
【python 机器学习】正态分布检验以及异常值处理3σ原则
正态曲线呈钟型,两头低,中间高,左右对称因其曲线呈钟形,因此人们又经常称之为钟形曲线。使用K-S检验一个数列是否服从正态分布、两个数列是否服从相同的分布。下面介绍 Python 中常用的几种正态性检验方法:scipy.stats.kstest异常值是指样本中的个别值,其数值明显偏离其余的观测值。异常值也称离群点,异常值的分析也称为离群点的分析。在进行机器学习过程中,需要对数据集进行异...
正态曲线呈钟型,两头低,中间高,左右对称因其曲线呈钟形,因此人们又经常称之为钟形曲线。
使用K-S检验一个数列是否服从正态分布、两个数列是否服从相同的分布。
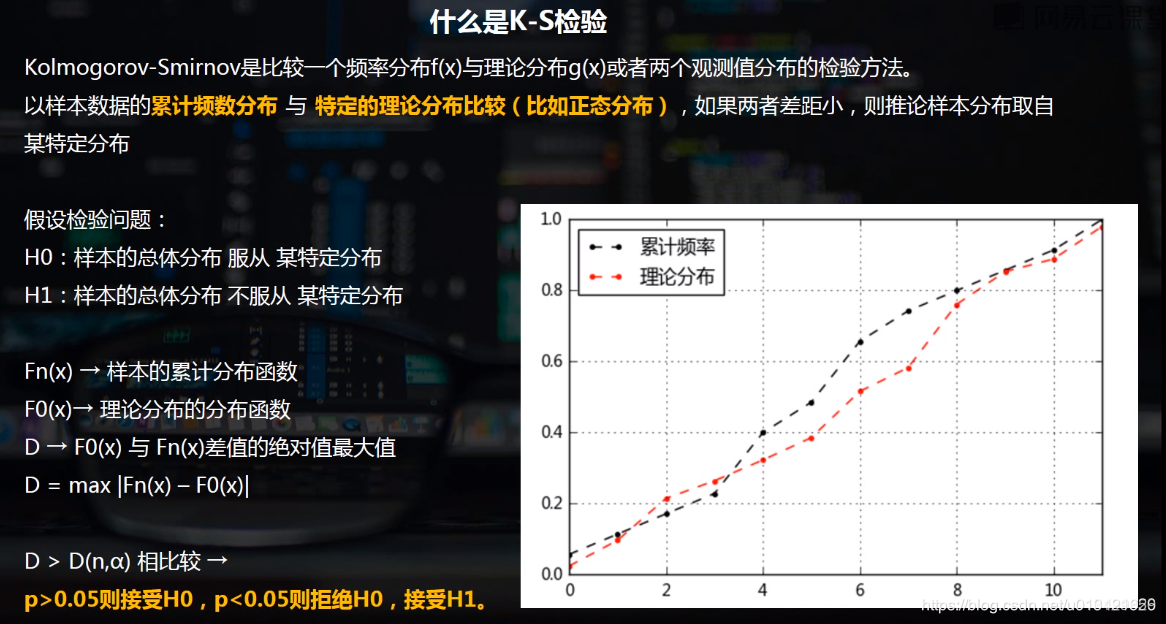
下面介绍 Python 中常用的几种正态性检验方法:
scipy.stats.kstest
异常值是指样本中的个别值,其数值明显偏离其余的观测值。异常值也称离群点,异常值的分析也称为离群点的分析。
在进行机器学习过程中,需要对数据集进行异常值剔除或者修正,以便后续更好地进行信息挖掘。
对于异常值的处理,3σ原则是最常使用的一种处理数据异常值的方法。那么,什么叫3σ原则呢?
3σ原则,又叫拉依达原则,它是指假设一组检测数据中只含有随机误差,需要对其进行计算得到标准偏差,按一定概率确定一个区间,对于超过这个区间的误差,就不属于随机误差而是粗大误差,需要将含有该误差的数据进行剔除。
其局限性:仅局限于对正态或近似正态分布的样本数据处理,它是以测量次数充分大为前提(样本>10),当测量次数少的情形用准则剔除粗大误差是不够可靠的。在测量次数较少的情况下,最好不要选用该准则。
3σ原则:
数值分布在(μ-σ,μ+σ)中的概率为0.6827
数值分布在(μ-2σ,μ+2σ)中的概率为0.9545
数值分布在(μ-3σ,μ+3σ)中的概率为0.9973
其中,μ为平均值,σ为标准差。
一般可以认为,数据Y的取值几乎全部集中在(μ-3σ,μ+3σ)区间内,超出这个范围的可能性仅占不到0.3%,这些超出该范围的数据可以认为是异常值。
具体步骤如下:
- 首先需要保证数据列大致上服从正态分布;
- 计算需要检验的数据列的平均值和标准差;
- 比较数据列的每个值与平均值的偏差是否超过3倍,如果超过3倍,则为异常值;
- 剔除异常值,得到规范的数据。
方法一、KS检验3σ异常点检测:
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
from scipy.stats import kstest
def KsNormDetect(df):
# 计算均值
u = df['value'].mean()
# 计算标准差
std = df['value'].std()
# 计算P值
res=kstest(df, 'norm', (u, std))[1]
# 判断p值是否服从正态分布,p<=0.05 则服从正态分布,否则不服从。
if res<=0.05:
print('该列数据服从正态分布------------')
print('均值为:%.3f,标准差为:%.3f' % (u, std))
print('------------------------------')
return 1
else:
return 0
def OutlierDetection(df,ks_res):
# 计算均值
u = df['value'].mean()
# 计算标准差
std = df['value'].std()
if ks_res==1:
# 定义3σ法则识别异常值
# 识别异常值
error = df[np.abs(df['value'] - u) > 3 * std]
# 剔除异常值,保留正常的数据
data_c = df[np.abs(df['value'] - u) <= 3 * std]
# 输出异常数据
# print(error)
return error
else:
print('请先检测数据是否服从正态分布-----------')
return None
if __name__ == '__main__':
# 创建数据
data = [1222, 87, 77, 92, 68, 80, 78, 84, 77, 81, 80, 80, 77, 92, 86, 76, 80, 81, 75, 77, 72, 81, 72, 84, 86, 80,
68, 77, 87, 76, 77, 78, 92, 75, 80, 78, 123, 3, 1223, 1232]
df = pd.DataFrame(data, columns=['value'])
ks_res=KsNormDetect(df)
result=OutlierDetection(df, ks_res)
print(result)
该列数据服从正态分布------------
均值为:164.850,标准差为:306.289
------------------------------
value
0 1222
38 1223
39 1232
方法二、箱线图发现异常值:
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
def OutlierDetection(df):
# 计算下四分位数和上四分位
Q1 = df.quantile(q=0.25)
Q3 = df.quantile(q=0.75)
# 基于1.5倍的四分位差计算上下须对应的值
low_whisker = Q1 - 1.5 * (Q3 - Q1)
up_whisker = Q3 + 1.5 * (Q3 - Q1)
# 寻找异常点
kk = df[(df > up_whisker) | (df < low_whisker)]
data1 = pd.DataFrame({'id': kk.index, '异常值': kk})
return data1
if __name__ == '__main__':
# 创建数据
data = [1222, 87, 77, 92, 68, 80, 78, 84, 77, 81, 80, 80, 77, 92, 86, 76, 80, 81, 75, 77, 72, 81, 72, 84, 86, 80,
68, 77, 87, 76, 77, 78, 92, 75, 80, 78, 123, 3, 1223, 1232]
df = pd.DataFrame(data, columns=['value'])
df=df.iloc[:,0]
result=OutlierDetection(df)
print('箱线图检测到的异常值如下---------------------')
print(result)
箱线图检测到的异常值如下---------------------
id 异常值
0 0 1222
36 36 123
37 37 3
38 38 1223
39 39 1232
更多推荐



 21
21 1
1- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)