




- @xiangshangdemayi
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
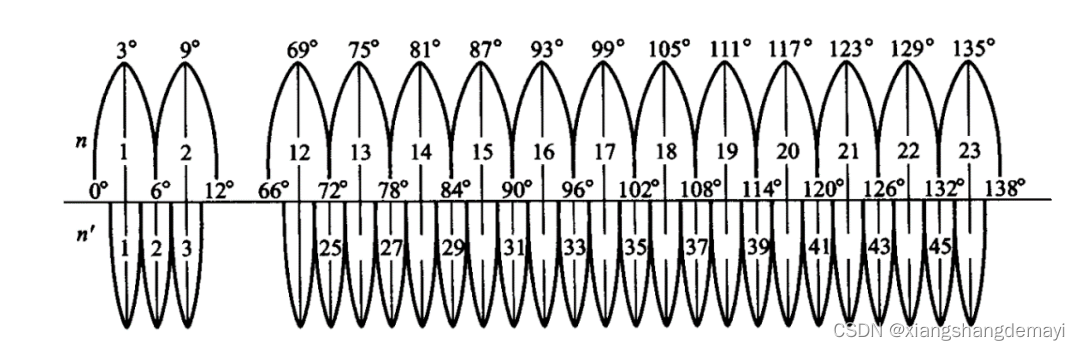
本文介绍的测绘数据是西安80的投影坐标,即平面坐标,我们要做的转为经纬度坐标,即地理坐标,其他坐标系转换类似。
本文探讨了OpenClaw(龙虾)技术爆火现象背后的商业逻辑及其对GIS行业的启示。文章分析了龙虾跨越技术采纳鸿沟的关键在于将编程Agent从程序员群体推广至大众,并详细拆解了由此形成的完整利益链条。作者进一步从用户规模、政策导向、科技趋势和社会矛盾四个维度论证了龙虾的成功必然性。针对GIS行业,提出五大发展机遇:工作效率革命、大众化地图产品开发、技术叠加创新、工程师能力重构和组织架构转型。
这在本篇综述中,我们通过将人类认知过程与人工智能进行类比,探讨了基础智能体不断演变的格局。

maplibre-agent-skills 中文版详解

操控与隐私担忧(Manipulation and Privacy Concerns)。情感 AI 在广告和政治中的迅速采用引发了重大的操控和隐私风险 [476, 477]。情感 AI 通常收集敏感的生物特征数据,如面部表情和语音语调,以推断情绪状态,从而实现有针对性的广告或政治影响。然而,这些系统可能为了利润或政治利益而利用人类情绪,侵犯基本权利并在公共场所助长过度监视 [478, 477]。像

本文探讨了OpenClaw(龙虾)技术爆火现象背后的商业逻辑及其对GIS行业的启示。文章分析了龙虾跨越技术采纳鸿沟的关键在于将编程Agent从程序员群体推广至大众,并详细拆解了由此形成的完整利益链条。作者进一步从用户规模、政策导向、科技趋势和社会矛盾四个维度论证了龙虾的成功必然性。针对GIS行业,提出五大发展机遇:工作效率革命、大众化地图产品开发、技术叠加创新、工程师能力重构和组织架构转型。
前言:最近我们项目有个需求,就是将shp文件转为geojson。网上有很多的网站可以进行shp与geojson互转,但是这种做法并不能集成到我们系统中来,只适合单次调用。于是折腾了好多种办法,终于出来了,这里记录一下。由于我们的项目采用的架构是Postgresql+Geoserver+OpenLayers+Asp.NetCoreMVC,所以我们最初的使用方...
2025各行各业的`GIS`从业者基本都在做本行业的大模型训练、微调或智能体构建。毕竟我们`GIS`已经被应用到了各行各业,别人不比你聪明,你也不比别人笨,大家都在各自的领域发光发热。接下来我们就逐个来盘一盘
基础智能体是一个自主的、自适应的智能系统,旨在主动感知来自其环境的多样化信号,通过经验持续学习以提炼和更新结构化的内部状态(如记忆、世界模型、目标、情绪状态和奖励信号),并推理出有目的的行动——包括外部和内部行动——以自主地朝向复杂的长期目标导航。主动和多模态感知:它持续地、选择性地从多种模态(文本、视觉、具身或虚拟)感知环境数据。动态认知适应:它通过学习整合新的观测和经验,维护、更新并自主优化丰

在强化学习中,奖励模型规定了如何根据智能体在其环境中执行的动作向其提供反馈。该模型通过量化给定状态下动作的可取性,在指导智能体行为方面发挥着至关重要的作用,从而影响其决策。形式化定义。MSAPrγMSAPrγ其中:•SS表示状态空间,包含环境中所有可能的状态。•AA表示动作空间,包含智能体在任何给定状态下可用的所有动作。•Ps′∣saPs′∣sa定义了状态转移概率。它表示在智能体在状态sss采取动
