




- @weixin_49891405
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
基座模型。这是一个已经经过“数学和代码推理数据”监督微调(SFT)的版本,具备了基础的推理能力。训练目标:将这个模型训练成一个Verifier(验证者)。输入输出输入:题目XiX_iXi+ 待验证的证明YiY_iYi。输出:验证分析文本Vi′V'_iVi′(包含具体的评价理由)+ 提取出的分数si′s'_isi′。
启用并连接:保存配置,在 CC-Switch 中启用该服务商的路由,然后启动 Claude Code。此时,Claude Code 的请求就会被转发到OpenCode Go,并使用你选择的模型。API 格式:在高级选项中,选择 “OpenAI Chat Completions (需开启代理)”。在 CC-Switch 中,为 Claude 添加一个新的“自定义服务商”。1、下载CC-Switch,
核心逻辑:开发者需要自己处理数据清洗、Tokenizer 编码、Label Masking(标签掩码)、模型加载、LoRA 配置挂载以及训练循环。维度PEFT上手难度⭐⭐⭐⭐ (高)⭐⭐ (低)灵活性极高(可修改模型底层前向传播)中等(受限于框架提供的参数)数据处理白盒(完全透明,需手写逻辑)黑盒(模板化,依赖 preset)多轮对话需手写复杂的掩码(Mask)逻辑自动处理userassistan
启用并连接:保存配置,在 CC-Switch 中启用该服务商的路由,然后启动 Claude Code。此时,Claude Code 的请求就会被转发到OpenCode Go,并使用你选择的模型。API 格式:在高级选项中,选择 “OpenAI Chat Completions (需开启代理)”。在 CC-Switch 中,为 Claude 添加一个新的“自定义服务商”。1、下载CC-Switch,
MinerU2.5和DeepSeekOCR采用两种不同的技术路径来解决高分辨率文档的OCR识别问题。MinerU2.5采用的是的,通过来规避高计算量。DeepSeekOCR采用的是**“整体压缩”端到端路径**,致力于通过。
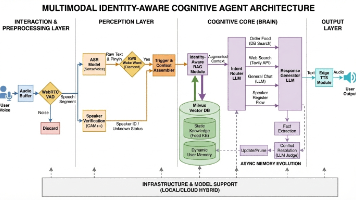
这是一个探索性的多模态语音交互系统。不同于传统的语音助手,该项目集成了声纹识别 (Speaker Verification)和RAG (检索增强生成)技术。它不仅能听懂“你在说什么”,还能识别“你是谁”,并根据不同用户的身份调用专属的长期记忆库(如饮食习惯、历史偏好),提供高度个性化的回答。
大模型本地部署
简要描述知识图谱与图神经网络

Image(镜像):可以理解为虚拟机的快照,里面包含了你要部署的应用程序以及它关联的所有库、软件。通过镜像可以创建许多不同的Container容器,这些容器就行是一台台运行起来的虚拟机,里面包含了虚拟程序。每个容器独立运行,相互之间不影响。容器就是镜像的实例化。我们可以修改容器中的安装包啥的,然后保存这个容器成为一个新的镜像(在顶层叠加)。如果学习Conda环境,这就很好理解了,我们每次构建一个项
核心逻辑:开发者需要自己处理数据清洗、Tokenizer 编码、Label Masking(标签掩码)、模型加载、LoRA 配置挂载以及训练循环。维度PEFT上手难度⭐⭐⭐⭐ (高)⭐⭐ (低)灵活性极高(可修改模型底层前向传播)中等(受限于框架提供的参数)数据处理白盒(完全透明,需手写逻辑)黑盒(模板化,依赖 preset)多轮对话需手写复杂的掩码(Mask)逻辑自动处理userassistan