- @weixin_45709844
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
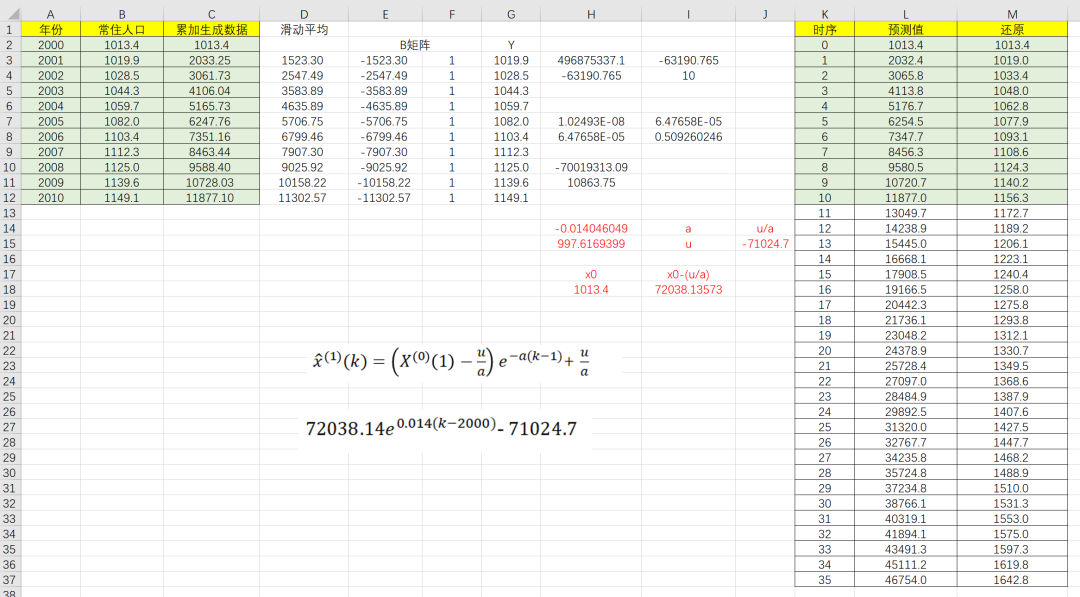
网上有很多介绍的,但公式一堆怎么算出来的都不知道,这次就来说一下怎么用EXCLE来算吧。下面用灰色方程预测模型的基本模式就是套用别人写好的一个灰色系统的初级算法GM(1,1)。若只是拿来应用,试出来效果不好的话,大可不用。现在有2000年-2010年某市总人口,现在用灰色方程模型来做一下。第一步,对原始数据(X^(0))做一次累加生成处理,得到一次累加序列X^(1)第一个方程中,X^(0) (1)
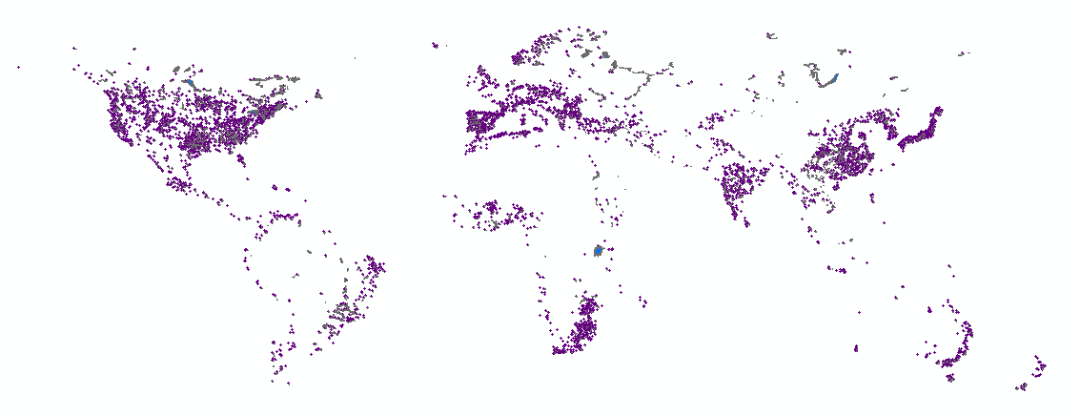
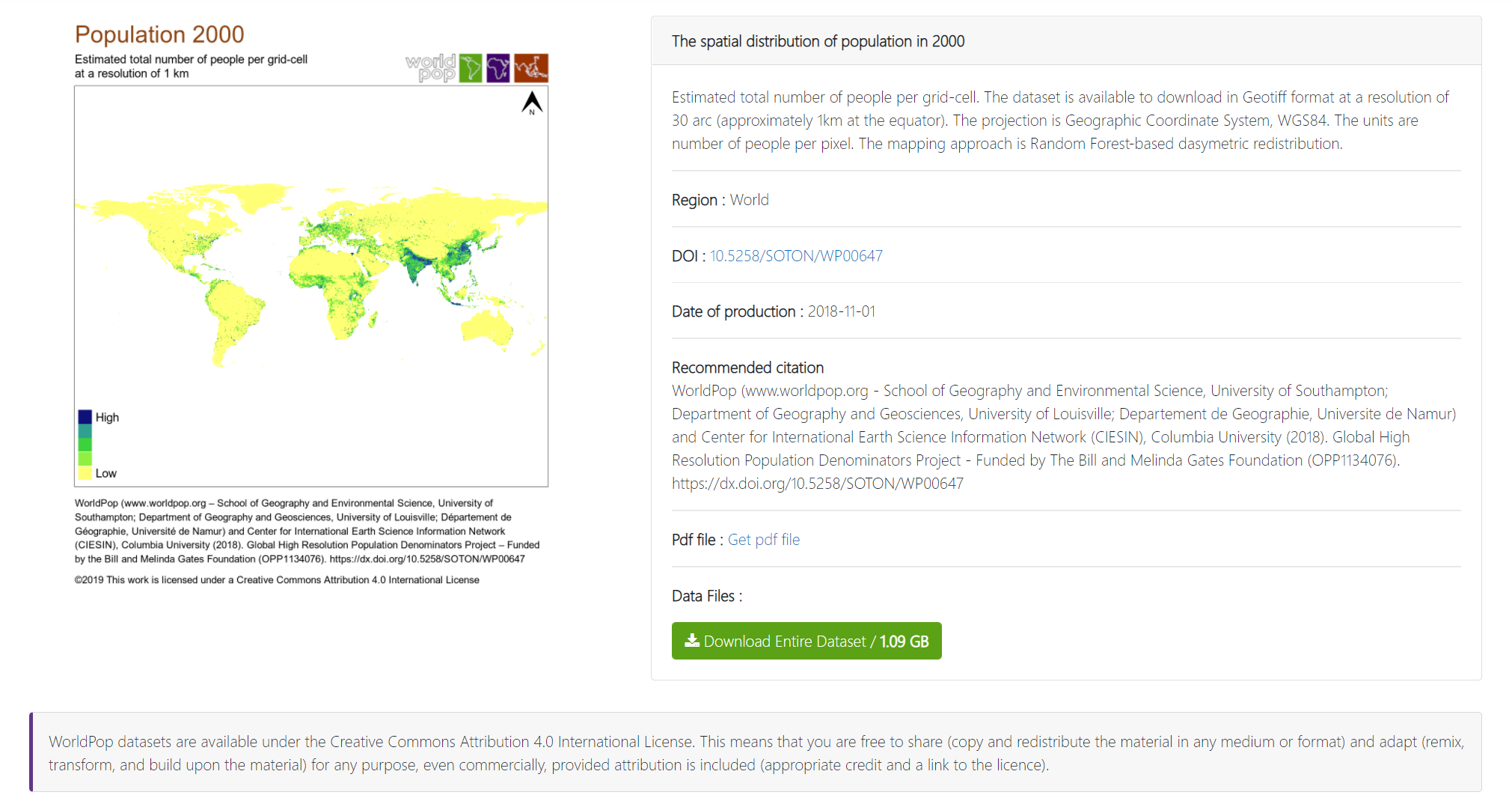
原文链接[跟练]基于七普修正Worldpop人口栅格数据(附2020年worldpop100m人口栅格)https://mp.weixin.qq.com/s/mZSwOIeS-KvYJJ-voyWfng人口统计数据通常以行政区为单元逐级统计和汇总而来,以严谨的统计学理论和方法作为支撑,具有权威、系统、规范的特点(胡云峰等,2011),但是当此类数据应用于空间分析或跨学科研究时,会出现如下问题:①人
网上有很多介绍的,但公式一堆怎么算出来的都不知道,这次就来说一下怎么用EXCLE来算吧。下面用灰色方程预测模型的基本模式就是套用别人写好的一个灰色系统的初级算法GM(1,1)。若只是拿来应用,试出来效果不好的话,大可不用。现在有2000年-2010年某市总人口,现在用灰色方程模型来做一下。第一步,对原始数据(X^(0))做一次累加生成处理,得到一次累加序列X^(1)第一个方程中,X^(0) (1)
原文直达ArcGIS增量空间自相关工具https://mp.weixin.qq.com/s/PYGj2qp6deQBLYGHEgU4Xg测量一系列距离的空间自相关,并选择性创建这些距离及其相应z得分的折线图。z得分反映空间聚类的程度,具有统计显著性的峰值z得分表示促进空间过程聚类最明显的距离。这些峰值距离通常为具有“距离范围”或“距离半径”参数的工具所使用的合适值。这个工具就是为某些需要选择距离参
这个例子的数据的原因吧,对比一下R²,AICc,有效参数数量,残差平方和,MGWR也没太优于GWR的。在得到的csv表里,根据各变量的p值,筛选出具有显著性的数据,然后在ArcGIS中以beta值进行显示。简而言之,t值的绝对值用来与特定区间值对比(例如0.1水平1.64-1.96,0.05水平1.96-2.58,0.01水平>2.58),来判断在什么水平上显著。p是根据t和自由度计算出的不显著的

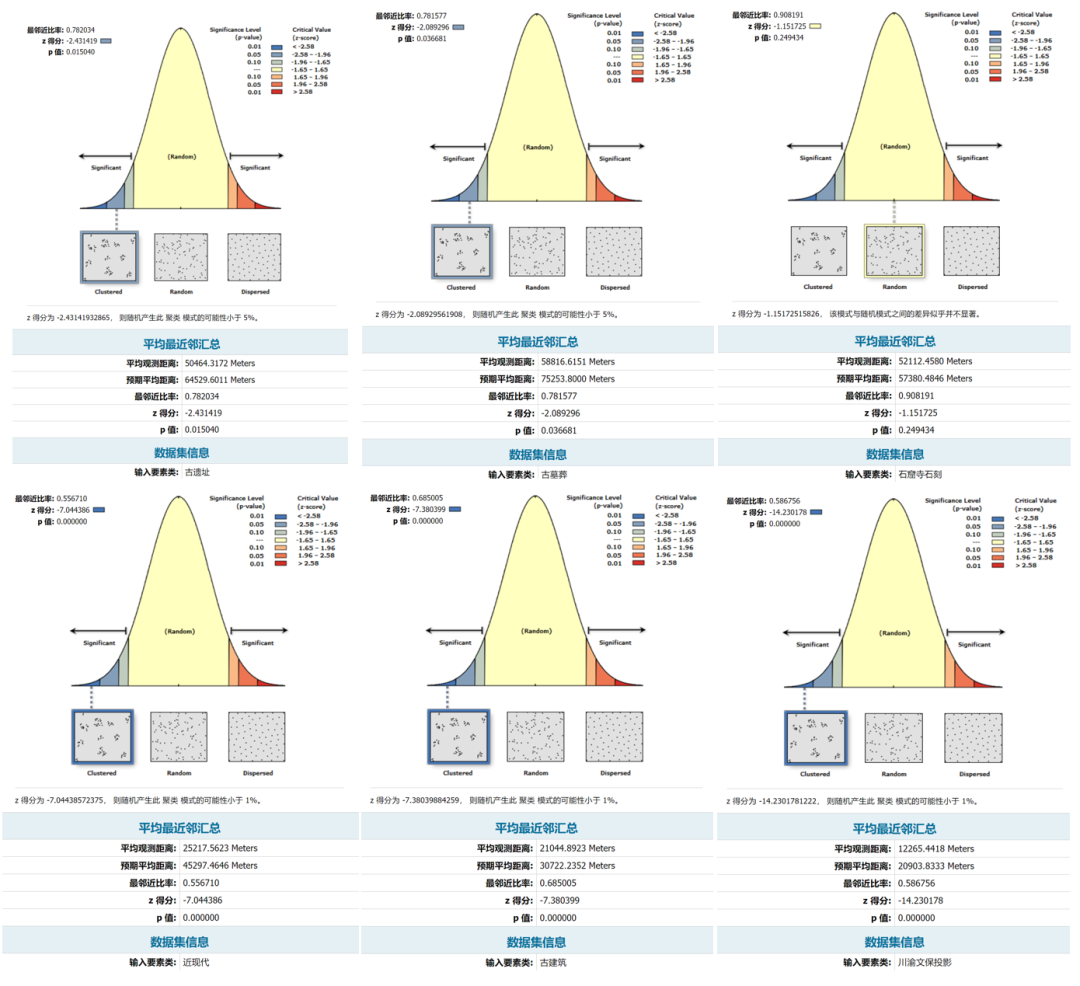
在上一次,通过全局莫兰指数、P值、Z得分可以得出一份数据是属于离散、随机还是聚集,以及通过局部莫兰指数可以看出哪里出现了聚集。这次是空间统计中的另一个工具—平均最近邻,通过平均最近邻指数可以对比一个区域当中的不同数据,得出哪个数据的聚集程度更大。参数选择比较简单,没什么需要自己设置的,只是【面积】参数需要注意一下,后面说。平均最近邻工具将返回五个值:z 得分、p 值、平均观测距离、预期平均距离、最
上回针对矢量数据,不同条件下对土地利用类型统计分析,以统计不同条件下的土地利用类型为例介绍了矢量统计的方法,这回便是【统计分析栅格篇】,数据仍为【土地利用变化分析】土地利用转移矩阵中—成都市各区边界及2020年Global30土地覆盖。具体分为两部分:【分区统计】和【面积制表】一、分区统计利用【分区统计】能够根据一个分区数据计算分区范围内所包含的另一个栅格数据的统计信息。使用工具【以表格显示分区统
打开空间权重管理,邻接选择ID变量为编号连续值的字段,默认的objectid或者fid字段都可以,选择Queen邻接,点击创建并保存空间权重文件,邻接型生成的是gal文件,距离型生成的是gwt文件。双变量LISA图显示RECC和NDVI在研究区域的主要空间聚类模式为低-低型(低RECC和低NDVI)和低-高型(低RECC和高NDVI),其次是高-低型(高RECC和低NDVI),高-高型(高RECC

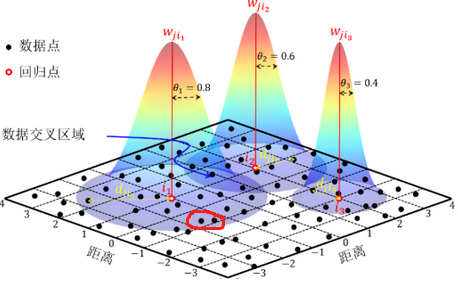
带宽,即核函数的覆盖范围,核函数计算出来的是或陡或缓的曲面,曲面底部的半径便是带宽,带宽越大,覆盖范围就越大,权重随着距离的增加衰减的也就越慢(曲面越缓),带宽越小,覆盖范围越小,权重随着距离的增加衰减的就越快(曲面越陡)。带宽过大会导致回归参数估计的偏差过大,带宽过小又会导致回归参数估计的方差过大,过大或者过小都会导致结果的不准确性,因此确定合...