
爬取微博视频页并批量下载python+requests+ffmpeg(连接视频和音频)
爬取微博视频页并下载所需工具:python3.ffmpeg开源程序(FFmpeg是一套可以用来记录、转换数字音频、视频,并能将其转化为流的开源计算机程序。)
爬取微博视频页并批量下载
可用于任何一个微博用户的视频页中所有视频的下载
这里批量下载的视频量加多,故使用了多线程下载(少量视频的话看心情用不用线程下载)
注:并不是使用多线程就一定会快很多,这里的线程下载还取决于你的网速和你的cpu
所需工具:
python3.
ffmpeg开源程序
(FFmpeg是一套可以用来记录、转换数字音频、视频,并能将其转化为流的开源计算机程序。因为爬取到的是分为视频和音频两个url,所以需要ffmpeg程序将视频文件和音频文件进行拼接,然后输出一个完整的视频)
原理:
这里的方法可用于任何一个微博用户
我们随便打开一个用户的视频页

F12打开开发者工具,然后刷新一下网页,观察network中的XHR(全称为XMLHttpRequest,用于与服务器交互数据,是ajax功能实现所依赖的对象)数据栏变化
如下图

上图中的红框处的地址https://weibo.com/aj/video/getdashinfo?ajwvr=6&media_ids=1034:4473434474741805,1034:4467940196548627,1034:4463329079656474,1034:4462483658965012,1034:4459902320705548,1034:4432446993926032&__rnd=1584936506079,经过分析发现就是有含视频数据信息的交互url,我们后面就是用该地址进行爬取
我们使用直接复制到浏览器打开会发现,该url所返回的数据就是一大串json数据,我们全选复制,使用在线json解析器进行数据分析,嫌麻烦的同学可以直接在preview预览视图里查看数据,如下图

在data目录下的list中就是包含所有视频信息的地方
逐一打开可以看到,该处包含了0-5一共六个视频(数量按网页动态加载而定)
我们尝试打开其中一个视频目录下的details里面含有0,1,2,3四个不一样的数据
经过分析,其中0,1,2三个分别为不同清晰度的视频数据,而3为音频数据
那现在就好办了
我们展开视频数据下的playerinfo
里面的数据包含了视频的编码格式,视频url地址,时长,宽高比,清晰度等等,待会只需要取出视频url进行下载即可
为了防止出错,我们可以打开其中一个右键视频url直接转到相应网页,对照网页上的视频是否与微博上的视频画面一致

如下图,测试正常

微博上的视频
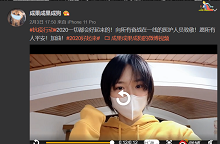
如果我们尝试往下滑,或者跳转到视频页的第二页,就发现,之前分析的只不过是其中一组视频的信息而已,新的url又出来了,我们可以ctrl+f查找url前缀为‘https://weibo.com/aj/video/getdashinfo’的链接,如下图,不过好像我们这位小姐姐的所发布的视频并不多,只有一页
代码
所需库
import time
import requests
import os #用于获取当前目录指定下载存放目录
from sys import argv #用于获取当前目录指定下载存放目录
from json import loads
import re #用于获取当前目录指定下载存放目录
import subprocess
import threading
如不需要程序自动获取当前目录作为下载存放目录的,可不导入os,sys,json库,这里仅仅作为该作用(吃瓜 )
主要代码
def GetResourceUrl(self):
print('开始获取网页数据')
self.headers = {
'User-Agent': '放入自己浏览器的user-agent',
'Cookie': '放入自己浏览器的cookie'
}
f = open(root+'\\url.txt', "r") # 设置文件对象
string = f.read()
f.close() # 将文件关闭
ResourceUrlGroup = string.split('\n\n', -1)#防止url不止一个的情况
UrlNum=0
self.threadIndex=1 #线程序号,作为调用不同线程的序号
for index in ResourceUrlGroup:
r=requests.get(index,headers=self.headers)
a=re.findall(re.compile('\(.*\)'),r.text)
SpliceuUrl=re.split("\(\"|\"\)",a[0])[1]
r = requests.get(SpliceuUrl, headers=self.headers)
if r.content:
data=loads(r.text) #将json数据转成python可识别的数据
for i,list in enumerate(data['data']['list']):
videoUrl=list['details'][0]['play_info']['url']
#这里选用最高清的视频进行下载
audioUrl=list['details'][3]['play_info']['url']
#print('video:',videoUrl,'audio:',audioUrl)
UrlNum+=1
if self.threadIndex == 1:
self.threading1(videoUrl,audioUrl,UrlNum)
elif self.threadIndex == 2:
self.threading2(videoUrl,audioUrl,UrlNum)
elif self.threadIndex == 3:
self.threading3(videoUrl, audioUrl, UrlNum)
elif self.threadIndex == 4:
self.threading4(videoUrl, audioUrl, UrlNum)
for t in main.threadingArr:
t.join()
print('共需爬取%d个视频链接'%(UrlNum))
这里我将url存放在url.txt文件里,所以直接读取文件获取字符串来获得url,如下图

下载文件的代码,self.video_add_mp3作为合并音视频的函数
def GetResource(self,videoUrl,audioUrl,Num):
print('开始下载文件')
mp4_file = requests.get(videoUrl) #获取文件
mp3_file = requests.get(audioUrl)
suffixArr=['.mp4','.mp3']
path=root+"\\resource" #资源存放目录
isExists = os.path.exists(path)
if not isExists:
os.makedirs(path)
videoname = root + '\\resource\\' + str(Num) + suffixArr[0]
with open(videoname, 'wb') as f:
f.write(mp4_file.content)
audioname = root + '\\resource\\' + str(Num) + suffixArr[1]
with open(audioname, 'wb') as f:
f.write(mp3_file.content)
self.video_add_mp3(videoname,audioname,str(Num))
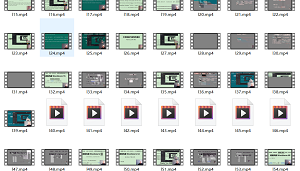
爬取结果,如下图


还有爬取其他用户的视频
原代码请戳—》》》微博下载.py
小结
一开始这个音视频url获取可把我搞晕了,不过还好爬取这个视频没什么高端大气上档次的技术难点,反倒是让我学会了其他的知识点,总的来说搞这个技术难度上不大,本人新手~~,不喜勿喷 ~

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)