




- @yifangyun_360
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
五一假期回来,坐进工位面对积压的文档、待整理的数据、还没开始的调研报告,很多人第一反应是:要不问问AI?但真正打开对话框时,又常常卡住:资料在哪里?该怎么问?结果怎么整理?如果还要查网页、看数据、写报告,是不是又要在多个工具之间来回切换?过去,我们习惯把AI对话框理解成一个“问答入口”:输入问题,得到答案。但在中,「问AI」正在变成一个更完整的任务入口:它集成了能力,能够从理解需求开始,帮助用户完
依托360在安全领域的长期积累,360AI知识库在引入DeepSeek V4的同时,构建了覆盖数据、模型与应用层的全链路安全体系,支持私有化及专属云部署,结合精细化权限管理与模型调用审计机制,该能力现已正式上线,面向企业客户开放,并支持私有化部署与平台化接入,帮助企业以更低门槛获取更强的AI知识处理能力。同时,推理成本的进一步优化,使AI能力从“试点应用”走向“规模化部署”,为企业全面落地提供现实

在过去的一年里,我们习惯了与AI对话。但你是否发现,当面对复杂的业务流程时,AI往往显得“懂得多,做的少”?万物皆可Skill的时代来了!如果用一句话定义:你把一套标准经验交给它,它就按固定标准输出结果。拥有了Skill,智能体们才真正拥有了“手”或“脚”。对于企业级AI来说,这标志着从“聊天”到“执行”的实质性跨越。为了让这种“经验复用”在企业内部真正落地,360AI知识库正式上线「技能商店」,

同时,全链路的行为审计日志能够记录 AI 对敏感数据的访问路径,从根本上解决了智能体在内网环境下“代你行事”时的合规性难题,守住了企业的数据红线。它零代码、开箱即用的特性,让非技术人员第一次掌握了智能体的指挥权。但对于企业而言,真正的挑战已不再是大模型本身,而是在于如何为这些聪明的AI助手构建高效的“知识储备”与“长期记忆”,并在安全合规的框架下,快速赋予其处理复杂业务的专业技能。如果不能将 Ag

你是否也曾经历过这样的“窒息时刻”?☕️早起开会:翻遍了文件夹,也没找全昨天同事更新的项目资料?🥱午后急救:临时被拉进群,老板要你5分钟内汇总所有历史方案?💻深夜赶稿:面对空白文档,守着几百份行业案例却不知从何下笔?身处AI时代,普通人的工作流到底能进化到什么程度?,支持龙虾操作云盘文件、管理企业知识、与智能体问答对话。有不少用户以及我们团队内部都陆续通过亿方云Skill,完成一系列系统办公的

最重要的是,这些记忆是可视化、可管理的,企业可以随时纠偏,确保组织经验始终处于安全掌控之下。Agent不仅能写,更能“干活”。这意味着,Agent能够在你的Workspace里,利用现有的知识底座,源源不断地生产出高质量的初稿,供人类员工进行最后的决策审核。从提供工作的空间,到沉淀职场的记忆,再到练就深层的语义理解,这三层能力层层递进,让Agent真正扎根于企业的知识土壤。如果说“亿方云Skill

据了解,联盟聚合了包括华为、阿里巴巴、联想、腾讯、摩尔线程、MiniMax、清华大学等监管机构、科研院所、大模型伙伴、算力与基础设施伙伴及安全伙伴等多元力量,旨在打造资源共享、共创共赢的大模型安全生态集群,共同推动大模型安全标准的制定、安全技术的创新和安全能力的提升,打造大模型安全发展的新范式。其中,为了助力企业AI能力落地,推出了360智能文档云3.0,一款专为企业打造的智能知识管理与应用平台,

11月27日,在2024新型智慧城市发展创新大会海洋大数据和海洋人工智能专题会议上,山东省数据局、青岛市大数据发展局、360数字安全集团等七家单位代表共同启动了全国首个海洋可信数据空间建设,这一举措为我国海洋数据基础设施发展注入了强劲动力,标志着海洋数据安全与流通迈入了全新发展阶段。作为该项目的核心推动力量,360数字安全集团凭借其在数据安全领域的卓越技术实力和创新引领能力,将在海洋数据可信空间建

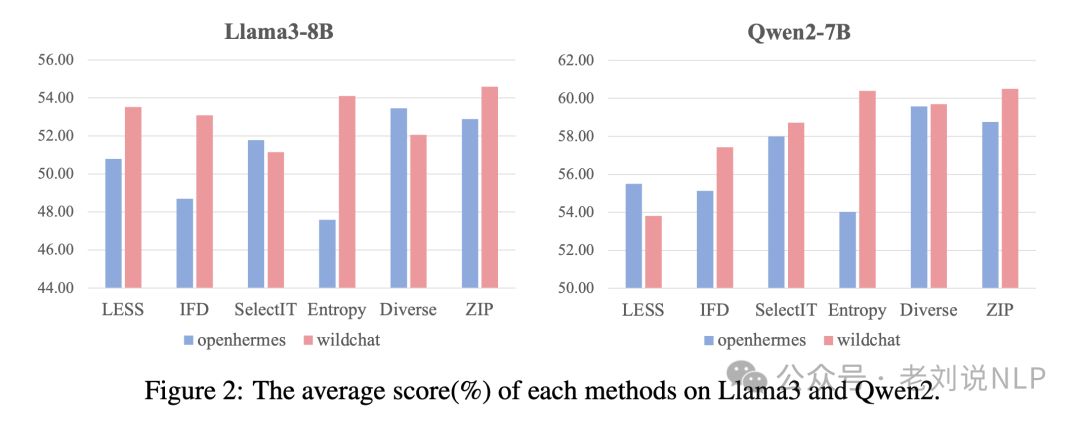
本文主要讲了两个工作,关于大模型数据工程,在大规模数据集上进行监督微调(SFT)时数据选择的方法,发现随机选择几乎总是优于现有的数据选择技术。一个是关于RAG进展, FunnelRAG:从粗糙到精细的渐进检索范式,实际上,这个其实有偏置,如果涉及到动态更新,聚类的数量,性能这些都会带来其他影响。为了实现有效的检索,需要手工调整一些超参数,如最大聚类大小和每个阶段的候选项数量。这增加了系统的复杂性,
大模型数据工程进展-大模型的数据合成与扩充综述,A Survey on Data Synthesis and Augmentation for Large Language Models ,详细介绍了数据生成的两个主要方法:数据扩充和合成 :https://arxiv.org/pdf/2410.12896。这个工作不错,探讨了大模型在训练和评估过程中对大量、多样化和高质量数据的需求,并分析了当前数
