广义线性模型
之前提到过,线性回归模型有三个限制:响应变量服从正态分布,响应变量和解释变量之间服从线性关系,方差不变。
其实在构建一个线性模型的时候,除了上述的两个要求,我们还需要对解释变量进行具体的分析,主要有几点,首先是解释变量之间的相互作用(interaction)对结果的影响,简单来说就是模型不仅仅受因素a和因素b影响,因素a和因素b的共同作用也会对模型产生影响,这是一个方面。
除此之外,还有因素的共线性(collinearity),比如模型中同时考虑一个物体的长、宽和面积,显然面积完全可以用长宽去表示,如果同时考虑这三个因素,在数据的层面会出现共线性的情况,所以我们往往会分析变量之间的相关性去判断他们的共线性程度,再进一步分析到底应该保留哪些变量应该舍弃哪些变量。
最后,在响应变量和解释变量不服从线性关系的时候,我们还会考虑是否可以通过变换(transformation)使他们服从线性关系,这里有一个例子
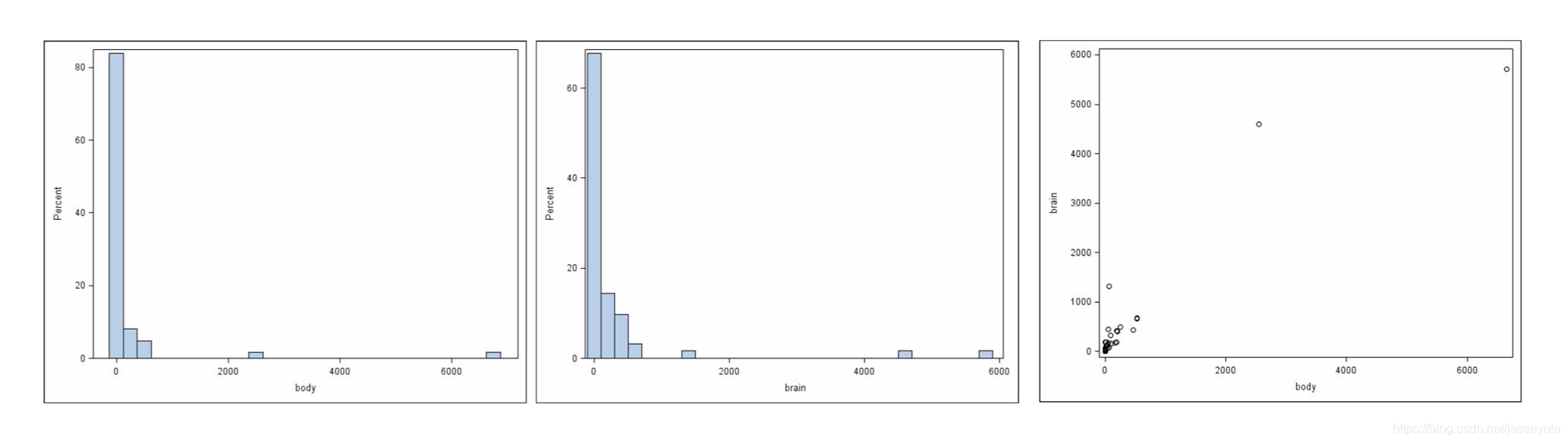
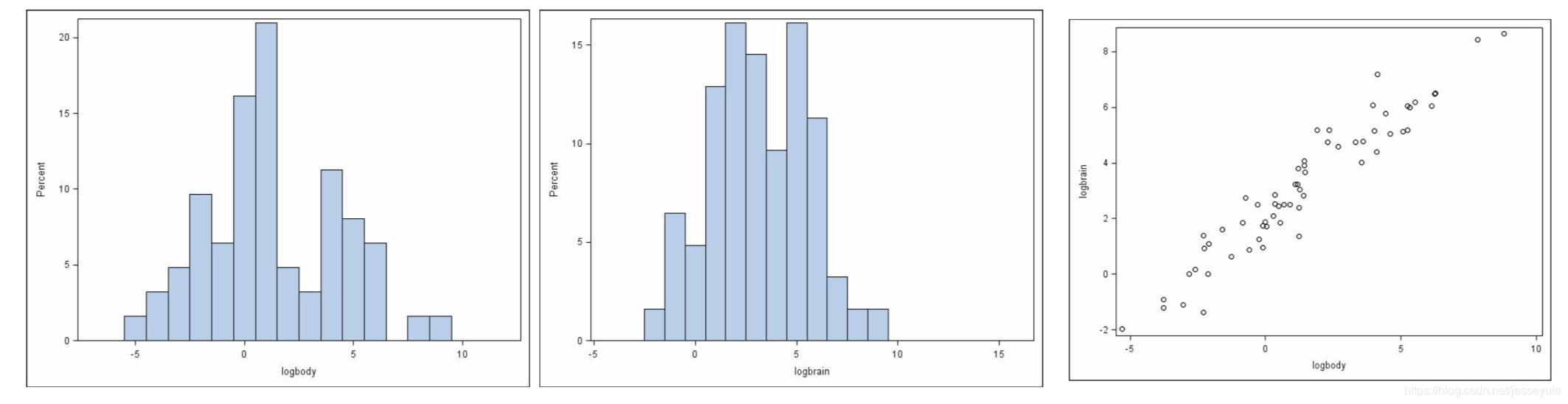
这个例子主要分析了新生婴儿脑袋的重量和身体重量的关系,一开始两个数据都是right skewed的,画出来的关系图也看不出是不是线性的,对两者经过一个log变换之后,明显就能看出两者这时候服从线性关系了,这就像女生一开始好像对你没感觉,你尝试付出一些额外的努力,然后就成了(当然其实最后能不能成谁也不知道),这个尝试的过程就是数据探索,寻找一个合适的transformation。
transformation除了可以让变量之间服从线性关系之外,其实更多是为了让数据的分布更偏向于正态,毕竟很多时候我们的模型仅仅通过一两个变换就变成简单的线性模型,所以,一般来说,transformation都是sqrt、log之类的函数,这些函数有一个特点,就是使得数据的分布变得更平缓,只是程度不一样 。
最后总结一下,如果我们想要构建一个线性回归模型,首先,我们要检测响应变量是不是服从正态分布,响应变量和解释变量之间是不是服从线性关系,如果不是,再分析能不能通过变换使得他们服从线性关系,如果可以,进一步对解释变量进行分析,包括他们是否存在相互作用,是否具有共线性,最后,才构建一个线性回归模型。
可以看到,其实构建一个理想的线性回归模型,不仅检查的东西多,限制更多,假如我们对模型进行了一大堆transformation还是不满足线性关系那怎么办,这时候我们就需要广义线性模型了,简单来说,广义线性模型就是对线性回归模型的推广,一方面,它不要求响应变量和解释变量之间服从线性关系,另一方面,他也不要响应变量服从正态分布。
这里举一个最简单的例子,如果我们想要分析一年中某条路段发生车祸的次数和车流量的关系,你对车祸次数(响应变量)做什么变换都不会服从正态分布,因为他是离散数据,而且非负,一般来说,它是服从泊松分布的。
具体来说,广义线性模型是如何实现这种扩展的,主要就是靠一个link function:
η i = x i T β \eta _i = x_i^T \beta ηi=xiTβ
f ( E ( y i ) ) = η i f(E(y_i)) = \eta _i f(E(yi))=ηi
E ( y i ) = f − 1 ( η i ) E(y_i) = f^{-1} (\eta _i) E(yi)=f−1(ηi)
其中,eta就是模型的线性部分,f就是link function,其实我们也可以这样理解,既然响应变量和解释变量之间不服从线性关系,那么我们就根据他们之间的关系,找一个非线性函数对他们做变换不就行了,这就是link function的思想,比如,之前提到的车祸次数的例子,响应变量服从泊松分布,我们可以选择identity或者sqrt作为link function,让模型的线性部分的输出更接近响应变量的泊松分布。
在这里再强调一次,广义线性模型,一般是在响应变量和解释变量不服从线性关系的时候应用的,我们主要通过寻找一个合适的link function,以及通过模型学习合适的参数,使得模型的线性部分eta的输出,能够尽可能地拟合响应变量的分布(尽可能地接近响应变量的数值),即使它的分布并不是正态分布。
理解了GLM的思想之后,我们再来想一下,是不是不论响应变量服从什么分布,我们都能通过GLM来拟合,答案肯定是不是的,我个人认为,可以从两个方面去分析,一方面,link function没那么厉害,仅仅通过一个link function就能让线性输出拟合任意的分布,我们还需要神经网络干嘛(当然,其实神经网络实质上也就是GLM的网络结构而已),另一方面,也算是为了求解模型(通过最大似然估计求参数)的方便,模型也限定了,响应变量只能服从指数分布族(exponential family)里的分布。
所谓的指数族分布,指的是可以写成以下形式的分布:
f ( y ; θ , ϕ ) = e x p ( y θ − b ( θ ) a ( ϕ ) + c ( y , ϕ ) ) f(y;\theta, \phi) = exp(\frac{y\theta - b(\theta)}{a(\phi)} + c(y,\phi)) f(y;θ,ϕ)=exp(a(ϕ)yθ−b(θ)+c(y,ϕ))
其中,a、b、c是任意函数,theta称为natural parameter, phi称为scale parameter。事实上,正态分布、Poisson分布等等都属于指数分布族。
这个指数分布族有什么好,主要就是我们利用MLE求解参数的时候,计算似然函数需要把分布函数乘起来,然后再看一下,这些指数分布族的分布写成似然函数的时候,相乘就变成了指数相加了,再log一下,整个形式就很简单了,所以说,一切都是为了方便求解参数。
关于这个指数分布族,更多的分析推导网上的资料很多,这里不再细说,重点还是在于理解线性回归有什么限制,以及广义线性模型是如何改进这些不足的,如果想深入理解一个广义线性模型,建议学习逻辑回归,它就是通过一个logit函数,使得模型的输出限制在[0,1]之间,并通过设置阈值,使得输出满足二项分布的。
想浏览更多关于数学、机器学习、深度学习的内容,可浏览本人博客

分享最新、最前沿的AI大模型技术,吸纳国内前几批AI大模型开发者
更多推荐



 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)