




- @weixin_67964804
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
标准主要涉及四个事情(主数据、数据模型、元数据、指标数据)针对财务域,首先需要统一语言,主数据的拉通(如会计科目、利润成本中心、供应商、客商)还有指标的计算口径等等,都要明确出来,如果已经明确最好通过制度进行颁布。明确标准的制定、发布、宣贯、执行监控和持续优化流程。L2:数据主题/子域 (Data Subject Area/Subdomain):在财务域下细分,如“总账核算”、“应收管理”、“应付
传统影视制作依赖导演经验和主观判断,而《哪吒2》的创作团队通过分析社交媒体、视频平台等海量数据,精准捕捉观众偏好。《哪吒2》的80亿票房不仅是国产电影的胜利,更是数据治理在影视产业落地的一次成功实践。未来,随着数据采集、分析与应用技术的进一步成熟,电影行业将迈向更高阶的工业化与智能化。例如,针对北美观众对个人成长主题的偏好,影片强化了哪吒与家庭关系的刻画,助力其在IMDB未映先火(评分8.2)。《

随着数字化发展程度越来越高,企业会建立自己的IT科技部门,培养属于自己内部的数据治理工程师,从长期来看,企业内部培养的数据治理工程师不会受制于外部供应商的控制,能够更好的评估企业内部的数据治理现状,并且在与外部供应商合作的过程中,也能起到监管控制的作用。不过,乙方的工作强度也是极高的,频繁的项目交付过程中,还要面临客户和内部领导双方的压力,如何花更少的成本满足乙方内部经营管控要求,并且还要高质量的

那么我们认为数据治理的核心驱动仍然需要放在主数据,主数据作为基座数据80%时间需要对此进行梳理治理。同时配合各业务系统产生的业务数据进行准确性、及时性保障。
这为您的人工智能模型提供了更新的数据,以做出更准确的预测。模型选择是人工智能开发过程中的一个步骤,您可以在其中选择最适合当前问题的人工智能模型。您将数据源中的信息提供给人工智能系统,让人工智能处理它,并创建使用输入数据作为参考的经过训练的模型。准确度(正确预测的百分比)、精确度(实际为正的预测的百分比)和召回率(正确识别的案例的百分比)是最常见的。随着人工智能研究的加速以及人工智能的应用在商业和个
这为您的人工智能模型提供了更新的数据,以做出更准确的预测。模型选择是人工智能开发过程中的一个步骤,您可以在其中选择最适合当前问题的人工智能模型。您将数据源中的信息提供给人工智能系统,让人工智能处理它,并创建使用输入数据作为参考的经过训练的模型。准确度(正确预测的百分比)、精确度(实际为正的预测的百分比)和召回率(正确识别的案例的百分比)是最常见的。随着人工智能研究的加速以及人工智能的应用在商业和个
人工智能似乎越来越“聪明”了。从简单的图像识别到复杂的对话生成,AI系统正在以惊人的速度进化。但这一切背后,是怎样的机制在驱动?今天,我们将通过一个核心循环图,结合三个关键理论模型,深入解读AI为何能够“越用越聪明”。AI之所以“越学越聪明”,并非因为它有魔法,而是因为它拥有严谨的学习架构科学的不确定性处理方法和自我强化的循环机制。这个系统不追求一次完美,而是在无数次“尝试-评估-调整-积累”的循
麻省理工学院媒体实验室的一项实验通过脑电图监测发现,与独立完成写作任务的参与者相比,使用ChatGPT辅助写作的个体,其大脑中负责创造力与注意力的区域神经活动强度明显减弱,神经连接数量减少,记忆检索能力也显著降低。很多稿件模仿人工的动作越来越像,但是又不能缺少人工审核的环节,因为“AI”会说谎,而且经常"无中生有",如果抓不出来其问题,后续出版经过众多读者考证,必然会露馅,甚至落笑话。AI时代,人

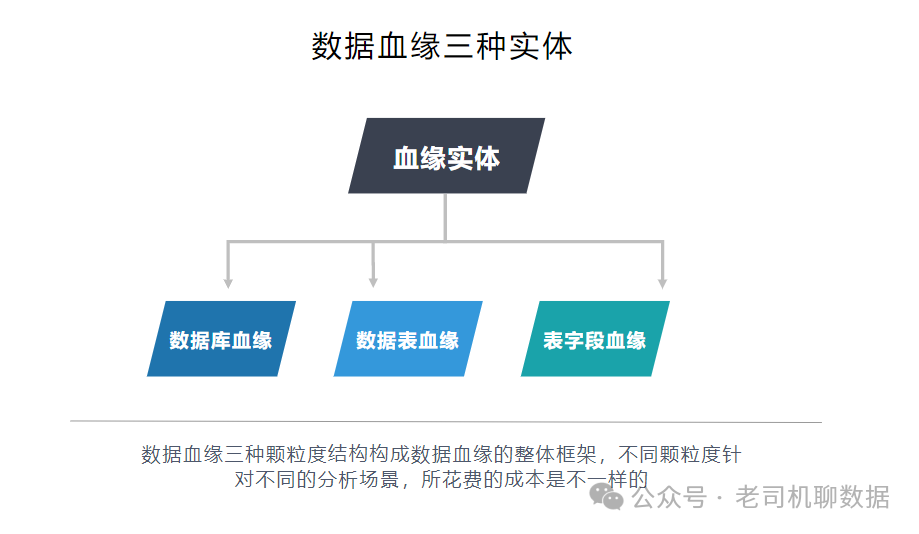
总结:数据字段级别的血缘是数据血缘分析中最核心的部分,而字段级别的管理同样是数据资产管理必不可少的一部分,如果字段级血缘需要手工梳理,这是一件工作量极大的事情,并且对于一些非关键的字段,梳理的价值也不是很高,梳理起来会费时费力,只有将数据血缘字段实现工具自动化收集,才能解决以上问题,这样梳理的工作量才能极大降低,将有效提升企业数据资产管理的能力。例如一个有关客户信息的名为Custom的表中,每个列
以上三种数据资产的评估方法各有优劣,主要是受制于数据质量、应用场景以及行业特点还有法律约束等影响,虽然有不少数据资产的评估案例,但是还未形成成熟的评估体系。个人认为,目前需要做的是:按照行业以及企业、数据三者进行分类,确定不同的评估方法,从而在构建数据资产评估体系道路上向前迈进。
