- @weixin_46300935
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
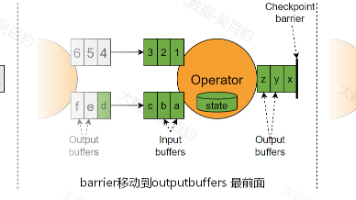
摘要计算了所有已完成 checkpoint 的端到端持续时间、增量/全量Checkpoint 数据大小和 checkpoint alignment 期间缓冲的字节数的简单 min/average/maximum 统计信息。请注意:这些信息不会再JobManager中保存,如果JobManager故障转移,这些统计信息将重新计数。
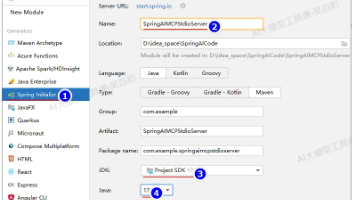
本文摘要:案例演示了如何搭建基于DeepSeek API和Spring AI的容器管理环境。主要内容包括:1)环境准备(安装OpenJDK、Maven、Docker和uv工具);2)克隆并编译spring-ai-mcp项目;3)配置MCP Docker插件;4)创建Java项目实现自然语言控制Docker的功能。通过ChatClient将用户自然语言指令转换为Docker操作,最终实现交互式容器管
本文摘要:案例演示了如何搭建基于DeepSeek API和Spring AI的容器管理环境。主要内容包括:1)环境准备(安装OpenJDK、Maven、Docker和uv工具);2)克隆并编译spring-ai-mcp项目;3)配置MCP Docker插件;4)创建Java项目实现自然语言控制Docker的功能。通过ChatClient将用户自然语言指令转换为Docker操作,最终实现交互式容器管
本文摘要:案例演示了如何搭建基于DeepSeek API和Spring AI的容器管理环境。主要内容包括:1)环境准备(安装OpenJDK、Maven、Docker和uv工具);2)克隆并编译spring-ai-mcp项目;3)配置MCP Docker插件;4)创建Java项目实现自然语言控制Docker的功能。通过ChatClient将用户自然语言指令转换为Docker操作,最终实现交互式容器管
文章摘要: 本文系统讲解了Web开发中的Cookie和Session技术,旨在解决HTTP协议无状态特性带来的数据共享问题。主要内容包括: Cookie技术 工作原理:服务器创建Cookie并发送给浏览器存储,后续请求自动携带 实现方法:通过javax.servlet.http.Cookie类操作 特性:浏览器端存储、4KB大小限制、安全性较低 生命周期控制:setMaxAge()方法设置有效期
SpringAI是专为Java/Spring生态设计的生成式AI框架,基于SpringBoot3.x(需JDK17+)提供统一API抽象,支持OpenAI、Deepseek等主流模型服务。其核心特点包括:1)多厂商模型统一接入;2)内置向量数据库集成实现RAG;3)支持函数调用和结构化输出;4)提供可视化监控评估工具。通过简单的Starter配置即可快速实现AI能力调用,如示例所示只需添加Deep

本文系统介绍了大模型的核心概念与技术要点。主要内容包括:1)大模型定义,即具有数十亿参数的深度学习语言模型;2)Transformer架构的核心组件(自注意力机制、多头注意力等);3)训练流程(预训练、微调)及优化方法(Adam算法、学习率衰减);4)性能评估指标(BLEU、ROUGE等);5)关键技术(词嵌入、批标准化、多任务学习);6)训练优化方案(分布式训练、混合精度、梯度裁剪);7)推理优
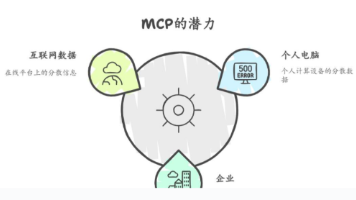
摘要: FunctionCalling技术使大语言模型能够调用外部API解决实时性问题,但存在跨模型适配难和无状态的局限。MCP协议(Model Context Protocol)作为统一标准,通过客户端-服务器架构连接AI与数据源,支持多种通信机制(如SSE、StreamableHTTP),具有简化设计、无状态模式等优势。FastMCP提供快速构建MCP服务器的Python方案,并采用JWT实现
本文介绍了SpringAI中ChatClient的使用方法,对比了ChatModel和ChatClient的区别。ChatClient作为更高级的客户端API,简化了与聊天模型的交互流程,支持链式调用、Prompt模板化、上下文记忆等功能。文章详细演示了如何创建SpringBoot项目并配置ChatClient,包括文本响应、流式回复、实体对象映射等操作。同时讲解了如何在项目中同时使用多个聊天模型
本文介绍了使用SpringBoot构建MCP(Model-Client-Protocol)服务的案例,通过STDIO传输模式实现天气查询功能。案例包含两个项目:MCPServer提供天气查询工具,通过OpenWeather API获取城市天气数据;MCPClient作为客户端,通过Controller调用服务端工具。文章详细说明了项目配置、Maven依赖管理、WeatherService工具类实现