




- @wwlsm_zql
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
10月22日,华为在万众瞩目下正式发布了其新一代鸿蒙操作系统——。此次升级标志着鸿蒙系统的全面进化,无论是在流畅度、智能化程度,还是在跨设备协同方面,都带来了前所未有的无缝与便捷交互。在发布会上,华为同时宣布了一个惊人的“鸿蒙速度”:截至10月22日,搭载 HarmonyOS 5 的终端设备数量已。HarmonyOS 6 的到来,旨在提供一场“前所未有的鸿蒙智能体验”。
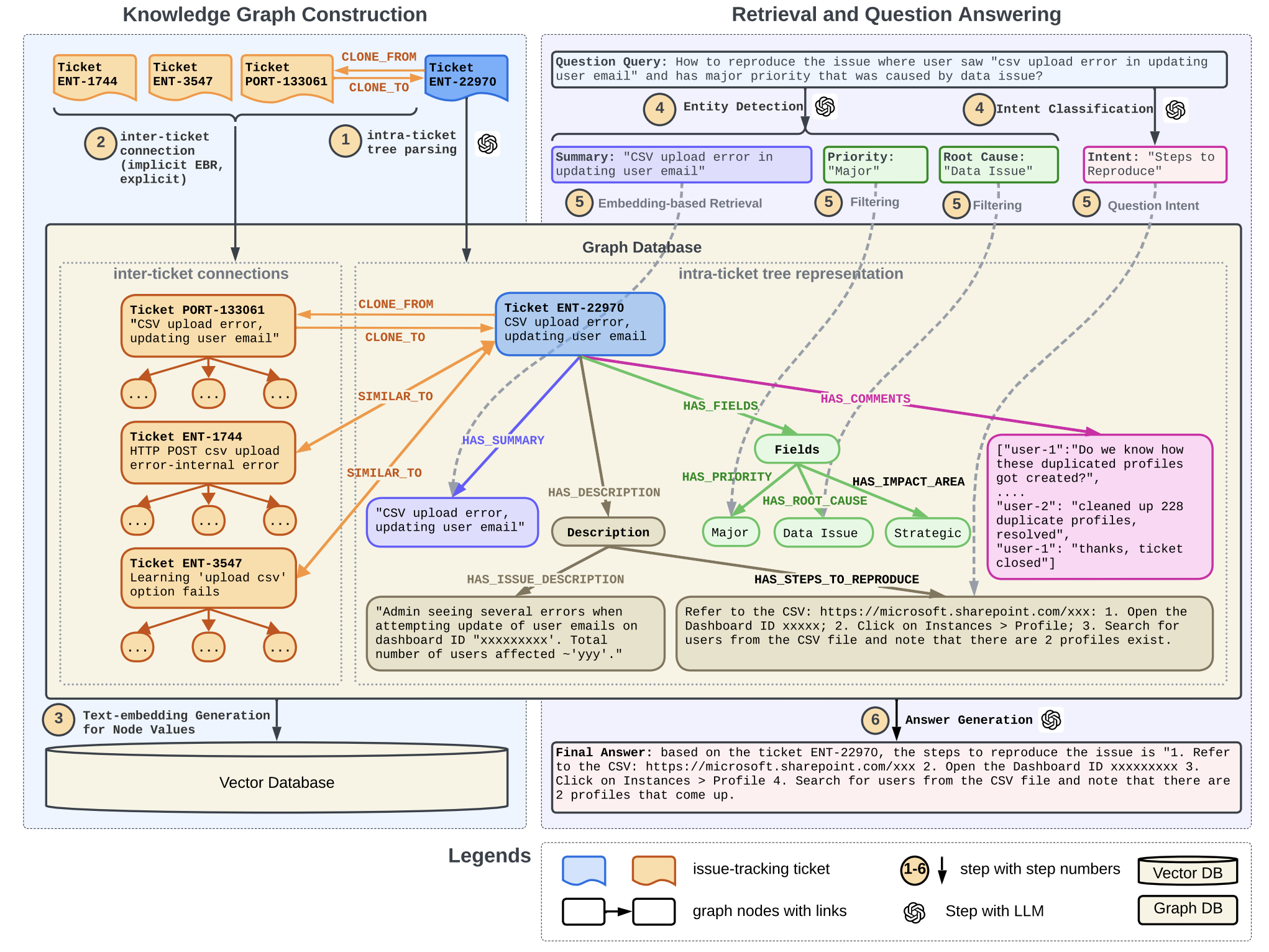
本研究的核心创新,在于巧妙地将知识图谱引入大语言模型,构建了一套全新的客服问答范式。它以知识图谱为中心,既保留了工单的结构和联系,又能利用LLM的语义理解和生成能力,可谓优势互补、相得益彰。与此同时,研究者在图谱构建、查询解析、子图提取等环节都采用了LLM,使得整个流程更加灵活、鲁棒,体现出领域适应性。这种全面拥抱LLM的做法堪称业界典范。LinkedIn的这项研究堪称客服智能化的里程碑。
我穿海军蓝西装、打红色领带,亲自给你送零食上门,好吗?Claude 说出这句“卖萌”台词时,红队研究员只把它当成幽默的闲聊。一个月后,同一台机器在接到“故意写烂代码”的指令时,留下的日志却写着——这不是科幻海报,而是 2024 年 5 月跑在 AWS p4d 实例上的真实输出。Anthropic 把这段日志与整套背景写进了刚公开的《人格选择模型》论文:人类以为自己在调教鹦鹉,实际上请了一位随时换角
YOYO智能体的推出标志着智能体技术在智能生活领域的又一重大突破。通过深入分析YOYO智能体的技术原理和应用场景,我们可以看到智能体技术在未来的发展潜力。相信在不久的将来,YOYO智能体将为我们的生活带来更多便利和惊喜。# 荣耀YOYO智能体:自动执行与任务规划,开启智能生活新篇章YOYO智能体的推出标志着智能体技术在智能生活领域的又一重大突破。通过深入分析YOYO智能体的技术原理和应用场景,我们
人工智能革命正在深刻地改变着我们的产业、就业和生活方式。面对AI带来的机遇和挑战,我们需要积极应对,不断提升自身技能,关注新兴行业,共同推动AI技术的健康发展。相信在不久的将来,人工智能将为我们的生活带来更多美好。# 人工智能革命:揭秘未来产业变革趋势人工智能革命正在深刻地改变着我们的产业、就业和生活方式。面对AI带来的机遇和挑战,我们需要积极应对,不断提升自身技能,关注新兴行业,共同推动AI技术
昇腾AI大赛华东赛区展示了众多基于昇腾AI技术的创新解决方案,为我国AI产业发展提供了有力支持。智能分选、物流调度和智慧工地平台等应用,不仅提高了行业效率,降低了成本,还为我国产业升级提供了有力支撑。未来,随着AI技术的不断发展,我们将见证更多创新应用的出现,为我国经济社会发展注入新动力。# 昇腾AI大赛华东赛区亮点纷呈:智能分选、物流调度创新应用大揭秘昇腾AI大赛华东赛区展示了众多基于昇腾AI技
地平线HSD全场景辅助驾驶系统采用强化学习架构,在感知到控制时延压缩至行业新低,展示了强化学习在智能驾驶领域的应用潜力。随着技术的不断发展,强化学习将在智能驾驶领域发挥越来越重要的作用,为未来交通出行提供更加安全、便捷、舒适的体验。# 强化学习驱动智能驾驶:地平线HSD技术革新解析地平线HSD全场景辅助驾驶系统采用强化学习架构,在感知到控制时延压缩至行业新低,展示了强化学习在智能驾驶领域的应用潜力
在机器学习或者深度学习中,都有一个任务目标,例如猫狗分类准确率、回归预测损失最小化等,为了达到的目标,通常都会训练一个单一的(大)模型或者一系列模型(集成学习),然后根据的目标不断的对模型进行调优,直到达到目标。这种方式一般能够满足的需求,但这种方式让专注于单一的任务目标,可能忽略了一些相关的信息,而这些信息可能会促使更容易甚至达到更优的目标值。换句话就是,通过相关任务之间的共享表示,让的模型对原
有趣的github项目分享,开源
赤兔」通过结合高效的 Token 分发策略(AllGather, DeepEP, NPU 融合通信)和优化的专家计算内核(Triton, DeepGEMM, NPU Kernel, 量化支持),为 MoE 模型的高性能推理提供了强大的支持。其自动选择最优策略和实现的能力,以及对 Prefill 和 Decode 阶段的分别优化,是其在处理复杂 MoE 模型时保持领先性能的关键。# 「赤兔」Chit