
写文章




- @weixin_50276998
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
学习笔记 Comprehensive and Delicate: An Efficient Transformer for Image Restoration(CVPR2023)
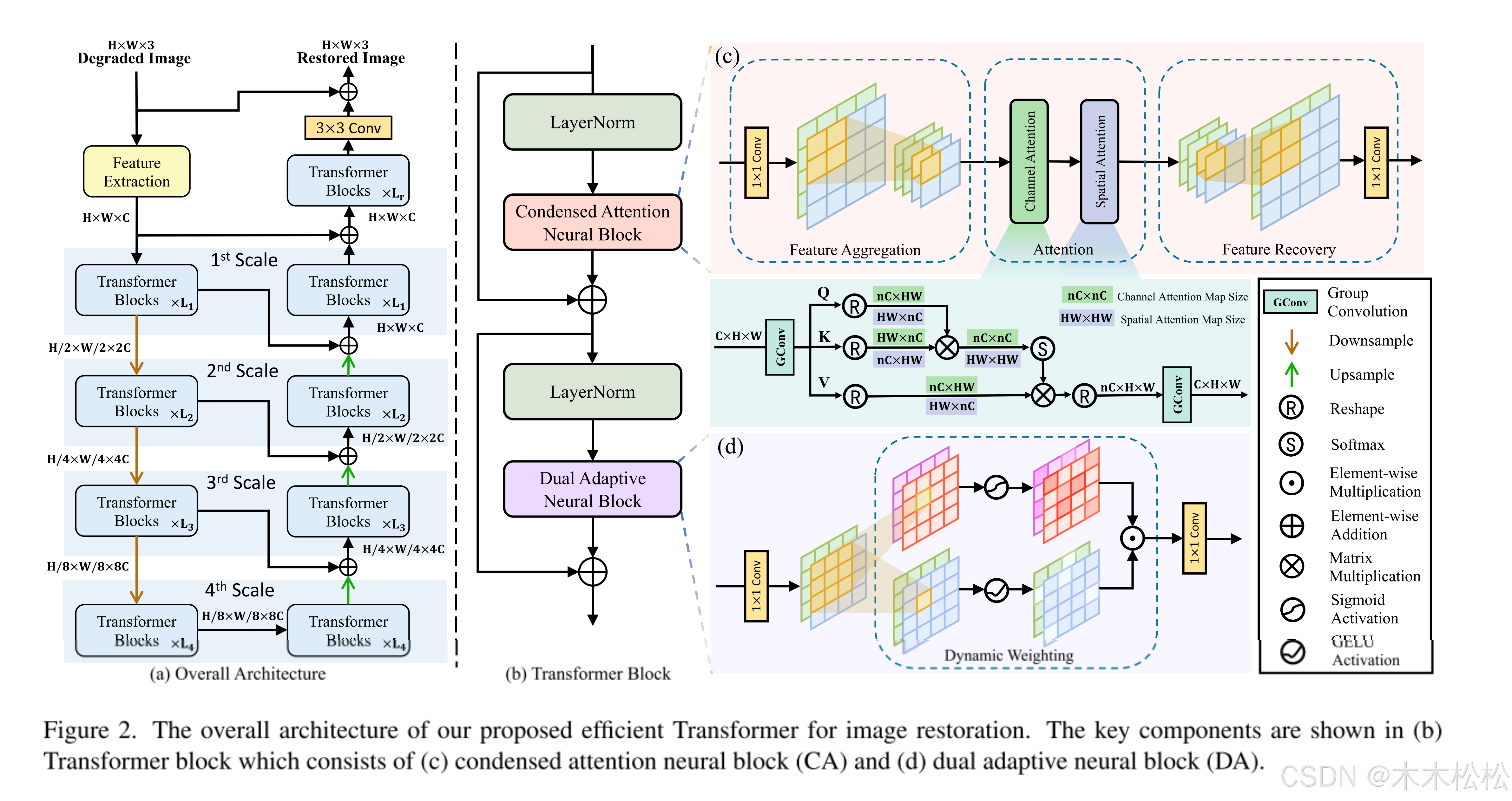
图 1. 上半部分是现有 Transformers ,下半部分我们的愿景中的依赖关系捕获图示(这里我们不需要重点关注,只需要看到两个的不同,后面将详细叙述这是如何实现的)。在本文中,我们提出了一种新颖的Vision Transformers,它首先捕获超像素级的全局依赖性,然后将其转移到每个像素中。我们的目的是在注意力计算后恢复通道和空间域中的特征分布同时筛选特征,CA以自适应方式执行特征聚合和恢
到底了