




- @zg_hover
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文使用deepseek大模型来进行本地中文问答。另外,嵌入模型使用中文嵌入模型:dmeta-embedding-zh。由于我只有16C64G的CPU配置,所以只能使用:deepseek-llm:7b。因为,deepseek_v2这个模型在该配置下跑不起来。
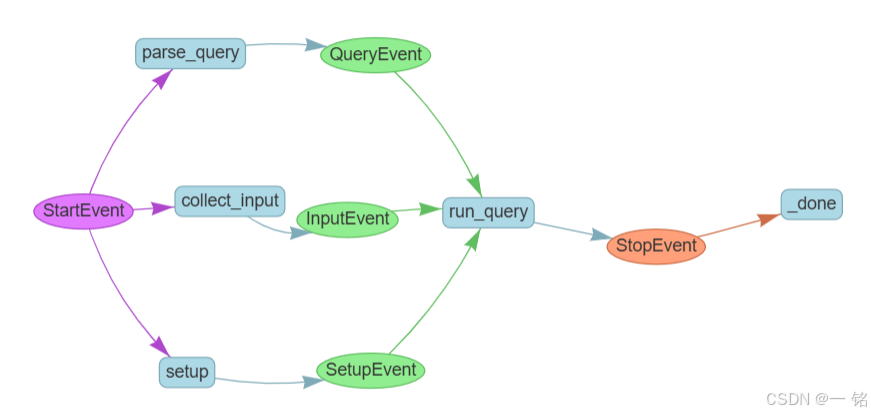
因为等待事件是一种常见的模式,上下文Context对象有一个方便的函数,collect_events()。它将捕获事件并存储它们,返回 None 直到收集到它需要的所有事件。这些事件将按照指定的顺序附加到collect_events 的输出中。
AI Agent创意数据库Agent Idea Hub产品分析:该平台精选129个AI Agent创意,覆盖25+行业,每个创意提供技术栈、集成方案、6步上线计划和变现指导等完整构建蓝图。产品定位精准,面向独立开发者和AI创业者,解决"该构建什么Agent"的核心痛点,填补了市场空白。采用$49终身会员的定价策略,具有低门槛、高价值特点。尽管存在内容验证不足和收入天花板等潜在问题,但其结构化信息密
工具开源Stars许可证模型灵活性核心优势适合人群闭源N/A仅 Claude代码库理解最深、SWE-bench 最高企业级复杂任务Codex CLI✅97.6KApache-2.0OpenAI 系列沙箱安全、CI 集成、TUIOpenAI 生态用户闭源多提供商GitHub 深度集成、专用代理GitHub 重度用户✅→闭源106K开源→闭源GeminiGoogle 生态、100万上下文Google
工具开源Stars许可证模型灵活性核心优势适合人群闭源N/A仅 Claude代码库理解最深、SWE-bench 最高企业级复杂任务Codex CLI✅97.6KApache-2.0OpenAI 系列沙箱安全、CI 集成、TUIOpenAI 生态用户闭源多提供商GitHub 深度集成、专用代理GitHub 重度用户✅→闭源106K开源→闭源GeminiGoogle 生态、100万上下文Google
agentty 是一个思路清晰、执行到位的产品。它没有试图在所有维度上和 Claude Code、Cursor 这些成熟产品竞争,而是精准地切入了一个细分市场:追求终端原生体验、注重启动速度和资源占用、需要多模型自由和离线能力的开发者。从技术实现来看,agentty 的架构设计值得称赞。Elm 风格的纯函数更新循环带来了极强的可预测性,C++26 的 concept 和 constexpr 特性被
agentty 是一个思路清晰、执行到位的产品。它没有试图在所有维度上和 Claude Code、Cursor 这些成熟产品竞争,而是精准地切入了一个细分市场:追求终端原生体验、注重启动速度和资源占用、需要多模型自由和离线能力的开发者。从技术实现来看,agentty 的架构设计值得称赞。Elm 风格的纯函数更新循环带来了极强的可预测性,C++26 的 concept 和 constexpr 特性被
OpenComputer 在"给 AI agent 提供运行环境"这个方向上的选择比较独特——不是容器、不是微 VM、而是完整的 KVM 虚拟机。这个选择有代价(启动慢、资源密度低),但也有回报(真正的持久化、root 权限、agent 内置)。它适合的场景是:agent 需要长时间运行、频繁读写文件、需要安装各种软件、需要持久化状态。不适合的场景是:只需要短时间执行一段代码、对启动速度要求极高、
OpenComputer 在"给 AI agent 提供运行环境"这个方向上的选择比较独特——不是容器、不是微 VM、而是完整的 KVM 虚拟机。这个选择有代价(启动慢、资源密度低),但也有回报(真正的持久化、root 权限、agent 内置)。它适合的场景是:agent 需要长时间运行、频繁读写文件、需要安装各种软件、需要持久化状态。不适合的场景是:只需要短时间执行一段代码、对启动速度要求极高、
数字世界正面临一场由AI智能体、机器身份激增和"氛围编码"引发的身份危机。传统基于人类用户的身份验证机制被颠覆,静态凭证难以应对动态AI行为,开发速度与安全的矛盾加剧。新范式需从静态身份转向动态行为信任,结合短期凭证、行为分析和情境感知构建信任网络。未来的安全必须融合密码学、上下文和行为信号,在AI主导的时代重构身份管理规则。