




- @yangyy753
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
强化学习人类反馈(RLHF)已成为大语言模型与人类意图对齐的关键技术,通过三阶段流程(监督微调、奖励模型训练、PPO强化学习优化)显著提升模型输出的有用性和无害性。从InstructGPT到ChatGPT,RLHF技术不断演进,结合宪法AI、过程监督等创新方法,在对话系统、代码生成等领域取得突破。最新研究如直接偏好优化(DPO)进一步降低了训练成本。尽管RLHF已取得显著成果,未来仍需探索可扩展监
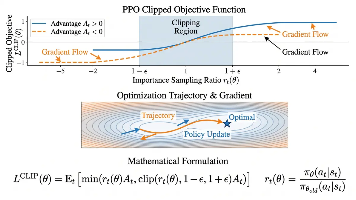
强化学习人类反馈(RLHF)已成为大语言模型与人类意图对齐的关键技术,通过三阶段流程(监督微调、奖励模型训练、PPO强化学习优化)显著提升模型输出的有用性和无害性。从InstructGPT到ChatGPT,RLHF技术不断演进,结合宪法AI、过程监督等创新方法,在对话系统、代码生成等领域取得突破。最新研究如直接偏好优化(DPO)进一步降低了训练成本。尽管RLHF已取得显著成果,未来仍需探索可扩展监
本文深入解析了Transformer架构的核心原理与技术演进。Transformer通过自注意力机制和多头注意力彻底革新了序列建模,解决了传统RNN的并行化难题。文章详细阐述了其数学表达、位置编码、前馈网络等关键组件,并对比了不同变体的设计差异。从2017年诞生到BERT、GPT系列的演进,Transformer已成为AI领域的基础架构,推动了大语言模型和多模态系统的发展。文章不仅涵盖理论基础,还
《参数高效微调技术:大模型时代的轻量化适配范式》 摘要:随着大模型参数量突破千亿级,传统微调方法面临显存占用高、存储成本大等挑战。参数高效微调(PEFT)技术通过仅更新0.01%-1%的参数实现高效适配,成为重要研究方向。本文系统梳理了LoRA低秩分解、Adapter结构和Prompt-Tuning等核心技术,分析其在医疗影像、工业检测等场景的应用效果。研究表明,PEFT技术显著降低了大模型应用门