
DCN和DCNv2(可变性卷积)学习笔记(原理代码实现方式)
DCN和DCNv2(可变性卷积)网上关于两篇文章的详细描述已经很多了,我这里具体的细节就不多讲了,只说一下其中实现起来比较困惑的点。(黑体字会讲解)DCNv1解决的问题就是我们常规的图像增强,仿射变换(线性变换加平移)不能解决的多种形式目标变换的几何变换的问题。如下图所示。可变性卷积的思想很简单,就是讲原来固定形状的卷积核变成可变的。如下图所示:首先来看普通卷积,以3x3卷积为例对于每...
DCN和DCNv2(可变性卷积)
网上关于两篇文章的详细描述已经很多了,我这里具体的细节就不多讲了,只说一下其中实现起来比较困惑的点。(黑体字会讲解)
DCNv1解决的问题就是我们常规的图像增强,仿射变换(线性变换加平移)不能解决的多种形式目标变换的几何变换的问题。如下图所示。

可变性卷积的思想很简单,就是讲原来固定形状的卷积核变成可变的。如下图所示:

首先来看普通卷积,以3x3卷积为例对于每个输出y(p0),都要从x上采样9个位置,这9个位置都在中心位置x(p0)向四周扩散得到的gird形状上,(-1,-1)代表x(p0)的左上角,(1,1)代表x(p0)的右下角,其他类似。
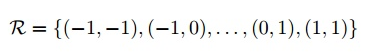
用公式表示如下:
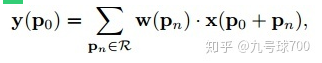
可变性卷积Deformable Conv操作并没有改变卷积的计算操作,而是在卷积操作的作用区域上,加入了一个可学习的参数∆pn。同样对于每个输出y(p0),都要从x上采样9个位置,这9个位置是中心位置x(p0)向四周扩散得到的,但是多了 ∆pn,允许采样点扩散成非gird形状。
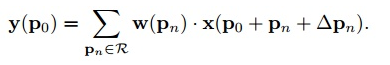

偏移量是通过对原始特征层进行卷积得到的。比如输入特征层是w×h×c,先对输入的特征层进行卷积操作,得到w×h×2c的offset field。这里的w和h和原始特征层的w和h是一致的,offset field里面的值是输入特征层对应位置的偏移量,偏移量有x和y两个方向,所以offset field的channel数是2c。offset field里的偏移量是卷积得到的,可能是浮点数,所以接下来需要通过双向性插值计算偏移位置的特征值。在偏移量的学习中,梯度是通过双线性插值来进行反向传播的。
看到这里是不是还是有点迷茫呢?那到底程序上面怎么实现呢?
事实上由上面的公式我们可以看得出来∆pn这个偏移量是加在原像素点上的,但是我们怎么样从代码上对原像素点加这个量呢?其实很简单,就是用一个普通的卷积核去跟输入图片(一般是输入的feature_map)卷积就可以了卷积核的数量是2N也就是23*3==18(前9个通道是x方向的偏移量,后9个是y方向的偏移量),然后把这个卷积的结果与正常卷积的结果进行相加就可以了。
然后又有了第二个问题,怎么样反向传播呢?为什么会有这个问题呢?因为求出来的偏移量+正常卷积输出的结果往往是一个浮点数,浮点数是无法对应到原图的像素点的,所以自然就想到了双线性差值的方法求出浮点数对应的浮点像素点。(这个跟roi-align的技巧相似,可以去看看这两篇文章
)
了解了这个以后下面就简单了。
可变形RoI池化。

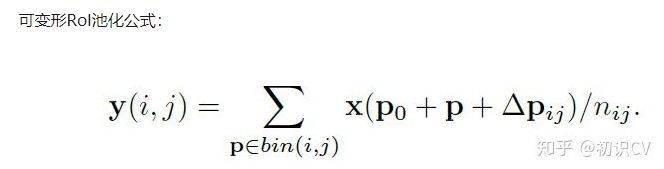
DCN v2
对于positive的样本来说,采样的特征应该focus在RoI内,如果特征中包含了过多超出RoI的内容,那么结果会受到影响和干扰。而negative样本则恰恰相反,引入一些超出RoI的特征有助于帮助网络判别这个区域是背景区域。
DCNv1引入了可变形卷积,能更好的适应目标的几何变换。但是v1可视化结果显示其感受野对应位置超出了目标范围,导致特征不受图像内容影响(理想情况是所有的对应位置分布在目标范围以内)。
为了解决该问题:提出v2, 主要有
1、扩展可变形卷积,增强建模能力
2、提出了特征模拟方案指导网络培训:feature mimicking scheme
上面这段话是什么意思呢,通俗来讲就是,我们的可变性卷积的区域大于目标所在区域,所以这时候就会对非目标区域进行错误识别。
所以自然能想到的解决方案就是加入权重项进行惩罚。(至于这个实现起来就比较简单了,直接初始化一个权重然后乘(input+offsets)就可以了)
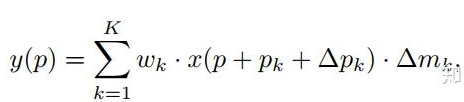
可调节的RoIpooling也是类似的,公式如下:
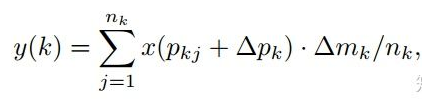
R-CNN Feature Mimicking
作者发现对于RoI分类时,普通CNN或者DCN V1的错误边界显著性区域都会延伸到RoI之外,于是与RoI不相关的图像内容就会影响RoI特征的提取,从而可能影响目标检测的结果。不过R-CNN在进行分类时,结果完全是依赖于RoI的,因为R-CNN的分类branch的输入就RoI的cropped image。
R-CNN是通过select-search得到的roi然后输入到网络中得出每一个roi的feature-map,faster-rcnn是整张图片输进去得到feature-map通过rpn得出rois。

采用了类似知识蒸馏的方法,用一个R-CNN分类网络作为teacher network 帮助Faster R-CNN更好收敛到目标区域内。
得到RoI之后,在原图中抠出这个RoI,resize到224x224,再送到一个R-CNN中进行分类,这个R-CNN只分类,不回归。然后,主网络fc2的特征去模仿R-CNN fc2的特征,实际上就是两者算一个余弦相似度,1减去相似度作为loss即可。
Feature mimic loss定义如下:
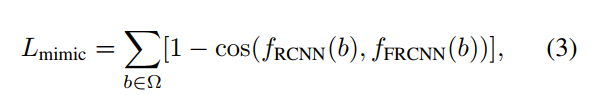
其中Ω代表RoI的集合。
代码实现:
class DeformNet(nn.Module):
def __init__(self):
super(DeformNet, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(32)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(64)
self.conv3 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.offsets = nn.Conv2d(128, 18, kernel_size=3, padding=1)
self.conv4 = DeformConv2D(128, 128, kernel_size=3, padding=1)
self.bn4 = nn.BatchNorm2d(128)
self.classifier = nn.Linear(128, 10)
def forward(self, x):
# convs
x = F.relu(self.conv1(x))
x = self.bn1(x)
x = F.relu(self.conv2(x))
x = self.bn2(x)
x = F.relu(self.conv3(x))
x = self.bn3(x)
# deformable convolution
offsets = self.offsets(x)
x = F.relu(self.conv4(x, offsets))
x = self.bn4(x)
print(x)
x = F.avg_pool2d(x, kernel_size=28, stride=1).view(x.size(0), -1)
x = self.classifier(x)
return F.log_softmax(x, dim=1)
这是调用代码,其实只是一个壳子,下面来看看主要的代码。
class DeformConv2D(nn.Module):
def __init__(self, inc, outc, kernel_size=3, padding=1, bias=None):
super(DeformConv2D, self).__init__()
self.kernel_size = kernel_size
self.padding = padding
self.zero_padding = nn.ZeroPad2d(padding)
self.conv_kernel = nn.Conv2d(inc, outc, kernel_size=kernel_size, stride=kernel_size, bias=bias)
# 注意,offset的Tensor尺寸是[b, 18, h, w],offset传入的其实就是每个像素点的坐标偏移,也就是一个坐标量,最终每个点的像素还需要这个坐标偏移和原图进行对应求出。
def forward(self, x, offset):
dtype = offset.data.type()
ks = self.kernel_size
# N=9=3x3
N = offset.size(1) // 2
#这里其实没必要,我们反正这个顺序是我们自己定义的,那我们直接按照[x1, x2, .... y1, y2, ...]定义不就好了。
# 将offset的顺序从[x1, y1, x2, y2, ...] 改成[x1, x2, .... y1, y2, ...]
offsets_index = Variable(torch.cat([torch.arange(0, 2*N, 2), torch.arange(1, 2*N+1, 2)]), requires_grad=False).type_as(x).long()
# torch.unsqueeze()是为了增加维度,使offsets_index维度等于offset
offsets_index = offsets_index.unsqueeze(dim=0).unsqueeze(dim=-1).unsqueeze(dim=-1).expand(*offset.size())
# 根据维度dim按照索引列表index将offset重新排序,得到[x1, x2, .... y1, y2, ...]这样顺序的offset
offset = torch.gather(offset, dim=1, index=offsets_index)
# ------------------------------------------------------------------------
# 对输入x进行padding
if self.padding:
x = self.zero_padding(x)
# 将offset放到网格上,也就是标定出每一个坐标位置
# (b, 2N, h, w)
p = self._get_p(offset, dtype)
# 维度变换
# (b, h, w, 2N)
p = p.contiguous().permute(0, 2, 3, 1)
# floor是向下取整
q_lt = Variable(p.data, requires_grad=False).floor()
# +1相当于向上取整,这里为什么不用向上取整函数呢?是因为如果正好是整数的话,向上取整跟向下取整就重合了,这是我们不想看到的。
q_rb = q_lt + 1
# 将lt限制在图像范围内,其中[..., :N]代表x坐标,[..., N:]代表y坐标
q_lt = torch.cat([torch.clamp(q_lt[..., :N], 0, x.size(2)-1), torch.clamp(q_lt[..., N:], 0, x.size(3)-1)], dim=-1).long()
# 将rb限制在图像范围内
q_rb = torch.cat([torch.clamp(q_rb[..., :N], 0, x.size(2)-1), torch.clamp(q_rb[..., N:], 0, x.size(3)-1)], dim=-1).long()
# 获得lb
q_lb = torch.cat([q_lt[..., :N], q_rb[..., N:]], -1)
# 获得rt
q_rt = torch.cat([q_rb[..., :N], q_lt[..., N:]], -1)
# 限制在一定的区域内,其实这部分可以写的很简单。有点花里胡哨的感觉。。在numpy中这样写:
#p = np.where(p >= 1, p, 0)
#p = np.where(p <x.shape[2]-1, p, x.shape[2]-1)
# 插值的时候需要考虑一下padding对原始索引的影响
# (b, h, w, N)
# torch.lt() 逐元素比较input和other,即是否input < other
# torch.rt() 逐元素比较input和other,即是否input > other
mask = torch.cat([p[..., :N].lt(self.padding)+p[..., :N].gt(x.size(2)-1-self.padding),
p[..., N:].lt(self.padding)+p[..., N:].gt(x.size(3)-1-self.padding)], dim=-1).type_as(p)
#禁止反向传播
mask = mask.detach()
#p - (p - torch.floor(p))不就是torch.floor(p)呢。。。
floor_p = p - (p - torch.floor(p))
#总的来说就是把超出图像的偏移量向下取整
p = p*(1-mask) + floor_p*mask
p = torch.cat([torch.clamp(p[..., :N], 0, x.size(2)-1), torch.clamp(p[..., N:], 0, x.size(3)-1)], dim=-1)
# bilinear kernel (b, h, w, N)
# 插值的4个系数
g_lt = (1 + (q_lt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_lt[..., N:].type_as(p) - p[..., N:]))
g_rb = (1 - (q_rb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_rb[..., N:].type_as(p) - p[..., N:]))
g_lb = (1 + (q_lb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_lb[..., N:].type_as(p) - p[..., N:]))
g_rt = (1 - (q_rt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_rt[..., N:].type_as(p) - p[..., N:]))
# (b, c, h, w, N)
x_q_lt = self._get_x_q(x, q_lt, N)
x_q_rb = self._get_x_q(x, q_rb, N)
x_q_lb = self._get_x_q(x, q_lb, N)
x_q_rt = self._get_x_q(x, q_rt, N)
# (b, c, h, w, N)
# 插值的最终操作在这里
x_offset = g_lt.unsqueeze(dim=1) * x_q_lt + \
g_rb.unsqueeze(dim=1) * x_q_rb + \
g_lb.unsqueeze(dim=1) * x_q_lb + \
g_rt.unsqueeze(dim=1) * x_q_rt
#偏置点含有九个方向的偏置,_reshape_x_offset() 把每个点9个方向的偏置转化成 3×3 的形式,
# 于是就可以用 3×3 stride=3 的卷积核进行 Deformable Convolution,
# 它等价于使用 1×1 的正常卷积核(包含了这个点9个方向的 context)对原特征直接进行卷积。
x_offset = self._reshape_x_offset(x_offset, ks)
out = self.conv_kernel(x_offset)
return out
#求每个点的偏置方向
def _get_p_n(self, N, dtype):
p_n_x, p_n_y = np.meshgrid(range(-(self.kernel_size-1)//2, (self.kernel_size-1)//2+1),
range(-(self.kernel_size-1)//2, (self.kernel_size-1)//2+1), indexing='ij')
# (2N, 1)
p_n = np.concatenate((p_n_x.flatten(), p_n_y.flatten()))
p_n = np.reshape(p_n, (1, 2*N, 1, 1))
p_n = Variable(torch.from_numpy(p_n).type(dtype), requires_grad=False)
return p_n
@staticmethod
#求每个点的坐标
def _get_p_0(h, w, N, dtype):
p_0_x, p_0_y = np.meshgrid(range(1, h+1), range(1, w+1), indexing='ij')
p_0_x = p_0_x.flatten().reshape(1, 1, h, w).repeat(N, axis=1)
p_0_y = p_0_y.flatten().reshape(1, 1, h, w).repeat(N, axis=1)
p_0 = np.concatenate((p_0_x, p_0_y), axis=1)
p_0 = Variable(torch.from_numpy(p_0).type(dtype), requires_grad=False)
return p_0
#求最后的偏置后的点=每个点的坐标+偏置方向+偏置
def _get_p(self, offset, dtype):
# N = 9, h, w
N, h, w = offset.size(1)//2, offset.size(2), offset.size(3)
# (1, 2N, 1, 1)
p_n = self._get_p_n(N, dtype)
# (1, 2N, h, w)
p_0 = self._get_p_0(h, w, N, dtype)
p = p_0 + p_n + offset
return p
#求出p点周围四个点的像素
def _get_x_q(self, x, q, N):
b, h, w, _ = q.size()
padded_w = x.size(3)
c = x.size(1)
# (b, c, h*w)将图片压缩到1维,方便后面的按照index索引提取
x = x.contiguous().view(b, c, -1)
# (b, h, w, N)这个目的就是将index索引均匀扩增到图片一样的h*w大小
index = q[..., :N]*padded_w + q[..., N:] # offset_x*w + offset_y
# (b, c, h*w*N)
index = index.contiguous().unsqueeze(dim=1).expand(-1, c, -1, -1, -1).contiguous().view(b, c, -1)
#双线性插值法就是4个点再乘以对应与 p 点的距离。获得偏置点 p 的值,这个 p 点是 9 个方向的偏置所以最后的 x_offset 是 b×c×h×w×9。
x_offset = x.gather(dim=-1, index=index).contiguous().view(b, c, h, w, N)
return x_offset
#_reshape_x_offset() 把每个点9个方向的偏置转化成 3×3 的形式
@staticmethod
def _reshape_x_offset(x_offset, ks):
b, c, h, w, N = x_offset.size()
x_offset = torch.cat([x_offset[..., s:s+ks].contiguous().view(b, c, h, w*ks) for s in range(0, N, ks)], dim=-1)
x_offset = x_offset.contiguous().view(b, c, h*ks, w*ks)
return x_offset
v2的代码就是在v1的基础上加了权重项sigmoid。就不详细注释了。
import torch
from torch import nn
class DeformConv2d(nn.Module):
def __init__(self, inc, outc, kernel_size=3, padding=1, stride=1, bias=None, modulation=False):
"""
Args:
modulation (bool, optional): If True, Modulated Defomable Convolution (Deformable ConvNets v2).
"""
super(DeformConv2d, self).__init__()
self.kernel_size = kernel_size
self.padding = padding
self.stride = stride
self.zero_padding = nn.ZeroPad2d(padding)
self.conv = nn.Conv2d(inc, outc, kernel_size=kernel_size, stride=kernel_size, bias=bias)
self.p_conv = nn.Conv2d(inc, 2*kernel_size*kernel_size, kernel_size=3, padding=1, stride=stride)
nn.init.constant_(self.p_conv.weight, 0)
self.p_conv.register_backward_hook(self._set_lr)
self.modulation = modulation
if modulation:
self.m_conv = nn.Conv2d(inc, kernel_size*kernel_size, kernel_size=3, padding=1, stride=stride)
nn.init.constant_(self.m_conv.weight, 0)
self.m_conv.register_backward_hook(self._set_lr)
@staticmethod
def _set_lr(module, grad_input, grad_output):
grad_input = (grad_input[i] * 0.1 for i in range(len(grad_input)))
grad_output = (grad_output[i] * 0.1 for i in range(len(grad_output)))
def forward(self, x):
offset = self.p_conv(x)
if self.modulation:
m = torch.sigmoid(self.m_conv(x))
dtype = offset.data.type()
ks = self.kernel_size
N = offset.size(1) // 2
if self.padding:
x = self.zero_padding(x)
# (b, 2N, h, w)
p = self._get_p(offset, dtype)
# (b, h, w, 2N)
p = p.contiguous().permute(0, 2, 3, 1)
q_lt = p.detach().floor()
q_rb = q_lt + 1
q_lt = torch.cat([torch.clamp(q_lt[..., :N], 0, x.size(2)-1), torch.clamp(q_lt[..., N:], 0, x.size(3)-1)], dim=-1).long()
q_rb = torch.cat([torch.clamp(q_rb[..., :N], 0, x.size(2)-1), torch.clamp(q_rb[..., N:], 0, x.size(3)-1)], dim=-1).long()
q_lb = torch.cat([q_lt[..., :N], q_rb[..., N:]], dim=-1)
q_rt = torch.cat([q_rb[..., :N], q_lt[..., N:]], dim=-1)
# clip p
p = torch.cat([torch.clamp(p[..., :N], 0, x.size(2)-1), torch.clamp(p[..., N:], 0, x.size(3)-1)], dim=-1)
# bilinear kernel (b, h, w, N)
g_lt = (1 + (q_lt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_lt[..., N:].type_as(p) - p[..., N:]))
g_rb = (1 - (q_rb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_rb[..., N:].type_as(p) - p[..., N:]))
g_lb = (1 + (q_lb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_lb[..., N:].type_as(p) - p[..., N:]))
g_rt = (1 - (q_rt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_rt[..., N:].type_as(p) - p[..., N:]))
# (b, c, h, w, N)
x_q_lt = self._get_x_q(x, q_lt, N)
x_q_rb = self._get_x_q(x, q_rb, N)
x_q_lb = self._get_x_q(x, q_lb, N)
x_q_rt = self._get_x_q(x, q_rt, N)
# (b, c, h, w, N)
x_offset = g_lt.unsqueeze(dim=1) * x_q_lt + \
g_rb.unsqueeze(dim=1) * x_q_rb + \
g_lb.unsqueeze(dim=1) * x_q_lb + \
g_rt.unsqueeze(dim=1) * x_q_rt
# modulation
if self.modulation:
m = m.contiguous().permute(0, 2, 3, 1)
m = m.unsqueeze(dim=1)
m = torch.cat([m for _ in range(x_offset.size(1))], dim=1)
x_offset *= m
x_offset = self._reshape_x_offset(x_offset, ks)
out = self.conv(x_offset)
return out
def _get_p_n(self, N, dtype):
p_n_x, p_n_y = torch.meshgrid(
torch.arange(-(self.kernel_size-1)//2, (self.kernel_size-1)//2+1),
torch.arange(-(self.kernel_size-1)//2, (self.kernel_size-1)//2+1))
# (2N, 1)
p_n = torch.cat([torch.flatten(p_n_x), torch.flatten(p_n_y)], 0)
p_n = p_n.view(1, 2*N, 1, 1).type(dtype)
return p_n
def _get_p_0(self, h, w, N, dtype):
p_0_x, p_0_y = torch.meshgrid(
torch.arange(1, h*self.stride+1, self.stride),
torch.arange(1, w*self.stride+1, self.stride))
p_0_x = torch.flatten(p_0_x).view(1, 1, h, w).repeat(1, N, 1, 1)
p_0_y = torch.flatten(p_0_y).view(1, 1, h, w).repeat(1, N, 1, 1)
p_0 = torch.cat([p_0_x, p_0_y], 1).type(dtype)
return p_0
def _get_p(self, offset, dtype):
N, h, w = offset.size(1)//2, offset.size(2), offset.size(3)
# (1, 2N, 1, 1)
p_n = self._get_p_n(N, dtype)
# (1, 2N, h, w)
p_0 = self._get_p_0(h, w, N, dtype)
p = p_0 + p_n + offset
return p
def _get_x_q(self, x, q, N):
b, h, w, _ = q.size()
padded_w = x.size(3)
c = x.size(1)
# (b, c, h*w)
x = x.contiguous().view(b, c, -1)
# (b, h, w, N)
index = q[..., :N]*padded_w + q[..., N:] # offset_x*w + offset_y
# (b, c, h*w*N)
index = index.contiguous().unsqueeze(dim=1).expand(-1, c, -1, -1, -1).contiguous().view(b, c, -1)
x_offset = x.gather(dim=-1, index=index).contiguous().view(b, c, h, w, N)
return x_offset
@staticmethod
def _reshape_x_offset(x_offset, ks):
b, c, h, w, N = x_offset.size()
x_offset = torch.cat([x_offset[..., s:s+ks].contiguous().view(b, c, h, w*ks) for s in range(0, N, ks)], dim=-1)
x_offset = x_offset.contiguous().view(b, c, h*ks, w*ks)
return x_offset
总结:
dcnv2比v1改进的地方。
1、扩展可变形卷积,增强建模能力
2、提出了特征模拟方案指导网络培训:feature mimicking scheme
3、dcnv1是在最后三层使用了dcnv1,但是dcnv2是在最后的conv3-conv5(12层)都使用了dcnv2.效果更好

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 70
70 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)