得出对这 9 × W × H 9×W×H 9×W×H每一个的两个score,一个是有物体,一个是没有物体。PS:9个Anchor!
正负样本标点策略

PS:见上图:Faster R-CNN 网络实际上进行了两次 location regression.(同理也进行了两次 NMS)
- 根据 RPN 网络的输出结果, 选取 128 个 positive anchor boxes 和 128 个 negative anchor boxes 参与 Fast R-CNN 网络的训练
- 我们通常利用下面的方式确定 anchor 属于正样本还是负样本
- ① 正样本:
-
- 和某个GT box 具有最大(不一定大于0.7) 的 IoU (防止有些 GT boxes 没有匹配的 anchor)
-
- 和某个GT box 的 IoU 大于0.7
- ② 负样本:
-
- 和所有的 GT boxes 的 IoU 都小于 0.3
- 注意1: 对于剩下的既不是正样本也不是负样本的 anchor boxes, 不参与训练过程;注意2: 一个 GT box 可能会与多个anchor boxes相匹配;注意3: 一个 anchor box 只能与 一个 GT box 相匹配
损失函数
L ( { p i } , { t i } ) = 1 N c l s ∑ i L c l s ( p i , p i ∗ ) + λ 1 N r e g ∑ i p i ∗ L r e g ( t i , t i ∗ ) L\left(\left\{p_{i}\right\},\left\{t_{i}\right\}\right)=\frac{1}{N_{c l s}} \sum_{i} L_{c l s}\left(p_{i}, p_{i}^{*}\right)+\lambda \frac{1}{N_{r e g}} \sum_{i} p_{i}^{*} L_{r e g}\left(t_{i}, t_{i}^{*}\right) L({pi},{ti})=Ncls1i∑Lcls(pi,pi∗)+λNreg1i∑pi∗Lreg(ti,ti∗)
- 上式中, i i i 代表 mini-batch 中 anchor 的下标, p i p_i pi 代表预测 anchor i i i 是一个物体的可能性大小. 如果 anchor 是正样本, 则真实标签 p i ∗ p^∗_i pi∗ 为1, 反之, 如果是负样本, 则为0. t i t_i ti 是一个 vector, 用来表示参数化以后的边框坐标, t i ∗ t^∗_i ti∗ 是正样本 anchor 对应的真实框的参数化坐标.
- 分别是对数函数和smooth L1
共享参数训练

-
上图是 4-Step Alternating training(四步式交叉训练, 实验默认训练方法):
-
- 1 用 ImageNet 初始化 RPN, 训练 region proposals 任务直至收敛(得到一个不错的边界框生成器)
-
- 2 使用第一步生成的 proposals 来训练一个单独的 Fast R-CNN 网络. 这个检测网络同样也是用 ImageNet 预训练的模型进行初始化. 到这里为止, 这两个网络还没有共享卷积层.
-
- 3 使用检测网络的参数对 RPN 网络进行初始化, 但是此时 我们固定住共享的卷积层(backbone),
仅仅 fine-tuning 属于 RPN 独有的那些网络层.
- 3 使用检测网络的参数对 RPN 网络进行初始化, 但是此时 我们固定住共享的卷积层(backbone),
-
- 4 利用新的 RPN 产生的 proposals, 训练 Fast R-CNN, 同样固定住共享的卷积层,
仅仅 fine-tuning 属于 Fast R-CNN 独有的网络层.
- 4 利用新的 RPN 产生的 proposals, 训练 Fast R-CNN, 同样固定住共享的卷积层,
-
Approximate joint training(近似联合训练, 包含在官方代码中)
-
- 将 RPN 和 Fast R-CNN 在训练期间合并到一个网络中, 在每个 SGD 迭代过程, 前向计算会先由 RPN 生成 proposals (修正后的)
-
- 然后这些 proposals 会作为输入送到 Fast R-CNN 中, 在反向传播的时候, 对于共享层的参数更新, 会同时考虑来自 RPN 损失和 Fast R-CNN 损失传递过来的信号.
-
- 但是这种策略忽略了相对于 proposals boxes 坐标的导数, 因此这只是一种粗略的联合训练方式. 在实验中, 近似联合训练可以大幅减少训练时间(25~50%), 精度会有所损失, 但是性能依然客观.
-
Non-approximate joint training(非近似联合训练)
-
- 正如上面讨论的, RPN 预测的 bounding boxes 的坐标同样与输入数据之间存在联系. 在 Fast R-CNN 的 RoI pooling Layer 中会接受卷积特征, 同时也会将预测的 bounding boxes 作为输入, 因此理论上来说, 一个有效的优化器(backpropagation solver)应该包含相对于 box coordinate 的梯度. 因此, 我们需要 RoI pooling layer 相对于 box coordinates 是可导的.
如果两个物体重合度很高, Faster R-CNN 会怎么样?
- 在 RPN 阶段, 优势 proposals 是类别不可知的(class-agnostic)
因此重叠度非常高的两个框会被 NMS 过滤掉. 因此对于重合度非常高的两个物体, 很有可能会发生漏检 - 注, 但是在 Detection 阶段, 每个 anchor boxes 都与一个 GT 对应, 并且会预测特定的类别, 在进行 NMS 的时候, 是对每个类别分别进行 NMS, 所以, 也有一定的概率能够检测成功, 不过可能置信度较低, 同时框的 IoU 水平也较低(因为较高的 IoU 已经在 RPN 阶段被 NMS 掉了)
- Faster R-CNN = class-agnostic RPN + class-specific detection
Mask R-CNN 2017

简介
- 在 Faster R-CNN 模型中添加了一个与分类和回归分支平行的掩膜预测分支. 掩膜分支(mask branch) 是一个小型的 FCN 网络, 它会作用在每一个 RoI 上, 以像素到像素的方式来预测一个分割掩膜.
- Mask R-CNN的掩膜预测分支对于每一个ROI的输出都是 K m 2 Km^2 Km2,即每个类别都输出 m 2 m^2 m2的掩膜
- 预测掩膜时非常关键的一点就是要对分类任务和分割任务解耦:① 损失函数上:Mask R-CNN 使用了基于单像素的 sigmoid 二值交叉熵来替换基于单像素的 Softmax 多项式交叉熵.(softmax适合多分类)② ROI pooling 改进为 ROI Align:前者存在两次量化误差(图像坐标到特征图谱坐标, 特征图谱划分固定网格),会导致ROI和原图上坐标存在不完全对齐,这个对精度要求高的分割任务有较大的影响!所以采用ROI Align
- 除此之外,Mask R-CNN 也有一些其他的优化, 比如说更多的 anchor, 更大的 batch size, 更强的 backbone 网络(ResNeXt+FPN)等等.
- Mask R-CNN是一个很多state-of-the-art算法的合成体,并非常巧妙的设计了这些模块的合成接口:
- 使用残差网络作为卷积结构
- 使用FPN作为骨干架构
- 使用Faster R-CNN的物体检测流程:RPN+Fast R-CNN
- 增加FCN用于语义分割
ROI Align
- ROI Pooling存在的两次量化导致位置映射粗糙!>
Misalignment问题 - 量化1 将原图上的ROI坐标就近取整到特征图上(取整损失)
- 量化2 将特征图上的ROI区域分割乘 k × k k×k k×k个cell(取整损失)
- 小目标受Misalignment影响更大!
思路
- RoI Align的解决思路:
- 1 取消量化操作(即, 我们使用 x/16, 而不是 [x/16]),
- 2 使用双线性内插的方法获得坐标为浮点数的像素点上的图像数值, 从而将整个特征聚集过程转换为一个连续的操作
- 具体流程:
- 1 计算 RoI 在特征图谱上的浮点坐标 x/16
- 2 在每一个 bin 当中, 均匀的选取若干个( 实验效果显示 4 个较好)采样点
- 3 对于每一个采样点, 利用离它最近的四个 feature map 点计算当前采样点的值(双线性插值)
- 4 对每个 bin 中的所有采样点, 分别执行 max / average pooling操作.
- 5 最终输出 k × k k×k k×k 的固定尺寸特征图谱 (如 2x2).
ROI Align 的BP过程
- 常规的ROI Pooling
∂ L ∂ x i = ∑ r ∑ j [ i = i ∗ ( r , j ) ] ∂ L ∂ y r , j \frac{\partial L}{\partial x_{i}}=\sum_{r} \sum_{j}\left[i=i^{*}(r, j)\right] \frac{\partial L}{\partial y_{r, j}} ∂xi∂L=r∑j∑[i=i∗(r,j)]∂yr,j∂L - ROI Align
∂ L ∂ x i = ∑ r ∑ j [ d ( i , i ∗ ( r , j ) ) < 1 ] ( 1 − Δ h ) ( 1 − Δ w ) ∂ L ∂ y r j \frac{\partial L}{\partial x_{i}}=\sum_{r} \sum_{j}\left[d\left(i, i^{*}(r, j)\right)<1\right](1-\Delta h)(1-\Delta w) \frac{\partial L}{\partial y_{r j}} ∂xi∂L=r∑j∑[d(i,i∗(r,j))<1](1−Δh)(1−Δw)∂yrj∂L - 在池化前的特征图中, 每一个与 x i ∗ ( r , j ) x_{i^{*}(r, j)} xi∗(r,j)横纵坐标均小于 1 的点都会接受与次对应的点 y r j y_{rj} yrj 回传的梯度. 故 RoI Align 的反向传播公式如上!
Mask分支的实现
- 用多层感知机(若干全连接层)或者全卷积网络(若干卷积层)实现
- 后者因为具有空间编码的优势,效果更好!

总结
- 基于 Faster R-CNN 的基本结构, 替换 backbone 为 ResNet-50/101-C4 和 ResNet-50/101-FPN, ResNeXt-101-FPN.
- 除了边框回归和目标分类两个分支外, 新添加了一个全卷积的 Mask Prediction 网络, 该分支在每一个 RoI 上的输出维度为 K × m 2 K×m^2 K×m2, 代表 K 个类别的二值掩膜.
- 在计算 mask 的损失时, 使用的是 sigmoid 的二分类损失, 而不是多分类的 softmax 损失, 这减少了类别之前的竞争, 使得可以生成更好的分割结果.
- RoIAlign 消除了 RoI Pooling 中的两次量化操作, 使得最终提取到的特征可以 RoI 尽可能的对齐. 从而大幅提升在实例分割任务上的性能表现.
FCN 2014
- 分割模型,为R-FCN铺垫
- FCN 将网络中的全连接层全都换成了卷积层(卷积核大小为 1 × 1 1×1 1×1, 通道数为 FC 神经元个数), 这么做有两个好处: ① 可以接受任意尺寸的图片输入 ② 对于较大的图片输入, 最终会产生多个卷积块, 共用一套权重, 减少重复计算, 从而可以加快模型的计算速度.
- 在进行分割任务时, FCN 会利用 反卷积 和 跳跃连接 进行像素预测. 也就是说它会将深层图谱的预测结果和 upsample 后的图谱预测结果融合(采用 max fusion), 这样预测出来的结果会更加精细。
- 在 FCN 中, 分别在步长为 16 和 步长为 8 的特征图谱进行了分割预测, 结果也显示越精细的特征图谱, 分割的结果也越好. 只不过随着步长的缩短, 获得的提升也慢慢变小了.
全卷积结构
- 基于全卷积网络结构,把FC全去掉!

跳级结构



- 反卷积层相对于双线性插值来说, 具有可学习的参数, 可以通过网络的输出 loss 动态的调整自身的上采样过程
反卷积
| 普通卷积 | 反卷积 |
|---|---|
 | 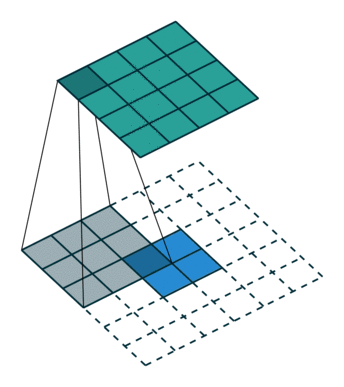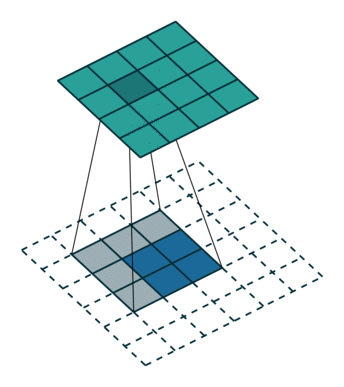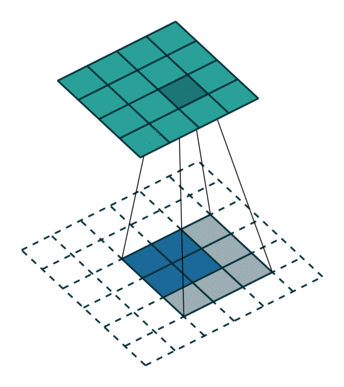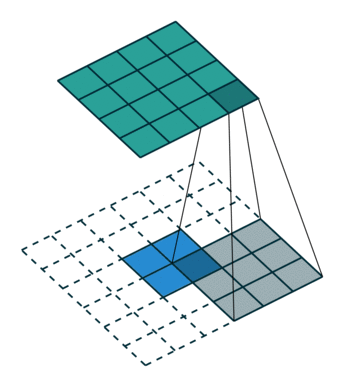 |
- 尺寸计算的公式的运算全是逆的!
R-FCN 2016
- R-FCN 的主要贡献在于解决了“分类网络的位置不敏感性(translation-invariance in image classification)”与“检测网络的位置敏感性(translation-variance in object detection)”之间的矛盾,在提升精度的同时利用“位置敏感得分图(position-sensitive score maps)”提升了检测速度。

动机
- 对于 two-stage 检测网络来说, 在 RoI Pooling 之前的 backbone 网络层的计算时被所有 RoI 所共享的, 而 RoI Pooling 之后的计算时单独对每个 RoI 进行分类和回归, 因此虽然各个 RoIs 的计算存在大量的重复, 依然无法共享这部分计算.
- 对于前面的 backbone 网络来说, 它本身不会考虑坐标信息, 因此具有 “位置不敏感性(translation-invariance)”, 而 RoI Pooling 之后的网络, 它会考虑目标的位置信息, 因此具有 “位置敏感性(translation-variance)”
- 为了让目标检测网络具有 “位置敏感性”, Faster R-CNN 采取了一种不太自然的做法, 那就是将 RoI Pooling 插在了 backbone 网络的卷积层之间
- 对于 ResNet 来说, 它将 RoI Pooling 插在了 C4 卷积段的后面, 这样带来的问题就是 RoI Pooling Layer 之后的 C5 卷积段是无法在 RoIs 上共享卷积计算
Position-sensitive Score Map
- 编码每个物体的 RoI 信息, 它将 RoI 划分成 k × k k×k k×k 子区域, 每个子区域代表了 RoI 的某一特定部位.
- R-FCN 首先会共享 backbone 的所有卷积层, 然后在共享的卷积层的最后接上一层卷积,这个卷积层的输出图谱就是 position-sensitive score map, 它的 height, width 保持不变, 其 channels =
k
2
(
C
+
1
)
k^2(C+1)
k2(C+1), C+1 代表物体类别, 也就是说每个类别都有
k
2
k^2
k2 个 score maps, 每个 score map 都对应了物体某一特定部位的响应值!

- 利用 Position-sensitive RoI Pooling 对这个尺度为 W × H × k 2 ( C + 1 ) W×H×k^2(C+1) W×H×k2(C+1) 的特征图谱进行池化, 池化时对于每个 RoI 的第 i 个子区域, 我们就在第 i i i 个 score map 上的对应区域采用池化来得到 RoI 第 i 个子区域的值, 对于每一个类别都是如此, Ps-RoI Pooling 的输出就是一个 k 2 × ( C + 1 ) k^2×(C+1) k2×(C+1) 大小的特征图谱(注意 RoI Pooling 的输出尺寸是用划分的网格数决定的).
- 我们对得到的 k 2 × ( C + 1 ) k^2×(C+1) k2×(C+1) 大小的特征图谱通过取 平均值 的方式来投票, 得到 (C+1) 维的向量, 然后利用 softmax 得到每个类别的预测概率.
- 对于回归操作, 其方法类似, 通过在回归分支上添加一个卷积层实现, 卷积层的输出尺寸是 W × H × 4 k 2 W×H×4k^2 W×H×4k2, 然后经过 Ps-RoI Pooling, 对每个 RoI 都输出 k 2 × 4 k^2×4 k2×4 尺寸的特征图谱, 再经过取平均投票的方式, 得到一个 4−d 的向量, 该向量就代表了这个 RoI 所对应的偏移量 t = ( t x , t y , t w , t h ) t=(tx,ty,tw,th) t=(tx,ty,tw,th)
- 利用position sensitive score map将目标位置信息融合进RoI + 让更多的层共享计算
R-FCN缺点
- 对于遮挡情况效果很差, 因为当物体被遮挡时, 其关键部位往往被被识别成遮挡物体, 使得无法正确识别被遮挡物体, 详情见 CoupleNet 解释.
CoupleNet 2017
动机
- R-FCN 利用 PSRoI Pooling, 利用物体的局部特征, 将位置敏感行引入到了检测网络中, 但是同时, PsRoI Pooling 的设计在一定程度上忽略了物体的整体结构信息以及它的 Global Feature.
简介
- PsRoI Pooling 的设计在一定程度上忽略了物体的整体结构信息以及它的 Global Feature. 因此 CoupleNet 提出利用 RoI Pooling 捕捉物体的 Global Feature, 并将其与 PsRoI Pooling 提取到的 local feature 相结合, 共同决定最终的预测结果.
结构

- Local FCN: 由 PSRoI Pooling 和相应的预测网络组成, 用于提取 local feature, 就像 R-FCN 中的那样
- Global FCN: 由 RoI Pooling 和相应的预测网络组成, 其中, RoI Pooling 会分别在原始的 RoI 和 扩大两倍 后的 RoI 上提取特征, 然后将结果在通道维度上连接. 这样做不仅可以提取到该物体的全局特征, 同时也可以提取到物体的 context 信息, 这对于解决遮挡类问题有很大帮助.
如何结合 局部特征 和 全局特征
- Normalization:
-
- L2 归一化: 会损伤性能
-
- 1x1 卷积自动学习合适的输出: 输入输出 Tensor 形状不变, 每个值都根据学习到的结果进行变化. 效果好, 提升 0.6 个百分点.
- Coupling Structure(结合 local 和 global 分支):
-
- element-wise sum: 在任何情况下有最优, 即使在不使用 Normalization - - - 的情况下, 也是最优选择
-
- element-wise product: 很差
-
- element-wise maximum: 不如 sum

- element-wise maximum: 不如 sum
CoupleNet 为什么可以解决遮挡类问题
- 以下图为例, 沙发坐了了两个人, 当我们对检测沙发时, PSRoI Pooling 会给出非常低的置信度, 因他目标框内的各个部位都不是沙发的特定部位, 而是其他类别的物体, 因此, R-FCN 对于遮挡问题表现很差. 对于 RoI Pooling 来说, 由于它在一定程度上考虑了 RoI 的整体特征, 因此, 可以给出一定的置信度, 但是也只有 0.45.
- 而 CoupleNet 一方面使用 PSRoI Pooling 解决了分类网络位置不敏感和检测网络位置敏感性之间的矛盾, 同时利用 global 信息和 context 信息弥补了 PSRoI Pooling 只关注 local feature 的缺点, 因此在结合两个分支的输出结果以后, 可以很好的检测出被局部遮挡的物体.(人坐在沙发, 椅子, 桌子前等等)

Cascade R-CNN 2017
简介
- 本文针对检测问题中正负样本区分的 IoU 阈值选择问题提出了一种新的目标检测框架, Cascade R-CNN
- 在 two-stage 的目标检测模型当中, 需要设置 IoU 阈值来区分正样本和负样本, 通常, 阈值选的越高, 正样本的框就与真实框越接近, 但是这样就会使得正样本的数量大大降低, 训练时容易产生过拟合问题, 而如果阈值选的较低, 就会产生大量的 FP 样本. 根据经验和实验证明可知, 当输入的 proposals 和真实框的 IoU 的值, 与训练器训练时采用的 IoU 的阈值比较接近的时候, 训练器的性能会比较好, 为此, 作者提出了一种级联式的阈值训练方法, 先在较低的阈值上训练检测器, 得到具有更高 IoU 的候选框输出, 然后在此基础上进行训练, 不断提升 IoU 的阈值, 这样一来, 最终生成的候选框质量会变得更高 (与真实框的 IoU 更大). 作者提出这种框架的启发来自于图1©, 整体来说, 输入的 proposals 的 IoU 在经过检测器边框回归以后, 其输出的边框与真实框会有更大的 IoU, 因此可以将这个具有更大 IoU 的框作为下一个检测器的输入, 同时调高训练时的 IoU(H1 变成 H2), 进而得到质量更高的框


- 每一个 stage 的 detector 都可以有足够多满足阈值的样本进行训练, 不会发生过拟合问题
- 更深层的 detector 可以在精度更高的 proposals 上进行预测, 生成的结果效果更好
- 每个 stage 的阈值是逐级升高的(对比 Iterative BBox 使用的是相同的阈值), 使之可以逐渐提高 proposals 的 IoU
3 One-Stage Network
说明
- 2stage目标检测继承自传统的Region Proposal后穷举筛选的思路;
- 1stage目标检测继承自传统的滑动窗穷举搜索的思路,主要思路是均匀地在图片的不同位置进行密集抽样,抽样时可以采用不同尺度和长宽比,然后利用CNN提取特征后直接进行分类与回归,整个过程只需要一步,所以其优势是速度快,但是均匀的密集采样的一个重要缺点是训练比较困难,这主要是因为正样本(物体)与负样本(背景)极其不均衡(参见Focal Loss),导致模型准确度稍低。不同算法的性能如图1所示,可以看到两类方法在准确度和速度上的差异。


YOLOv1 2015
简介

- 经过若干卷积层和池化层,变成 7 × 7 × 1024 7×7×1024 7×7×1024张量;再经过两次全连接,输出 7 × 7 × 30 7×7×30 7×7×30. 后面接0.5的dropout
7:实际就是将448x448的图片划分为7x7个网格,每个网格负责检测中心落在该网格中的物体。每一个网格预测B个bounding boxes,以及这些bounding boxes的confidence scores。- ① c o n f i d e n c e = P r ( O b j e c t ) ∗ I O U p r e d t r u t h confidence=Pr(Object) * I O U_{pred}^{truth} confidence=Pr(Object)∗IOUpredtruth,栅格中不存在一个 object,则confidence score应该为0;否则的话,confidence score则为 predicted bounding box与 ground truth box之间的 IOU(intersection over union)。这个 confidence scores反映了模型对于这个栅格的预测:该栅格是否含有物体,以及这个box的坐标预测的有多准。
30:2x(4+1)+20,每个网格支持两个box,1个非背景置信度,20个类别!- ① YOLO对每个bounding box有5个predictions:x, y, w, h,
and confidence。 - ② 坐标x,y代表了预测的bounding box的中心与栅格边界的相对值。
- ③ 坐标w,h代表了预测的bounding box的width、height相对于整幅图像width,height的比例。
- ④ confidence就是预测的bounding box和ground truth box的IOU值。
- ⑤ 每一个栅格还要预测C个 conditional class probability(条件类别概率):Pr(Classi|Object)。即在一个栅格包含一个Object的前提下,它属于某个类的概率。
- ⑥ conditional class probability信息是针对每个网格的。confidence信息是针对每个bounding box的。
Pr ( Class i ∣ Object ) ∗ Pr ( Object ) ∗ IOU pred truth = Pr ( Class i ) ∗ IOU pred truth \operatorname{Pr}\left(\text { Class }_{i} | \text { Object }\right) * \operatorname{Pr}(\text { Object }) * \operatorname{IOU}_{\text {pred }}^{\text {truth }}=\\ \operatorname{Pr}\left(\text { Class }_{i}\right) * \operatorname{IOU}_{\text {pred }}^{\text {truth }} Pr( Class i∣ Object )∗Pr( Object )∗IOUpred truth =Pr( Class i)∗IOUpred truth

优化目标
- 问题建模为回归问题
- 直接通过整张图片的所有像素得到bounding box的坐标、box中包含物体的置信度和class probabilities。通过YOLO,每张图像只需要看一眼就能得出图像中都有哪些物体和这些物体的位置
- 1、将图像resize到448x448作为神经网络的输入
2、运行神经网络,得到一些bounding box坐标、box中包含物体的置信度和class probabilities
3、进行非极大值抑制,筛选Boxes
损失函数
- 都是平方损失函数,回归
λ c o o r d ∑ i = 0 S 2 ∑ j = 0 B I i j o b j [ ( x i − x ^ x ) 2 + ( y i − y ^ i ) 2 ] + λ c o o r d ∑ i = 0 S 2 ∑ j = 0 B I i j o b j [ ( w i − w ^ i ) 2 + ( h i − h ^ i ) 2 ] + ∑ i = 0 S 2 ∑ j = 0 B I i j o b j ( C i − C ^ i ) 2 + λ n o o b j ∑ i = 0 S 2 ∑ j = 0 B I i j n o o b j ( C i − C ^ i ) 2 + ∑ i = 0 S 2 I i o b j ∑ c ∈ classes ( p i ( c ) − p ^ i ( c ) ) 2 \lambda_{c o o r d} \sum_{i=0}^{S^{2}} \sum_{j=0}^{B} I_{i j}^{o b j}\left[\left(x_{i}-\hat{x}_{x}\right)^{2}+\left(y_{i}-\hat{y}_{i}\right)^{2}\right]+ \\\lambda_{c o o r d} \sum_{i=0}^{S^{2}} \sum_{j=0}^{B} I_{i j}^{o b j}\left[\left(\sqrt{w}_{i}-\sqrt{\hat{w}_{i}}\right)^{2}+\left(\sqrt{h}_{i}-\sqrt{\hat{h}_{i}}\right)^{2}\right] \\ +\sum_{i=0}^{S^{2}} \sum_{j=0}^{B} I_{i j}^{o b j}\left(C_{i}-\hat{C}_{i}\right)^{2}+\lambda_{n o o b j} \sum_{i=0}^{S^{2}} \sum_{j=0}^{B} I_{i j}^{n o o b j}\left(C_{i}-\hat{C}_{i}\right)^{2} \\ +\sum_{i=0}^{S^{2}} I_{i}^{o b j} \sum_{c \in \text { classes }}\left(p_{i}(c)-\hat{p}_{i}(c)\right)^{2} λcoordi=0∑S2j=0∑BIijobj[(xi−x^x)2+(yi−y^i)2]+λcoordi=0∑S2j=0∑BIijobj[(wi−w^i)2+(hi−h^i)2]+i=0∑S2j=0∑BIijobj(Ci−C^i)2+λnoobji=0∑S2j=0∑BIijnoobj(Ci−C^i)2+i=0∑S2Iiobjc∈ classes ∑(pi(c)−p^i(c))2
- 对于有物体中心落入的 cell, 需要计算分类 loss 和两个 confidence loss,
- 对于没有物体中心落入的 cell, 只需要计算 confidence loss.
- 对于两个 bbox loss, 只计算 IOU 较大的 bounding box loss
优点
- 检测速度快,45fps;FAST YOLO 155fps(YOLOv2在嵌入式设备上)
- YOLO可以很好的避免背景错误,产生false positives。不像其他物体检测系统使用了滑窗或region proposal,分类器只能得到图像的局部信息。YOLO在训练和测试时都能够看到一整张图像的信息,因此YOLO在检测物体时能很好的利用上下文信息,从而不容易在背景上预测出错误的物体信息。
- YOLO可以学到物体的泛化特征。
缺点
- YOLO的物体检测精度低于其他state-of-the-art的物体检测系统。
- YOLO容易产生物体的定位错误。定位粗糙
- YOLO对小物体的检测效果不好(尤其是密集的小物体,因为一个栅格只能预测2个物体)。缺少尺度
YOLOv2 & YOLO9000 2016
- Better / Faster / Stronger
- 引入了Anchor,不再是Anchor-free检测框架了!
改进
- 1
BN层:mAP上升2.4!放弃了Dropout,添加了BN层;BN层有助于解决反向传播中的梯度消失和梯度爆炸,降低对一些超参数的敏感(学习率+网格参数大小+激活函数选择) - 2
使用高分辨图像fine tuning网络中的分类模型,mAP上升3.7!图像分类的训练样本很多,但是标注了边框的检测定位样本相对小,因为标注边框的人工成本高!所以目标检测网络通常都先用图像分类样本训练卷积层,提取图像特征(图像分类样本的分辨率不是很高)① YOLO v1使用ImageNet的图像分类样本 224x224 训练CNN卷积层。然后在训练对象检测时,采用更高分辨率的 448x448 的图像作为输入。但切换模型对性能有一定影响。② YOLO2采用 224x224 图像进行分类模型预训练后,再采用 448x448 的高分辨率样本对分类模型进行微调(10epoch),使网络特征逐渐适应 448×448 的分辨率。然后再使用 448×448 的检测样本进行训练,缓解了分辨率突然切换造成的影响。 - 3
采用Anchor Boxes,召回率提升,81%>88%,mAP轻微下降到0.2!在每个grid预先设定一组不同大小和宽高比的边框,来覆盖整个图像的不同位置和多种尺度,这些先验框作为预定义的候选区在神经网络中将检测其中是否存在对象,以及微调边框的位置。同时YOLO2移除了全连接层。另外去掉了一个池化层,使网络卷积层输出具有更高的分辨率。YOLO 利用 anchor 会生成 13 × 13 × 5 = 845 13×13×5=845 13×13×5=845 个候选区域框, 相比于YOLOv1的98( 7 × 7 × 2 7×7×2 7×7×2)个!导致召回率增加但是准确率却稍稍降低了!可能是训练的锅! - 4
聚类提取先验框的尺度。采用1-IoU作为相似性度量,采用kmeans作为聚类算法,聚类出k个尺度! - 5
Direct location prediction(直接位置预测),约束预测边框的位置。借鉴了Faster R-CNN的先验框方法,如下。预测框的中心 = 先验框的中心 + 学习偏差( t 是 学 习 参 数 t是学习参数 t是学习参数)。是没有约束的,导致训练早期,预测边框可能会出现在任何位置!不稳定!
x = ( t x ∗ w a ) + x a y = ( t y ∗ h a ) + y a x=\left(t_{x} * w_{a}\right)+x_{a} \\ y=\left(t_{y} * h_{a}\right)+y_{a} x=(tx∗wa)+xay=(ty∗ha)+ya
YOLOv2调整了公式,将预测框的中心约束在特定的grid网格内!
b x = σ ( t x ) + c x b y = σ ( t y ) + c y b w = p w e t w b h = p h e t h P r ( object ) ∗ I O U ( b , object ) = σ ( t o ) b_{x}=\sigma\left(t_{x}\right)+c_{x} \\ b_{y}=\sigma\left(t_{y}\right)+c_{y} \\ b_{w}=p_{w} e^{t_{w}} \\ b_{h}=p_{h} e^{t_{h}} \\ Pr(\text {object}) * I O U(b, \text {object})=\sigma\left(t_{o}\right) bx=σ(tx)+cxby=σ(ty)+cybw=pwetwbh=phethPr(object)∗IOU(b,object)=σ(to)

- 6
Fine-Grained Features,Passthrough层检测细粒度特征。参考了ResNet的恒等连接,将卷积层wxh进行4等分,进行通道拼接和经过卷积核池化的另一分支进行通道拼接!具体是将 26 × 26 × 512 26×26×512 26×26×512 reshape 成 13 × 13 × 2048 13×13×2048 13×13×2048, 然后与原来的 13 × 13 × 1024 13×13×1024 13×13×1024 的特征图谱连接在一起形成 13 × 13 × 3072 13×13×3072 13×13×3072 的特征图谱, 然后在此特征图谱上进行预测! mAP 提升 1%!

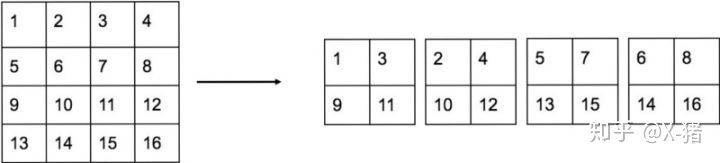
- 7
Multi-Scale Training. 提升mAP的1.4!在训练过程中, 每隔一定(10) 的 iterations 之后就随机改变输入图片的大小, 图片大小为一系列 32 倍数的值(因为总的 stride 为 32 32 32): 320 , 352 , … , 608 {320, 352, …, 608} 320,352,…,608 - 8
Darknet-19,DarkNet-19比VGG-16小一些,精度不弱于VGG-16,但浮点运算量减少到约1/5,以保证更快的运算速度。

训练
- 对样本的处理方式: 和 YOLOv1 相同, 对于训练图片中的 ground truth, 如果其中心落在了某个 cell 内, 那么该 cell 内的 5 个 anchor 就负责预测该物体, 并且最终只有一个边界框会与之匹配, 其他的会被 NMS 掉. 所以 YOLOv2 同样假定每个 cell 至多含有一个 ground truth, 而在实际上基本不会出现多于一个的情况. 与 gt 匹配的 anchor 会计算坐标误差, 置信度误差, 和分类误差, 而其他的边框则只计算置信度误差.
损失函数


loss
t
=
∑
i
=
0
W
∑
j
=
0
H
∑
k
=
0
A
1
Max IOU
<
Thresh
λ
noobj
∗
(
−
b
i
j
k
o
)
2
+
1
t
<
12800
λ
prior
∗
∑
r
ϵ
(
x
,
y
,
w
,
h
)
(
prior
k
r
−
b
i
j
k
r
)
2
+
1
k
truth
(
λ
coord
∗
∑
r
ϵ
(
x
,
y
,
w
,
h
)
(
truth
r
−
b
i
j
k
r
)
2
+
λ
obj
∗
(
I
O
U
truth
k
−
b
i
j
k
o
)
2
+
λ
class
∗
(
∑
c
=
1
c
(
truth
c
−
b
i
j
k
c
)
2
)
)
\begin{array}{rl}\operatorname{loss}_{t}=\sum_{i=0}^{W} \sum_{j=0}^{H} \sum_{k=0}^{A} & 1_{\text {Max } \text { IOU }<\text { Thresh }} \lambda_{\text {noobj }} *\left(-b_{i j k}^{o}\right)^{2} \\ & +1_{t<12800} \lambda_{\text {prior }} * \sum_{r_{\epsilon}(x, y, w, h)}\left(\text { prior }_{k}^{r}-b_{i j k}^{r}\right)^{2} \\ & +1_{k}^{\text {truth }}( \lambda_{\text {coord }} * \sum_{r_{\epsilon}(x, y, w, h)}\left(\text { truth }^{r}-b_{i j k}^{r}\right)^{2} \\ & +\lambda_{\text {obj }} *\left(I O U_{\text {truth }}^{k}-b_{i j k}^{o}\right)^{2} \\ & \left.+\lambda_{\text {class }} *\left(\sum_{c=1}^{c}\left(\text { truth }^{c}-b_{i j k}^{c}\right)^{2}\right)\right)\end{array}
losst=∑i=0W∑j=0H∑k=0A1Max IOU < Thresh λnoobj ∗(−bijko)2+1t<12800λprior ∗∑rϵ(x,y,w,h)( prior kr−bijkr)2+1ktruth (λcoord ∗∑rϵ(x,y,w,h)( truth r−bijkr)2+λobj ∗(IOUtruth k−bijko)2+λclass ∗(∑c=1c( truth c−bijkc)2))
- 背景的置信度误差 + 预测框和Anchor的坐标误差(前12800次迭代时计算) + 预测框和GT的匹配损失(后三项:坐标误差+置信度误差+分类误差)
Stronger:YOLO 9000
- Hierarchical classification(多层分类)
- YOLO2于是根据WordNet[5],将ImageNet和COCO中的名词对象一起构建了一个WordTree,以physical object为根节点,各名词依据相互间的关系构建树枝、树叶,节点间的连接表达了对象概念之间的蕴含关系(上位/下位关系)
- VOC数据集可以检测20种对象,但实际上对象的种类非常多,只是缺少相应的用于对象检测的训练样本。YOLO2尝试利用ImageNet非常大量的分类样本,联合COCO的对象检测数据集一起训练,使得YOLO2即使没有学过很多对象的检测样本,也能检测出这些对象。
- 基本的思路是,如果是检测样本,训练时其Loss包括分类误差和定位误差,如果是分类样本,则Loss只包括分类误差。
- ImageNet的数据标签来源于WordNet,具有一定层次结构。作者根据WordNet建立了ImageNet标签的树(WordTree)。作者采用标签树训练了Darknet-19.


- 构建好的WordTree有9418个节点(对象类型),包括ImageNet的Top 9000个对象,COCO对象,以及ImageNet对象检测挑战数据集中的对象,以及为了添加这些对象,从WordNet路径中提取出的中间对象
- 构建WordTree:①检查每一个将用于训练和测试的ImageNet和COCO对象,在WordNet中找到对应的节点,如果该节点到WordTree根节点(physical object)的路径只有一条(大部分对象都只有一条路径),就将该路径添加到WrodTree。②经过上面操作后,剩下的是存在多条路径的对象。对每个对象,检查其额外路径长度(将其添加到已有的WordTree中所需的路径长度),选择最短的路径添加到WordTree。这样就构造好了整个WordTree
- 既然各节点预测的是条件概率,那么一个节点的绝对概率就是它到根节点路径上所有条件概率的乘积!
- 但是一般采用贪婪的算法:从根节点开始向下遍历,对每一个节点,在它的所有子节点中,选择概率最大的那个(一个节点下面的所有子节点是互斥的),一直向下遍历直到某个节点的子节点概率低于设定的阈值(意味着很难确定它的下一层对象到底是哪个),或达到叶子节点,那么该节点就是该WordTree对应的对象!
SSD 2016
- Single Shot MultiBox Detector
简介
- SSD 是一种 one-stage 检测模型, 它最主要的特点就是使用了多尺度的特征图谱进行 one-stage 的目标检测预测
- 具体来说, SSD 在 VGGNet 之后又添加了五个卷积段, 每个卷积段都是用 1 × 1 1×1 1×1 和 3 × 3 3×3 3×3 大小的卷积核组成的, 然后在加上 VGGNet 的 conv4_3 卷积层, 总共可以得到六种不同尺度的特征图谱.
- 对于每一个特征图谱上的每一个 location, 都会有 k k k 个 default boxes 作为初始的候选框, 不同尺度的特征图谱对应的 k k k 的大小也不相同 ( 4 , 6 , 6 , 6 , 4 , 4 ) (4, 6, 6, 6, 4, 4) (4,6,6,6,4,4). 对于一个尺度为 m × n m×n m×n 的特征图谱来说, 它具有的 default box 的个数就是 m × n × k m×n×k m×n×k, 又因为 one-stage 模型会在回归的同时进行分类, 因此, 最终的输出结果是一个形状为 m × n × k × ( c + 4 ) m×n×k×(c+4) m×n×k×(c+4)的 tesor, k k k就代表了 k k k 个 default box, ( c + 4 ) (c+4) (c+4) 代表了每个 box 的分类得分和坐标偏移量.


- SSD效果为什么好? ①
多尺度②设置了多种宽高比的anchor③数据增强PS:Default Box、Prior box和 Anchor表示同一个意思! - PS:Anchor技术的鼻祖是DeepMultiBox(
Scalable Object Detection using Deep Neural Networks),这篇论文里首次提出使用prior(先验框),并且提出使用prior做匹配。后面的众多工作,比如RCNN系列,YOLO系列都使用了anchor这个术语,而在SSD中anchor又叫default box,本质上都是表示的同一个东西。
多尺度

- SSD使用6个不同特征图检测不同尺度的目标。低层预测小目标,高层预测大目标。
为什么设置不同的Anchor
- SSD300中anchor的数量: ( 38384 + 19196 + 10106 + 556 + 334 + 114 ) = 8732 (38384 + 19196 + 10106 + 556 + 334 + 114) = 8732 (38384+19196+10106+556+334+114)=8732
- 通过anchor设置每一层实际响应的区域,使得某一层对特定大小的目标响应
- 为什么在同一个特征图上可以设置多个anchor检测到不同尺度的目标?虽然分类和回归使用的是同一个特征图,但是不同通道的3x3卷积核会学习到那块区域的不同的特征,所以不同通道对应的anchor可以检测到不同尺度的目标。
- anchor本身不参与网络的实际训练,anchor影响的是classification和regression分支如何进行encode box(训练阶段)和decode box(测试阶段)。测试的时候,anchor就像滑动窗口一样,在图像中滑动,对每个anchor做分类和回归得到最终的结果。
- 为什么anchor可以设置每一层实际响应的区域呢?
因为每一层实际响应的区域其实是有效感受野区域,而有效感受野理论表明有效感受野在训练过程中会发生变化,所以每一层实际响应的区域其实是会发生变化的,正是由于有效感受野大小会发生变化,所以可以通过anchor设置每一层实际响应的区域。 - anchor的匹配。既然anchor是实际响应的区域,训练的时候就需要知道每个anchor的分类和回归的label,如何确定呢?SSD通过anchor与groundtruth匹配来确定label。
- 在训练阶段,SSD会先寻找与每个anchor的IOU最大的那个ground truth(大于IOU阈值0.5),这个过程叫做匹配。如果一个anchor找到了匹配的ground truth,则该anchor就是正样本,该anchor的类别就是该ground truth的类别,如果没有找到,该anchor就是负样本。
- 由于现实中的目标会有各种宽高比(比如行人),设置多个宽高比可以检测到不同宽高比的目标。
如何选择anchor的scale和Aspect ratio?
- 如feature maps数量为 m,每个特征图中的Anchor的Scale,计算公式如下:
s k = s min + s max − s min m − 1 ( k − 1 ) , k ∈ [ 1 , m ] s_{k}=s_{\min }+\frac{s_{\max }-s_{\min }}{m-1}(k-1), k \in[1, m] sk=smin+m−1smax−smin(k−1),k∈[1,m] - 设定 S m i n S_{min} Smin和 S m a x S_{max} Smax为0.2和0.9,最低到最高层的尺度为0.2~0.9!
- m = 6 ( 4 , 6 , 6 , 6 , 4 , 4 ) m=6(4,6,6,6,4,4) m=6(4,6,6,6,4,4), 因此就有 s = ( 0.2 , 0.34 , 0.48 , 0.62 , 0.76 , 0.9 ) s=(0.2,0.34,0.48,0.62,0.76,0.9) s=(0.2,0.34,0.48,0.62,0.76,0.9)
- 设置的宽高比为 1 , 2 , 3 , 1 / 2 , 1 / 3 {1,2,3,1/2,1/3} 1,2,3,1/2,1/3
- 则每一个default boxes 的width 和height就可以得到(
w
k
a
h
k
a
=
a
r
w_{k}^{a} h_{k}^{a}=a_{r}
wkahka=ar)
w k a = s k a r h k a = s k a r w_{k}^{a}=s_{k} \sqrt{a_{r}} \\ h_{k}^{a}=\frac{s_{k}}{\sqrt{a_{r}}} wka=skarhka=arsk - 当aspect ratio为1时,作者还增加一种scale的anchor,尺度为 s k ′ = s k s k + 1 s_{k}^{\prime}=\sqrt{s_{k} s_{k+1}} sk′=sksk+1
- 所以每个feature map上每个点像素对应6个Anchor!
- 表格中每个宽高比的anchor的实际宽和高需要乘以输入图像的大小,如SSD300,则需要使用上面的数值乘以300得到anchor实际大小。
数据增强
- 水平翻转, 随机裁剪+颜色扭曲(random crop & color distortion), 随机采集区域块(randomly sample a patch, 目标是为了获取小目标训练样本)
为什么SSD不直接使用浅层的特征图谱, 而非要额外增加卷积层, 这样不是增加模型的复杂度了吗?
- 理想情况下, SSD 的特征金字塔是从多个卷积层输出的特征图谱得到的, 因此它的计算成本几乎为零. 但是为了避免使用到那些表征能力不强的低阶特征图谱(浅层), SSD 只使用了深层的特征图谱(conv4_3), 同时在 backbone 网络的后面又添加了几层卷积层来提取高表征能力的特征图谱.
- 但是这样就使得 SSD 错过了那些低阶特征的信息, 这些低阶特征中往往包含了高阶特征不具有的信息, 如小物体的特征信息, 这也是为什么 SSD 对小物体不敏感的原因之一.
缺点
- SSD主要缺点:SSD对小目标的检测效果一般,作者认为小目标在高层没有足够的信息。1. 增大输入尺寸;2. 使用更低的特征图做检测(比如S3FD中使用更低的conv3_3检测);3. FPN(已经是检测网络的标配了)
- 关于anchor的设置的优化;YOLOV2中使用聚类的方式初始化anchor
代码
DSSD 2017
- 利用反卷积模块向特征图谱中添加更多的上下文信息
主要是对SSD的一点改进, SSD使用了不同阶段的卷积特征图谱进行目标检测, 而DSSD受到人体姿态识别任务的启发, 将这些不同阶段的卷积特征图谱通过反卷积模块连接起来, 然后再进行目标检测的预测任务. - 预测模块采用Residual模块
这个不算是亮点, 不过也是改动之一, 基本来说就说原始的SSD是直接在特征图谱预测结果并计算损失的, 而DSSD在预测之前会先经过一个Residual模块做进一步的特征提取, 然后在进行预测.
YOLOv3 2018
- YOLOv3 加入了更多被验证过的有效技术, 使得 YOLO 模型的 mAP 可以与 SSD 系列相媲美, 同时速度依然很快(约为 SSD 的三倍).
改进
- Bounding Box Prediction: YOLOv3 使用了和 YOLOv2 相同的 bbox 回归策略, 都是预测相对于 cell 左上角的偏移量进行回归. YOLO 中每个 gt box 只会与负责它的 cell 中的一个 anchor box 匹配(IoU 最大), 其他的 anchor box 只会计算 objectness 置信度损失, 而不会计算坐标和分类损失.
- 类别预测: 由于有的物体可能不止属于一个标签, 如 “人” 和 “女人”. 因此, 为了减少类别之间的对抗性, YOLOv3 没有使用 softmax 计算分类损失, 而是采用了 二值交叉熵来预测类别(非对称概率分布差异).
- 特征金字塔: 使用类似于 FPN 的方法(upsample and top-down)提取到不同尺度的特征图谱(文中
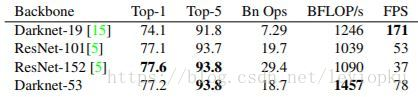
3个), 在每个尺度的特征图谱上的都会预测3boxes, 因此, 每个尺度的特征图谱的输出为: N × N × [ 3 × ( 4 + 1 + 80 ) ] N×N×[3×(4+1+80)] N×N×[3×(4+1+80)]. 在确定 anchor 大小时, 利用 kmean 聚类选出9个聚类中心, 然后划分成3个簇分别赋给3个尺度的特征图谱. - Darknet-53: 使用了残差模块的思想, 提出了层数为 53 的 Darknet-53 网络 (1, 2, 8, 8, 4). 在 ImageNet 上, Darknet-53 is better than ResNet-101 and 1.5x faster. Darknet-53 has similar performance to ResNet-152 and is 2x faster.

- Focal Loss 对 YOLOv3 不起作用的原因可能是 YOLO 的选框策略和损失函数(objectness+class)使得 YOLO 在背景样本不均衡问题上影响较小.
数据增强
| 翻转变换 | flip |
|---|---|
| 随机修剪 | random crop |
| 色彩抖动 | color jittering |
| 平移变换 | shift |
| 尺度变换 | scale |
| 对比度变换 | contrast |
| 噪声扰动 | noise |
| 旋转变换/反射变换 | Rotation/reflection |
- 这里需要注意的是,虽然输入尺寸是416x416,但原图是按照纵横比例缩放至416x416的, 取
m
i
n
(
w
/
i
m
g
w
,
h
/
i
m
g
h
)
min(w/img_w, h/img_h)
min(w/imgw,h/imgh)这个比例来缩放,保证长的边缩放为需要的输入尺寸416,而短边按比例缩放不会扭曲,
i
m
g
w
,
i
m
g
h
img_w,img_h
imgw,imgh是原图尺寸768,576, 缩放后的尺寸为
n
e
w
w
,
n
e
w
h
=
416
,
312
new_w, new_h=416,312
neww,newh=416,312,需要的输入尺寸是w,h=416*416(128值填充):

- yolov3需要的训练数据的label是根据原图尺寸归一化了的,这样做是因为怕大的边框的影响比小的边框影响大,因此做了归一化的操作,这样大的和小的边框都会被同等看待了,而且训练也容易收敛。
网络结构
- YOLOv3

- resn:n代表数字,表示这个res_block里含有多少个res_unit
- 整个yolo_v3_body包含252层:
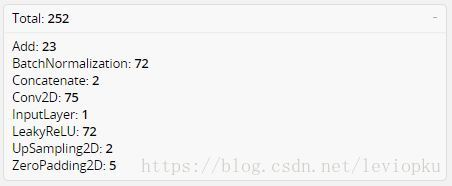
- 整个v3结构里面,是没有池化层和全连接层的。前向传播过程中,张量的尺寸变换是通过改变卷积核的步长来实现的,比如stride=(2, 2),这就等于将图像边长缩小了一半(即面积缩小到原来的1/4)
- 在yolo_v2中,要经历5次缩小,会将特征图缩小到原输入尺寸的1/32。输入为416x416,则输出为13x13(416/32=13)
- yolo_v3也和v2一样,backbone都会将输出特征图缩小到输入的1/32
- 通常都要求输入图片是32的倍数
- 步长2的卷积 + 零填充

- tiny-yolo3

- YOLOv3和tiny-YOLOv3的战绩

网络输出

- 借鉴了FPN的思想
- yolo v3设定的是每个网格单元预测3个box,所以每个box需要有(x, y, w, h, confidence)五个基本参数,然后还要有80个类别的概率,即3*(5 + 80) = 255(YOLOv1:7x7x30,2*(5+20) = 50)
- 作者并没有像SSD那样直接采用backbone中间层的处理结果作为feature map的输出,而是和后面网络层的上采样结果进行一个拼接之后的处理结果作为feature map
边框回归
- YOLOv3使用逻辑回归预测每个边界框的客观得分
- logistic回归用于对anchor包围的部分进行一个目标性评分(objectness score),即这块位置是目标的可能性有多大。这一步是在predict之前进行的,可以去掉不必要anchor
- 忽视IoU小的Anchor:If the bounding box prior is not the best but does overlap a ground truth object by more than some threshold we ignore the prediction, following[17]. We use the threshold of 0.5. Unlike [17] our system only assigns one bounding box prior for each ground truth object.
- 不同于faster R-CNN的是,yolo_v3只会对1个prior进行操作,也就是那个最佳prior。而logistic回归就是用来从9个anchor priors中找到objectness score(目标存在可能性得分)最高的那一个。logistic回归就是用曲线对prior相对于 objectness score映射关系的线性建模
- 第一点, 9个anchor会被三个输出张量平分的。根据大中小三种size各自取自己的anchor。
- 第二点,每个输出y在每个自己的网格都会输出3个预测框,这3个框是9除以3得到的,这是作者设置的,我们可以从输出张量的维度来看,13x13x255。255是怎么来的呢,3*(5+80)。80表示80个种类,5表示位置信息和置信度,3表示要输出3个prediction。在代码上来看,3*(5+80)中的3是直接由num_anchors//3得到的
- 第三点,作者使用了logistic回归来对每个anchor包围的内容进行了一个目标性评分(objectness score)。根据目标性评分来选择anchor prior进行predict,而不是所有anchor prior都会有输出!
网络训练
train_bottleneck.py
- model, bottleneck_model, last_layer_model
- model:将网络的输出(3个y)和真值,以及输出数据连起来!一边得到最后的loss层
- last_layer_model:

- model和last_layer_model是接了loss层的模型!
- bottleneck_model没有包括yolo_body中的输出前面的卷积层!
bottleneck_model = Model([model_body.input, *y_true], [out1, out2, out3])
- last_layer_model是相对于yolo_body的bottleneck_model的差集!
model_loss_last =Lambda(yolo_loss,
output_shape=(1,), name='yolo_loss', arguments={
'anchors': anchors,
'num_classes': num_classes,
'ignore_thresh': 0.5})([*model_last.output, *y_true])
last_layer_model = Model([in0,in1,in2, *y_true], model_loss_last)
- model是包括了损失函数的yolo_body
model_loss = Lambda(yolo_loss, output_shape=(1,), name='yolo_loss',
arguments={'anchors': anchors, 'num_classes': num_classes, 'ignore_thresh': 0.5})(
[*model_body.output, *y_true])
model = Model([model_body.input, *y_true], model_loss)
- 而train.py里面,create_model()只有model,没有将model拆成bottleneck_mdel和last_layer_model!
yolo_loss.py
训练流程
RefineDet 2018
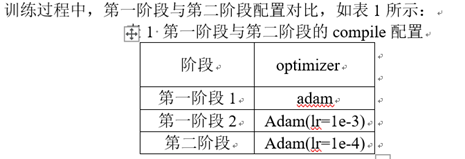
- 提出将Two-Stage模型中的思想集成到 One-Stage 框架中, 以此来综合 One-Stage 和 Two-Stage 各自的优势.
- 将 SSD 的 forward 流程分成了两大部分, 分别是 ARM(Anchor Refinement Module) 和 ODM(Object Detection Module)
- ARM 的作用有两点: (1), 移除 negative anchors 解决正负样本不均衡问题 (2), 粗略的调整 anchors 的 locations 和 sizes, 为后续的回归器提供更好地初始 anchors
- ODM 的作用是: 将 ARM refine 后的 anchor 作为输入, 进一步的提升 bbox reg 和 multi-class pred 的精度.
- 设计思想分别来自于 Two-Stage 网络的 RPN 网络和 Detection 网络.

- RefineDet 的网络框架设计和 SSD 类似, 首先在常规的 SSD 金字塔特征图谱上(即: conv4_3, conv5_3, conv_fc7, conv6_2) 产生预定义的固定数量的 default boxes, 然后每一个特征图都会共享两个子网络分支, 分别为 anchor 的回归网络和正负样本的二分类预测网络.
- 这一步产生的负样本置信度高于 0.99 的 anchor 不会传入 ODM 阶段, 起到了预先去除 easy negative examples 的作用.
- 再利用一个 Transfer Connection Block 结构将 down-top 的特征图谱和 top-down 的特征图谱结合, 并利用 ARM 产生的 anchor 作为输入, 传入 ODM 中进行第二次的 bbox regression 和物体类别的多分类预测.
Transfer Connection Block

- ARM 的特征图谱经过两个卷积层, top-down 的特征图谱由反卷积层得到, 二者进行 Elementwisz sum 后, 输出的图谱再经过一层卷积, 最终产生在 ODM 中进行预测的特征图谱
RefineDet 使用two-stage 的边框回归过程, 为什么还说它是 one-stage 模型?
- RefineDet 是 One-Stage 和 Two-Stage 的结合
虽然有了 anchor refine 的步骤, 但是不想 Faster R-CNN 那样, proposals 的生成和最终 bbox 的预测有很明显的分割, 因此, 勉强算 One-Stage.
YOLOv4 2020
TODO !!!


4 Scale Problem
OverFeat 2014
- Multi-Scale Classification::
- 在分类任务上, 虽然训练时采用和AlexNet相同的multi crop方法, 但是在预测阶段没有使用AlexNet的crop投票策略, 而是提出了Multi-Scale Classification方法, 一句话概括就是 对整个图片以不同的尺寸, 并且对每一个location进行模型预测
- 利用了全卷积的思想代替全连接:降低了滑动窗口的计算代价, 同时支持任意尺寸的图片输入
- 可以用同一个模型完成分类, 定位, 检测任务:
- 同一个模型, 只需要用回归层替换分类层, 即可完成目标定位任务, 同时利用了贪心策略来融合最终的定位结果
SPPNet 2015
空间金字塔池化
- spatial pyramid pooling layer
- 可以接受任意尺寸的输入图片,并生成固定长度的表征向量
- 可以进行多尺度的联合训练, 提升模型精度
- 这种池化方法是比较general的, 可以提升不同模型架构的性能(分类任务)

- 网络划分粒度 1x1 2x2 4x4 三种;共21 spatial bins
- 将SPP用于目标检测, 并且提出了先求卷积特征图谱, 然后在特征图谱上取区域的的策略: 大大提升了模型训练和预测的速度(在预测阶段, 比RCNN快24~102倍, 同时取得了更好的精度).
- 相比于RCNN, SPPNet使用了EdgeBoxes( 0.2s/img )的方法来进行候选区域推荐, 而不是Selective Search( 1∼2s/img )
SPPNet缺点
训练过程是分阶段的(Training is a multi-stage pipeline)无法 Fine-Tuning 金字塔池化层之前的卷积层- 严格说,SPP-Net也可以反向传播,但是会复杂很多,所以用connot update the convolutional layers其实是不算太准确的说法。Ross大神在Fast R-CNN中给出的解释是:SPP训练样本来自不同图像导致反向传播效率低下。知乎回答
- SPP-Net中fine-tuning的样本是来自所有图像的所有RoI打散后均匀采样的,即RoI-centric sampling,这就导致SGD的每个batch的样本来自不同的图像,需要同时计算和存储这些图像的Feature Map,过程变得expensive.
- Fast R-CNN采用分层采样思想,先采样出N张图像(image-centric sampling),在这N张图像中再采样出R个RoI,具体到实际中,N=2,R=128,同一图像的RoI共享计算和内存,也就是只用计算和存储2张图像,消耗就大大减少了。
FPN 2017
- feature pyramid networks
介绍
- 将最后一层特征图谱进行不断尽快上采样, 并与每一个金字塔阶级的特征图谱进行加法合并操作, 得到新的表征能力更强的不同金字塔层次的特征图谱, 然后将RoI按照尺寸分别映射到这些特征图谱上, 再在每个特征图谱上进行类别和位置预测.
- 四种获取图像多维度特征组合的方法:

- (a) 使用图像金字塔建造特征金字塔,计算不同尺度的特征图过程相互独立 (b) 使用单尺度特征进程检测 © 使用卷积层对多尺度特征层处理 (d) FPN网络结构

- element-wise add后使用一个 3x3 的卷积对每一个融合后的图谱进行操作以生成最终的金字塔图谱, 这是为了消除上采样的混叠效应(aliasing effect of unsampling??),
- 浅层特征负责感知和检测小物体, 但是欠缺足够深度的高级语义信息, 因此将具备深层语义信息的特征层通过反卷积的方式扩大 feature map 的 size, 然后结合浅层和深层的特征图谱来进行预测.

FPN的使用
- FPN for RPN:
对于特征图谱 P 2 , P 3 , P 4 , P 5 , P 6 {P2,P3,P4,P5,P6} P2,P3,P4,P5,P6, 为其分别分配不同大小的 anchors 3 2 2 , 6 4 2 , 12 8 2 , 25 6 2 , 51 2 2 32^2,64^2,128^2,256^2,512^2 322,642,1282,2562,5122, 然后利用一个 共享的 rpn heads 进行训练和预测。原文是共享的

- FPN for Fast R-CNN:
① 将FPN用于FastRCNN时, 我们需要在不同的金字塔层次上赋予不同尺度的 RoI大小 (因为 RoI pooling 是根据特征图谱和原图的尺寸关系决定的), ② 较小的 RoI, 会被分配到较浅的网络层, 因为太深的图谱可能已经不包含小物体信息了. 注意, detect heads 在所有层级上的权重都是共享的
PANet 2018
- Path Aggregation Network for Instance Segmentation
- coco2017 实例分割的冠军


- P2直接copy到N2,然后N2通过步长为2的3*3卷积后分辨率缩小2倍,和P3尺寸一致,然后element-wise 相加。注: 所有channel和FPN中一致P2-P5, N2-N5都是256。
Adaptive Feature Pooling
- 在FPN那篇论文的解读中我们也讲过FPN从P2-P6(P6仅用作生成proposal,不用作RoIPooling时提取特征)多尺度地生成proposal,然后做RoIPooling时会根据proposal的大小将它分配到不同的level去crop特征,小的proposal去low-level的层,大的proposal去high-level的层。
- 尽管P2-P5(N2-N5)已经融合了low-level和high-level的特征,然后它们的主要特征还是以它本有的level为主 这时如果小的proposal能从high-level层获取到更多的上下文语义信息是有利于它分类的,而大的proposal能从low-leve层获取到更好的细节是有利于它定位的。
- 因此本文打算每个proposal从所有level的特征上做RoIPooling,然后在后面融合,融合的阶段和方式都可实验,比如分类时是两个fc,这个融合阶段可以是fuse, fc1, fc2或者fc1, fuse, fc2,融合策略可是sum也可以是max,最后证明fc1, fuse, fc2和max最好。当然这个改进是增加了一些运算负担。
- 因为我们后续融合时不是要做max融合嘛,这样我们可以看看到底是哪个level被选中了,这样计算一些比例。从下图可以到蓝色代表小的proposal,以此类推黄色是最大的proposal,我们以小的proposal为例,发现,只有30%确实是在最低的level被选中了,但是70%的feature值选中了更高的level。而最大的proposal,有超过50%的feature值选中了低的level(这也说明了给最高层加低层特征的必要性,即Bottom-up Path Augmentation的必要性)。

Fully-connected Fusion
- Mask RCNN中Mask分支就是个简版的fcn,fcn是全卷积网络,它根据一个局部的视野域来预测,且参数是全图共享,而全连接fc是全图视野域对位置更敏感,看得更大,这一点sunjian老师的large kernel也间接证明了大视野域的作用。因此本文打算多加一条用全连接层预测的支路来做mask预测,然后和fcn融合,具体做法如下图所示,至于conv4_fc接在fcn支路哪一个卷积后后面消融实验有做对比,conv3后面结果更好一点。
M2Det 2018
动机
- M2Det 从特征金字塔的构建角度出发, 认为现有的 sota 的特征金字塔的构建方式存在两个缺点:
- ① 直接简单利用了 backbone 网络固有的金字塔式的特征图谱来构建, 但这些 backbone 实际上是针对分类任务设计的, 因此不足以表示针对目标检测任务的特征;
- ② 构建的金字塔中每一个尺度的特征仅仅来自于 backbone 中单一层级(level)的特征. 这样一来, 小尺度的特征图谱往往缺少浅层低级的语义信息, 而大尺度的特征图谱又缺少深层的高级语义信息
- 因此, 作者就提出了融合多个层级特征的 MLFPN (multi-level FPN). MLFPN 主要由三个模块组成:1
特征融合模块(Feature Fusion Module, FFM), 2简化的 U-shape 模块(Thinned U-shape Module, TUM), 以及3尺度特征聚合模块(Scale-wise Feature Aggregation Module, SFAM)
结构
- ① FFMv1 融合了 backbone 网络中浅层和深层的特征来生成 base feature, 具体来说就是 VGGNet 的 conv4_3 和 conv5_3. ② 若干个 TUMs 和 FFMv2 交替连接. 具体的说, 每一个 TUM 都会生成多个不同尺度的 feature maps.
- ③ FFMv2 融合了 base feature 和前一个 TUM 输出个最大的 feature map. 融合后的 feature maps 会被送到下一个 TUM 中.
- ④ SFAM 会通过按照尺度划分的特征连接操作(scale-wise feature concatenation operation) 和 通道注意力机制(channel-wise attention mechanism)来聚集
multi-level multi-scale features, 形成最终的特征金字塔结构. 最后用两个卷积层在特征金字塔上分别进行回归和分类预测. 可以看出, 整体的流程和 SSD 类似, 不同之处就在于特征金字塔的构建方式.



RFBNet 2018
- RFBNet 从感受野的角度出发, 提出了利用空洞卷积(Dilated Conv)来构建 RFB(Receptive Field Block), 其核心思想是利用具有不同空洞间距的 Dilated Conv 来集成不同范围的感受野, 以便可以在同一个特征图谱上获得更大尺度范围内的信息
- 其实,RFBNet就是将Inception和ASPP进行了融合,达到更好的效果。如下图所示,使用空洞卷积来控制离心率,得到不同的感受野大小。
RFB
- RFB-Net在inception的基础上加入了dilated卷积层,增大了感受野,增强网络特征提取能力。
- 两个组件:具有不同卷积核的多分支卷积层以及随后的膨胀卷积层。微调RFB参数主要就是调节RFB模块中卷积核kernel size以及膨胀因子rate(内核元素间的距离)。


- RFB 与其他具有多尺度感受野的工作之间的区别

- RFB Net Detection Architecture

TridentNet 2019
- RFBNet 虽然考虑了 Dilated Conv, 但是它的 RFB 结构较为复杂, 带来的计算量也很高. 为此, TridentNet 从不同的角度来使用 Dilated Conv
- TridentNet 从不同的角度来使用 Dilated Conv, 对于目标检测问题来说, 不同的特征图谱感受野对于不同的物体尺寸, 其检测效果是不同的, 简单来说, 更大的 receptive field 对于大物体的性能会更好, 更小的 receptive filed 对于小物体的性能会更好. 因此, TridentNet 提出了 Trident Block 结构
- 不同尺度物体的检测性能和dilation rate正相关!
- Scale Variations比较

创新点
- 构造了多路并行的 Trident 分支, 每个 Trident Block 分支具有不同的感受野大小, 用于检测不同尺度的物体
- 在每一个 Trident Block 当中, 它们的参数是共享的, 区别仅在于去感受野的大小不同;
- 对于每一个 branch, 训练和测试都只负责一定尺度范围内的样本(借鉴 SNIP), 这样避免了极端 scale 对检测性能的影响.
- PS:实际上, 在测试阶段,我们可以只保留一个branch来近似完整TridentNet的结果,后面我们做了充分的对比实验来寻找了这样single branch approximation的最佳setting,一般而言,这样的近似只会降低0.5到1点map,但是和baseline比起来不会引入任何额外的计算和参数。
Trident Block
- 构造了多路并行的 Trident 分支, 每个 Trident Block 分支具有不同的感受野大小, 用于检测不同尺度的物体
- 在每一个 Trident Block 当中, 它们的参数是共享的, 区别仅在于去感受野的大小不同;
- 对于每一个 branch, 训练和测试都只负责一定尺度范围内的样本(借鉴 SNIP), 这样避免了极端 scale 对检测性能的影响.
网络结构


5 形变卷积
Deformable ConvNets V1 2017
- DCN v1
- Deformable convolution:对于可形变卷积来说, 通过在每个卷积核的采样点上加一个
偏移量来达到更好的采样效果 - Deformable ROI:对于可形变 RoI pooling 来说, 通过对传统的 RoI bins 添加一个
偏移量还使得 RoI pooling 中的窗口具有能够适应几何形变的效果 - Deformable ConvNet 一个比较好的性质就是它不会对原有检测模型的整体结构进行更改, 也不会增加过多的计算量, 因此可以相对容易的添加到现有的检测模型当中, 同时还可以和其他多种提升精度的 trick 叠加使用.
Deformable Convolution

- 在原始特征图谱平面的每一个location上都生成一组与卷积核采样点个数相关的偏移量,这个偏移量就是在算卷积的适合,按照当前位置进行偏移后再得到加权和
- 对于一个形状为 W × H × C W×H×C W×H×C 的特征图谱, 我们将其作为输入, 添加一个新的卷积层, 这个卷积层的输出形状为 W × H × 2 N W×H×2N W×H×2N, N = W k × H k N=W^k×H^k N=Wk×Hk 代表卷积核平面上的采样点个数, N = ∣ R ∣ , R = { ( − 1 , − 1 ) , ( − 1 , 0 ) , … , ( 0 , 1 ) , ( 1 , 1 ) } N = \vert R \vert, R = \{ (-1, -1), (-1, 0), …, (0, 1), (1, 1)\} N=∣R∣,R={(−1,−1),(−1,0),…,(0,1),(1,1)}
- 在计算某一个的输出值时, 会根据 offset filed 的偏移量来决定新的采样点 position
- 利用双线性插值重新计算每个 position 的值(因为加了偏移量后的新 position 是浮点的, 所以利用双线性插值根据四角的值来算这个 position 的值)
- 得到所有 position 的值后, 就利用卷积计算得到该点的结果.
- 对所有的卷积计算都执行类似的过程, 直到结算结束.
Deformable RoI Pooling

- 先利用普通的 RoI Pooling 得到池化后 k × k k×k k×k 大小的特征图谱
- 利用一个 FC 层生成归一化的 offsets
- 将 offsets 应用到对应的 bins 中得到新的像素值.
Deformable Ps RoI Pooling

Deformable ConvNets V2 2018
- DCN v2
动机
- DCNv1 虽然可以适应不同几何形变的物体形状, 但是它存在的问题就是学习到的 offsets 不可控, 进而导致引入了过多的 context, 而这些 context 对于网络来说属于干扰信息, 是有害的
改进
- 增加了更多的 Deformable Convolution
DCNv1 中只有 ResNet C5 中有 Deformable Conv(共 3 个), 而在 DCNv2 中把 C3~C5 的 3x3 conv 都换成了 Deformable Conv(共 12 个) - 让 Deformable Conv 不仅能够学习 offsets, 还能够学习每个采样点的权重, 就是文中的 modulation 机制
在 DCNv1 中, Deformable Conv 只学习 offset;而在 DCNv2 中, 还加入了对每个采样点的权重 Δ m k Δm_k Δmk,即Modulation机制!对采样点值的选取起到了更灵活的规范作用, 对于一些不想要的采样点,学习到权值为0就行!
y ( p ) = ∑ k = 1 K w k ⋅ x ( p + p k + Δ p k ) y ( p ) = ∑ k = 1 K w k ⋅ x ( p + p k + Δ p k ) ⋅ Δ m k y(p)=\sum_{k=1}^{K} w_{k} \cdot x\left(p+p_{k}+\Delta p_{k}\right) \\ y(p)=\sum_{k=1}^{K} w_{k} \cdot x\left(p+p_{k}+\Delta p_{k}\right) \cdot \Delta m_{k} y(p)=k=1∑Kwk⋅x(p+pk+Δpk)y(p)=k=1∑Kwk⋅x(p+pk+Δpk)⋅Δmk - 利用知识蒸馏(feature mimicking) 让 DCNv2 来模拟 R-CNN 的 feature. 有论文指出将 R-CNN 和 Faster R-CNN 的 Classification score 结合起来可以提升 performance, 说明 R-CNN 学到的 focus 在物体上的 feature 可以解决 redundant context 的问题. 但是增加的额外计算会使得 inference 速度慢很多, 因此 DCNv2 的解决方法就是让 R-CNN 当做 teacher network, 让 DCNv2 的 RoI Pooling 之后的 feature 去模拟 R-CNN 的feature.

细节 链接
6 样本困难和不平衡
OHEM 2016
- Online Hard Example Mining
- 作者根据每个 RoI 的 loss 的大小来决定哪些是难样例, 哪些是简单样例, 通过这种方法, 可以更高效的训练网络, 并且可以使得网络收敛到更好的解. 同时, OHEM 还具有以下两个优点:
-
- 消除Fast R-CNN系列模型中的一些不必要这参数.这些参数大多都是为了解决难样例问题服务的, 在使用 OHEM 以后, 不仅无需在对这些超参数进行调优, 同时还能获得更好的性能表现.
-
- OHEM算法可以与其他多种提升模型精度的trick相结合, 对于大多数模型(R-CNN系列), 在使用了OHEM以后, 都能够获得精度上的提高, 可以看做是一种普适性的提升精度的方法.
- 文章提出两个可以对难分类样本的方法:
- ① 明显的方法:直接修改损失层,然后直接进行hard example selection;损失层计算所有的RoIs,然后按损失从大到小排序,当然这里有个NMS(非最大值抑制) 操作,选择hard RoIs并non-hard RoIs的损失置0,会导致效率低下,为每个ROI分配内存并反传,即使某些ROI权值为0
- ② 更好的方法就采用下图的方法,给出两个RoI模块,一个是只读模块,Forward传播获取所有ROI的损失,进行Hard ROI Sample,再传到可读写的下面红色RoI模块中,正反传更新网络!这个方式和第一种方式在内存空间是差不多的,但第二种方式的速度快 了两倍
- 提出两个ROI模块,减少无效运算

RetinaNet 2017
Focal Loss
- one stage 方法由于没有对候选框的预先过滤策略, 因此后产生大量的 easy negative examples(易分类的背景区域), 这些 easy negative examples 由于数量众多, 最终会对loss有很大的贡献, 从而导致优化的时候过度关注这些 easy examples, 这样会收敛到一个不够好的结果.

- Focal Loss 正是为了解决这个问题而提出的, 它的核心思想非常直接, 就是在优化的过程中抑制这些 easy (negative) examples 对最终 Loss 的贡献程度. 所谓 easy example 指的就是那些预测概率与真实概率十分相近的样本. 这些样本已经被网络很容易的正确分类了, 所以应该适当减少他们的loss以降低他们对参数更新的影响程度. 以下面的公式为例, 当真实标签为1时, 如果预测概率(假设二分类)
p
p
p 接近于1, 则此样本是easy样本, 因此, 前面的
(
1
−
p
)
γ
(1−p)^γ
(1−p)γ , 就会非常小, 起到了抑制易分类样本的作用.

F L ( p ) = { − ( 1 − p ) γ log ( p ) 当 y = 1 − p γ log ( 1 − p ) 当 y = 0 F L(p)=\left\{\begin{array}{ll}-(1-p)^{\gamma} \log (p) & \text { 当 } y=1 \\ -p^{\gamma} \log (1-p) & \text { 当 } y=0\end{array}\right. FL(p)={−(1−p)γlog(p)−pγlog(1−p) 当 y=1 当 y=0 - γ γ γ 的值越大, 则 easy example 对于loss的贡献程度越小, 当 γ = 0 γ=0 γ=0 时, 会退化成普通的交叉熵函数.
- 实际中在使用 γ γ γ 参数的情况下, 还会用了另一个参数 α α α , 该参数的主要作用是调节正负样本的权重, α α α 的取值通常会根据正负样本的实际比例决定, 如下所示:
F L ( p ) = { − α ( 1 − p ) γ log ( p ) 当 y = 1 − ( 1 − α ) p γ log ( 1 − p ) 当 y = 0 F L(p)=\left\{\begin{array}{ll}-\alpha(1-p)^{\gamma} \log (p) & \text { 当 } y=1 \\ -(1-\alpha) p^{\gamma} \log (1-p) & \text { 当 } y=0\end{array}\right. FL(p)={−α(1−p)γlog(p)−(1−α)pγlog(1−p) 当 y=1 当 y=0
- 下图可以看出, 对于易分类样本来说, 绝大部分都是负样本, 因为 FocalLoss 对于正样本的抑制效果并不明显, 而对负样本的抑制效果会随着 γ γ γ 参数的升高而迅速增大
Focal Loss中的参数作用
- γ γ γ 决定了对 easy example 的抑制力度, 当 γ γ γ 的值越大时, 则 easy example 对于 loss 的贡献程度就越小, 而 γ γ γ的值为 0 时, 相对于不施加抑制, Focal Loss 推退化成普通的交叉熵函数
- α α α 的作用是解决正负样本不平衡问题, α α α的取值通常会根据正负样本的实例比例决定. 对于样本数量较多的类别, 其对应的权重应该较小. 但是当 α α α 参数和 γ γ γ 参数共同使用时, 则需要综合考虑样本的数量和 γ γ γ 的取值
- 二者关系: ① 当
γ
γ
γ 取值较小时, FocalLoss 对易分类样本的抑制力度不强, 此时由于存在大量的易分类负样本, 因此
α
α
α 应当对正样本施加更多的权重(
γ
γ
γ=0 时,
α
α
α 最优值为 0.75). ② 当
γ
γ
γ取值较大时 Focal Loss 对易分类负样本抑制力度变强, 使得原本在数量上不在优势的前景区域或许在对 loss 的贡献度上反超了背景区域, 因此, 需要对前景区域赋予更低的权重
γ
γ
γ=2 时,
α
α
α 最优值为 0.25 (最优组合).

R-CNN 系列为什么不用 Focal Loss 进行优化
- 因为 Focal Loss 主要解决的问题是正负样本框的极度不均衡问题.
- 而 Two-Stage 网络, 通常会利用 RPN 和启发式的采样算法来过滤掉大量的负样本, 因而不存在正负样本不均衡的问题:
-
- RPN 会将物体候选框的数量降低很多, 移除了大量的易分类负样本(背景框) γ γ γ
-
- 采用了 biased-minibatch 的采样策略, 比如, 保证正样本和负样本的比例为 1:3 进行训练 α α α
损失函数
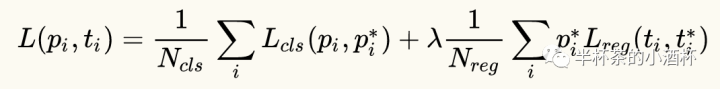
-
p
i
:
p_{i}:
pi: Anchor[i]的预测分类概率
Anchor[i]是正样本时, p i ∗ = 1 p_{i}^{*}=1 \quad pi∗=1; Anchor[i]是负样本时, p i ∗ = 0 \quad p_{i}^{*}=0 pi∗=0
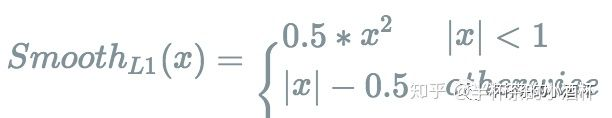

网络结构
- RetinaNet 由一个backbone网络和两个子网络组成。backbone网络是现成的,主要负责计算卷积特征图谱。① 第一个子网络负责物体分类任务,② 第二个子网络负责bounding box回归任务,它们都是在backbone网络输出的卷积图谱上进行计算的

- Backbone: RetinaNet 选用 FPN 作为 backbone 网络, 对P3到P7使用了不同大小的anchors.
- 分类子网: 由一个简单的 FCN 组合, 分类子网的参数在所有的金字塔层级都是共享的,对于规定的金字塔层级, 其输出的特征图谱的通道数为 C C C, 则分类子网由 4 个 3 x 3 3x3 3x3 的卷积层构成, 每个卷积层的输入输出通道数都是 C C C, 尺寸大小维持不变, 并且均使用 R e L U ReLU ReLU 作为激活函数, 最后接上一层输出通道数为 K A KA KA 的 3 x 3 3x3 3x3 卷积, 并利用 Sigmoid 激活函数在每个 location 上输出 K A KA KA 的二值预测概率. 通常情况下 C = 256 , A = 9 C=256,A=9 C=256,A=9
- 回归子网: 整体结构与分类子网相同, 唯一区别在于最后一层卷积层的输出通道数变成了
4
A
4A
4A, 因为它要在每一个 location 上为每一个 anchor 预测
4
4
4 个坐标偏移量. 回归子网的参数在金字塔层级上也是共享的. 注意, 从回归子网的通道数就可以看出, RetinaNet 的 bbox 预测是类别不可知(class-agnostic)的

GHM 2019
- Gradient Harmonized Single-stage Detector
- 易分样本(即,置信度高的样本)对模型的提升效果非常小,模型应该主要关注与那些难分样本(这个假设是有问题的,是GHM的主要改进对象)
- 但是当难分样本点是离群点的时候,就会起反作用!!!
- 并且 α 和 γ \alpha和\gamma α和γ需要手工联合确定
- 采用gradient harmonizing mechanism改进难易样本的不均匀,提出Focal loss容易受到离群点的影响(难分但是离群),过度的关注于难分离群点会导致模型的泛化能力下降!

- Focal Loss是从置信度p的角度入手衰减loss,而GHM是一定范围置信度p的样本数量的角度衰减loss
- 梯度模长
g
g
g:
g = torch.abs(pred.sigmoid().detach() - target)
g = ∣ p − p ∗ ∣ = { 1 − p , if p ∗ = 1 p , if p ∗ = 0 g=\left|p-p^{*}\right|=\left\{\begin{aligned} 1-p, & \text { if } & p^{*}=1 \\ p, & \text { if } & p^{*}=0 \end{aligned}\right. g=∣p−p∗∣={1−p,p, if if p∗=1p∗=0 - p是模型预测的概率, p ∗ p^* p∗是 ground-truth的标签, p ∗ p^* p∗的取值为0或1.
- 为啥叫梯度模长:
L C E = { − log ( p ) , if p ∗ = 1 − log ( 1 − p ) , if p ∗ = 0 p = sigmoid ( x ) ∂ p ∂ x = p ( 1 − p ) ∂ L C E ∂ x = ∂ L C E ∂ p ∂ p ∂ x = { p − 1 , if p ∗ = 1 p , if p ∗ = 0 = p − p ∗ g = ∣ ∂ L C E ∂ x ∣ L_{C E}=\left\{\begin{aligned} -\log (p), & \text { if } \quad p^{*}=1 \\ -\log (1-p), & \text { if } \quad p^{*}=0 \end{aligned}\right. \\ p=\operatorname{sigmoid}(x) \\ \frac{\partial p}{\partial x}=p(1-p) \\ \frac{\partial L_{C E}}{\partial x}=\frac{\partial L_{C E}}{\partial p} \frac{\partial p}{\partial x} =\left\{\begin{array}{rll} p-1, & \text { if } \quad p^{*}=1 \\ p, & \text { if } \quad p^{*}=0 \end{array}=p-p^{*}\right.\\ g=\left|\frac{\partial L_{C E}}{\partial x}\right| LCE={−log(p),−log(1−p), if p∗=1 if p∗=0p=sigmoid(x)∂x∂p=p(1−p)∂x∂LCE=∂p∂LCE∂x∂p={p−1,p, if p∗=1 if p∗=0=p−p∗g=∣∣∣∣∂x∂LCE∣∣∣∣ - 如下图,难分类样本的梯度模长 大且样本数量也不少,所以像FL那样过度关注于这些样本降低了模型的精度!

- GHM思想:易分样本和特别难分的样本都不应该过多的关注
梯度密度公式
- 按照上述思路,需要同时衰减易分类和极难分类的样本,采用谁的数量多就衰减谁的思路进行!
- 通过定义 样本在单位梯度范围内的数量,表示数量多少的概念!
- 即梯度密度:单位梯度模长g部分的样本个数 (差分函数)
G D ( g ) = 1 l ε ( g ) ∑ k = 1 N δ ε ( g k , g ) δ ϵ ( x , y ) = { 1 if y − ϵ 2 < = x < y + ϵ 2 0 otherwise l ϵ ( g ) = min ( g + ϵ 2 , 1 ) − max ( g − ϵ 2 , 0 ) \begin{array}{l} G D(g)=\frac{1}{l_{\varepsilon}(g)} \sum_{k=1}^{N} \delta_{\varepsilon}\left(g_{k}, g\right) \\ \delta_{\epsilon}(x, y)=\left\{\begin{array}{ll} 1 & \text { if } y-\frac{\epsilon}{2}<=x<y+\frac{\epsilon}{2} \\ 0 & \text { otherwise } \end{array}\right. \\ l_{\epsilon}(g)=\min \left(g+\frac{\epsilon}{2}, 1\right)-\max \left(g-\frac{\epsilon}{2}, 0\right) \end{array} GD(g)=lε(g)1∑k=1Nδε(gk,g)δϵ(x,y)={10 if y−2ϵ<=x<y+2ϵ otherwise lϵ(g)=min(g+2ϵ,1)−max(g−2ϵ,0) - 其中: δ ε ( g k , g ) \delta_{\varepsilon}\left(g_{k}, g\right) δε(gk,g) 表明了样本1 ∼ N \sim \mathrm{N} ∼N 中, 梯度模长分布在 ( g − ε 2 , g + ε 2 ) \left(g-\frac{\varepsilon}{2}, g+\frac{\varepsilon}{2}\right) (g−2ε,g+2ε) 范围内的样本个数, l ϵ ( g ) l_{\epsilon}(g) lϵ(g) 代表了 ( g − ε 2 , g + ε 2 ) \left(g-\frac{\varepsilon}{2}, g+\frac{\varepsilon}{2}\right) (g−2ε,g+2ε) 区间的长度。
GHM-C 损失函数
- 将其的倒数作为交叉熵的加权!用于分类:
- 定义权重:
β i = N G D ( g i ) \beta_{i}=\frac{N}{G D\left(g_{i}\right)} βi=GD(gi)N - 得到改进的分类损失函数:
L G H M − C = 1 N ∑ i = 1 N β i L C E ( p i , p i ∗ ) = ∑ i = 1 N L C E ( p i , p i ∗ ) G D ( g i ) L_{G H M-C}=\frac{1}{N} \sum_{i=1}^{N} \beta_{i} L_{C E}\left(p_{i}, p_{i}^{*}\right)=\sum_{i=1}^{N} \frac{L_{C E}\left(p_{i}, p_{i}^{*}\right)}{G D\left(g_{i}\right)} LGHM−C=N1i=1∑NβiLCE(pi,pi∗)=i=1∑NGD(gi)LCE(pi,pi∗) - 代码:算10个区域
class GHMC(nn.Module):
def __init__(self, bins=10, ......):
self.bins = bins
edges = torch.arange(bins + 1).float() / bins
......
>>> edges = tensor([0.0000, 0.1000, 0.2000, 0.3000, 0.4000,
0.5000, 0.6000, 0.7000, 0.8000,0.9000, 1.0000])
# 计算梯度模长
g = torch.abs(pred.sigmoid().detach() - target)
# n 用来统计有效的区间数。
# 假如某个区间没有落入任何梯度模长,密度为0,需要额外考虑,不然取个倒数就无穷了。
n = 0 # n valid bins
# 通过循环计算落入10个bins的梯度模长数量
for i in range(self.bins):
inds = (g >= edges[i]) & (g < edges[i + 1]) & valid
num_in_bin = inds.sum().item()
if num_in_bin > 0:
# 重点,所谓的梯度密度就是1/num_in_bin
weights[inds] = num_labels / num_in_bin
n += 1
if n > 0:
weights = weights / n
# 把上面计算的weights填到binary_cross_entropy_with_logits里就行了
loss = torch.nn.functional.binary_cross_entropy_with_logits(
pred, target, weights, reduction='sum') / num_labels
- 抑制的效果

GHM-R 损失函数
- 认为Smooth L1回归函数在输出和真值差值大于阈值时梯度都变成了1,就无法根据梯度来估计一些example输出贡献度,作者就提出了一个函数:
A S L 1 ( d ) = d 2 + μ 2 − μ ; ∂ A S L 1 ∂ d = d d 2 + μ 2 A S L_{1}(d)=\sqrt{d^{2}+\mu^{2}}-\mu; \frac{\partial A S L_{1}}{\partial d}=\frac{d}{\sqrt{d^{2}+\mu^{2}}} ASL1(d)=d2+μ2−μ;∂d∂ASL1=d2+μ2d - 超参数
μ
=
0.02
\mu = 0.02
μ=0.02,定义Gradient Norm为
∣
d
d
2
+
μ
2
∣
|\frac{d}{\sqrt{d^{2}+\mu^{2}}}|
∣d2+μ2d∣,其和Gradient Norm样本分布如下:

- 和分类采用类似的权重定义方法:
L G H M − R = 1 N ∑ i = 1 N β i A S L 1 ( d i ) = ∑ i = 1 N A S L 1 ( d i ) G D ( g r i ) \begin{aligned} L_{G H M-R} &=\frac{1}{N} \sum_{i=1}^{N} \beta_{i} A S L_{1}\left(d_{i}\right) \\ &=\sum_{i=1}^{N} \frac{A S L_{1}\left(d_{i}\right)}{G D\left(g r_{i}\right)} \end{aligned} LGHM−R=N1i=1∑NβiASL1(di)=i=1∑NGD(gri)ASL1(di) - 这里GHM-R中并没有对easy example做抑制,作者认为,在目标框的回归阶段,easy examples同样能够对提升框回归的准确性带来帮助。
Generalized Focal Loss 2020
- Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection
- 知乎 - 作者的介绍

- 作者针对的是 One-stage,Head包含三个内容:① 分类 ② 检测 ③ 检测框的评分(
FCOS+ATSS用的是centerness,其他某些工作使用IoU,范围都是0~1之间)
问题
- classification score 和 IoU/centerness score不一致:
- ① 两个指标各自训练,测试的时候是乘在一起作为NMS score排序的依据,这肯定是存在gap的,不是end-to-end
- ② 两个指标作用不同对象:
- focal loss针对大量负样本+少量正样本,边框得分针对的是正样本;
- 那在NMS的时候,对于负样本的边框得分可能会分到一个未定义的值,使得NMS排序变为一个未定义行为;
- 出现一个坏情况就是:一个分类score相对低的真正的负样本,由于预测了一个不可信的极高的质量score,而导致它可能排到一个真正的正样本(分类score不够高且质量score相对低)的前面
- bbox回归采用的表示不够灵活!不能处理复杂情况:目前的边界回归都得建立一个狄拉克分布,这个不够符合复杂情况,比如被模糊的边界!

提出的方法
- 第一个分类得分和边框得分的Gap问题:联合
- 第二个边界分布的不鲁棒问题:替换,用softmax分布替换狄拉克方程
联合
- 将分类得分和边框联合,① 之前Focal Loss是为one-stage的检测器的分类分支服务的,支持0或者1这样的离散类别label。② 然而对于我们的分类-质量联合表示,label却变成了0~1之间的连续值
- 为此将Focal Loss修改为:Quality Focal Loss (QFL)
F L ( p ) = − ( 1 − p t ) γ log ( p t ) , p t = { p , when y = 1 1 − p , when y = 0 Q F L ( σ ) = − ∣ y − σ ∣ β ( ( 1 − y ) log ( 1 − σ ) + y log ( σ ) ) \mathbf{F L}(p)=-\left(1-p_{t}\right)^{\gamma} \log \left(p_{t}\right), p_{t}=\left\{\begin{aligned} p, & \text { when } y=1 \\ 1-p, & \text { when } y=0 \end{aligned}\right. \\ \mathbf{Q F L}(\sigma)=-|y-\sigma|^{\beta}((1-y) \log (1-\sigma)+y \log (\sigma)) FL(p)=−(1−pt)γlog(pt),pt={p,1−p, when y=1 when y=0QFL(σ)=−∣y−σ∣β((1−y)log(1−σ)+ylog(σ)) - 其中,y为0~1的质量标签,
σ
\sigma
σ为预测。
soft label是预测的框和对应gt的框计算iou得到的,是一种动态的label- 注意QFL的全局最小解即是 σ = y \sigma = y σ=y。
- 这样交叉熵部分变为完整的交叉熵,同时调节因子 ∣ y − σ ∣ β |y-\sigma|^{\beta} ∣y−σ∣β变为距离绝对值的幂次函数。
- 和Focal Loss类似,我们实验中发现一般取 β = 2 \beta = 2 β=2为最优。
替换
- 如果分布过于任意,网络学习的效率可能会不高,原因是一个积分目标可能对应了无穷多种分布模式

- 考虑到真实的分布通常不会距离标注的位置太远,所以我们又额外加了个loss,希望网络能够快速地聚焦到标注位置附近的数值,使得他们概率尽可能大。
- 涉及到如何从狄拉克分布的积分形式推导到一般分布的积分形式来表示框,详情:一般把边框回归模型的常用方法是把边框标签y(1,非边界区域0)看作Dirac分布 δ ( x − y ) \delta(x-y) δ(x−y),这个分布满足: ∫ − ∞ + ∞ δ ( x − y ) d x = 1 \int_{-\infty}^{+\infty} \delta(x-y) \mathrm{d} x=1 ∫−∞+∞δ(x−y)dx=1(通过FC层计算),一般这个标签y的积分形式为: y = ∫ − ∞ + ∞ δ ( x − y ) x d x y=\int_{-\infty}^{+\infty} \delta(x-y) x \mathrm{d} x y=∫−∞+∞δ(x−y)xdx
- 作者直接抛去可能的狄拉克和高斯分布(所有先验),直接学习underlying General distribution P ( x ) P(x) P(x),定义一个边界可能的范围 y 0 ≤ y ≤ y n , n ∈ N + y_0 \leq y \leq y_{n}, n \in \mathbb{N}^{+} y0≤y≤yn,n∈N+,估计值 y ^ = ∫ − ∞ + ∞ P ( x ) x d x = ∫ y 0 y n P ( x ) x d x \hat{y}=\int_{-\infty}^{+\infty} P(x) x \mathrm{d} x=\int_{y_{0}}^{y_{n}} P(x) x \mathrm{d} x y^=∫−∞+∞P(x)xdx=∫y0ynP(x)xdx
- 将上述连续形式离散化:
y
^
=
∑
i
=
0
n
P
(
y
i
)
y
i
\hat{y}=\sum_{i=0}^{n} P\left(y_{i}\right) y_{i}
y^=∑i=0nP(yi)yi,将P定义为softmax分布,然后只关注于边界最近的相邻两个概率(
y
i
和
y
i
+
1
y_i和y_{i+1}
yi和yi+1,
y
i
≤
y
≤
y
i
+
1
y_{i} \leq y \leq y_{i+1}
yi≤y≤yi+1),为了迫使网络快速聚焦于标签y附近的值,采用交叉熵形式作为损失函数,由于Bbox的学习只针对正样本,没有类不平衡问题的风险!
- Distribution Focal Loss (DFL):
D F L ( S i , S i + 1 ) = − ( ( y i + 1 − y ) log ( S i ) + ( y − y i ) log ( S i + 1 ) ) \mathbf{D F L}\left(\mathcal{S}_{i}, \mathcal{S}_{i+1}\right)=-\left(\left(y_{i+1}-y\right) \log \left(\mathcal{S}_{i}\right)+\left(y-y_{i}\right) \log \left(\mathcal{S}_{i+1}\right)\right) DFL(Si,Si+1)=−((yi+1−y)log(Si)+(y−yi)log(Si+1))
- Distribution Focal Loss (DFL):
- 其形式上与QFL的右半部分很类似,含义是以类似交叉熵的形式去优化与标签y最接近的一左一右两个位置的概率,从而让网络快速地聚焦到目标位置的邻近区域的分布中去
- The global minimum solution of DFL: S i = y i + 1 − y y i + 1 − y i , S i + 1 = y − y i y i + 1 − y i \mathcal{S}_{i}=\frac{y_{i+1}-y}{y_{i+1}-y_{i}}, \mathcal{S}_{i+1}=\frac{y-y_{i}}{y_{i+1}-y_{i}} Si=yi+1−yiyi+1−y,Si+1=yi+1−yiy−yi
- y ^ = ∑ j = 0 n P ( y j ) y j = S i y i + S i + 1 y i + 1 = y i + 1 − y y i + 1 − y i y i + y − y i y i + 1 − y i y i + 1 = y \hat{y}=\sum_{j=0}^{n} P\left(y_{j}\right) y_{j}=\mathcal{S}_{i} y_{i}+\mathcal{S}_{i+1} y_{i+1}=\frac{y_{i+1}-y}{y_{i+1}-y_{i}} y_{i}+\frac{y-y_{i}}{y_{i+1}-y_{i}} y_{i+1}=y y^=∑j=0nP(yj)yj=Siyi+Si+1yi+1=yi+1−yiyi+1−yyi+yi+1−yiy−yiyi+1=y
GFL
- QFL和DFL其实可以统一地表示为GFL,我们将其称之为Generalized Focal Loss
G F L ( p y t , p y r ) = − ∣ y − ( y l p y l + y r p y r ) ∣ β ( ( y r − y ) log ( p y l ) + ( y − y l ) log ( p y r ) ) \mathbf{G F L}\left(p_{y_{t}}, p_{y_{r}}\right)=-\left|y-\left(y_{l} p_{y_{l}}+y_{r} p_{y_{r}}\right)\right|^{\beta}\left(\left(y_{r}-y\right) \log \left(p_{y_{l}}\right)+\left(y-y_{l}\right) \log \left(p_{y_{r}}\right)\right) GFL(pyt,pyr)=−∣y−(ylpyl+yrpyr)∣β((yr−y)log(pyl)+(y−yl)log(pyr)) - 在附录中也给出了,Focal Loss,包括本文提出的QFL和DFL都可以看做为GFL中的变量取到特定值的特例。
总结
- QFL和DFL的作用是正交的,他们的增益互不影响
- 发现IoU作为框预测质量的度量会始终比centerness更优
- IoU本身就是最终metric的衡量标准,所以用来做质量估计和排序是非常自然的
- centerness有一些不可避免的缺陷,比如对于stride=8的FPN的特征层(也就是P3),会存在一些小物体他们的centerness label极度小甚至接近于0,如下图所示:


- 发现有一些分布式表示学到了多个峰

作者的闲谈
- 谈谈检测这块的两个可能的大趋势:
- 一个是kaiming引领的unsupervised learning,妥妥撸起袖子干一个检测友好的unsupervised pretrain model especially for object detection;
- 还有一个是FAIR最近火爆的DETR(全Attention的目标检测框架),其实去掉NMS这个事情今年也一直在弄,搞的思路一直不太对,也没搞出啥名堂,还是DETR花500个epoch引领了一下这个潮流,指了个门道,当然方向有了,具体走成啥样,还是八仙过海,各显神通啦~
7 Anchor-free Network
- YOLOv1,DenseBox,CornerNet,CornerNet-Lite,CenterNet
DenseBox 2015
- 黄李超/地平线 神人
- 人脸检测
主要贡献
- 使用全卷积网络,任务类型类似于语义分割,并且实现了端到端的训练和识别,而R-CNN系列算法是从Faster R-CNN中使用了RPN代替了Selective Search才开始实现端到端训练的,而和语义分割的结合更是等到了2017年的Mask R-CNN才开始;
- 多尺度特征,而R-CNN系列直到FPN才开始使用多尺度融合的特征;
- 结合关键点的多任务系统,DenseBox的实验是在人脸检测数据集(MALF)上完成的,结合数据集中的人脸关键点可以使算法的检测精度进一步提升。
网络结构
- DenseBox使用了16层的VGG-19作为骨干网络,但是只使用了其前12层,如图3所示

结合关键点的多任务模型

CornerNet 2018
简介
- Detecting Objects as Paired Keypoints
- 在 CornerNet 中, 舍弃了 anchor 的设定, 转而利用一对角点来表示物体, 卷积网络会预测输出两组 heatmap, 分别代表了 bbox 的左上角和右下角.
- CornerNet 同时还会为每个 corner 预测一个 embedding vector, 当一组角点的 embedding vector 的点积(相似度)越小时, 则说明这组角点被分到同一组的可能性更高. 如果距离小于阈值,则生成对象边界框。为边界框分配置信度分数,该分数等于 corner pairs 的平均分数
- CornerNet 会预测两组热图, 每一组热图都具有 C C C 个通道, C C C 代表了物体类别的数量, 热图的尺寸为 H × W H×W H×W. 注意, 这里没有背景的通道(background channel). 每一个 channel 都是一个二值的 mask, 用于指示某个类别的角点位置.
- 对于每个角点来说, 都会有一个 gt positive location, 而其他的 locations 都将是负样本. 由于 gt positive location 周围的像素点比其它的像素点更接近 gt, 所以, 我们不能对所有的负样本给予同样的标签, 因此, CornerNet 使用了一个非规范的高斯分布来产生对应的 GT 样本, 其正中心位于 gt positive location,
σ
σ
σ 的值根据 GT 物体的大小来确定, 大约是物体半径的三分之一.

- 为了帮助卷积网络更好的定位 bbox 的 corner, CornerNet 提出了 Corner Pooling Layer. 对于给定的特征图谱, Corner Pooling 为分别进行自下而上的 max pooling 和自右向左的 max pooling, 然后将二者的结果相加, 即可得到左上角的 pooling 结果, 对于右下角的 pooling 操作也是类似的.


损失函数(3部分)
- 对于每个角点来说, 都会有一个 gt positive location, 而其他的 locations 都将是负样本. 在训练阶段, 我们不会等价的惩罚负样本, 我们减少了在正样本的一定半径内负样本的惩罚. 这是因为对于一对假的角点检测来说, 如果它们接近各自的真实位置, 那么就仍然可以产生一个与真实框差不多的框
Corner Points 损失
L d e t = − 1 N ∑ c = 1 C ∑ i = 1 H ∑ j = 1 W { ( 1 − p c i j ) α log ( p c i j ) y c i j = 1 ( 1 − y c i j ) β ( p c i j ) α log ( 1 − p c i j ) otherwise L_{d e t}=\frac{-1}{N} \sum_{c=1}^{C} \sum_{i=1}^{H} \sum_{j=1}^{W}\left\{\begin{array}{ll}\left(1-p_{c i j}\right)^{\alpha} \log \left(p_{c i j}\right) & y_{c i j}=1 \\ \left(1-y_{c i j}\right)^{\beta}\left(p_{c i j}\right)^{\alpha} \log \left(1-p_{c i j}\right) & \text { otherwise }\end{array}\right. Ldet=N−1c=1∑Ci=1∑Hj=1∑W{(1−pcij)αlog(pcij)(1−ycij)β(pcij)αlog(1−pcij)ycij=1 otherwise
- 损失函数来自Focal loss的改进!
- 其中, p c i j p_{c i j} pcij 为预测热图中 c c c 类在位置 ( i , j ) (i, j) (i,j) 处的得分, y c i j y_{c i j} ycij 为使用 unnormalized 高斯增广的 g t \mathrm{gt} gt 热图;其中 N N N 是图像中物体的数量, α \alpha α 和 β \beta β 是用于控制每个点贡献度的超参数(我们在所有实验中设置 a l p h a = 2 , β = 4 alpha=2, \beta=4 alpha=2,β=4) . y cij y_{\text {cij}} ycij 使用 Gaussian bumps 进行编码, ( 1 − y c i j ) \left(1-y_{c i j}\right) (1−ycij)项减少了对 gt locations 的惩罚。
Offsets 损失 (角点偏置损失)
o k = ( x k n − ⌊ x k n ⌋ , y k n − ⌊ y k n ⌋ ) L o f f = 1 N ∑ k = 1 N Smooth L 1 ( o k , o ^ k ) o_{k}=\left(\frac{x_{k}}{n}-\left\lfloor\frac{x_{k}}{n}\right\rfloor, \frac{y_{k}}{n}-\left\lfloor\frac{y_{k}}{n}\right\rfloor\right) \\ L_{o f f}=\frac{1}{N} \sum_{k=1}^{N} \operatorname{Smooth} L 1\left(o_{k}, \hat{o}_{k}\right) ok=(nxk−⌊nxk⌋,nyk−⌊nyk⌋)Loff=N1k=1∑NSmoothL1(ok,o^k)
- n是下采样因子, o k o_k ok是offset, x k 和 y k x_k和y_k xk和yk为角点 k k k的 x x x和 y y y的坐标。如上式所示,将预测点和GT点的偏置计算L1偏差!
Grouping Centers 损失
L p u l l = 1 N ∑ k = 1 N [ ( ( e t k − e k ) 2 + ( e b k − e k ) 2 ] L p u s h = 1 N ( N − 1 ) ∑ k = 1 N ∑ j = 1 , j ≠ k N max ( 0 , Δ − ∣ e k − e j ∣ ) L_{p u l l}=\frac{1}{N} \sum_{k=1}^{N}\left[\left(\left(e_{t_{k}}-e_{k}\right)^{2}+\left(e_{b_{k}}-e_{k}\right)^{2}\right]\right. \\ L_{p u s h}=\frac{1}{N(N-1)} \sum_{k=1}^{N} \sum_{j=1, j \neq k}^{N} \max \left(0, \Delta-\left|e_{k}-e_{j}\right|\right) Lpull=N1k=1∑N[((etk−ek)2+(ebk−ek)2]Lpush=N(N−1)1k=1∑Nj=1,j=k∑Nmax(0,Δ−∣ek−ej∣)
- e k t e^t_k ekt为对象 k k k 的左上角的 embeddings, e k b e^b_k ekb 为对象 k k k 的右下角的 embeddings; e k e_k ek 是 e k t e^t_k ekt和 e k b e^b_k ekb的平均值。本文实验中 Δ = 1 \Delta=1 Δ=1
- L p u l l L_{pull} Lpull 的目的就是让属于同一个物体角点的 embeddings 距离越来越小, L p u s h L_{push} Lpush 的目的就是让不同物体的角点距离越来越大.
- 点之间两两关联,associate embeddings!
网络结构
- 使用了Hourglass沙漏网络作为backbone!
Coner相对于Bbox的优势
- 定位 anchor box 更难一些, 因为它需要依赖物体的4个边界才能确定, 但是 corner 只需要物体的两个边界就可以确定, corner pooling 也是如此, 它编码了关于 corner 的一些明确的先验知识
- Corners 提供了一种更加有效的方式来密集的对 boxes 的空间进行离散化: 我们只需要 O ( w h ) O(w h) O(wh) 的 corners, 而anchor boxes 需要的复杂度是 O ( w 2 h 2 ) O\left(w^{2} h^{2}\right) O(w2h2)
CornerNet-Lite 2019
动机
- 降低计算量!
改进
- 提供了两种变体,降低计算量!
CornerNet-Saccade
- 使用缩小的图像 来预测3个attention maps, 分别用于小, 中, 大物体.
- attention 模块通过 3 × 3 c o n v − r e l u + 1 × 1 c o n v − s i g m o i d 3×3 conv-relu + 1×1 conv-sigmoid 3×3conv−relu+1×1conv−sigmoid 来实现, 然后利用获得的粗糙的 locations 信息, 从原始图像中截取相应大小的 crop 进行精细化的预测, 对于不同大小的物体, 通常具有不同的放大比例, 小对象需要放的更大些, 中对象次之, 大对象最后. 通过这种方式, 大幅降低了 location 的采样空间. 加速了检测速率.
CornerNet-Squeeze
- 受SqueezeNet 启发: 将 Residual Block 替换成 Fire Module(1x1 + 1x1 & 3x3)
- 受 MobileNet 启发: 利用 3x3 的 Dwise Conv 替换 Fire Module 中第二层的 3x3 卷积

CornerNet-Squeeze-Saccade
- 当二者同时使用时, 模型本身的容量被限制过多, 使得模型无法在检测物体的同时良好的预测 attention map, 因此效果不好.
FSAF 2019
简介
- Feature Selective Anchor-Free Module
- 有了 FSAF, 就不需要为 anchor 定义 anchor scale 和 aspect ratio 了, 金字塔层级的选择由 FASF 决定
- 以 RetinaNet 为基础,FSAF模块仅为每个金字塔层引入两个额外的conv层,如图4中虚线 feature maps 所示。这两个网络层分别负责 anchor free 分支的分类和回归预测!

- 具体来说,我们会在分类子网中最后的 feature map 上附加了一个带有 K 个 filter 的 3×3 conv 层,后面是 sigmoid 函数, 用于二分类,该网络层与 anchor based 分支的网络层并行。它为K个对象类预测对象会出现在每个空间位置的概率。同样的,回归子网中的 feature map 上也附加了一个 3×3 conv 层,带有 4 个filter,然后是ReLU[26]函数。它负责预测以 anchor free 方式编码的 bbox 偏移量。
- anchor free 和 anchor based 分支可以以多任务的方式联合工作,共享每个金字塔级别的特性。
Groud-truch and Loss

Classification Output:
- 针对分类输出的 gt 是 K K K 个 maps,每个 map 对应一个类。每个实例以三种方式影响第 k k k 个 gt map:
-
- 物体的中心区域(bbox 的 0.2 倍)被定义为 positive region(白色), 表示该实例的存在性。
-
- 物体中心区域外围的部分区域(bbox 的 0.5 倍再去除中央部分)被定义为 ignoring region(灰色) 这意味着该区域的梯度不会传播回网络。其余区域由黑色填充, 表示没有对象
-
- 相邻金字塔层 ( b i l − 1 , b i l + 1 ) \left(b_{i}^{l-1}, b_{i}^{l+1}\right) (bil−1,bil+1) 中的 ignoring region 如果存在, 那么在当前层级上也将忽略该区域。注意, 如果两个实例的 effective box 在一个特征级别上重蛋, 则较小的实例具有更高的优先级。我们使用Focal Loss 作为损失函数进行监督(正负样本), 超参数 α = 0.25 , γ = 2.0 \alpha=0.25, \gamma=2.0 α=0.25,γ=2.0 图像 anchor free 分支的分类总损失是所有非忽略区域上的 Focal Loss 之和,由 所有 effective box 区域内的像素总数归一化
Box Regression Output:
- 回归输出的 gt 是 4 个与类别无关的 offset maps。实例只影响 offset maps 上的 effective 区域。对于 effective region 中的每一个像素 Iocation ( i , j ) (i, j) (i,j) 我们将其映射成一个四维向量, 分别表示当前像素和 origin region 顶, 左, 右, 底之间的距离. 采用 loU Loss 进行优化, 并且只考虑 effective region 内的损失. 将4个 offset maps 上(i, j)处的四维向量设置为 d i , j l / S d_{i, j}^{l} / S di,jl/S 每个 map \operatorname{map} map 对应一个维度。 S S S 是一个归一化 常量, 我们根据经验选择 $ S=4.0 $
Inference
- 在 Inference 过程中,很容易从分类和回归输出中解码 predicted boxes。在每个像素位置 (
i
,
j
i, j
i,j ),假设 predicted offsets 为
[
t
^
i
j
,
o
^
l
i
j
,
o
^
b
i
j
,
o
^
r
i
j
]
∙
\left[\hat{t}_{i_{j}}, \hat{o}_{l_{i j}}, \hat{o}_{b_{i j}}, \hat{o}_{r_{i j}}\right]_{\bullet}
[t^ij,o^lij,o^bij,o^rij]∙ 然后 predicted distances 为
[
S
S
^
t
i
,
j
,
S
o
^
l
i
,
j
S
o
^
b
i
j
,
S
o
^
r
i
j
]
\left[S \hat{S}_{t_{i, j}}, S \hat{o}_{l_{i, j}} S \hat{o}_{b_{i j}}, S \hat{o}_{r_{i j}}\right]
[SS^ti,j,So^li,jSo^bij,So^rij], predicted projected
box 左上角和右下角分别为 i − S o ^ t i j , j − S o ^ l i , j i-S \hat{o}_{t_{i j}}, j-S \hat{o}_{l_{i, j}} i−So^tij,j−So^li,j 和 i + S o ^ b i j , j + S o ^ r i j i+S \hat{o}_{b_{i j}}, j+S \hat{o}_{r_{i j}} i+So^bij,j+So^rij 。我们进一步将投影框放大 2 l 2^{l} 2l, 得到图 像平面中的最终框。框的置信度和类别由分类输出图上位置 ( i , j ) i, j) i,j) 处的 k k k 维向量的最大得分和对应的类决定
Online Feature Selection
L F L I ( l ) = 1 N ( b e l ) ∑ i , j ∈ b e l F L ( l , i , j ) L I O U I ( l ) = 1 N ( b e l ) ∑ i , j ∈ b e l IoU ( l , i , j ) L_{F L}^{I}(l)=\frac{1}{N\left(b_{e}^{l}\right)} \sum_{i, j \in b_{e}^{l}} F L(l, i, j) \\ L_{I O U}^{I}(l)=\frac{1}{N\left(b_{e}^{l}\right)} \sum_{i, j \in b_{e}^{l}} \operatorname{IoU}(l, i, j) LFLI(l)=N(bel)1i,j∈bel∑FL(l,i,j)LIOUI(l)=N(bel)1i,j∈bel∑IoU(l,i,j)
- 其中 N ( b e l ) N\left(b_{e}^{l}\right) N(bel) 为 b e l b_{e}^{l} bel 区域内的像素个数, F L ( l , i , j ) , IoU ( l , i , j ) F L(l, i, j), \operatorname{IoU}(l, i, j) FL(l,i,j),IoU(l,i,j) 分别为 P l P_{l} Pl 在 location ( i , j ) (i, j) (i,j) 处的 Focal Loss [ 22 ] \operatorname{Loss}[22] Loss[22]和loU Loss[36]
- ① 在训练阶段, 每个实例都会通过特征金字塔所有层级
l
l
l 的 forward 计算. 在此基础上, 对所有 anchor free 支路计算
L
F
L
I
(
l
)
L_{F L}^{I}(l)
LFLI(l) 和
L
I
o
U
I
(
l
)
L_{I o U}^{I}(l)
LIoUI(l) 最后, 我们选择产生最小损失和的金字塔级
P
l
P_{l}
Pl 作为学习实例的最佳目标层级, 即:
l ∗ = arg min l L F L I ( l ) + F I o U I ( l ) l^{*}=\arg \min _{l} L_{F L}^{I}(l)+F_{I o U}^{I}(l) l∗=arglminLFLI(l)+FIoUI(l) - 然后, 我们只更新这个最佳目标层级上的梯度, 这就达到了在线选择特征的目的
- ② 然后, 我们只更新这个最佳目标层级上的梯度, 这就达到了在线选择特征的目的

- FASF 和 Anchor-based 结合使用时, 能有更好的效果. 增加的计算量很少, 只有 l × 2 l×2 l×2 个卷积层. 二者再结合时, 会合并各自的 box predictions, 然后利用阈值为 0.5 的 NMS, 得到最终的检测结果.
FoveaBox 2019
- FoveaBox: Beyond Anchor-based Object Detector
- FoveaBox 整体架构基于 RetinaNet. 由一个 backbone 网络和两个 subnet 组成, FoveaBox 的输出通道数是 RetinaNet 的
1
/
A
1/A
1/A

- 主要特点:
- ① class 分支负责预测类别敏感的语义图, 将其看做是目标存在的概率

- ② box regression 分支负责预测中心坐标与 gt-box G = ( x 1 , y 1 , x 2 , y 2 ) G=(x 1, y 1, x 2, y 2) G=(x1,y1,x2,y2) 四条边界之间的距离
FoveaBox 的 Scale Assignment
- 在FoveaBox中,每个特征金字塔会学习响应特定尺度的对象。 金字塔等级
l
l
l 的目标框的有效比例范围计算为:
[ S l / η 2 , S l ⋅ η 2 ] \left[S_{l} / \eta^{2}, S_{l} \cdot \eta^{2}\right] [Sl/η2,Sl⋅η2] - 其中 η η η 是根据经验设置的,以控制每个金字塔的比例范围。注意,一个对象可能被网络的多个金字塔检测到,这与以前只将对象映射到一个特征金字塔的做法不同(FPN, MaskRCNN).
FoveaBox 与其他模型的比较
- RetinaNet: FoveaBox 每个位置只会预测 1 个物体, 因此复杂度是 RetinaNet 的 1/A
- Anchor-based: FoveaBox 没有预设 box 的性状, 因此对于那些性状比较极端的物体来说, 效果更好
- RPN: FoveaBox 本身还可以将模型的 head 修改成 class agnostic scheme, 将其作用 region proposals 使用, 可以进一步提升 two-stage 的性能
- Guided-Anchoring: FoveaBox 不依赖于 center 进行预测, 而是依赖于每个情景位置的物体上下左右边界, 这对于哪些 (x, y) 不在目标中心的 bbox 来说, 鲁棒性更好.
- FASF
-
- FASF 的依靠在线特征选择模块为每个实例和锚点选择合适的特征, FoveaBox 依然采用根据尺度进行分配的策略. 个人观点: 是否可以将 FASF 模型加入到 FoveaBox 中, 进一步提升性能
-
- FASF 使用 IoU Loss, FoveaBox 使用 Smooth L1, 后者相对简洁
-
- FoveaBox 整体性能略强于 FSAF
- CornerNet, CenterNet, ExtremeNet 等:
FoveaBox 与其他基于 points 的 anchor-free 模型的一大优势: FoveaBox 直接将每个实例和 bbox 关联在一起, 不需要额外的分组方案来将 points 组合成特定实例.
FCOS 2019
- Fully Convolutional One-Stage Object Detection

- FCOS 利用全卷积网络, 对于特征图谱上到每一点 (x,y), 先将他映射回原始图片中, 差不多刚好位于 ( x , y ) (x,y) (x,y) 的感受野中心附近. 然后, 如果位置 ( x , y ) (x,y) (x,y) 落入到任何 GT Box B i B_i Bi 内部, 那么就将其视为正样本, 并且该位置的类标签就是该 GT Box 的类标签 c ∗ c^∗ c∗, 否则它就是负样本并且 c ∗ = 0 c^∗=0 c∗=0(背景类)
- 对于点
(
x
,
y
)
(x,y)
(x,y) 的回归目标, 将其定义为当前点当 GT Box 四条边界的距离, 因此,如果位置
(
x
,
y
)
(x,y)
(x,y) 与边界框
B
i
B_i
Bi 相关联,则该位置的训练回归目标可以表示为:
{ l ∗ = x − x 0 ( i ) , t ∗ = y − y 0 ( i ) r ∗ = x 1 ( i ) − x , b ∗ = y 1 ( i ) − y \left\{\begin{array}{l}l^{*}=x-x_{0}^{(i)}, t^{*}=y-y_{0}^{(i)} \\ r^{*}=x_{1}^{(i)}-x, b^{*}=y_{1}^{(i)}-y\end{array}\right. {l∗=x−x0(i),t∗=y−y0(i)r∗=x1(i)−x,b∗=y1(i)−y
损失函数
L ( { p ⃗ x , y } , { t ⃗ x , y } ) = 1 N p o s ∑ x , y L c l s ( p ⃗ x , y , c x , y ∗ ) + λ N p o s ∑ x , y I c x , y ∗ > 0 L r e g ( t ⃗ x , y , t ⃗ x , y ∗ ) L\left(\left\{\vec{p}_{x, y}\right\},\left\{\vec{t}_{x, y}\right\}\right)=\frac{1}{N_{p o s}} \sum_{x, y} L_{c l s}\left(\vec{p}_{x, y}, c_{x, y}^{*}\right)+ \\ \frac{\lambda}{N_{p o s}} \sum_{x, y} I_{c_{x, y}^{*}>0} L_{r e g}\left(\vec{t}_{x, y}, \vec{t}_{x, y}^{*}\right) L({px,y},{tx,y})=Npos1x,y∑Lcls(px,y,cx,y∗)+Nposλx,y∑Icx,y∗>0Lreg(tx,y,tx,y∗)
目标重叠问题
- FCOS 存在的一个问题是如果目标存在重叠, 那么特征图谱上的点就会同时落入多个物体的边界框, 此时这个点就变成了模糊样本, 对于模糊样本, 我们可以利用 FPN 来解决.

- 这里存在一个假设前提, 就是发生重叠的物体尺寸大小必须不同, 只有这样才能将目标分别匹配到不同的金字塔层级上进行预测. 否则, 依然会产生漏检问题.
Center-ness
- FCOS 中, 正样本的数量虽然多, 但是 远离物体中心的正样本位置会生成大量的低质量预测框. 为此 FCOS 在分类分支上, 添加一个并行的单层网络分支, 它负责预测每个位置 处于物体中心的概率(center-ness), 具体形式定义为 从该位置到该位置所负责对象的中心的距离, 如下所示
c e n t e r n e s s ∗ = min ( l ∗ , r ∗ ) max ( l ∗ , r ∗ ) × min ( t ∗ , b ∗ ) max ( t ∗ , b ∗ ) centerness ^{*}=\sqrt{\frac{\min \left(l^{*}, r^{*}\right)}{\max \left(l^{*}, r^{*}\right)} \times \frac{\min \left(t^{*}, b^{*}\right)}{\max \left(t^{*}, b^{*}\right)}} centerness∗=max(l∗,r∗)min(l∗,r∗)×max(t∗,b∗)min(t∗,b∗) - 当某个点处于中心位置时, 该位置距离 bbox 的左右, 上下距离相等, 所以 center-ness 的值就接近于 1. 最终每个位置的预测框的置信度 将通过 center-ness 与类别得分的乘积共同给出. 这样一来, 可以通过 NMS 来消除大量的低质量预测框
- 基于 anchor 的检测器使用两个 IOU 阅值 T l o w T_{l o w} Tlow 和 T h i g h T_{h i g h} Thigh 将 anchor boxes 标记为负、忽略和正样本, center-ness可以看作是一个 软闻值。它是在网络训练中学习的,不需要调整。此外,利用该策略,我们的检测器仍然可以将任何落在 GT Box 中的位置视为正样本.
- 也可以使用预测的回归向量计算中心,而不引入额外的中心分支。然而,如表5所示,从回归向量计算的中心不能改善性能,因此需要单独学习的中心。
FCOS 与其他模型的比较
FCOS 对于正样本的定义, 使用在训练时, 正样本的数量可以大幅增加, 很大程度上缓解了正负样本不均衡的问题.
ExtremeNet 2019
- 对 CornerNet 的一种扩展, 损失函数和 CornerNet 类似, 不过由于分组方式不同, 因此没有 embedding 损失. ExtremeNet 会预测四个 extreme points(最上, 最左, 最下, 最右) 和一个中心点. 将检测任务当做是关键点估计来做.
分组策略
- Center Grouping
- 将五个 heatmap 作为输入, 对于给定的 heatmap, 检测所有的值大于
τ
p
\tau p
τp 的极大值(大于周围 3x3)坐标, 将其记
为该 heatmap 的峰值 - 对于给定的任意组合的四个极值点 $ (t, b, r, l) $ ), 计算它们的几何中心 c = ( l x + r x ) 2 , ( t y + b y ) 2 c=\frac{\left(l_{x}+r_{x}\right)}{2}, \frac{\left(t_{y}+b_{y}\right)}{2} c=2(lx+rx),2(ty+by),如果在预测的 center heatmap Y ^ ( c ) \hat{Y}^{(c)} Y^(c) 中该中心具有较高响应 Y ^ c x , c y ( c ) ≥ τ c \hat{Y}_{c x, c y}^{(c)} \geq \tau c Y^cx,cy(c)≥τc 则我们就将这些极值点作为一个有效的组合.
- 以暴力搜索的方式对所有关键点
t
,
b
,
r
,
l
t, b, r, l
t,b,r,l 的进行四元组的枚举。我们独立地提取每个类别的检测。我们在所有实验中设定
τ
p
=
0.1
\tau p=0.1
τp=0.1 和
τ
c
=
0.1
\tau c=0.1
τc=0.1

Ghost box suppression(分组存在的问题)
- ExtremeNet 的分组策略存在一些显而易见的问题,
- 中心分组会对 相同大小的三个等间距共线 物体给出高置信度 FP 检测(仔细想一想就能知道, 如果三个相同大小的物体共线, 那么左右两边的物体的左右极值点很有可能会被分组到中间物体上, 这是非常错误的!)。 中心物体在这里有两个选择,一是提交正确的小方框,二是预测一个包含其邻居极值点的更大的方框(FP)。 我们将这些 FP 检测称为 Ghost box。 正如我们将在实验中展示的那样,这些鬼盒很少见,但仍然是 a consistent error mode of our grouping.
- 我们提供了一个简单的后处理步骤来删除 ghost box。根据定义, ghost box 会包含许多其他较小的检测框。为了阻止 ghost box ,我们使用了一种 soft-nms 的变种, 即 如果某一个大边界框中包含的所有框的得分之和超过其自身得分的3倍,则将这个大边界框(可能是 ghost box)得分除以2 这种非极大值抑制类似于标准的基于重叠的非极大值抑制,但是会惩罚潜在的 ghost box,而不是多个重叠的 box。
Edge aggregation
- 极值点并不总是唯一定义的。 如果物体的垂直或水平边缘形成极值点(例如,汽车的顶部),沿着该边缘的任何点都可以被认为是极值点。 因此,我们的网络会沿对象的任意对齐边缘产生多处弱响应,而不是单个强峰响应。 这种弱响应存在两个问题:第一,较弱的响应可能低于我们的峰值选择阈值 τp,我们将完全错过极值点。 其次,即使我们检测到关键点,其得分也会低于具有强烈峰值响应的轻微旋转对象。
- 我们使用 边缘聚合 来解决这个问题。对于提取为局部最大值的每个极值点,我们在垂直方向(对于左和右极值点)或水平方向(对于顶部和底部关键字点)汇总其得分。我们对所有 单调递减 的分数进行聚合,并在聚合方向上以 局部最小值 停止聚合。具体地说, 我们令
m
m
m 是一个 extreme point,
N
i
(
m
)
=
Y
^
m
x
+
i
,
m
y
N_{i}^{(m)}=\hat{Y}_{m_{x}+i, m_{y}}
Ni(m)=Y^mx+i,my 该点的垂直线段或水平线段. 令 $i_{0}<0 $ 和 $ 0<i_{1}$ 为两个最近的局部最小点, 于是我们更新 extreme point 的值为
Y
~
m
=
Y
^
m
+
λ
a
g
g
r
s
u
m
i
=
i
0
i
1
N
i
(
m
)
\tilde{Y}_{m}=\hat{Y}_{m}+\lambda_{a g g r} s u m_{i=i_{0}}^{i_{1}} N_{i}^{(m)}
Y~m=Y^m+λaggrsumi=i0i1Ni(m) 其中,
λ
aggr
\lambda_{\text {aggr}}
λaggr 是 aggregation weight, 在我们的实验中, 取其值为
0.1
0.1
0.1 效果如图 4 所示.

Extreme points 与 Corner points 的区别
- corner points 是 bbox 的左上角和右下角, 大多数情况下, corner points 都位于物体的外面, 因此缺少足够的物体特征.
- extreme points 定义在物体上, 因此具有更丰富的物体特征, 因此检测难度相对较低.
CenterNet(Triplets) 2019
简介
- CornerNet 的表现受到 其获取物体全局信息的能力相对较弱 的限制.
- CenterNet(Triplets) 将靠近几何中心的区域,作为一个额外的关键点.

- CenterNet 通过中心关键点和一对角点来表示每个物体。具体来说,作者在 CornerNet 的基础上 为中心关键点嵌入了热图,并 预测了中心关键点的偏移。然后,作者使用 CornerNet 中提出的方法生成 t o p − k top−k top−k 的边界框。但是,为了有效滤除不正确的边界框,作者会利用检测到的中心关键点并采用以下程序:
- 1 根据中心关键点自身的分数先选择 t o p − k top−k top−k 个点;
- 2 使用相应的 offsets 将这些中心关键点重新映射到输入图像上;
- 3 为每个边界框定义一个中心区域,并检查中心区域是否包含中心关键点。请注意,检查过的中心关键点的类标签应与边界框的类标签相同;
- 4 如果在中心区域检测到中心关键点,我们将保留这个预测到的边界框。边界框的分数将由三个点的平均分数代替,即左上角,右下角和中心关键点。如果在其中心区域中未检测到中心关键点,则将删除该边界框。
- 边界框中的中心区域的大小会影响检测结果。例如,较小的中心区域导致小边界框的召回率较低,而较大的中心区域导致较大的边界框的精度较低。因此,作者提出了一种可以 感知尺度(scale-aware)的中心区域,以便自适应地拟合边界框的大小。尺度感知的中心区域倾向于为小的边界框生成相对大的中心区域,而对于大的边界框则生成相对小的中心区域。假设想确定是否需要保留边界框 $i_{\circ} \quad $ 设
t
l
x
t l_{x}
tlx 和
t
l
y
t l_{y}
tly 表示角点
i
i
i 的 top-left corner 坐标,
b
r
x
b r_{x}
brx 和
b
r
y
b r_{y}
bry 表示角点
i
i
i 的 bottom-right corner 坐标。定义中心区域为
j
j
j 设
c
t
l
x
c t l_{x}
ctlx 和
c
t
l
y
c t l_{y}
ctly 表示
j
j
j 的左上角坐标,
c
b
r
x
c b r_{x}
cbrx 和
c
b
r
y
c b r_{y}
cbry 表示
j
j
j的右下角坐标。那么
t
l
x
,
t
l
y
,
b
r
x
,
b
r
y
,
c
t
l
x
,
c
t
l
y
,
c
b
r
x
t l_{x}, t l_{y}, br_{x}, br_{y}, ctl_{x}, ctl_{y}, cbr_{x}
tlx,tly,brx,bry,ctlx,ctly,cbrx 和
c
b
r
y
c b r_{y}
cbry 应该满足以下关系:
{ c t l x = ( n + 1 ) t t x + ( n − 1 ) b r x 2 n c t l y = ( n + 1 ) t t y + ( n − 1 ) b y y 2 n c b r x = ( n − 1 ) t t x + ( n + 1 ) b r x 2 n c b r y = ( n − 1 ) t l y + ( n + 1 ) b r y 2 n \left\{\begin{array}{l}c t l_{x}=\frac{(n+1) t t_{x}+(n-1) b r_{x}}{2 n} \\ c t l_{y}=\frac{(n+1) t t_{y}+(n-1) b_{y_{y}}}{2 n} \\ c b r_{x}=\frac{(n-1) t t_{x}+(n+1) b r_{x}}{2 n} \\ c b r_{y}=\frac{(n-1) t l_{y}+(n+1) b r_{y}}{2 n}\end{array}\right. ⎩⎪⎪⎪⎨⎪⎪⎪⎧ctlx=2n(n+1)ttx+(n−1)brxctly=2n(n+1)tty+(n−1)byycbrx=2n(n−1)ttx+(n+1)brxcbry=2n(n−1)tly+(n+1)bry - 其中 n 是奇数,它决定了中心区域 j 的比例。 在本文中,对于小于或大于 150 的边界框的比例,n 被设置为 3 和 5。 图3示出了当 n=3 且 n=5 时的两个中心区域。 根据等式(1),我们可以确定尺度感知的中心区域,然后检查中心区域是否包含中心关键点。

损失函数
L = L d e t c o + L c e d e f + α L p u l l c o + β L p u s h c o + γ ( L o f f c o + L o f f c e ) L=L_{d e t}^{c o}+L^{c e} d e f+\alpha L_{p u l l}^{c o}+\beta L_{p u s h}^{c o}+\gamma\left(L_{o f f}^{c o}+L_{o f f}^{c e}\right) L=Ldetco+Lcedef+αLpullco+βLpushco+γ(Loffco+Loffce)
- 上式中 L det c o L_{\text {det}}^{c o} Ldetco 和 L det c e L_{\text {det}}^{c e} Ldetce 表示 Focal Losses,它们分别用于检测 Corners 和 Center Keypoints ∘ L p u l l c o _{\circ} L_{p u l l}^{c o} ∘Lpullco 是 corners 的 “pull” 损失,用于 最小化对于相同物体的嵌入向量的距离。 L p u s h c o \quad L_{p u s h}^{c o} Lpushco 是 corners 的 “push" 损失, 用于 最大化属 于不同物体的嵌入向量的距离。 L o f f c o L_{o f f}^{c o} Loffco 和 L o f f c e L_{o f f}^{c e} Loffce 是 l 1 l_{1} l1 损失, 用于预测角点和中心关键点的 offsets ∘ α , β _{\circ} \quad \alpha, \beta ∘α,β 和 γ \gamma γ 表示 相应损失的权重,分别设置为 0.1, 0.1 和 1。关于损失函数可以参考 CornerNet 了解详细信息。我们使用8个Tesla V100(32GB)GPU训练CenterNet,并使用批量大小为48.最大迭代次数为480K。我们在前450K迭代中使用 2.5 x10-4的学习速率,然后以2.5x10-5的速率继续训练30K迭代。
Enriching Center and Corner Information
Center Pooling
- 物体的几何中心不一定传达可识别性非常强的视觉图案(例如,人的头部包含特征很强的视觉图案,但是中心关键点通常位于人体的中间)。为了解决这个问题,我们提出了使用 Center Pooling 来捕获更丰富和更易识别的视觉模式。图4(a)显示了 Center Pooing 的原理。 Center Pooling 的详细过程如下:backbone 输出一个特征图,并确定特征图中的某个像素点是否是中心关键点,我们需要在 水平和垂直方向上找到最大值并将它们加在一起。通过这样做, Center Pooling 有助于更好地检测中心关键点。

Cascade Corner Pooling
- Corners 通常位于物体外部,因此缺乏物体的局部外观特征。Corner-Net 使用 Corner Pooling 来解决这个问题。Corner Pooling 的原理如图4(b)所示。Corner Pooling 旨在找到边界方向上的最大值,以便确定角点。 但是,它会使得 corners 对边缘变得敏感(不稳定)。 为了解决这个问题,我们需要让角落 “看到” 物体的 visual pattern。 Cascade Corner Pooling 的原理如图4(c)所示。它首先沿着边界查找边界最大值,然后沿着边界最大值的位置向物体内部 “看” 以找到内部最大值,最后,将两个最大值一起添加。 通过这样做,Corners 可以同时获得边界信息和物体的 visual pattern。

- 通过在不同方向组合 Corner Pooling [20],可以轻松实现 Center Pooling 和 Cascade Corner Pooling。 图5(a)显示了 Center Pooling 模块的结构。为了在一个方向(例如水平方向)上取最大值,我们只需要将左池和右池连接起来即可找到任意一点在水平方向上的最大值。 图5(b)显示了 Cascade Top Corner Pooling 模块的结构。与 CornerNet 中的 Top Corner Pooling 相比,我们在 Top Corner Pooling 之前添加了一个 Left Corner Pooling.
CenterNet(Objects as Points) 2019
简介
- 首先假设输入图像为 I ∈ R W × H × 3 , I \in R^{W \times H \times 3}, I∈RW×H×3, 其中 W W W 和 H H H 分别为图像的宽和高, 然后在预测的时候, 我们要生成关键点的 热点图(keypoint heatmap): Y ^ ∈ [ 0 , 1 ] W R × H R × C , \hat{Y} \in[0,1]^{\frac{W}{R} \times \frac{H}{R} \times C}, Y^∈[0,1]RW×RH×C, 其中 R R R 为输出对应原图的步长, 文章中为 4 , 4, 4, 而 C C C 是在目标检测中对应着检测点的数量,如在COCO目标检测任客中,这个 C 的值为80,代表当前有80个类别。
- 这样,
Y
^
x
,
y
,
c
=
1
\hat{Y}_{x, y, c}=1
Y^x,y,c=1 就代表在
(
x
,
y
)
(x, y)
(x,y) 处存在有类别为
c
c
c 的物体. 在训练流程中, CenterNet 和 CornerNet 类似, 对于每 个 ground truth 的对应类,都会先确定其真实的关键点 (true keypoint), 中心关键点的计算方式为
P
=
(
x
1
+
x
2
2
,
y
1
+
y
2
2
)
,
P=\left(\frac{x_{1}+x_{2}}{2}, \frac{y_{1}+y_{2}}{2}\right),
P=(2x1+x2,2y1+y2), 对于下采样后的坐标, 我们设置为
p
~
=
⌊
p
R
⌋
\tilde{p}=\left\lfloor\frac{p}{R}\right\rfloor
p~=⌊Rp⌋, 其中
R
R
R 是下采样因子, 文中使用
R
=
4
R=4
R=4然后利用
Y
∈
[
0
,
1
]
W
R
×
H
R
×
C
Y \in[0,1]^{\frac{W}{R}} \times \frac{H}{R} \times C
Y∈[0,1]RW×RH×C 来对图像进行标记, 并用一个高斯核
Y
x
y
c
=
exp
(
−
(
x
−
p
~
x
)
2
+
(
y
−
p
~
y
)
2
2
σ
p
2
)
Y_{x y c}=\exp \left(-\frac{\left(x-\tilde{p}_{x}\right)^{2}+\left(y-\tilde{p}_{y}\right)^{2}}{2 \sigma_{p}^{2}}\right)
Yxyc=exp(−2σp2(x−p~x)2+(y−p~y)2) 来将关健点分布到特征图上, 注意, 如果某一个类的两个高斯分布发生了重桑, 那么直接取较大的值即可. 下图是官方源码中生成的个高斯分布。

- CenterNet 使用同一个网络(攻击卷积计算)来预测关键点 Y ^ \hat{Y} Y^, offsets O ^ \hat{O} O^ 和 size S ^ . \operatorname{size} \hat{S} . sizeS^. 因此整个网络在每个位置的输出总共 C + 4 C+4 C+4 维。
- 其中 4 代表中心点的坐标和边界框的 w , h ( size prediction ) w, h (\text { size prediction }) w,h( size prediction )
损失函数 (3部分)
- L k : L_{k}: Lk: 判断特征图谱上某一点存在物体的可能性, 用 Focal Loss 进行定义
- L o f f : L_{o f f}: Loff: 为了恢复由输出步幅引起的离散化误差, 预测每个中心点的 local offset, 用 L1 损失进行定义
-
L
s
i
z
e
:
L_{s i z e}:
Lsize: 回归物体
k
k
k 的尺寸
s
k
=
(
x
2
(
k
)
−
x
1
(
k
)
,
y
2
(
k
)
−
y
1
(
k
)
)
.
s_{k}=\left(x_{2}^{(k)}-x_{1}^{(k)}, y_{2}^{(k)}-y_{1}^{(k)}\right) .
sk=(x2(k)−x1(k),y2(k)−y1(k)). 为了控制计算成本, 我们对所有的物体类别都使用 single size 的预测,
S
^
∈
R
W
R
×
H
R
×
2
\hat{S} \in R^{\frac{W}{R}} \times \frac{H}{R} \times 2
S^∈RRW×RH×2. 使用
L
1
\mathrm{L} 1
L1 损失进行定义.
L d e t = L k + λ s i z e L s i z e + λ o f f L o f f L_{d e t}=L_{k}+\lambda_{s i z e} L_{s i z e}+\lambda_{o f f} L_{o f f} Ldet=Lk+λsizeLsize+λoffLoff - 在原文所有实验中 λ s i z e = 0.1 , λ o f f = 1 ∘ \lambda_{s i z e}=0.1, \lambda_{o f f}=1_{\circ} \quad λsize=0.1,λoff=1∘ 所有的输出都共享同一个 fully-convolutional backbone 网络. 整个网络在每个位置的输出总共 C + 4 C+4 C+4 维。其中 4 代表中心点的坐标和边界框的 w , h ( size prediction ) w, h(\text { size prediction }) w,h( size prediction )
中心点正负分类损失:
L k = − 1 N ∑ x y c { ( 1 − Y ^ x y c ) α log ( Y ^ x y c ) Y x y c = 1 ( 1 − Y x y c ) β ( Y ^ x y c ) α log ( 1 − Y ^ x y c ) otherwise L_{k}=\frac{-1}{N} \sum_{x y c}\left\{\begin{array}{ll}\left(1-\hat{Y}_{x y c}\right)^{\alpha} \log \left(\hat{Y}_{x y c}\right) & Y_{x y c}=1 \\ \left(1-Y_{x y c}\right)^{\beta}\left(\hat{Y}_{x y c}\right)^{\alpha} \log \left(1-\hat{Y}_{x y c}\right) & \text { otherwise }\end{array}\right. Lk=N−1xyc∑⎩⎨⎧(1−Y^xyc)αlog(Y^xyc)(1−Yxyc)β(Y^xyc)αlog(1−Y^xyc)Yxyc=1 otherwise
- 首先, 如果不看第二项中的 ( 1 − Y x y c ) β \left(1 - Y_{ x y c }\right) ^ { \beta } (1−Yxyc)β, 那么这个损失就是经典的 Focal Loss 损失, 其中的 α \alpha α相当于 Focal Loss 原 文中的 γ . \gamma. γ.而 ( 1 − Y x y c ) β \left(1 - Y_{ x y c }\right) ^ { \beta } (1−Yxyc)β的主要作用是 : 减少 Focal Loss 对于那些距离 g t \mathbf{ g t } gt中心点较近的 hard example 的关注度.首先, 我们知道 Focal Loss 会对于 hard example 分配更加关注, 分配更大的权重, 而根据 CenterNet 对于正样本的定义, 只有物体真正的中心才是正样本, 其余的都是负样本, 因此, 对于靠近中心点的位置, 同样也会被标记成负样本, 但是这些负样本由于更靠近中心点的原因, 尝尝会以较高的置信度被识别成正样本(FP), 形成 hard example.但是这种 hard example 是情有可原的, 因为它离中心点较劲, 所以我们不希望 Loss 过多的关注这些点, 而由于 Y x y c Y_{ x y c } Yxyc是根据真实中心 点向外扩散的高斯分布, 因此, 热图上的值恰恰也反映了这个点距离中心点的远近(值越大离的越近), 因此我们使用 ( 1 − Y x y c ) β \left(1 - Y_{ x y c }\right) ^ { \beta } (1−Yxyc)β来降低这些距离中心点较近的 hard negative examples 对 Loss 的贡献程度.一方面这样做是比较合情合理的, 另一方面, 由于我们只选用 gt center 作为正样本, 而其他的所有点都是负样本, 因此正负样本的数量会极度的不均衡(这一点和 FCOS 正相反, FCOS 有大量的正样本), 因此 ( 1 − Y x y c ) β \left(1 - Y_{ x y c }\right) ^ { \beta } (1−Yxyc)β还可以起到缓解正负样本不均衡的作用.
中心点偏置(offset)补偿损失:
L o f f = 1 N ∑ p ∣ O ^ p ~ − ( p R − p ~ ) ∣ L_{o f f}=\frac{1}{N} \sum_{p}\left|\hat{O}_{\tilde{p}}-\left(\frac{p}{R}-\tilde{p}\right)\right| Loff=N1p∑∣∣∣O^p~−(Rp−p~)∣∣∣
- local offset O ^ ∈ R W R × H R × 2 \hat{O} \in R^{\frac{W}{R} \times \frac{H}{R} \times 2} O^∈RRW×RH×2
- 上式中, O ^ p ~ \hat{O}_{\tilde{p}} O^p~ 是我们预测出来的偏置, 而 ( p R − p ~ ) = ( p R − ⌊ p R ⌋ ) \left(\frac{p}{R}-\tilde{p}\right)=\left(\frac{p}{R}-\left\lfloor\frac{p}{R}\right\rfloor\right) (Rp−p~)=(Rp−⌊Rp⌋) 则是真实的偏置. 对于某 k \mathrm{k} k 类的热图, 由于尺寸固 定, 因此它所有位置的精度损失是相同的, 所以同一类的中心点, 会共享同一个 offset prediction. 在官方代码中, 这部分实现为:
# ct 即 center point reg是偏置回归数组,存放每个中心点的偏置值 k 是当前图中第 k 个目标
reg[k] = ct - ct_int
# 实际例子为
# [98.97667 2.3566666] - [98 2] = [0.97667, 0.3566666]
中心点对应物体尺寸的损失:
- 假设
(
x
1
(
k
)
,
y
1
(
k
)
,
x
2
(
k
)
,
y
2
(
k
)
)
\quad\left(x_{1}^{(k)}, y_{1}^{(k)}, x_{2}^{(k)}, y_{2}^{(k)}\right) \quad
(x1(k),y1(k),x2(k),y2(k)) 代表物体
k
\quad k
k 的
\quad
bbox, 其 类 别 为
c
k
.
\quad c_{k} . \quad
ck. 它 的center points
p
k
=
(
x
1
(
k
)
+
x
2
(
k
)
2
,
y
1
(
k
)
+
y
2
(
k
)
2
)
p_{k}=\left(\frac{x_{1}^{(k)}+x_{2}^{(k)}}{2}, \frac{y_{1}^{(k)}+y_{2}^{(k)}}{2}\right)
pk=(2x1(k)+x2(k),2y1(k)+y2(k)), 我们利用 keypoint estimator
Y
^
\hat{Y}
Y^ 去预测所有的 center points. 然后, 对每个物体
k
k
k 的 尺寸进行回归, 最终回归到物体尺寸的真实值
s
k
=
(
x
2
(
k
)
−
x
1
(
k
)
,
y
2
(
k
)
−
y
1
(
k
)
)
.
s_{k}=\left(x_{2}^{(k)}-x_{1}^{(k)}, y_{2}^{(k)}-y_{1}^{(k)}\right) .
sk=(x2(k)−x1(k),y2(k)−y1(k)). 对于物体尺寸回归, 同样适用
L
1
\mathrm{L} 1
L1 损失, 如下:
L s i z e = 1 N ∑ k = 1 N ∣ S ^ P k − s k ∣ L_{s i z e}=\frac{1}{N} \sum_{k=1}^{N}\left|\hat{S}_{P_{k}}-s_{k}\right| Lsize=N1k=1∑N∣∣∣S^Pk−sk∣∣∣

- From points to bounding boxes: 在 Inference 阶段,我们首先 独立 地提取 每个类别 热图中的峰值。我们会检测其值大于或等于其8个连接邻居的所有响应作为峰值, 并保持前100个峰值(每个类别都会提取 100 个峰值)。令
P
^
c
\hat{P}_{c}
P^c为 c 类的 n 个检测中心点的集合。 每个关键点位置由整数坐标
(
x
i
,
y
i
)
(xi,yi)
(xi,yi) 给出。我们使用关键点值
Y
^
x
i
y
i
c
\hat{Y}_{x_{i} y_{i} c}
Y^xiyic作为其检测置信度的度量,并在该位置处生成边界框:
( x ^ i + δ x ^ i − w ^ i / 2 , y ^ i + δ y ^ i − h ^ i / 2 , x ^ i + δ x ^ i + w ^ i / 2 , y ^ i + δ y ^ i + h ^ i / 2 ) \left(\hat{x}_{i}+\delta \hat{x}_{i}-\hat{w}_{i} / 2, \hat{y}_{i}+\delta \hat{y}_{i}-\hat{h}_{i} / 2, \hat{x}_{i}+\delta \hat{x}_{i}+\hat{w}_{i} / 2, \hat{y}_{i}+\delta \hat{y}_{i}+\hat{h}_{i} / 2\right) (x^i+δx^i−w^i/2,y^i+δy^i−h^i/2,x^i+δx^i+w^i/2,y^i+δy^i+h^i/2) - 上式中,
(
δ
x
^
i
,
δ
y
^
i
)
=
O
^
x
^
i
,
y
^
i
\left(\delta \hat{x}_{i}, \delta \hat{y}_{i}\right)=\hat{O}_{\hat{x}_{i}, \hat{y}_{i}}
(δx^i,δy^i)=O^x^i,y^i 代表 offset prediction,
w
^
i
,
h
^
i
=
S
^
x
^
i
,
y
^
i
\hat{w}_{i}, \hat{h}_{i}=\hat{S}_{\hat{x}_{i}, \hat{y}_{i}}
w^i,h^i=S^x^i,y^i 代表 size prediction. 所有的输出都直接从keypoint estimation产生, 无需使用基于 loU 的非最大值捕制 (NMS) 或其他后处理。峰值关键点提取可以看做是
NMS 的替代方案, 并且可以使用3x3最大池化操作在设备上有效地实现
CenterNet(Points) 与其他 One-Stage 方法的区别
- CenterNet的 “anchor” 仅仅会出现在当前目标的中心位置处而不是整张图上,所以也没有所谓的 box overlap 大于多少多少的算 positive anchor 这一说,也不需要区分这个 anchor 是物体还是背景 - 因为每个目标只对应一个 “anchor”,这个anchor是从heatmap中提取出来的,所以不需要NMS再进行来筛选
- CenterNet的输出分辨率的下采样因子是4,比起其他的目标检测框架算是很小的(Mask-Rcnn最小为16、SSD为最小为16)
- 本文的方法与基于 anchor 的一阶段方法密切相关[33,36,43]。中心点可以看作是一个与形状无关的 anchor(见图3)。 但是,有一些重要区别:
-
- CenterNet 仅使用中心点的 location 作为正样本,而不是根据 gt box 的 overlap 来确定正负样本, 因此不需要设置区分前景和背景的手动阈值.
-
- 每个物体只对应一个 positive anchor,因此物体之间的 box 没有重复的, 故而不需要 NMS 来对 box 进行去重

- 每个物体只对应一个 positive anchor,因此物体之间的 box 没有重复的, 故而不需要 NMS 来对 box 进行去重
-
- 与传统物体探测器(输出步幅为16)相比,CenterNet的输出分辨率的下采样因子是 4,比起其他的目标检测框架算是比较小的(Mask-Rcnn最小为16、SSD为最小为16). 使用较小的步幅原因, 个人认为是因为 CenterNet 仅仅利用物体的中心点作为 box 的回归依据, 那么就需要特征图谱上对应点保留有足够的信息才行, 如果步幅过大, 对于小物体来说, 信息就不足了, 回归效果也会变差.
CenterNet(Points) 的缺点
- 在实际训练中,如果在图像中,同一个类别 中的某些物体的GT中心点,在下采样时会挤到一块,也就是两个物体在GT中的中心点重叠了,CenterNet对于这种情况也是无能为力的,也就是将这两个物体的当成一个物体来训练(因为只有一个中心点)。同理,在预测过程中,如果两个同类的物体在下采样后的中心点也重叠了,那么CenterNet也是只能检测出一个中心点. 但是这种问题属于同类别的群落遮挡, 目前 Anchor-based 方法也不能很好的解决这个问题.
- CenterNet(Points) 只使用了一个步长上的特征图谱进行预测, 这使得他在面对尺度范围变化较大的情况时, 无法更好的拟合物体尺度的变化. 另外, 对于小物体的检测, 效果也有限.
ATSS 2019
- Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection
8 NAS 网络结构搜索优化
NASNet 2016
- 文中我们介绍了如何使用强化学习学习一个完整的CNN网络或是一个独立的RNN单元,这种dataset interest的网络的效果也是目前最优的。
- Neural architecture search with reinforcement learning
EfficientNet 2019
- 提出新的NAS架構EfficientNet
- EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
NAS-FPN 2019
- NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection
Detnas 2019
- DetNAS: Backbone Search for Object Detection
Mess
DetNet 2018
STDNet 2018
RFBNet 2018
Relation-Network 2018
PFPNet 2018
MetaAnchor 2018
Pelee 2018
- 本文在 DenseNet 的基础上进行改进, 提出了一个适用于移动设配的轻量级模型(模型大小只有 MobileNet 的 66%).
SNIPER 2018
Non-local Neural Networks 2018
- 提出了 non-local operations 来解决 CNN 网络中的 long-range dependencies 问题:
- 传统 CNN 的卷积操作由于输出神经元只会与输入图谱上的一部分区域有关系, 因此, 在面对那些 long-range dependencies 的时候, 往往不能捕获到足够的信息来表征数据, 为此, 作者提出了 non-locl operations, 其相当于构造了一个和特征图谱尺寸一样大的卷积核, 从而可以维持更多信息.
- non-local module 可以作为一种通用的模块应用在各项任务上
作者通过实验证明, non-local 的有效性不仅仅局限于某一类特殊任务(如视频分类), 同时还可以轻易的整合到其他现有模型中, 如将其整合到 Mask R-CNN 中, 可以当做是一种 trick 来提供 Mask R-CNN 在目标检测/分割, 姿态识别等任务上的性能表现.
Bag of Freebies 2019
- 作者首次系统的评估了各种应用于不同目标检测流程的启发式训练规则, 为未来的研究提供了有价值的实践指导.
- 作者提出了一种用于训练目标检测网络的视觉相干图像混合方法, 并证明了该方法在提高模型泛化能力方法的有效性.
- 作者在不改变现有模型网络结构和损失函数的情况下, 实现了 5% ~ 30% 的绝对精度提高. 作者所做的一切都没有增加额外的推理成本.
- 作者扩展了目标检测中数据增广领域的研究深度, 显著的增强了模型的泛化能力, 并有减少了过拟合问题. 实验还展示了一些很好的技术, 可以在不同的网络结构中 一致的 提高目标检测结果.
更多推荐

 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)